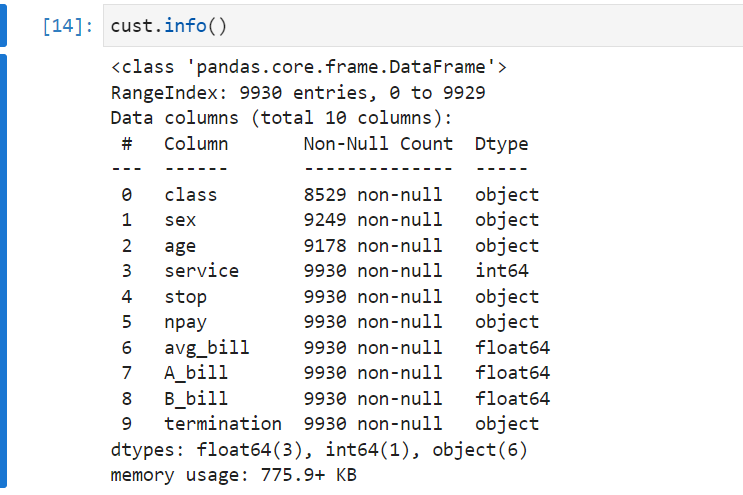
시작해보겠다. 이 주제에 관해서 맨 마지막에 작성하는 이유는 실제로 판다스 라이브러리의 메소드들은 워낙 방대한 내용으로 작성돼있고, 실제로 다양한 name으로 같은 기능을 수행할 수 있기 때문에, 나는 필요한 기능을 그때그때 찾아보고 많이쓰는건 기억하면서 사용해왔었다.
요점은 너무 많은 기능이 존재하기 때문에, 머신러닝이나 딥러닝처럼 이론적인 부분은 거의 없고 기능을 위주로 살펴보아야 한다.
따라서 이번 기회에 이 velog를 작성하고 새로운 것을 알게 될때마다 기능을 업데이트해 나가겠다.
Note! 내 기준 생소한 기능만을 작성할거라 Drop과 데이터프레임 생성 concat등 기본적인 기능들은 실리지 않음을 알고 봐주셨으면 한다.
Pandas

pd.read_csv(path,index_col,usecols,sep)
usecols = []안에 들어가는 column name은 index_col이 작성될경우 포함해줘야 한다.- 가끔 인코딩이
|를 기준으로 뭉뜽그러져 있는 데이터셋이 존재한다. 이에 맞춰서sep=|을 통해 Decoding해줘야 한다.
이외에도
pd.read_를 검색해보면
수많은 파일 형식을 지원함을 확인 할 수 있다.
→ 실제로 Json 형식도 많이 사용된다고 알고 있다.
DataFrame 행 가져오기
DataFrame은 리스트와 같은 mutable한 객체이다.
- 하나의 column을 선택할때
이렇게 작성시 Series 형태
cf> [[]]로 작성해 주면 데이터프레임 형태로 가져온다

- 여러개의 column 선택시
[]로 작성하면 오류가 발생한다.
무조건[[]]로 작성을 해주어야 한다.

- Slicing
→ 데이터프레임에서[]의 기본은column단위이지만
:를 사용하여 slicing을 해주면row단위로 처리를 해준다.

- loc와 iloc
→loc은 name으로 데이터를 가져오고

iloc와 loc의 값 읽기
input_data.iloc[-1]['A'] = 11
이렇게 사용을 하게되면 실제 데이터프레임의 값이 변하지 않는다. iloc를 이용해서 값을 변경하려면 iloc만 사용해야 한다. 따라서 다음과 같이 할 수 있다. 'A' 컬럼의 인덱스가 -1일때
input_data.iloc[-1,-1] = 11
loc또한 마찬가지이다.
→ iloc는 index로 데이터를 가져온다.

loc와 slicing을 결합하여 다음과 같이 사용할 수 있다.[name을 기준으로 생각해보면 자연스러움]

iloc와 slicing을 결합하여 다음과 같이 사용할 수 있다.[index를 기준으로 생각해보면 자연스러움]
Boolean Indexing으로 Filtering하기
DataFrame은 Boolean indexing이 가능한데, 이를 가장 많이 사용하는 것은 조건에 맞게 데이터프레임을 재구성할때 가장 많이 사용한다. AICE에서 제공해주는 데이터가 전처리가 돼있지 않기 때문에 알고있지만 그동안 잘 쓰지 못했던 Boolean Indexing을 경험할 좋은 기회였다.
다음과 같이 indexing을 수행하여서 새로운 데이터프레임을 만들어낸다.

group by
나는 주로 딥러닝 모델을 공부해와서 직접적으로 데이터를 분석해본 경험은 몇번 없다. 따라서 group by를 써볼 기회가 충분치 않았다.
- groupby의 결과는 dictionary의 형태이다.
다음을 확인해보자.
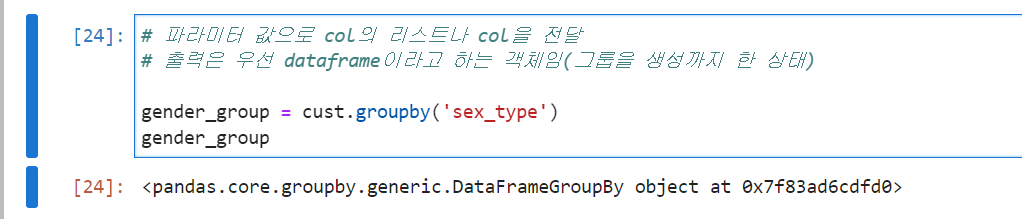
groupby의 groups 속성
- 각 그룹과 그룹에 속한 index를 dict 형태로 표현

나는 My SQL을 경험해봤기 때문에 group by와 aggregation function이 set임을 알고 있다.
groupby의 aggregation function method
- 그룹 데이터에 적용 가능한 통계 함수(NaN은 제외하여 연산)
- count : 데이터 개수
- size : 집단별 크기
- sum : 데이터의 합
- mean, std, var : 평균, 표준편차, 분산
- min, max : 최소, 최대값
e.g.
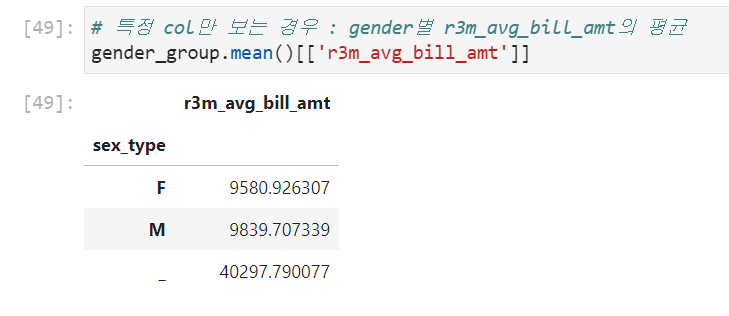
복수 column 을 이용한 groupby
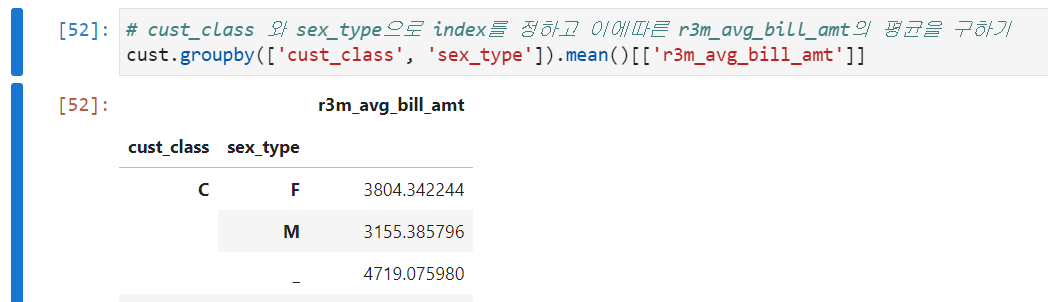
이때 loc를 사용하기 위해서는 Tuple을 이용해서 지정해줘야한다.
# INDEX는 DEPTH가 존재함 (loc을 사용하여 원하는 것만 가지고 옴)
cust.groupby(['cust_class', 'sex_type']).mean().loc[[("C","M")]]
# 튜플을 사용해서 하나의 key로 사용을 해야 한다.set_index()와 reset_index()
미리 데이터프레임을 만들어 놨다면 데이터프레임의 set_index() 메소드를 활용해서 index를 지정할 수 있다.
#set_index로 index셋팅(멀티도 가능)
cust.set_index(['cust_class','sex_type'])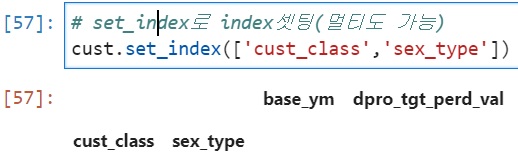
이를 원래대로 돌리기 위해서는 reset_index()를 사용하면 된다.

