
요즘 인공지능응용시스템 팀 프로젝트를 하고 있다.
내가 하는 프로젝트에서는 CNN과 ResNet을 사용해야 하는데, 그 개념을 잘 몰라 다시 한 번 정리해보도록 한다.
CNN이 무엇일까?
CNN은 Convolutional Neural Networks의 약자로 딥러닝에서 주로 이미지나 영상 데이터를 처리할 때 쓰인다.
이름에서 알 수 있다시피 Convolution이라는 전처리 작업이 들어가는 Neural Network 모델이다.
왜 CNN을 사용할까?
일반 DNN(Deep Neural Network)의 문제점에서 출발해보자.
일반 DNN은 기본적으로 1차원 형태의 데이터를 사용한다. 때문에 2차원 형태의 이미지가 입력값이 되는 경우, 이를 flatten 시켜서 한 줄 데이터로 만들어야 하는데 이 과정에서 이미지의 공간적/지역적 정보가 손실되게 된다.
CNN은 이러한 문제점에서 고안한 해결책이다.
이미지를 날 것(raw input) 그대로 받음으로써 공간적/지역적 정보를 유지한 채 특성들의 계층을 빌드업한다.
✨ key point: 이미지 전체보다는 부분을 보고, 이미지의 한 픽셀과 주변 픽셀의 연관성을 살리는 것
예를 들어보자.
