
등장 배경
ResNet 이전의 모델들은 깊은 모델(레이어를 많이/깊이 쌓아 성능을 높이는 모델)을 만드는데 치중했다.
모델이 깊어질수록 gradient vanishing problem 때문에 학습이 잘 이루어지지 않고, 최적화에서 멀어져 오히려 성능이 떨어지게 되었다.
Gradient vanishing problem이란,
딥러닝 중 backpropagation시 발생되는 어려움으로, 모델이 깊어질수록 미분을 많이 하기 때문에 output에 영향을 끼치는 weight가 작아지는 것을 의미한다.
이는 overfitting과 다른 문제이다.
overfitting은 학습 데이터에 완벽하게 fitting 시킨 탓에 테스트 성능에서 안 좋은 결과를 보이지 않는 것이고,
위 문제는 degradation 문제로 training data에도 학습이 되지 않는 것이다.
이를 극복하기 위해 ResNet이 고안되었다.
ResNet은 skip connection을 이용한 residual learning을 통해 layer가 깊어짐에 따른 gradient vanishing 문제를 해결하였다.
ResNet의 구조
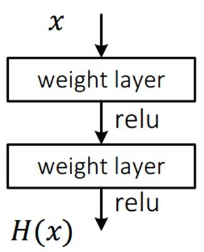
Resnet의 구조를 보기 전에 기존 neural net(Plane Layer)의 구조를 먼저 살펴보자.
기존 neural net의 목적은 input x를 타겟값 y로 mapping하는 함수 H(x)를 찾는 것이였다.
이미지 classification의 문제라면 x에 대한 타겟값 y는 사실 x를 대변하는 것으로 y와 x의 의미가 같게끔 mapping해야 한다.
하지만 위 그림처럼 단순히 H(x)가 x가 되도록 학습해도 gradient vanishing 문제는 해결되지 않는다.
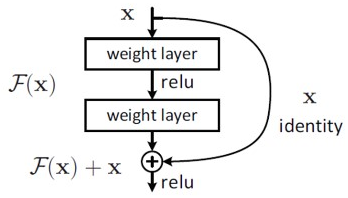
위 사진은 ResNet 모델에서 사용되는 가장 기본적인 구조인 Residual Block이며, BottleNect Architecture로도 불린다.
Resnet 모델은 H(x)-y를 최소화하는 방향으로 학습을 진행한다.
즉, 네트워크의 출력값이 x가 되도록 H(x)-x를 최소화하는 방향으로 학습을 진행한다.
F(x) = H(x)-x 를 잔차라고 하며 이 잔차를 최소화하여 학습하는 것을 Residual learning이라고 한다.
gradient vanishing 문제를 해결하기 위해 마지막에 x를 더해서 H(x)가 x가 되도록 학습하면 미분을 해도 x 자체는 미분값 1을 갖기 때문에 각 layer마다 최소 gradient로 1을 갖게 된다.
그러면 layer가 아무리 깊어져도 최소 gradient로 1 이상의 값을 가지므로 gradient vanishing 문제가 해결된다.