DataFrame의 level이란?
DF의 level은 바깥에서부터 0,1, .. ,로 읽어 내려가면 된다.
set_index와 groupby 메소드의 level 파라미터를이용한 Group by
ex1>
# 멀티 인덱스 셋팅 후 인덱스 기준으로 groupby하기
# 'sex'와 'cp'를 기준으로 index를셋팅하고 index를 기준으로 groupby하고자 하는경우
# groupby의 level은 index가 있는 경우에 사용
cust.set_index(['cust_class','sex_type']).groupby(level=0).mean()
ex2>
cust.set_index(['cust_class','sex_type']).groupby(level=[0,1]).mean()
groupby의 aggregate메소드를 사용하여 여러개의 집계함수 동시에 사용하기
cust.set_index(['cust_class','sex_type']).groupby(level=[0,1]).aggregate([np.mean,np.sum])
pivot/pivot_table
pivot의 사전 뜻
a fixed point supporting something that turns or balances
-> 고정점
pivot
우리는 데이터 프레임에 고정점들을 두어서 새로운 데이터프레임을 만들 수 있다.
다음과 같은 데이터 프레임을 생성했다고 해보자.
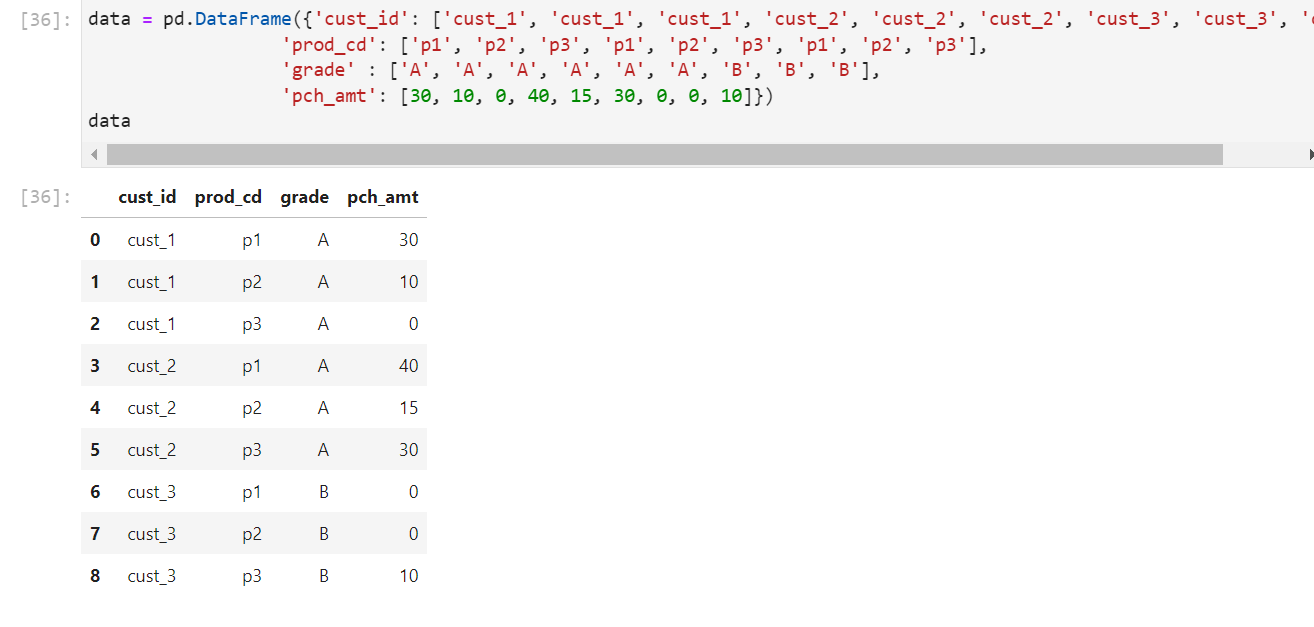
이 데이터프레임은 가독성이 떨어지는 것을 확인할 수 있다. 우리는 이 데이터프레임의 정보를 가독성 좋게 확인하기 위해서 어떤 column set을 index로 어떤 column set을 column으로 할때의 value값을 확인하고자 데이터프레임의 pivot메소드를 사용하여 고정점을 둔후 사용할 수 있다.
e.g.>
data.pivot(index = 'cust_id', columns = 'prod_cd', values = 'pch_amt')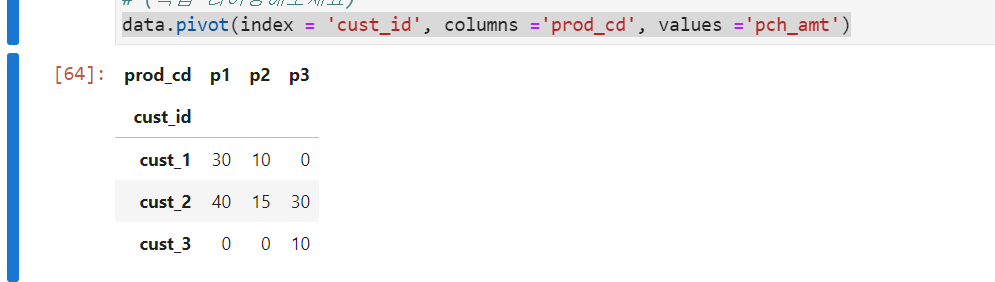