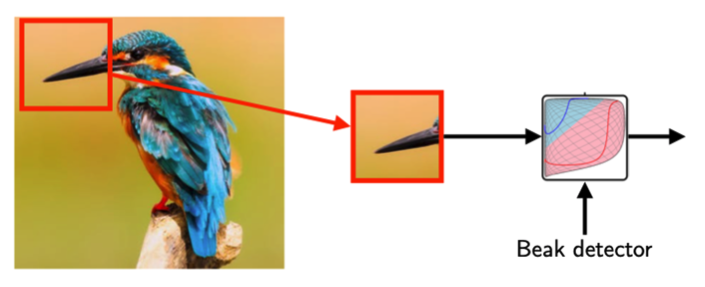
이미지가 주어졌을 때 이것이 새의 이미지인지 아닌지 결정할 수 있는 모델을 만드려고 한다.
그렇다면 새의 주요 특징인 새의 부리가 중요한 포인트가 된다.
하지만 새의 전체 이미지에서 새의 부리 부분은 비교적 작은 부분이다.
그러므로 전체 이미지보다는 새의 부리 부분 이미지를 잘라 보는게 더 효율적이다.
이것을 해주는 것이 CNN이다.
CNN의 주요 컨셉
- CNN에 넣어줄 입력값은 matrix로 표현된 이미지
- 필터(커널)이 존재
- 필터를 이미지 입력값에 전체적으로 훑어줌
- 입력값 이미지의 모든 영역에 같은 필터를 반복 적용해 패턴을 찾아 처리하는 것이 목적
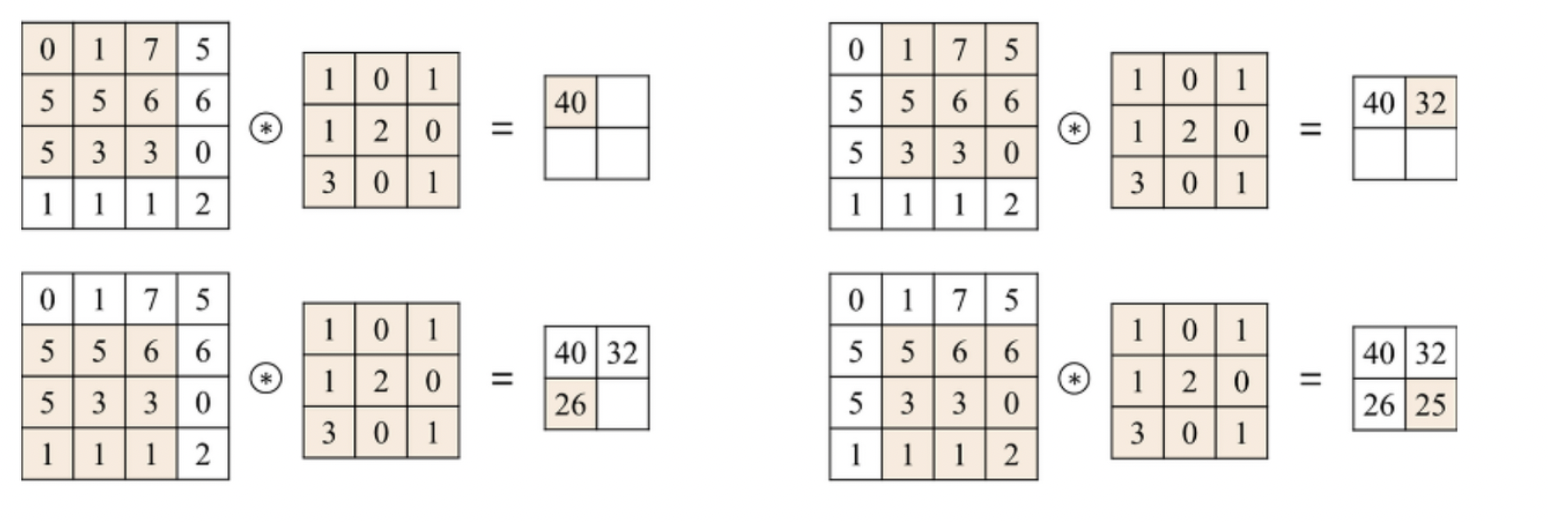
- Zero padding: 0으로 구성된 테두리를 이미지 가장자리에 감싸 주어 손실되는 부분을 줄임
- 입력값의 크기와 결과값의 크기가 동일 → 손실이 없어졌다는 의미
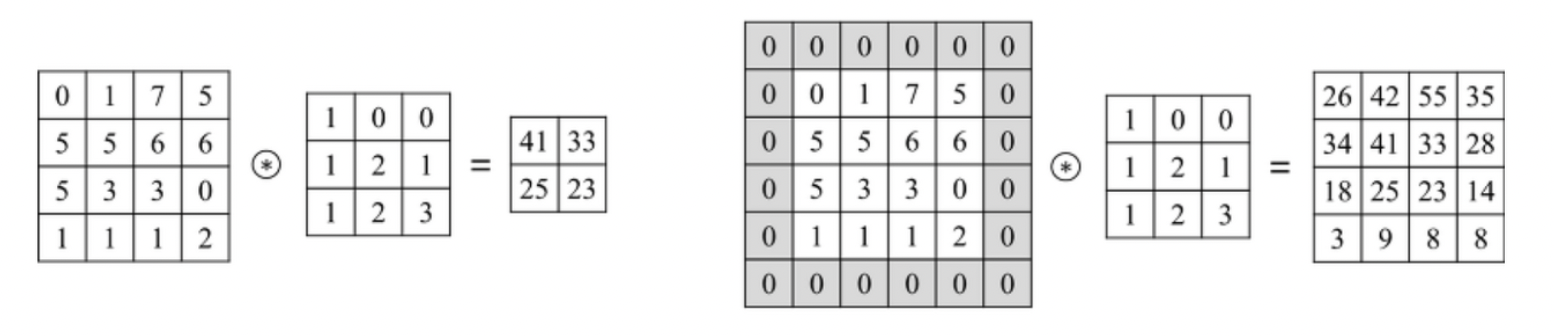
- 입력값의 크기와 결과값의 크기가 동일 → 손실이 없어졌다는 의미
- Stride: 필터를 얼마만큼 움직여 주는가
