나는 DL모델을 주로 파이토치를 이용해서만 사용해왔다. 파이토치로 내가 모델을 구성한이후 loss.backward()를 이용해서 모델의 가중치를 업데이트 하는 방식을 사용해왔었다. 또한 pytorch_lightning을 이용해서 모델을 훈련시켜보기도 했다. 각각에 대한 내용도 상기해서 추후 포스팅에 정리를 해두겠다. 하지만 AICE자격증에서는 TensorFlow를 이용해서 모델을 훈련시키는데, fit()을 사용해서 간단하게 훈련을 시킬 수 있고, 아직 많은 분야에서 TF를 많이 쓰고 있긴 하기 때문에 기본적인 내용을 알아두는 것이 괜찮을 것이라고 생각했다. 그렇다면 시작해보겠다.
DNN
DNN은 Deep Neural Network로써 여러개의 hidden layer가 존재하는 Neural Network이다.
ANN, 즉 Artificial Neural Network와의 차이점은 hidden layer가 하나만 존재하면 ANN 2개이상 존재하면 DNN이다.
이미지출처
너무 많이 봐온 그림이다. 이러한 DNN의 구현을 TensorFlow에선 어떻게 구현할까? 먼저, 필요한 element들을 라이브러리로부터 import 해오겠다.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Activation,Dropout그 이후 tensorflow는 Sequential()이라는 모델 구성요소를 담는 Container를 정의하고 Sequential 클래스 메소드인 add를 통해서 layer를 추가하면 된다. 다음과 같이 수행하자
model = Sequential()
model.add(Dense(4,activation = 'relu',input_shape=(18,)))
model.add(Dense(3,activation='relu'))
model.add(Dense(1,activation='sigmoid'))첫번째로 추가시켜준 Dense Layer에는 input_shape parameter를 정의해줘야 한다. 여기에는 18개의 feature가 들어오는 것으로 돼있다.
모델 구성요소를 확인하기 위해서는 summary()클래스 메소드를 사용해주면 된다.
model.summary()

이진분류
우리는 train과 test set에 모델을 fitting시켜주기 전에 compile과정을 거쳐야 하는데 compile과정은 optimizer,loss,metrics 를 model에 wrapping시켜주는 과정이다. 다음과 같이 진행한다.
model.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])- loss: 손실함수로써 훈련셋과 연관되어 훈련에 사용한다.
- metric: 평가지표로써 validation set과 연관돼어 훈련과정을 모니터링 하는데 사용한다.
이 metric은 모델 가중치의 업데이트에는 영향을 미치지 않는다.
우리는 실습단계에서 validation set으로 test set을 사용했는데, 실상은 이렇게 사용하면 안된다.
하지만.. 시험이고 강의에서 둘다 그렇게 사용했으니깐 그렇게 사용하도록 해보자..
실제론 train set으로부터 validation set을 따로 분리한 이후 validation set으로 부터 모델 파라미터들을 조정한후 validation set까지 합쳐서 train set을 새로 만들고 이를 재학습 시켜서 최종적으로 test set으로 성능을 파악해야한다.
일단 model fitting을 진행해보겠다.
from tensorflow import keras
from keras.callbacks import ModelCheckpoint, EarlyStopping
early_stopping = EarlyStopping(monitor = 'val_loss',patience = 10) # 조기종료 함수
checkpoint = ModelCheckpoint(checkpoint_path, save_weights_only = True,
monitor = 'val_loss', verbose = 1,save_best_only = True)
history = model.fit(X_train,y_train,
validation_data = (X_test,y_test),
epochs = 20,
batch_size = 16,
callbacks = [early_stopping,checkpoint])보통의 경우 여기서 fitting을 진행한후 model의 predict 메소드를 활용해서 X_test를 예측하곤 하는데, AICE 강의에서는 훈련되는 과정을 보여주었다. 따라서 내가 예측을 진행해보았다.
