나는 주로 다루는 것이 파이토치 딥러닝을 주로 다루어 왔다. 이번 방학에 기본기를 다지고자 AICE자격증을 신청했고, pandas와 matplotlib seaborn에 대해서 기본기를 숙달하기 좋은 기회였다. 그에 비해 너무나 방대한 ML DL은 사용해보는 정도의 수준에 머물렀는데, DL은 익숙한 편이지만 ML은 예전에 해보고 까먹었기 때문에 내가 추가로 내용을 조금씩 정리해보면서 복습해보겠다.(이론의 완벽한 정리를 하는 것은 아니지만 핵심만 집어보겠다. 혹시나 틀린 것이 있다면 알려주시면 감사하겠습니다 !)
M.L
Train데이터 Test데이터 split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.3,
stratify=y,
# y를 기준으로 비율을 나누는 것이다.
random_state=42)astratify는 target의 각 category의 비율을 train test 비율에 맞춰서 동등하게 나눠주는 역할을 한다. 이를 통해 한쪽에 데이터가 몰릴경우 맞추지 못하는 현상을 방지한다.
Scaler
데이터의 scaling은 각 Feature의 영향이 수치적인 크기에 따라서 좌지우지 되는 것을 막고자 사용한다.
StandardScaler: 우리가 아는 표준정규분포로 정규화 할때 사용하는 공식을 사용하여 정규화한다.
MinMaxScaler: Min값과 Max값을 이용해 정규화를 진행하는데 0~1사이의 값으로 나오도록 한다.
from sklearn.preprocessing import MinMaxScaler
import는 sklearn의 preprocessing에서 진행하고 유의할점은 다음과 같다.
train데이터를 이용해
fit_transform을 진행해서 scaler가 train데이터의 정보를 이용해서 fit하고 transform할 수 있도록 하고, 이 train데이터의 정보를 이용해서 test데이터를 scaling해야한다.
train, test데이터를 위와 같이 나누는 이유는 train set에 test set의 정보가 안 흘러들어가도록(Data Leakage)를 방지하기 위해서이다.
Logistic Regression
분류를 위한 회귀로써 회귀를 수행하고 나서(
y = a1x1+a2x2+ ... + 식으로 만들고 나서)
y값을 sigmoid function에 넣음으로써 분류를 수행한다. 이때, loss함수는 크로스 entrophy함수를 사용한다. 이 loss를 낮출 수 있도록 계수를 줄인다.
참고할만한 링크를 달아두겠다.
블로그
위의 Logistic Regression을 사용하기 위해서는 sklearn의 linear_model을 사용하면 된다.
from sklearn.linear_model import LogisticRegression
lg = LogisticRegression(C=1.0, max_iter = 2000)
lg = lg.fit(X_train,y_train)
# 강의에서는 fit하고 다시 재할당을 해주지 않았지만, 나는 일관성을 위해 하겠다.parameter 소개
C는 regularization strength의 역수로써 작으면 작을수록 가중치에 더 강한 regularization이 적용된다.
parameter 중에solver가 있는데 solver는 gradient descent를 기반으로 한 weight를 최적화하는 유형들을 구분한 것이다.
max_iter은 이러한 solver의 최적화 방식을 몇번 수행할것인지 정해주는 것이다.(epoch와 유사한 의미로 보인다.)
metrics(accuracy, precision, recall, f1 score)
import하는 방법은 다음과 같다.
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
accuracy_score: 모델이 정답을 맞춘것의 비율
precision_score: 모델이 True로 예측한 데이터중 실제로 True인 데이터
recall_score: 내일 눈이 내릴지 아닐지를 예측하는 모델이 있다고 해볼떄, 이 모델이 항상 False를 출력하게 한다면 꽤 좋은 예측 성능을 보장할 수 있을 것이다.
이러한 상황을 방지하기 위해 실제로 True인 데이터를 모델이 True라고 인식한 데이터의 비율인 recall_score를 확인하여야 한다.
f1 score: 정밀도 + 재현율
위의 정밀도와 재현율은 trade-off 관계가 있어서, 이 둘을 모두 평가하기 위해서는
그 둘을 조화평균으로 엮은 F1 Score를 확인해보면 된다.
KNN(K-Nearest Neighbor)
어떤 데이터를 기준으로 그 주변을 확인해서 더 많은 이웃이 속한 클래스로 판정하는 것이 KNN이다.
import는 다음과 같이 수행한다.
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 5)
knn.fit(X_train,y_train)DecisionTree
DecisionTree는 feature_importance를 제공하고 좋은 성능을 보인다는 점에서 훌륭하다.
classfier 혹은 Regression 둘다로 사용할 수 있다.
간단하게 Regression은 영역에 포함되는 element들의 평균을 사용한다고 생각하면 된다.