- stride 값이 커질 경우 필터가 이미지를 건너뛰는 칸이 커짐을 의미 → 결과값 이미지의 크기가 작아짐
- 1이 기본값
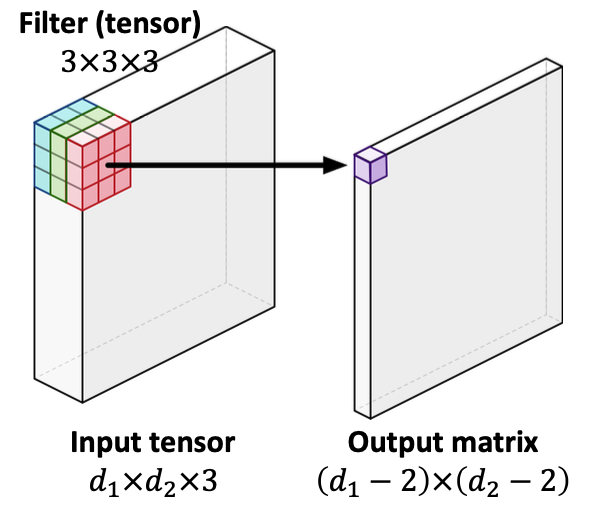
위에서는 2차원 이미지가 입력값일 때를 예시로 들었는데, 컬러 이미지는 R, G, B 3가지 채널로 구성되어 있기 때문에 3차원의 크기를 갖는다.
이러한 모양을 order-3 텐서라고 한다.
CNN 네트워크 구조
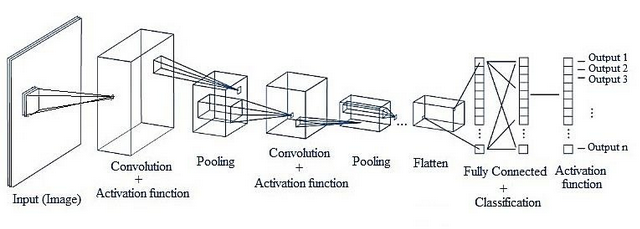
이전 계층의 모든 뉴런과 결합되어 있는 Fully-Connected Layer과 다르게, CNN은 Convolutional Layer과 Pooling Layer들을 활성화 함수 앞뒤에 배치하여 만든다.
1. 첫 번째 Convolution Layer
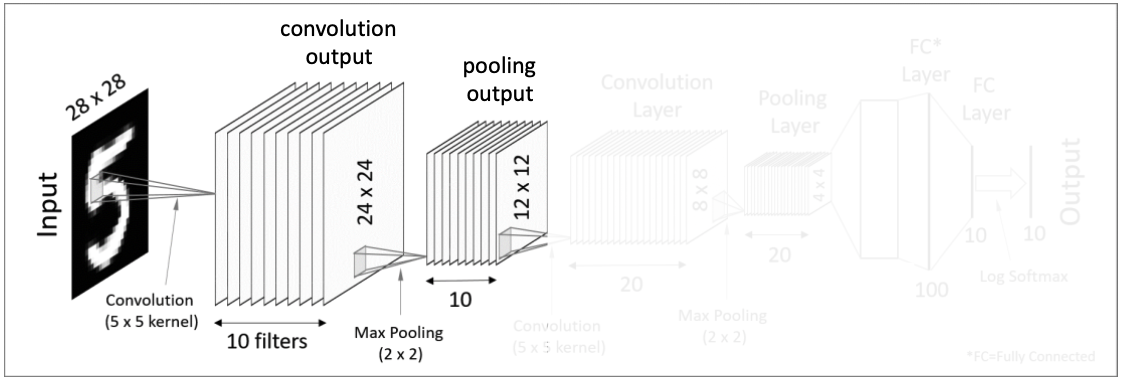
28x28 크기를 가진 이미지에 여러 개의 필터를 사용하여 결과값을 얻는다. (이 과정을 feature mapping이라고도 한다)
1개의 28x28 이미지에 10개의 5x5 필터를 사용하여 10개의 24x24 행렬(convolution 결과값)을 만들어낸다.