절대로, X_test를 validation set으로 사용한 모델을 이용해서 X_test를 예측해선 안된다.
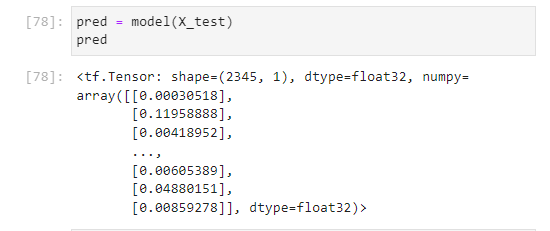
위의 출력결과를 보면 확률이 출력됨을 확인할 수 있다. sigmoid의 결과로써 1일 확률을 출력한 것이다.
1일 확률이라고 해석하는 이유는 무엇일까? 우린 우선 이진분류를 수행하는 중이다. 또한 LossFunction으로 binary-crossentropy를 사용한다.
우선 loss를 최소로 만든다는 그 근간만 잊지 않으면 y=1일 경우 우리는 이 1에 가까워야지 loss가 0에 가까워질 것이고, y=0일 경우 이 0에 가까워야지 loss가 0에 가까워 질 것이다. 따라서, 우리는 sigmoid의 출력결과가 1일 확률을 예측하는 것이라고 해석할 수 있다.
→ 실제로 확률이 아닌 분류를 수행하고 싶으면 예측한 확률을 가지고 threshold(기준)을 세워서 분류를 수행할 수 있을 것이다.
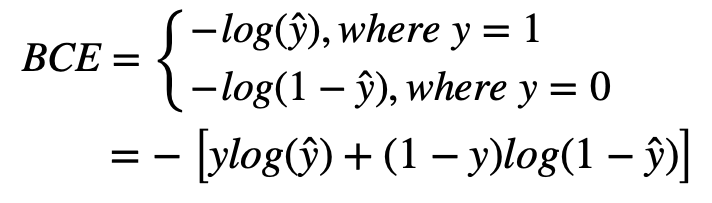
다시 돌아와서 우리는 fitting을 시킨 이후 history객체를 반환하는데 이 history객체는 loss값과 metric값에 대한 레코드를 유지한다.
model을 fit시키는 과정은 내가 model의 variable을 찍어보니깐 in-place로 fitting이 되는 것 같다.
다중분류
다중분류는 마지막 Dense Layer에 activation을 softmax를 사용한다.
-> 아래는 categorical_crossentropy식
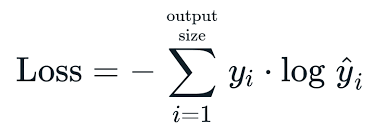
위의 Binary Cross entorpy식도 그렇고 이것도 그렇고 앞에 N이 붙은경우 식이 있고 그렇지 않은 경우의 식이 인터넷에 존재하는데, 아마 내 생각엔 Batch로 처리할때의 표현을 나타낸 것으로 보인다. (정확한건 교수님께 여쭤보고 확인해보겠다)
activaiton설정
- 마지막 출력층에 Label의 열이 하나고 두 개의 값으로 이루어진 이진분류라면
sigmoid - Label의 열이 두개 이상이라면
softmax
loss설정
- 출력층 activation이
sigmoid인 경우:binary_crossentropy - 출력층 activation이
softmax인 경우:- 원핫인코딩(O):
categorical_crossentropy - 원핫인코딩(X):
sparse_categorical_crossentropy
- 원핫인코딩(O):
metrics를 'acc' 혹은 'accuracy'로 지정하면, 학습시 정확도를 모니터링 할 수 있습니다.
일반적인 경우 분류문제에서 마지막 Dense Layer에 activation 모델 구성은 다음과 같이 된다.
여기선 아까전
from tensorflow.keras.layers import Dropout을 import한 것을 상기시켜서 Dropout 또한 적용해보겠다.