↑ pivot은 dataframe의 형태를 가지고 있음을 확인할 수 있다.
pivot table
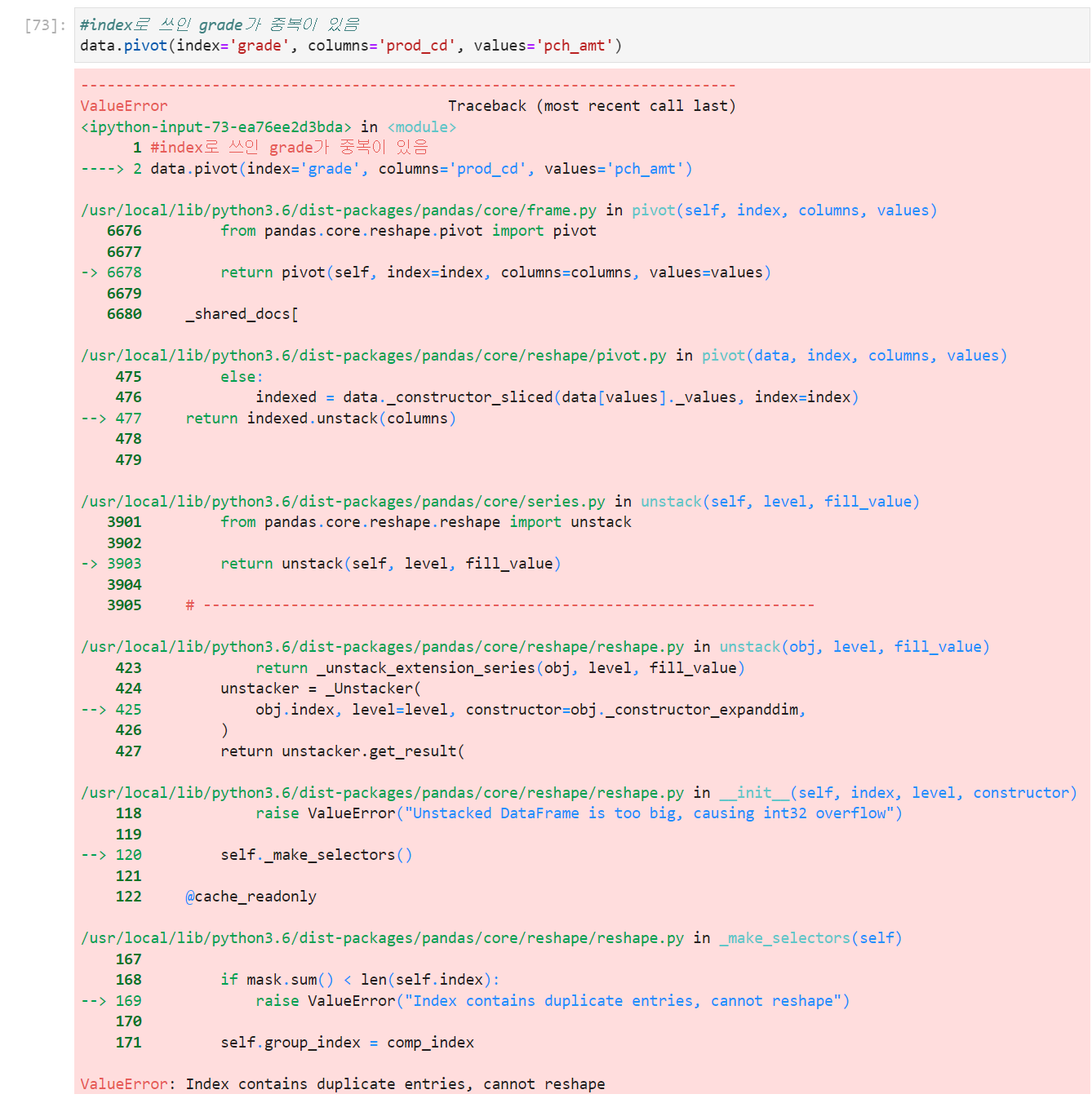
pivot_table은 pivot과 동일하지만 index에 중복이 있을경우aggregation function을 적용할 수 있다.
아래의 예시를 보자.
ex>
pivot()의 경우
pivot_table()의 경우
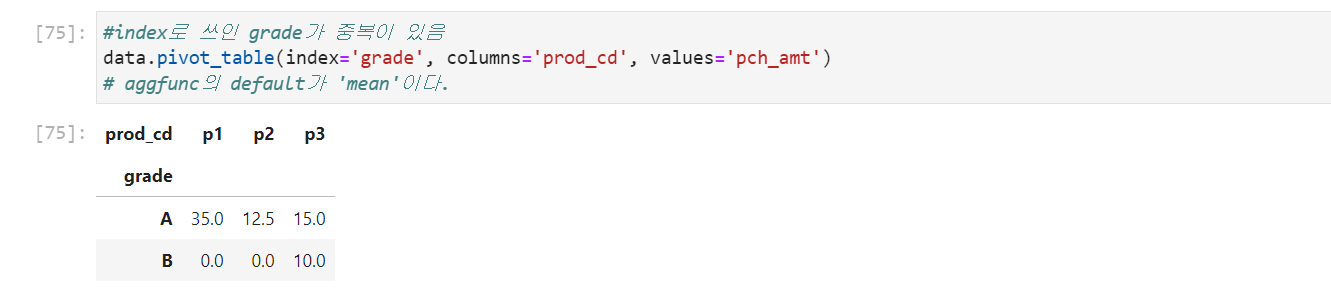
→ pivot은 aggregation function을 사용할 수 없기 때문에 value error를 반환하지만 pivot_table은 사용할 수 있어서 평균값을 리턴하는 것을 확인할 수 있다.
이외에도 aggfunc= 파라미터의 numpy 함수(e.g.np.sum)등을 제공하면 그 함수에 맞추어서 계산을 수행해준다.
데이터프레임 stack()메소드와 unstack()메소드
- stack : 컬럼 레벨에서 인덱스 레벨로 dataframe 변경
- 즉, 데이터를 row 레벨로 쌓아올리는 개념으로 이해하면 쉬움
- unstack : 인덱스 레벨에서 컬럼 레벨로 dataframe 변경
- stack의 반대 operation
- 둘은 역의 관계에 있음
다음 데이터 프레임을 생각해보자
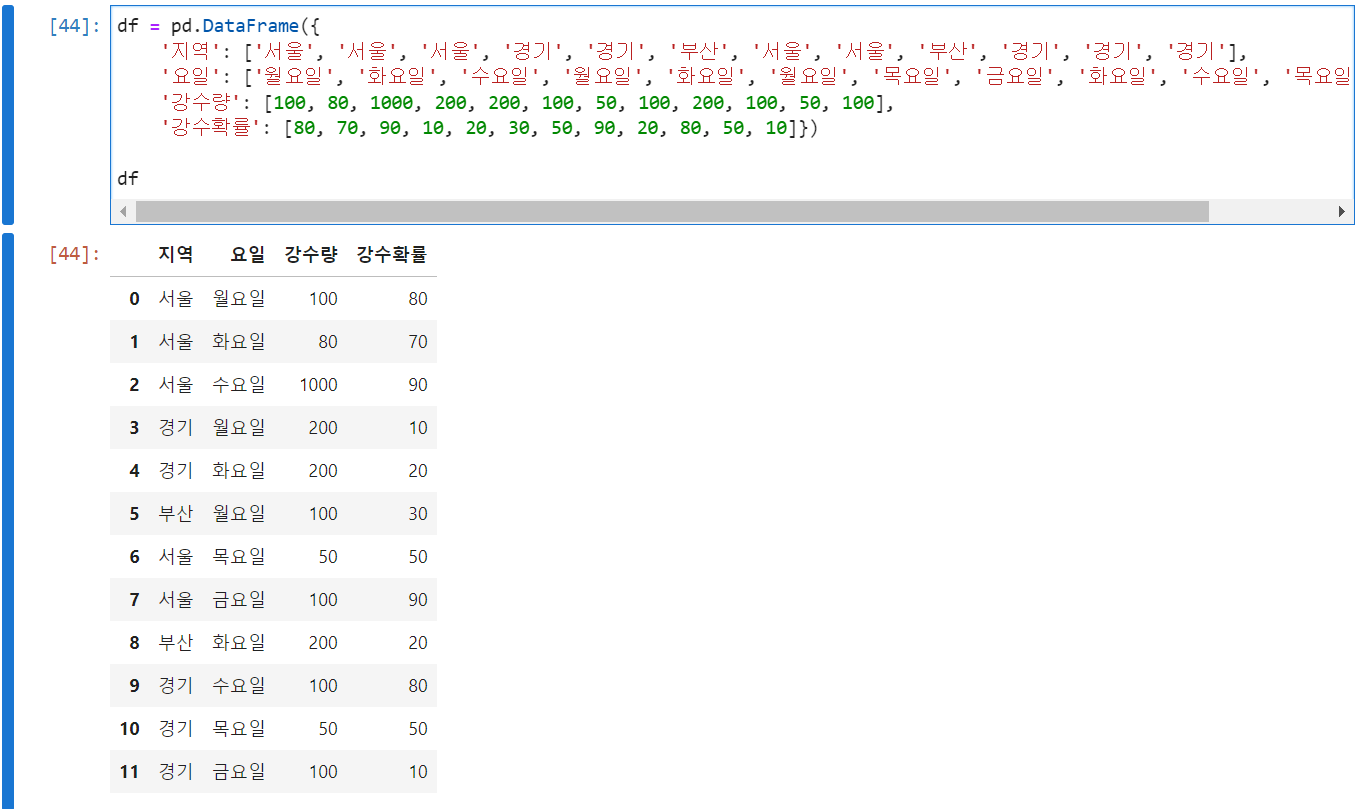
이때, 지역과 요일을 set_index()함수를 통해서 index로 설정해보자
new_df = df.set_index(['지역','요일'])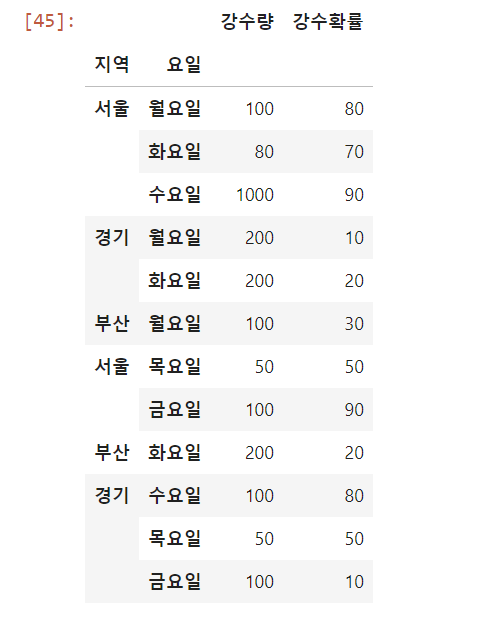