그 후, 결과값에 Activation function (ex. ReLU)을 적용한다.
활성함수란? 선형 함수인 convolution을 추가하기 위해 사용하는 것이렇게 첫 번째 Covolution Layer가 완성된다.
하나의 Convolution Layer은 Convolution 처리와 Activation function으로 구성되어 있다.
2. 첫 번째 Pooling Layer
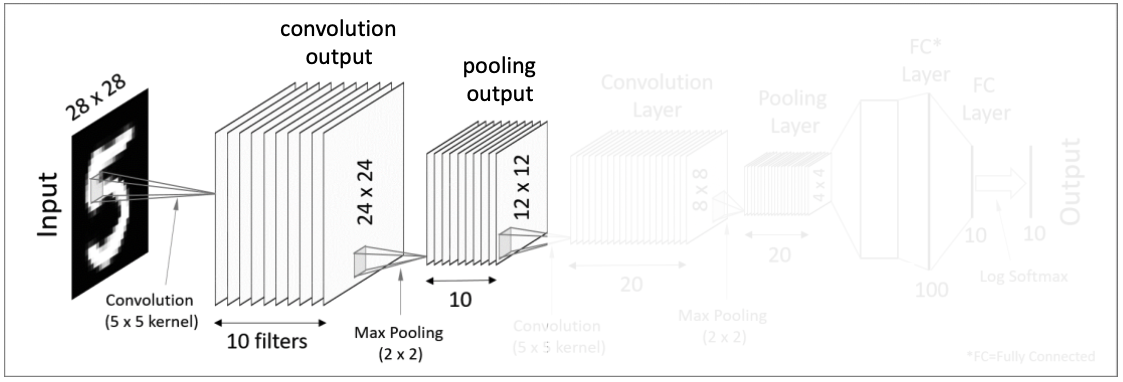
앞의 단계에서 우리는 convolution을 통해 하나의 이미지에서 10개의 이미지 결과값이 도출되어버렸다.
이렇게 되면 값이 너무 많아진다는 문제가 생긴다. 그래서 고안된 방법이 Pooling이라는 과정이다.
Pooling은 correlation이 낮은 부분을 삭제하여 각 결과값의 차원을 축소해 준다.
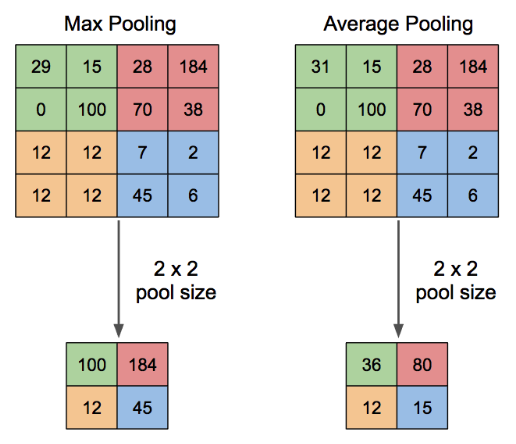
네트워크 구조 이미지를 다시 보면 Pooling Layer을 거쳐 결과값이 10개의 24x24 행렬에서 10개의 12x12 행렬로 준 것을 확인할 수 있다.