→ 드롭아웃도 layer니깐 그냥 add로 추가해주면 된다.
model = Sequential()
model.add(Dense(4, activation = 'relu', input_shape = (18,)))
model.add(Dropout(0.3))
model.add(Dense(3, activation = 'relu'))
model.add(Dropout(0.3))
model.add(Dense(2, activation = 'softmax'))Dropout을 통해 30퍼센트의 노드만이 살아남아서 propagating되도록 했다. model.summary()를 찍으면 다음과 같다.
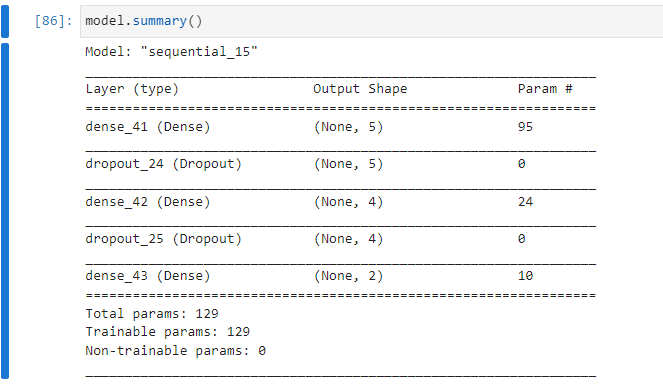
compile and fit
model.compile(optimizer = 'adam',
loss = 'sparse_categorical_crossentropy',
metrics = ['accuracy'])
history = model.fit(X_train,y_train,
validation_data = (X_test,y_test),
epochs = 20,
batch_size = 16)위에서 수행한 모델도 2진 분류 모델이지만 각각의 class에 대해서 확률이 나오도록 하였다 실제로 predict를 통해서 값을 찍어보면 다음과 같이 나온다.
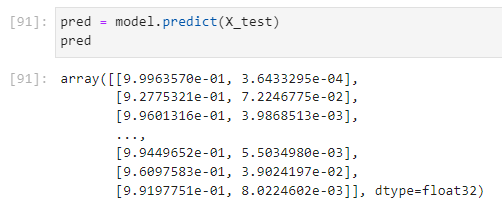
history 객체 plot
history객체의 history attribute는 loss와 metrics score에 대한 epoch별 record를 가지고 있다. 따라서 이를 데이터 프레임으로 만들고 그리고 싶은 Feature에 대해서 plot 메소드를 사용하면 간단하게 그릴 수 있다. 다음과 같이 말이다.
record = pd.DataFrame(history.history)
record['accuracy'].plot()
record[['loss','val_loss']].plot()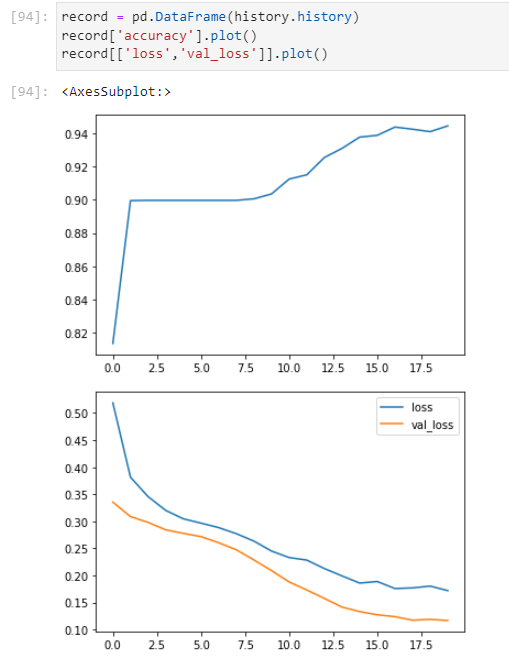
history.history는 딕셔너리를 가지고 있다.

matplotlib을 활용해 더 이쁘게 꾸밀 수도 있을것이다.