위에서 언급한 level개념을 적용하면 된다.
이때, stack과 unstack으로 쌓이는 것은 높은 level로 쌓이는 것으로 생각하면 된다
new_df.unstack(0)를 수행하면 index가 column의 level 1으로 이동한다.
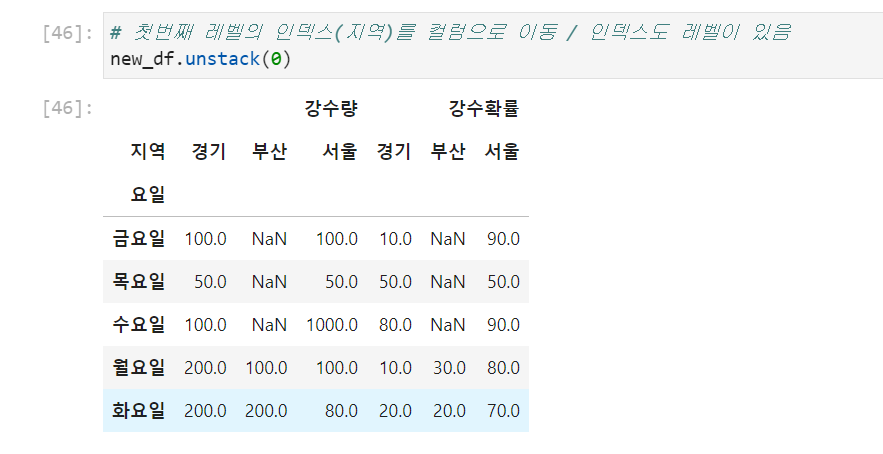
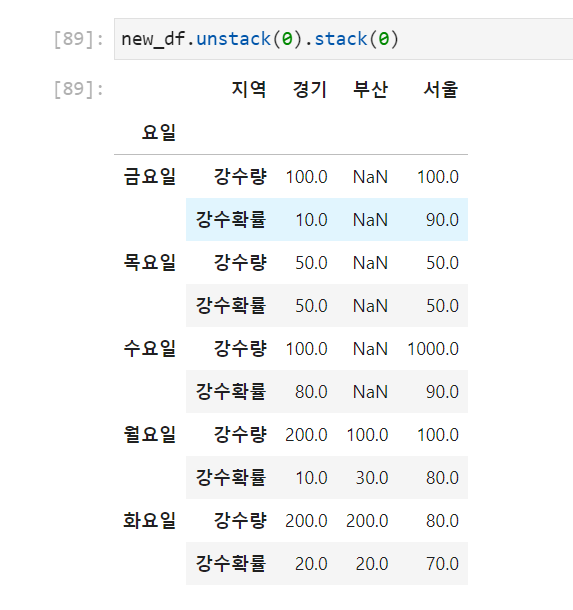
example 2>
concat함수의 join과 verify_integrity(무결점 확인) 파라미터에 대한 이해
-
join = 'inner'→ 교집합 -
join = 'outer'→ 합집합
이때, axis = 0을 지정하면 column을 기준으로 교집합 합집합을 따지고 axis = 1을 지정하면 index를 기준으로 교집합 합집합을 따진다.
-
verify_integrity=True→ 두 데이터프레임이 중복 인덱스(when axis = 1, 컬럼)를 가질경우 error 발생 -
verify_integrity=False→ 두 데이터프레임이 중복 인덱스(when axis = 1, 컬럼)를 가질경우 error 발생하지 않음
Pandas의 merge와 join함수
merge()
MySQL에서 여러가지 join을 배웠었다. 이때 join은 외래키를 사용하여 join했었는데 판다스의 merge도 같은 기능을한다. 다음과 같은 두 데이터프레임을 생각해보자.
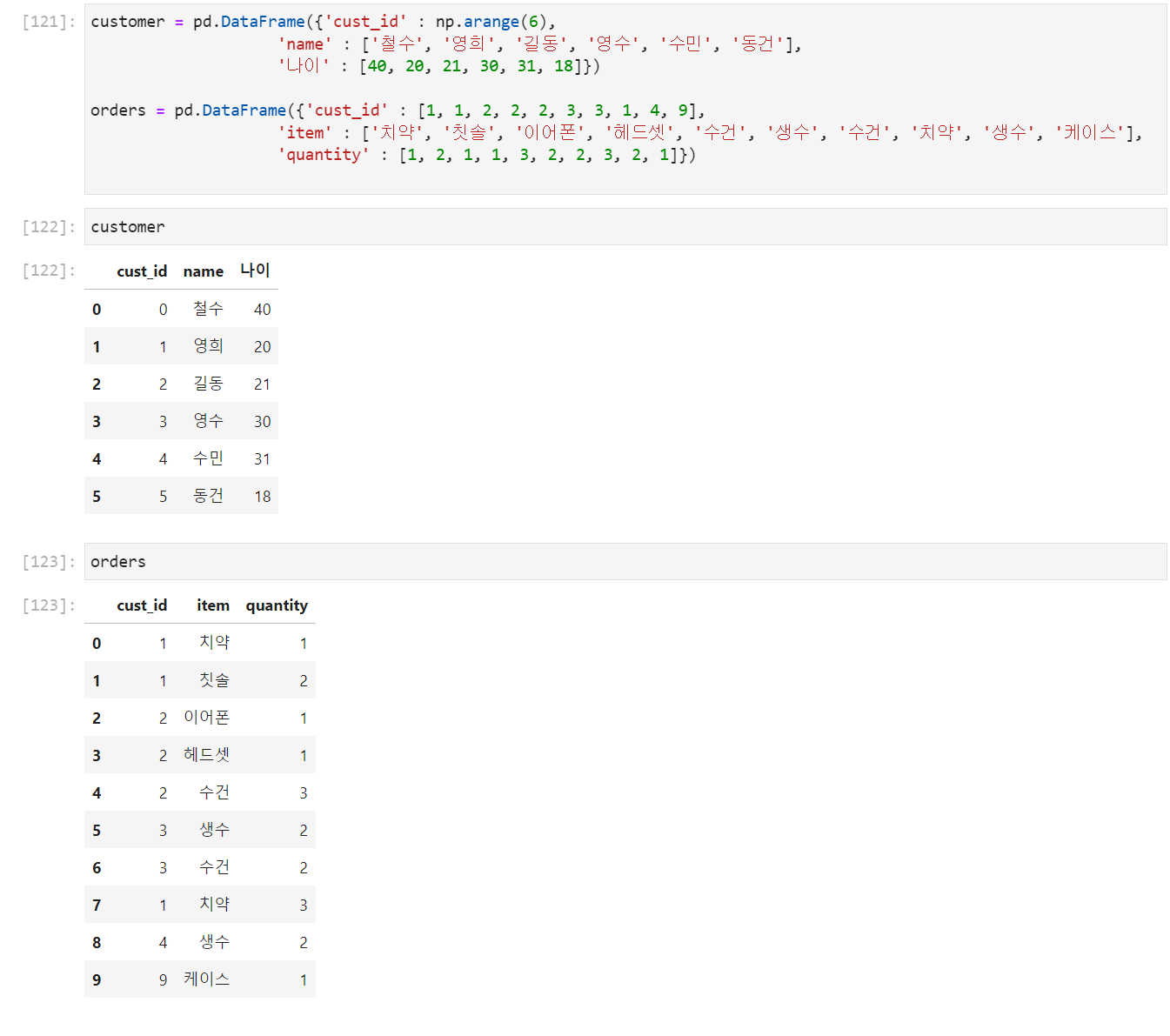
- on: join대상이 되는 column[외래키] 명시
how의 default는inner[공통된것]
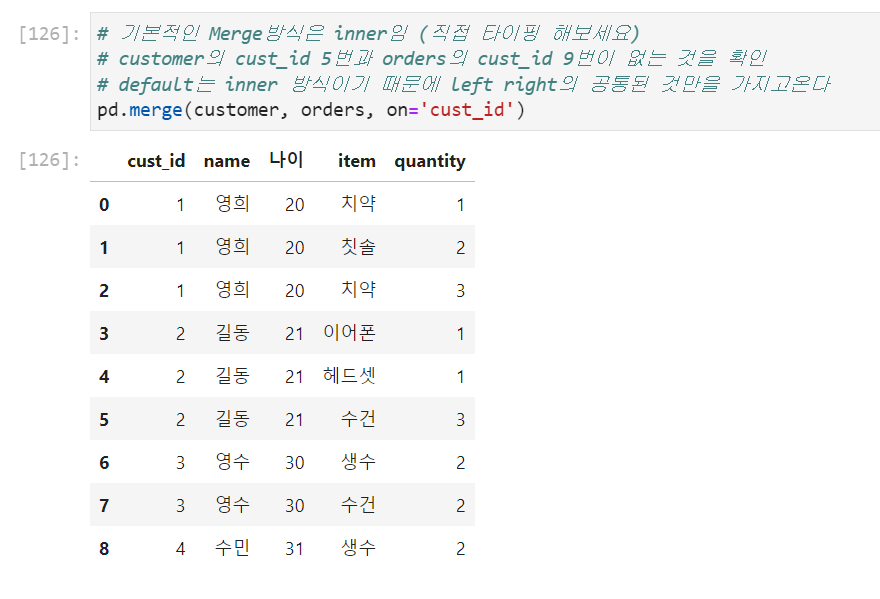