3. 두 번째 Convolutional Layer
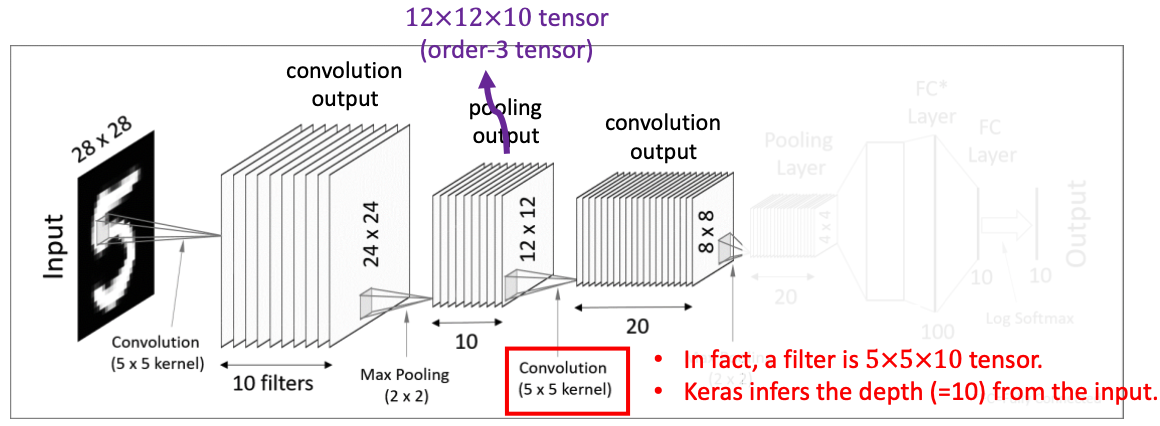
이번 convolutional layer에서는 tensor convolution을 적용한다.
12x12x10 tensor에 5x5 커널 10개(=5x5x10 tensor)를 사용하여 8x8 matrix 20개를 얻어낸다.
4. 두 번째 Pooling Layer
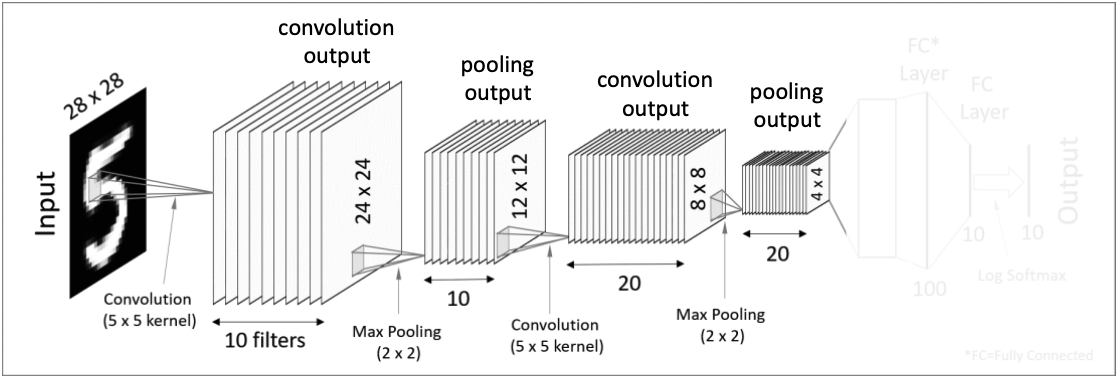
2번째 과정과 동일하게 Pooling 과정을 처리하여 8x8x20 tensor를 4x4x20 tensor로 줄여준다.
5. Flatten(Vectorization)
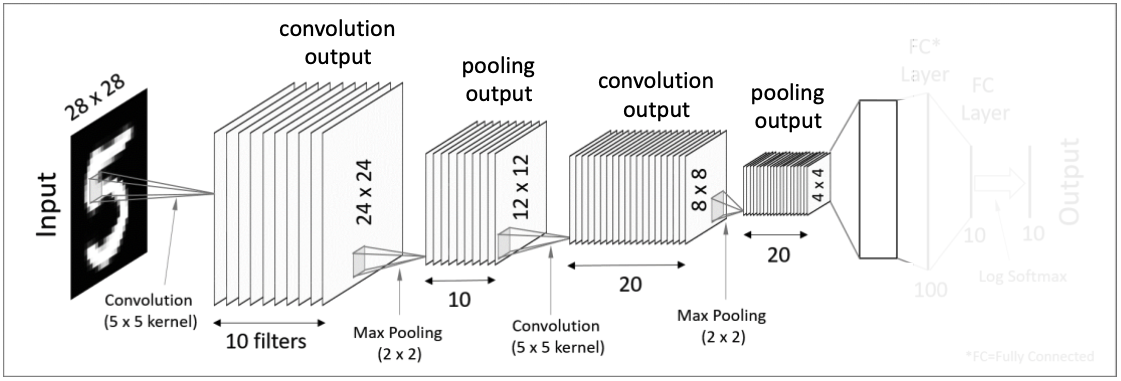
4x4x20 tensor를 일렬로 쭉 세워두어 320차원을 가진 벡터(vector) 형태로 바꾼다.