여기서 sparse_categorical_crossentropy를 사용한 이유는 우리가 더미변수를 만들면서 one-hot encoding을 할때 다음과 같이 encoding을 했기 때문이다.
pd.get_dummies(data = df, columns = cal_cols, drop_first = True)여기서 drop_first parameter는 여러개의 category를 one hot encoding 시킬때, 0으로 채워진 녀석들도 포함 시킬건지의 여부이다. 이로써 원래 N개의 category에 대해서 N개의 one-hot encoding vector가 나올것을 0까지 포함해서 N-1개의 vector가 나오게 된다.
CNN
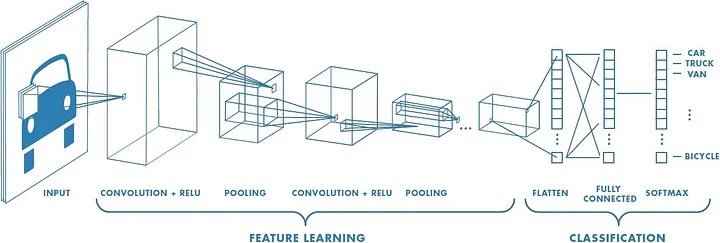
image의 기본 shape는
height,width,channel로 구성돼있다. 다음은 파일을 읽어와서 image를 decod하는 코드이다.
gfile = tf.io.read_file(clean_img_path)
# tensorflow.inputoutput.read_file path에서 file을 읽어오고
print(type(gfile))
image = tf.io.decode_image(gfile, dtype=tf.float32)
# image를 decode한다.
실제로 image를 출력해보면 다음과 같다
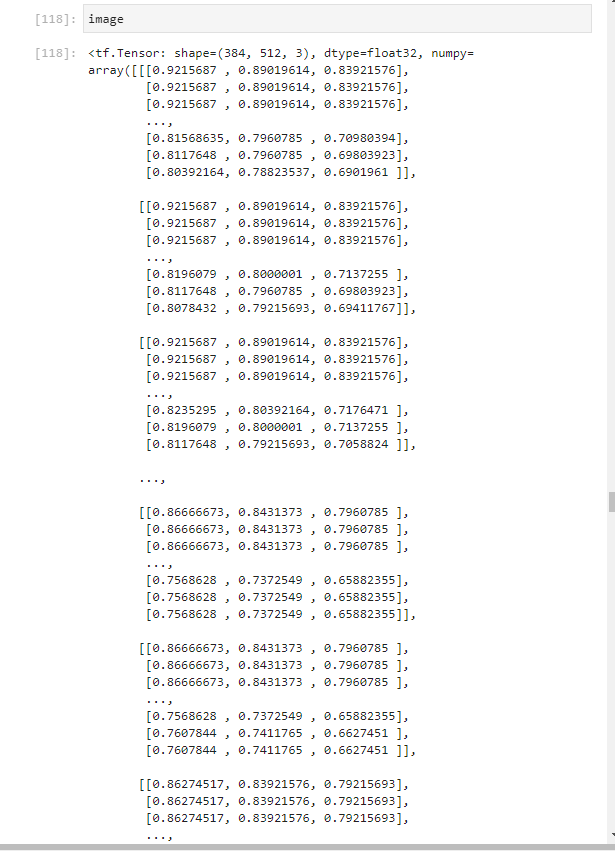
각각의 channel(RGB)값이 하나의 element(pixel)을 구성하고 그 element가 512개가 모여 하나의 line을 구성하고 그 line이 다시 384개가 모여 하나의 image를 구성함을 알 수 있다.
우리는 이런 image 데이터 특성을 이해하는 이유는 image 데이터를 전처리 하기 위해서이다.
자 다시 위에 진행한 DNN을 생각해보자. 우리는 DNN에서
from sklearn.model_selection import train_test_split을 통해 train set과 test set을 구분했던걸 기억할 것이다. 그런데 이미지 데이터셋은 어떻게 구분할까? 이를 위해선 tensorflow에서 제공하는 ImageDagaGenerator객체를 사용하여야 한다. 이는 tensorflow.keras의 preprocessing.image에 존재한다. 따라서 다음과 같이 import를 수행하면 된다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
이를 통해 우리는 Image 데이터를 scaling 함과 동시에 validation_split인자를 사용해 이미지를 train set과 test set으로 나눌수 있다.