- how: inner, outer, left, right
left→ 왼쪽에 적은 데이터 프레임이 가진 외래키를 기준으로 데이터프레임을 merge하는데 오른쪽이 갖지 않은것은 NaN으로 작성된다.
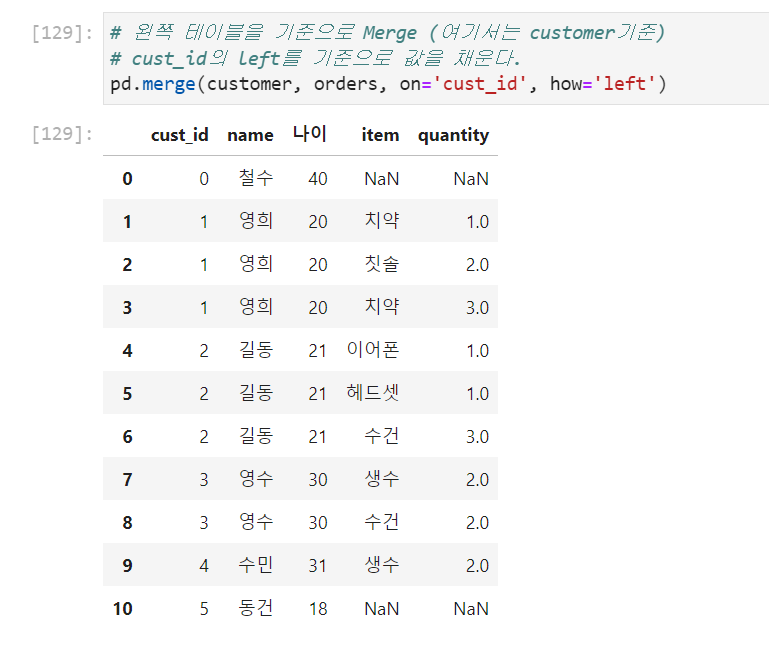
right→ 오른쪽 데이터프레임이 갖는 외래키를 기준으로 데이터프레임을 merge한다.
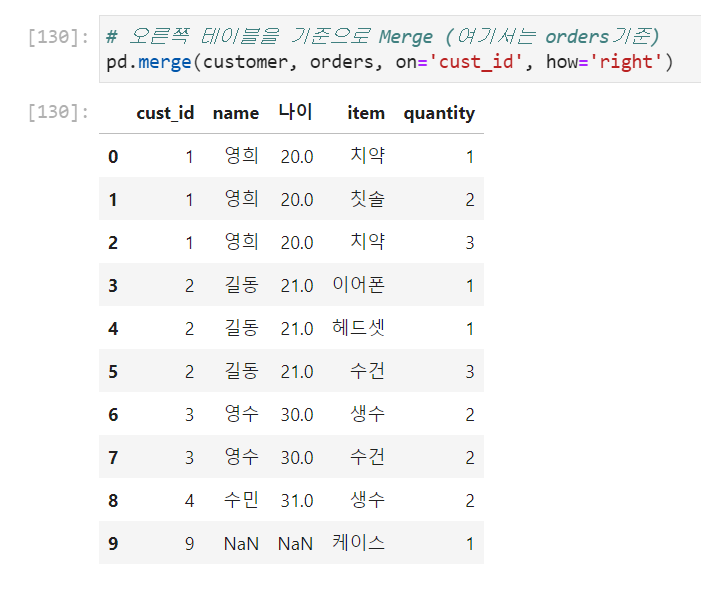
outer→ left와 right merge한 것을 합집합함
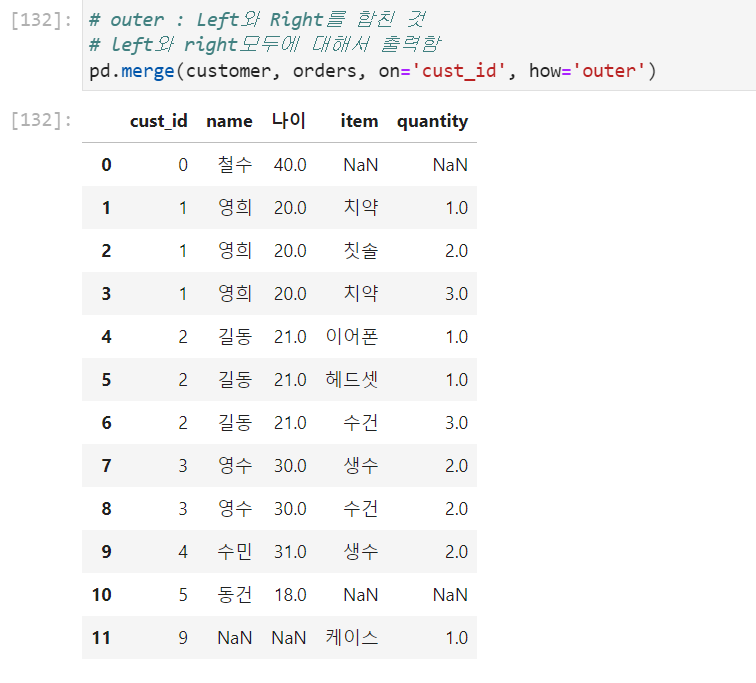
연습문제 1 : 가장 많이 팔린 아이템은?
# 3. sort_values를 이용하여 quantity를기준으로 sort + 내림차순으로 정렬 pd.merge(customer, orders, on='cust_id', how='right').groupby('item').sum().sort_values(by='quantity', ascending=False) # 오름차순 ascending= False # 만약 groupby를 하는 기준이 되는 키값이 NaN이면 그 row는 드롭이된다.
연습문제2: 영희가 가장 많이 구매한 item은?pd.merge(customer,orders, on = 'cust_id', how = 'inner').groupby(['name','item']).sum().sort_values('quantity',ascending = False).loc['영희']
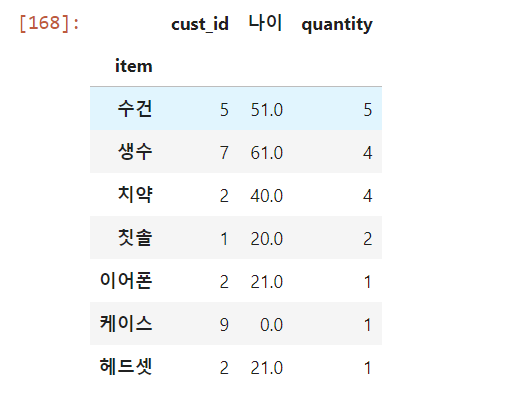