두 번째 pooling을 통해 얻어낸 4x4 이미지들은 이미지 자체라기보다는 입력된 이미지에서 얻은 특이점 데이터가 되기 때문에 1차원 벡터 데이터로 변형시켜주어도 무관한 상태가 된다.
6. Fully-Connected Layers
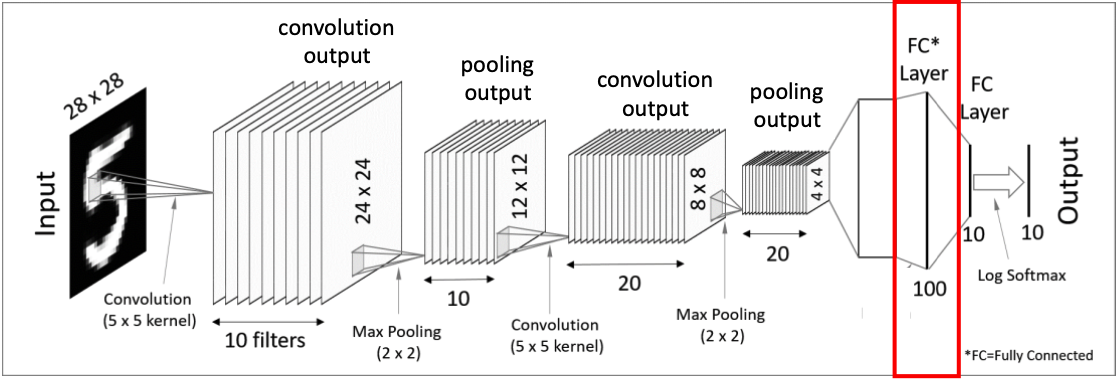
마지막으로 하나 혹은 하나 이상의 Fully-Connected Layer를 적용시키고 Softmax activation function을 적용해주어 최종 결과물을 출력한다.
앞선 Convolution과 pooling은 특징 추출을 위한 작업이고, Flatten과 Fully-Connected Layer는 분류 작업을 하는 것이다.
- Flatten Layer: 입력 데이터의 shape 변경
- Softmax Layer: classification 수행
Convolution과 Pooling을 반복적으로 사용하며 불변하는 특징을 찾고, 그 특징을 입력 데이터로 Fully-connected layer에 보내 Classification을 수행한다.
CNN의 Hyperparameters
- convolution 필터의 개수
- 보통 pooling layer를 거치면 1/4로 출력이 줄어들기 때문에 convolution layer의 결과인 feature map의 개수를 4배 정도 증가시키면 된다.
- 필터의 크기
- 작은 필터를 여러 개 중첩하면 원하는 특징을 더 돋보이게 하며 연산량을 줄일 수 있다.
- 대부분 3x3 크기를 중첩해서 사용한다.
- padding 여부
- padding을 사용하면 입력 이미지의 크기를 줄이지 않을 수 있다.
- stride
- 값이 커질수록 결과 데이터의 사이즈가 작아진다.
- pooling layer의 종류
🔮 레퍼런스
https://halfundecided.medium.com/딥러닝-머신러닝-cnn-convolutional-neural-networks-쉽게-이해하기-836869f88375
https://rubber-tree.tistory.com/116