📜 정리
- Plane Layer
- 기존에 학습한 정보를 보존하지 않고 변형시켜 새롭게 생성하는 정보
- 오픈북이 불가능한 시험에 비유 (범위가 많을수록 많은 양을 공부)
- Residual Block
- 기존에 학습한 정보 보존, 거기에 추가적으로 정보를 학습
- 오픈북이 가능한 시험에 비유 (추가적으로 학습해야 할 정보만을 공부)
Residual Block
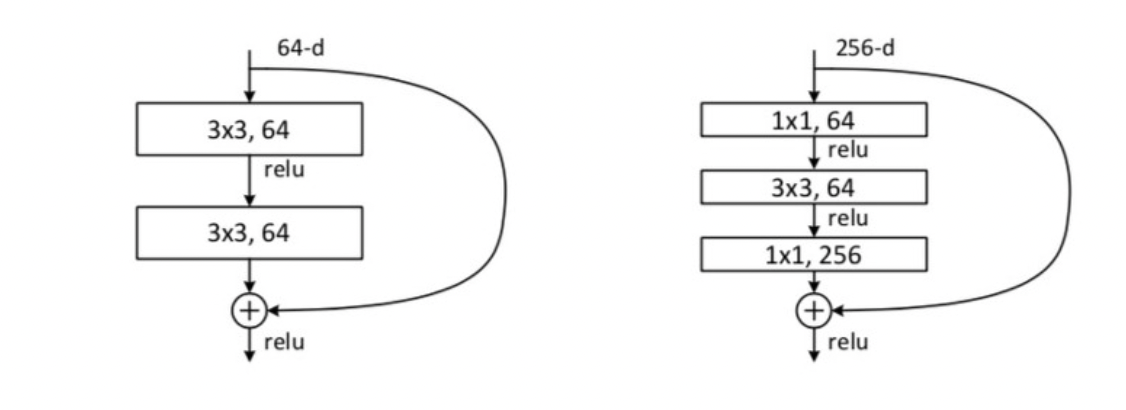
ResNet은 연산량을 줄이기 위해 GoogLeNet에서 사용했던 Bottle Neck Layer를 사용한 Residual Block을 사용한다.
위 사진에서 왼쪽은 Bottle Neck을 사용하지 않은 Residual Block, 오른쪽은 Bottle Neck을 사용한 Residual Block이다.
(ResNet50 이상에서는 Bottle Neck을 사용한 Block을 사용한다)
오른쪽을 확인하면 input x의 dimension을 64로 축소한 후 f(x)를 연산하고 마지막에 256으로 다시 높여주는 것을 확인할 수 있다.
각 convolutional layer은 convolution - batch normalization - relu를 거치는 형태를 띈다.
- Batch normalization: Regularization의 대표적인 기법 중 하나로, batch 데이터를 바탕으로 mean과 variance를 적용해 0~1의 값을 가지도록 도와준다.
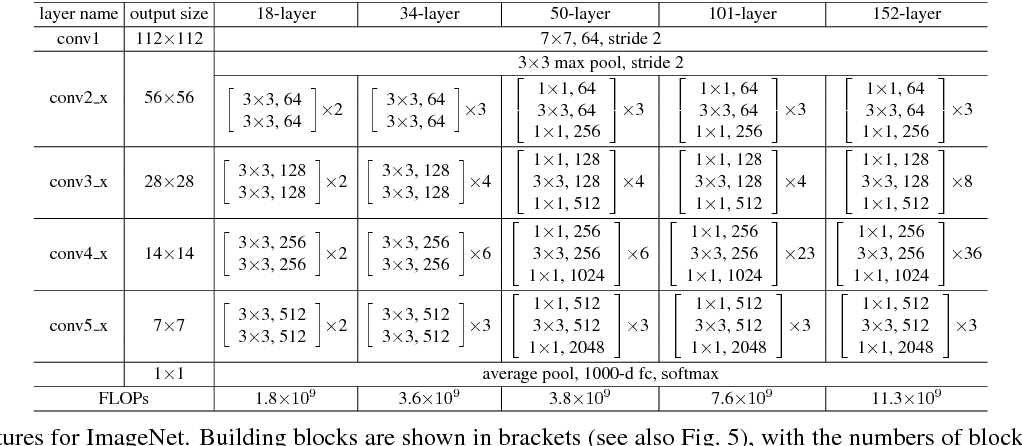
위의 residual block을 바탕으로 만들어지는 ResNet50의 구조는 다음과 같다. 아래 그림 중 50-layer 부분에 해당한다.
🔮 레퍼런스
https://jisuhan.tistory.com/71
https://ganghee-lee.tistory.com/41
https://itrepo.tistory.com/36