먼저 DecisionTreeClassifier를 사용해보겠다.
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(max_depth = 10, random_state = 42)
tree.fit(X_train,y_train)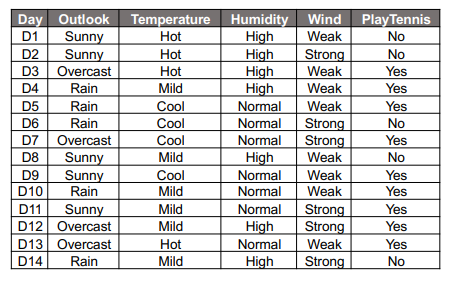
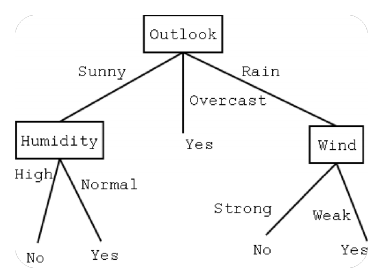
위의 두사진을 보면 감이 안올 것이다. 이는 내가 정리한 XAI word파일에 tree의 feature_importance를 구하는 방식을 정리해놓은 것을 보아야하는데, 우선 tree가 분기하는 방식이 entropy를 제일 낮추는 feature를 선택한다는 것을 기억하자.
전체적인 데이터를 보고 위에 overcast에 해당하는 것들이 yes임을 확인하고, 나머지 feature에 대해서도 확인하는 방식으로 fitting을 진행한다.
parameter
파라미터로는 위에서 max_depth가 사용됐는데 말 그대로 트리의 최대 깊이를 의미한다.
이외에도, 각 노드와 leaf가 가져야할 sample의 최소갯수를 지정해주는 파라미터 등이 있다.
Ensemble
앙상블은 약한힘을 발휘하는 모델 여러개가 강한힘을 발휘하는 모델 한개보다 좋을 것이라는 발상에서 나왔다.
앙상블 기법의 종류
배깅 (Bagging):
여러개의 DecisionTree 활용하고 샘플 중복 생성을 통해 결과 도출. RandomForest
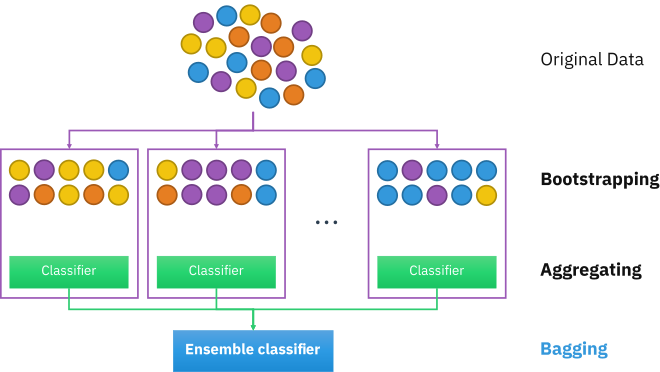
사진 출처
Bootstrap은 통계학에서 사용하는 용어로, random sampling(복원추출)을 적용하는 방법으로써 복원추출을 통해서 training data를 늘린다. 즉, Bagging은 Bootstrap을 통해서 얻은 train_data로 각각의 모델을 학습시킨 이후 각각의 예측을 categorical의 경우 투표로 집계하고 continuous의경우 평균으로 집계된다.
RandomForest
random forest를 한번 사용해 보겠다.
주요 Hyperparameter
- random_state: 랜덤 시드 고정 값. 고정해두고 튜닝할 것!
- n_jobs: CPU 사용 갯수
- max_depth: 깊어질 수 있는 최대 깊이. 과대적합 방지용
- n_estimators: 앙상블하는 트리의 갯수
- max_features: 최대로 사용할 feature의 갯수. 과대적합 방지용[한번에 분기할 기준으로 사용할 feature갯수]
- min_samples_split: 트리가 분할할 때 최소 샘플의 갯수. default=2. 과대적합 방지용
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(n_estimators = 30, max_depth = 10, random_state = 42)
rfc.fit(X_train,y_train)부스팅 (Boosting):
약한 학습기를 순차적으로 학습을 하되, 이전 학습에 대하여 잘못 예측된 데이터에 가중치를 부여해 오차를 보완해 나가는 방식. XGBoost, LGBM
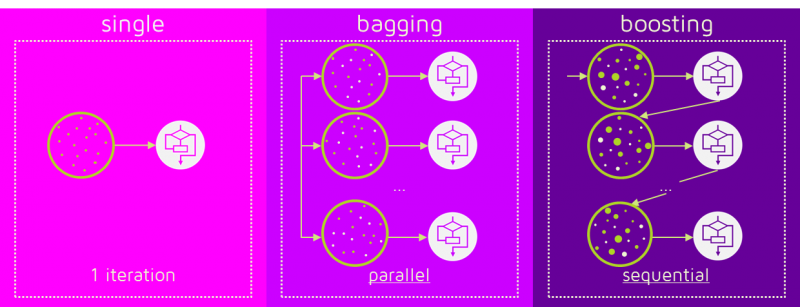
이미지 출처
Boosting도 bootstrap을 통해 충분한 데이터를 확보하고 학습 알고리즘을 순차적으로 학습시킨다.