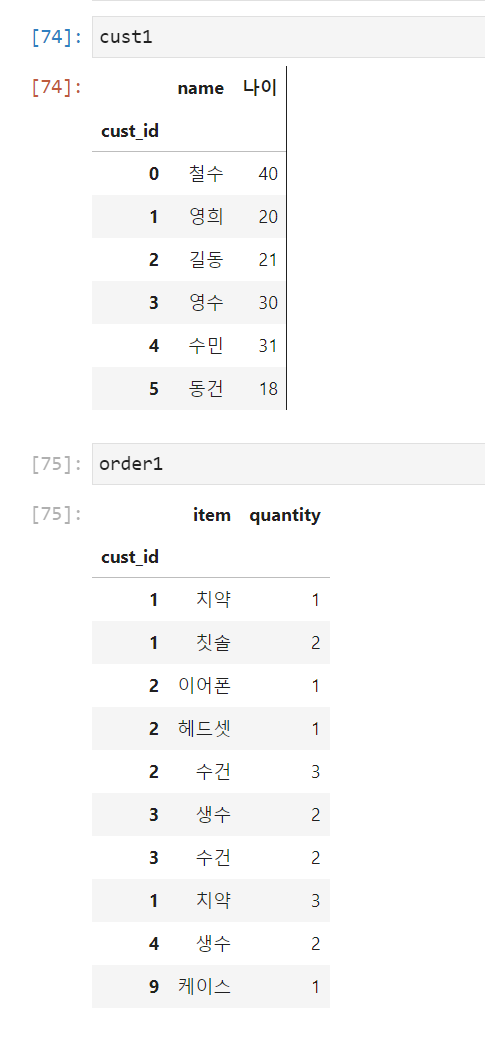
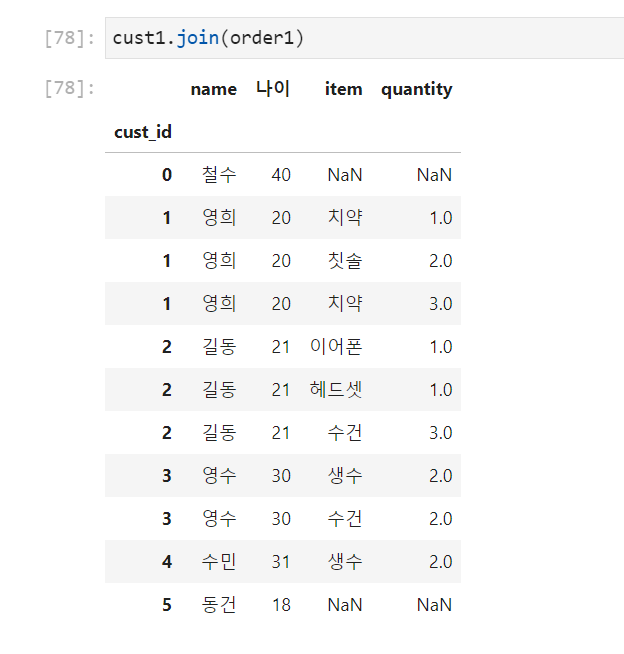
DF의 join()메소드
join()은merge()를 이용한 메소드로써, index를 사용하여 join을 수행하고, 기본형태는 다음과 같다.
DataFrame1.join(DataFrame2,how = 'left')
how의 Default값이 'left'이다.
DataFrame의 replace 메소드
데이터프레임의 특정값을 바꾸고자 하는 메소드로써 가끔 파일을 보다보면 결측치를 "-"라고 처리하는 경우가 있는데, 이럴때 사용하면 좋다.
cust.replace("_",np.NaN)
NaN의 Float지원
NaN은 기본적으로 float형식만을 지원하기 때문에, 다음과 같은 상황
에서 우리가 age를astype(float)으로 float형으로 바꾸고 싶다면 NaN을 지원하는 특성때문에 바뀌어진다.
하지만astype(int)에서 int는 지원하지 않기 때문에 바뀌지 않는다.
fillna의 method 파라미터
결측치를 처리하기 위해서 사용하는 메소드중에 fillna()라는 메소드가 있는데 파라미터로 method를 갖는다. 이때 다음과 같다.
padorffill앞의 원소를 사용하여 결측치를 채운다.bfillorbackfill뒤의 원소를 사용하여 결측치를 채운다.
cust.fillna(method = 'ffill')
이때, 맨앞 원소와 맨 뒤 원소가 결측치인지 확인해보아야 한다.
중간값이나 다른값으로 채우고 싶으면 replace를 사용하는 것도 고려해볼만 하디.
결측치의 선형처리를 위한 interpolate()메소드
interpolate 메소드를 사용하면 선형적으로 결측치 값이 채워지는데, 당연하게도 수치형 column만이 채워진다.
cust.interpoltate()
결측치 drop하기(listwise, pairwise)+dropna 파라미터
결측치를 drop할때 기본적으로 두가지의 개념이 있다
- listwise방식: 결측치가 하나라도 존재할 경우 drop
- pairwise방식: 모든 column이 결측치일 경우 drop
두방식 모두 기본적으로 dropna메소드를 사용하고
pairwise방식 같은 경우에는 dropna의
how파라미터에'all'을 작성해주면 되고 기본은 listwise 방식으로 drop한다.
dropna의thresh(threshold)파라미터는 NA가 아닌값이 지정된 개수 이상의 경우만 남겨두고 나머지는 전부 drop한다.dropna의subset=[column_name1, .. ]파라미터는 지정된 열 안에 NA만 참고하여 결측치를 처리한다.
예를들어
cust = cust.dropna(subset = ['class'])는 class안에 NA가 존재하면 DROP하고 아니면 DROP하지 않는다.
IQR을( Inter Quatile Range )
우리는 IQR을 기준으로 outlier와 outlier가 아닌것을 비교한다.
IQR = 1.5*(df.quantile(0.75)-df.quantile(0.25)) 로써
quantile 25퍼센트 값으로부터 아래로 IQR미만(즉, value< df.quantile(0.25) - IQR))
quantile 75퍼센트 값으로부터 위로 IQR초과(즉, value>df.quantile(0.75) + IQR))인 경우에 보통 outlier라고 정의한다.
Binning
Binning은 수학의 modulo를 이용한 개념으로써 연속형 범주를 범주형 변수로 만들어준다.
다음과 같이 수행할 수 있다.
cust_data['by_age'] = cust_data['age']//10*10위의 코드로 나이가 몇십대인지 알려줄 수 있다.
Pandas의 Binning을 위한 cut과 q_cut 메소드
판다스는 cut과 qcut메소드를 제공해서 왼쪽 열린구간이 만들어지도록 한다.
이때, cut은 범위를 지정해서(왼쪽 열린구간 오른쪽 닫힌구간으로 생각) 그 범위 안에 들어가는 요소에 대해 해당범위를 채워서 Series로 반환해준다.
qcut은 bin의 개수(q)를 지정해서 해당 column의 min과 max값 사이를 q에 지정된 값만큼의 bin의 개수로 나눠준다.
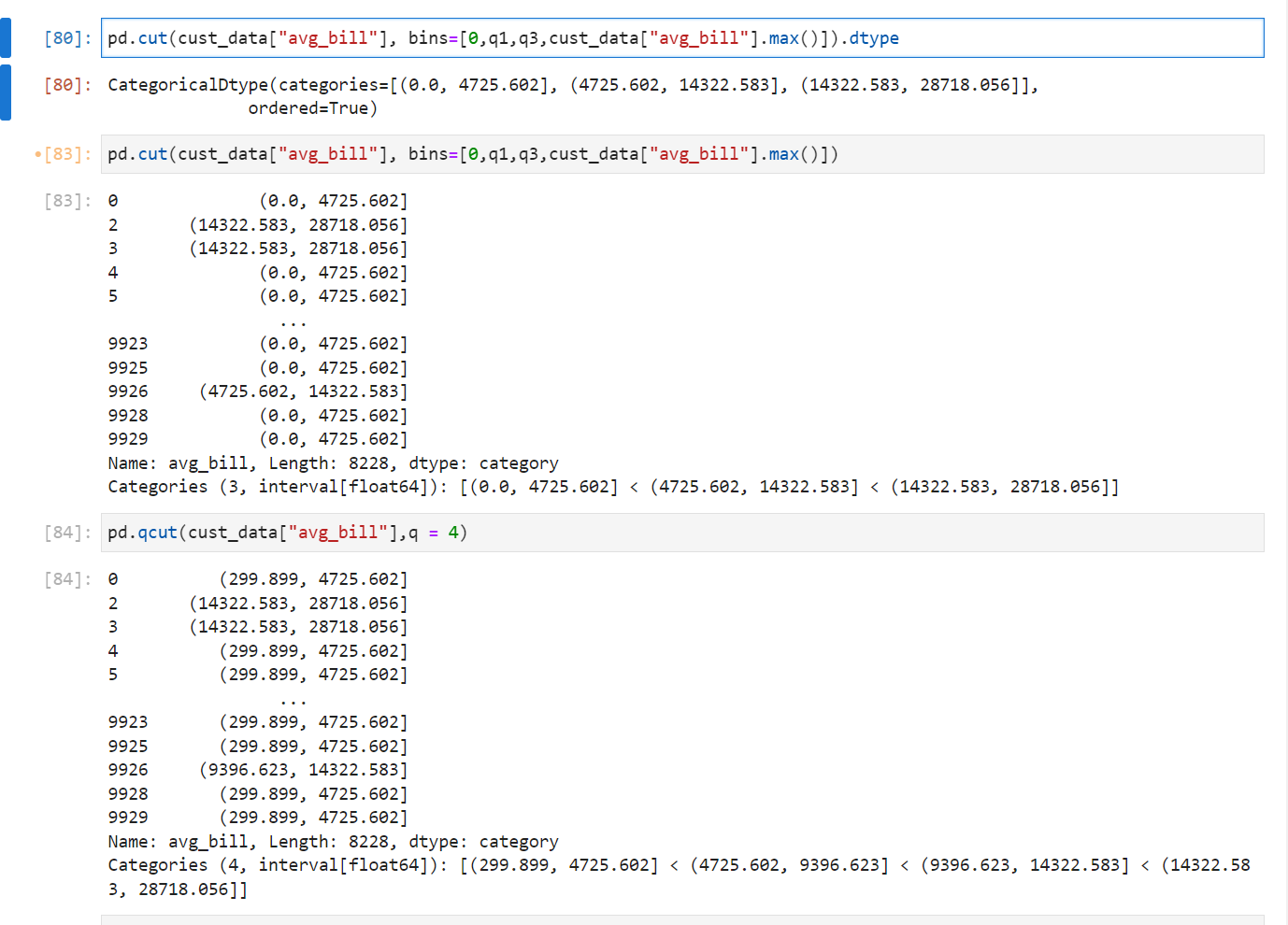
이러한 메소드들은 parameter로
labels를 가지고 있는데 따라서 범위에 따라서 categorical한 변수를 만들기 매우 좋은 함수이다.
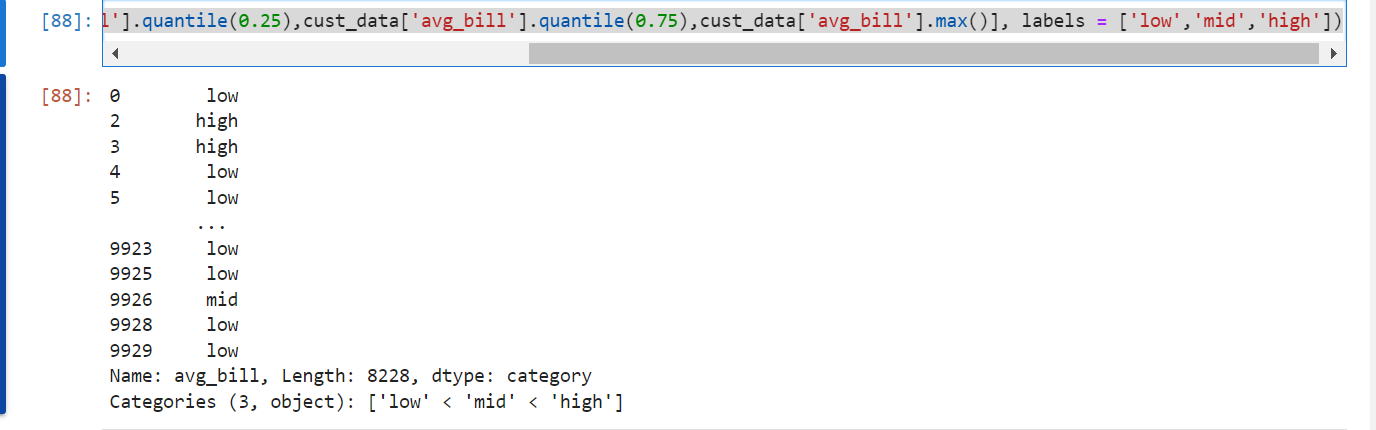
pd.cut(cust_data['avg_bill'], bins = [0,cust_data['avg_bill'].quantile(0.25),cust_data['avg_bill'].quantile(0.75),cust_data['avg_bill'].max()], labels = ['low','mid','high'])