물론 이 방법 외에도 나눌 수 있는 방법이 있을 것이다. 나의 주전공이 CV가 아니기 떄문에, CNN에 익숙치 않아서, 강의에서 알려주는 방식을 좀더 detail하게 기술할 뿐이다. 나중에 알게되면 추가 포스팅을 작성하겠다.
다시 돌아와서 위의 방식으로 나누기 위해선 generator를 우선 두개를 생성한다.
training_datagen = ImageDataGenerator(rescale = 1./255, validation_split = 0.2)
test_datagen = ImageDataGenerator(rescale = 1./255, validation_split = 0.2)이 generator의 flow_from_directory메소드를 사용하여서 pytorch의 DataLoader처럼 데이터가 세팅됨을 알 수 있다. 즉, Batch형태로 묶어주는 역할을 수행한다 코드는 다음과 같다.
# Generate Batch ImageDataGenerator객체의 메소드이다.
training_generator = training_datagen.flow_from_directory(
'./IMAGE/dataset-clean,dirty/',
batch_size=batch_size,
target_size=(384, 512), # 타겟 이미지의 사이즈 확인
class_mode = 'categorical', # binary , categorical
shuffle = True,
subset = 'training' # training, validation. validation_split 사용하므로 subset 지정
)
# 데이터 증강과정인 ImageDataGenerator에서 validation_split을 사용했다면
# subset을 training으로 설정해 줘야지 제대로 설정된다.(이 주피터 노트북에서는 test의 validation set을 사용하는게 좀 이상하긴 하다.
# class_mode를 통해 생성된 데이터셋이 가질 target label의 형태를 설정하는 것으로 categorical은 2D형테의 원-핫 인코딩 label이고 binary는 1D형태의 이진 label이다.
# Pytorch의 DataLoader와 비슷한 역할을 하는 것으로 보이는데, 구체적으로는 하위 디렉토리에 있는 모든 image데이터를 Image증강 단계인 ImageDataGenerator의 규격에 맞추어 가져온다.
test_generator = test_datagen.flow_from_directory(
'./IMAGE/dataset-clean,dirty/',
batch_size=batch_size,
target_size=(384, 512), # 사이즈 확인
class_mode = 'categorical', # binary , categorical
shuffle = True,
subset = 'validation' # training, validation. validation_split 사용하므로 subset 지정
)여기서 Batch형태로 묶을 경우에, batch_size = 4라고 하면, 크기가 어떻게 될까 궁금해서 찾아봤는데 그저 차원이 하나 늘었을 뿐이다. 다음과 같이 차원이 나온다.
batch_samples = next(iter(training_generator)) print(batch_samples[0].shape) print(batch_samples[0][0].shape) #4d batch에서 cube의 형태를 유추할 수 있다. print(batch_samples[1]) # 위에서 설정한대로 target label이 2D형태의 원-핫인코딩이 됐음을 확인할 수 있다. batch_samples를 출력하면 tuple이 나오는데 첫번째는 Batch가 나오고 두번째는 Target class가 나오는것을 확인할 수 있다. # 여기서 class는 해당이미지가 속한 폴더의 이름을 의미하는 것 같다. # binary로 바꿀경우 다음과 같은 형태가 나온다. [1. 1. 1. 1.]
이제 CNN모델링을 시작해보자.