내가 이해한 바대로 작성해보겠다. 먼저 모델에 sequential한 특징을 부여한 것이 첫번째 Boosting계열 모델의 특징이다. 모든 모델은 학습하기전에, 데이터를 bootstrap하고, 학습을 통해 예측을 수행한다. 예측을 수행한후 target과의 error를 구한이후 그 에러를 바탕으로 데이터에 가중치를 곱해준다.(한 weekly 학습기가 학습할 때 Bootstrap추출된 데이터에 대해서 동일한 가중치를 곱한다.) 그 이후 이 에러를 바탕으로 모델 가중치(초기화는 1/(약한학습기의 개수)를 조정한다.
그 다음 모델은 앞서서 잘 분류하지 못한(가중치가 곱해진) 데이터를 더욱 심도있게 살펴보아서 그들을 잘 분류할 수 있는 모델을 만들고 이 모델에 대해서도 모델 가중치를 구한다.
이렇게 구한 n개의 모델을 additive model로 만들어서 최종적으로 예측을 수행한다.
Adaboost는 Decision Tree를 약한학습기로 사용하고 있기 때문에 entrophy를 최적화하는 방식으로 학습한다.(Not gradient descent)
GBM(Gradient Boosting Machine)은 adaboost와 유사하지만 경사하강법을 사용한다. 경사하강법을 사용하는만큼 예측성능은 좋지만 과적합이 될 가능성이 높다.
이문제를 해결하고자 한게
XGBoost: GBM에 기반한 것으로 GBM에 regularization term을 추가했다. 병렬학습이 가능하고다.
LightGBM: LightGBM은 최적의 리프만을 계속해서 분할하는 Leaf-wise tree growth방법을 사용한다.
각각이 큰 주제이기 때문에 여기선 이정도만 알고 넘어가겠다.
xgboost
xgboost는 sklearn에서 제공하지 않기 때문에, 따로 install해주어야 한다. 다음과 같이 install하고 사용한다.
주요 Hyperparameter
- random_state: 랜덤 시드 고정 값. 고정해두고 튜닝할 것!
- n_jobs: CPU 사용 갯수
- learning_rate: 학습율. 너무 큰 학습율은 성능을 떨어뜨리고, 너무 작은 학습율은 학습이 느리다. 적절한 값을 찾아야함. n_estimators와 같이 튜닝. default=0.1
- n_estimators: 부스팅 스테이지 수. (랜덤포레스트 트리의 갯수 설정과 비슷한 개념). default=100
- max_depth: 트리의 깊이. 과대적합 방지용. default=3.
- subsample: 샘플 사용 비율. 과대적합 방지용. default=1.0
- max_features: 최대로 사용할 feature의 비율. 과대적합 방지용. default=1.0
!pip install xgboost
from xgboost import XGBClassifier
xgb = XGBClassifier(n_estimator = 3, random_state = 42)
xgb.fit(X_train,y_train)
xgb_pred = xgb.predict(X_test)LightGBM
lightgbm또한 scikit learn에서 제공하지 않기 때문에, 따로 install해주어야 한다. 다음과 같이 install하고 사용해야한다.
주요 Hyperparameter
- random_state: 랜덤 시드 고정 값. 고정해두고 튜닝할 것!
- n_jobs: CPU 사용 갯수
- learning_rate: 학습율. 너무 큰 학습율은 성능을 떨어뜨리고, 너무 작은 학습율은 학습이 느리다. 적절한 값을 찾아야함. n_estimators와 같이 튜닝. default=0.1
- n_estimators: 부스팅 스테이지 수. (랜덤포레스트 트리의 갯수 설정과 비슷한 개념). default=100
- max_depth: 트리의 깊이. 과대적합 방지용. default=3.
- colsample_bytree: 샘플 사용 비율 (max_features와 비슷한 개념). 과대적합 방지용. default=1.0
- subsample: 샘플 사용 비율. 과대적합 방지용. default=1.0
!pip install lightgbm
from lightgbm import LGBMClassifier
lgbm = LGBMClassifier(n_estimators = 3, random_state = 42)
lgbm.fit(X_train,y_train)
lgbm_pred = lgbm.pred(X_tset)스태킹 (Stacking):
여러 모델을 기반으로 예측된 결과를 통해 Final 학습기(meta 모델)이 다시 한번 예측하는 방법이다. 이는 너무 좋은 포스팅을 찾았기 때문에 공유드리겠다.