categorical변수 one-hot encoding을 위한 Pandas의 get_dummies()함수
dummy: 많은 물건들이 모여있는 덩어리
get_dummies()함수를 이용해서 categorical 변수를 원핫 인코딩 시킬 수 있고, 다음과 같이 사용한다.
pd.get_dummies(data,columns[list-like],drop_first, ...)
columns를 지정해주지 않을경우 모든 categorical변수에 대해서 get_dummies()함수를 적용한다.
drop_first 파라미터는 zero_vector를 사용할지 결정하는 것으로써 True로 설정해놓으면 사용하지 않는것이다
classify 문제에서 우리는 target의 one-hot encoding이 돼있냐 안돼있냐에 따라서 돼있으면 categorical_crossentropy 돼있지 않았으면 sparse_categorical_crossentropy를 사용했다.
이때, 이진분류를 수행하는데 drop_first때문에 one-hot encoding이 안돼있는것처럼 돼서 sparse_categorical_crossentropy를 사용한적이 있다. "AICE시험을 위한 M.L코드"를 확인해보길 바란다.
Matplotlib and Seaborn
Matplotlib

plt.Scatter()
산점도는 키와 몸무게 같은 두 값 간의 관계를 표현하고 두 값이 양의 상관관계인지 음의 상관관계인지를 파악할 수 있다.
다음과 같이 사용한다.
plt.figure(figsize = (16,5))
plt.scatter(x = df['age'], y = df['avg_bill'])
plt.show()plt.hist()
히스토그램은 수치형 데이터의 분포를 나타낸다. 흔히 빈도, 빈도밀도, 확률등의 분포를 그릴때 사용한다.
bins(default = 10)를 정해줘서 수치형 데이터의 구간을 나눈다.
plt.figure(figsize = (16,5))
plt.hist(df['age'], bins = 10)
plt.show()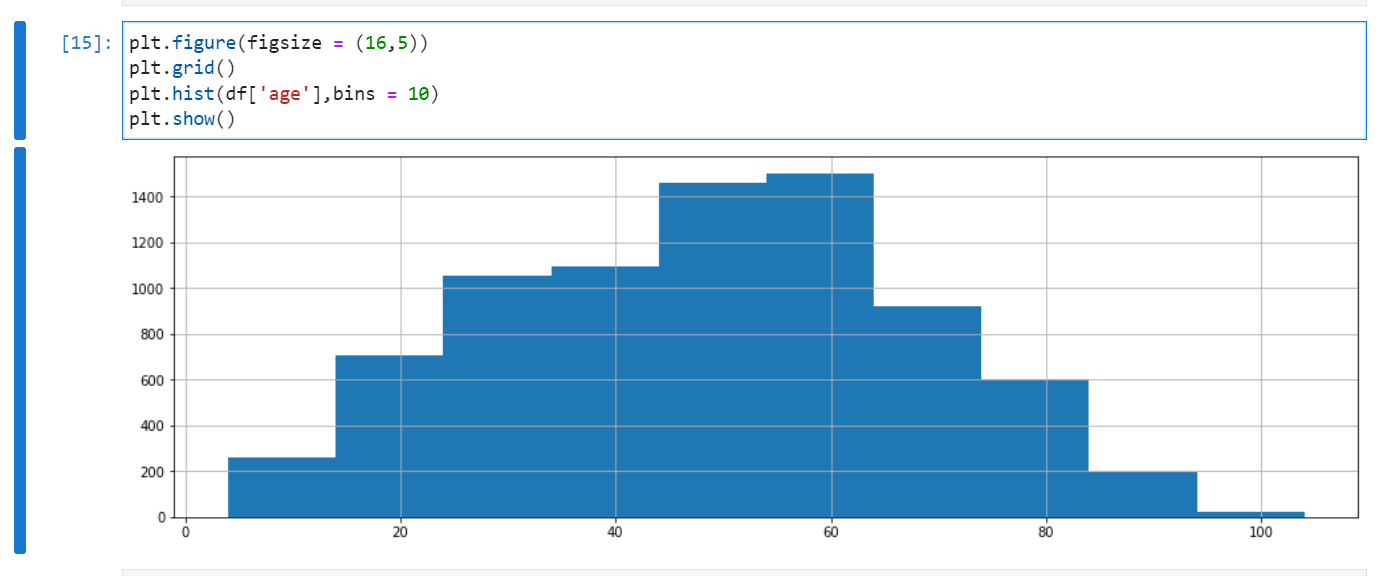
plt.bar() & df.plot(kind = 'bar')
막대그래프는 범주형 데이터의 수치를 나타낸다. 이것은 위에 hist와 다르게 두개의 변수를 받아서 빈도수가 아닌실제 y값을 표현해준다는 점에서 명백히 다르다.
DataFrame을 이용해서 그릴수도 있다. 이때, index를 X축으로 사용해야 하기 때문에 DataFrame을 변형하여 그려야 한다.