CNN모델링
CNN도 마찬가지로 convolutional layer와 pooling layer가 존재해서 각 Feature의 특징을 뽑아내고 그들을 합치는 과정을 거친다. 확인해보자.
import tensorflow as tf
from tensorflow.models import Sequential
from tensorflow.layers import Conv2D,MaxPooling2D,Dense,Flatten,Dropoutmodel = Sequential()#1
model.add(Conv2D(filters= 32, kernel_size =3,activation='relu', input_shape= (384,512,3))#2
model.add(MaxPooling2D(pool_size = 2))#3
model.add(Conv2D(filters= 16, kernel_size = 3, activation='relu'))#4
model.add(MaxPooling2D(pool_size = 2))#5
model.add(Flatten())#6
model.add(Dense(50,activation='relu'))#7
model.add(Dense(2,activation='softmax'))#8#1 container 생성
#2 kernelsize = 3-> 3x3 커널로 filters = 32->32개의 filter를 만들어서 이미지를 훑는다(합성곱 한다).
#3 합성곱해서 나온 이미지를 2x2 커널로 MaxPooling을 진행한다.(height와 width가 각각 2씩 줄어들것이다.)
#4 그렇게 해서 나온 이미지를 다시 16개의 filter를 만들어서 kernel_size 3x3으로 훑는다.(합성곱한다.)
#5 합성곱해서 나온이미지를 MaxPooling한다.
#6 그렇게 해서 나온 요소들을 쭉 펼친후
#7~#8 DNN에 투입하여 분류를 수행한다.
model compile& fit
#model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate),
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# fit을 하기전에 거쳐야 하는 과정
history = model.fit(training_generator,
epochs=20 ,
steps_per_epoch = len(training_generator) / batch_size,
validation_steps = len(test_generator) / batch_size,
validation_data=test_generator,
verbose=1
)steps_per_epoch와 validation_steps는 학습과 평가를 조절하는 인자이다.
steps_per_epoch: 에포크마다 모델을 통과할 Batch Step
→ 한번의 에포크마다 몇개의 Batch를 통과시킬 것이냐
validation_steps: 각 Epoch마다 검증을 수행할 Batch의 갯수
→ 이를 통해 더 빠른 Validation을 도모한다.
성능시각화
위의 DNN과 비슷한 방식으로 수행하면 된다.
RNN
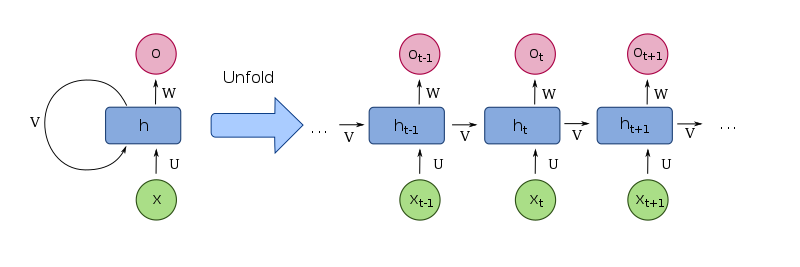
{kind=link}
#RNN 라이브러리 임포트
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, FlattenRNN은 데이터를 axis = 1에 데이터를 넣어줘야한다.
즉, 다음과 같이 구성시켜야한다(pytorch와 동일)
X_train = X_train.reshape(-1,18,1)
X_test = X_test.reshape(-1,18,1)model = Sequential()
model.add(LSTM(32, activation='relu', return_sequences=True, input_shape=(18, 1)))
# lstm의 hidden state크기라고 research에서 표현할 수 있지만, tf에서는 unit의 output크기라고 표현
# return_sequences
model.add(LSTM(16, activation='relu', return_sequences=True))
model.add(Flatten())
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))return_sequences=True라고 설정하면 모든 시점의 hidden_state를 출력한다.
따라서 위에는 모든시점의 hidden_state를 출력하고 DenseLayer에 넣는것으로 보면 된다.
model compile and fit
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# compile은 optimizer loss, metric을 정의한다.
history = model.fit(x=X_train, y=y_train,
epochs=10 , batch_size=128,
validation_data=(X_test, y_test),
verbose=1
)성능 시각화
위에 DNN과 똑같이 진행하면 된다.