K-fold stacking 블로그
Vanilla stacking 블로그
KFold 교차검정으로 stacking을 사용하지 않고 기본적인 stacking의 과정은 다음과 같다.
개별 모델이 예측한 데이터를 기반으로 final_estimator에 종합하여 예측을 수행합니다.
한마디로 final model을 하나두고 그 이전단계에서 각각의 모델이 예측한 예측값을 Feature로써 사용해서 모델을 training시키고 final_model을 이용해 예측하는 경우를 얘기한다.
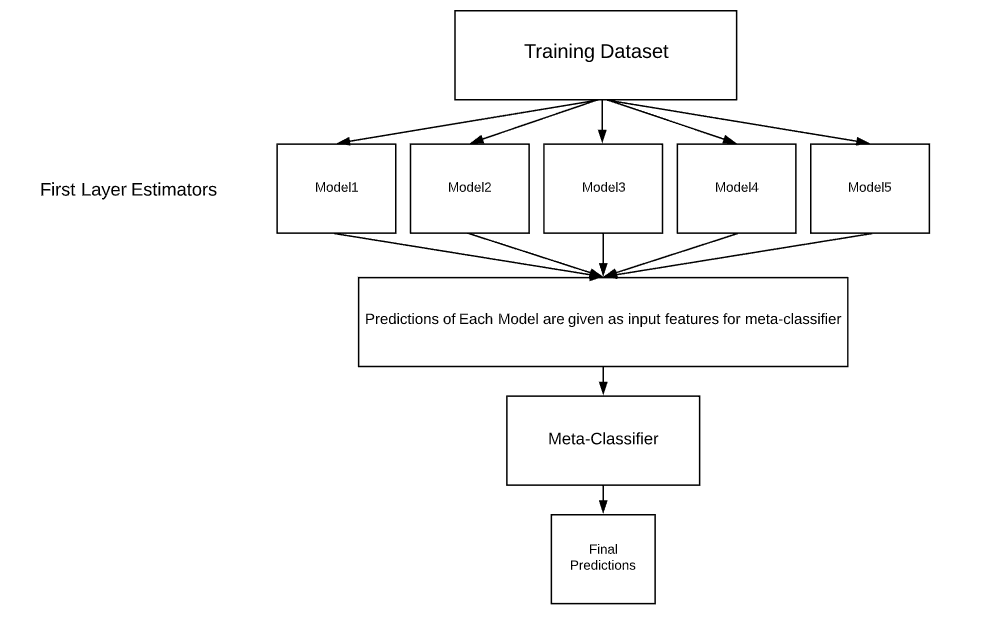
이미지 출처
- 성능을 극으로 끌어올릴 때 활용하기도 합니다.
- 과대적합을 유발할 수 있습니다. (특히, 데이터셋이 적은 경우)
실제로 사용할때는 다음과 같이 사용한다.
from sklearn.ensemble import StackingRegressor, StackingClassifier
stack_models = [
('LogisticRegression', LogisticRegression(C=1.0,max_iter = 1000)),
('KNN', KNeighborsClassifier(n_neighbors = 10)),
('DecisionTree', DecisionTreeClassifier(max_depth = 10)),
]
rfc = RandomForestClassifier(n_estimators = 15)
stacking = StackingClassifier(stack_models, final_estimator=rfc, n_jobs=-1)
stacking.fit(X_train,y_train)원래 AICE강의에서는 학습된 모델을 사용했었는데, 모델의 구조를 보니 쫌 이상해서 아래 자료를 참고해보니 최초의 모델로 stacking을 수행했다.
https://www.kaggle.com/code/marcinrutecki/stacking-classifier-ensemble-for-great-results
Weighted Blending
예측값에 weight를 곱해서 최종 output을 계산한다. 모델에 대한 가중치를 합산이 1이되도록 heuristic하게 조절한다.
final_outputs = {
'DecisionTree': dt_pred,
'randomforest': rfc_pred,
'xgb': xgb_pred,
'lgbm': lgbm_pred,
'stacking': stacking_pred,
}
# \은 줄바꿈의 의미
final_prediction=\
final_outputs['DecisionTree'] * 0.1\
+final_outputs['randomforest'] * 0.2\
+final_outputs['xgb'] * 0.25\
+final_outputs['lgbm'] * 0.15\
+final_outputs['stacking'] * 0.3\
final_prediction = np.where(final_prediction > 0.5, 1, 0)

아주 유용한 정보네요!