다음과 같이 그린다.
df2[['A_bill','B_bill']].plot(kind = 'bar')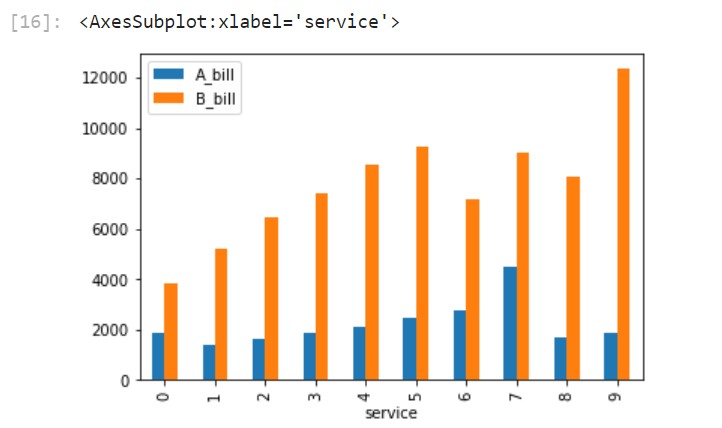
df2[['A_bill','B_bill']].plot(kind = 'bar',stacked = True)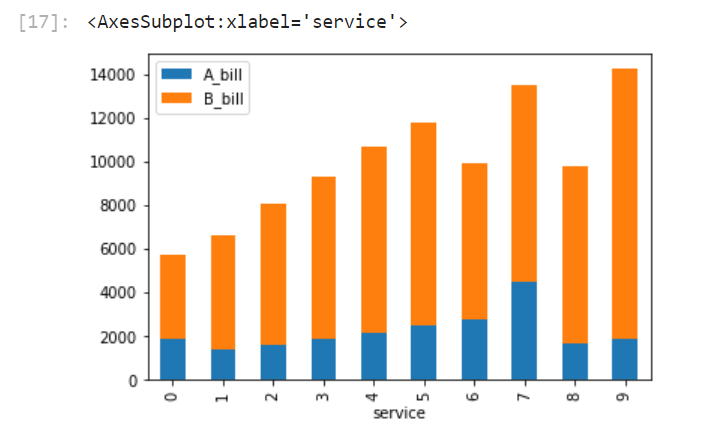
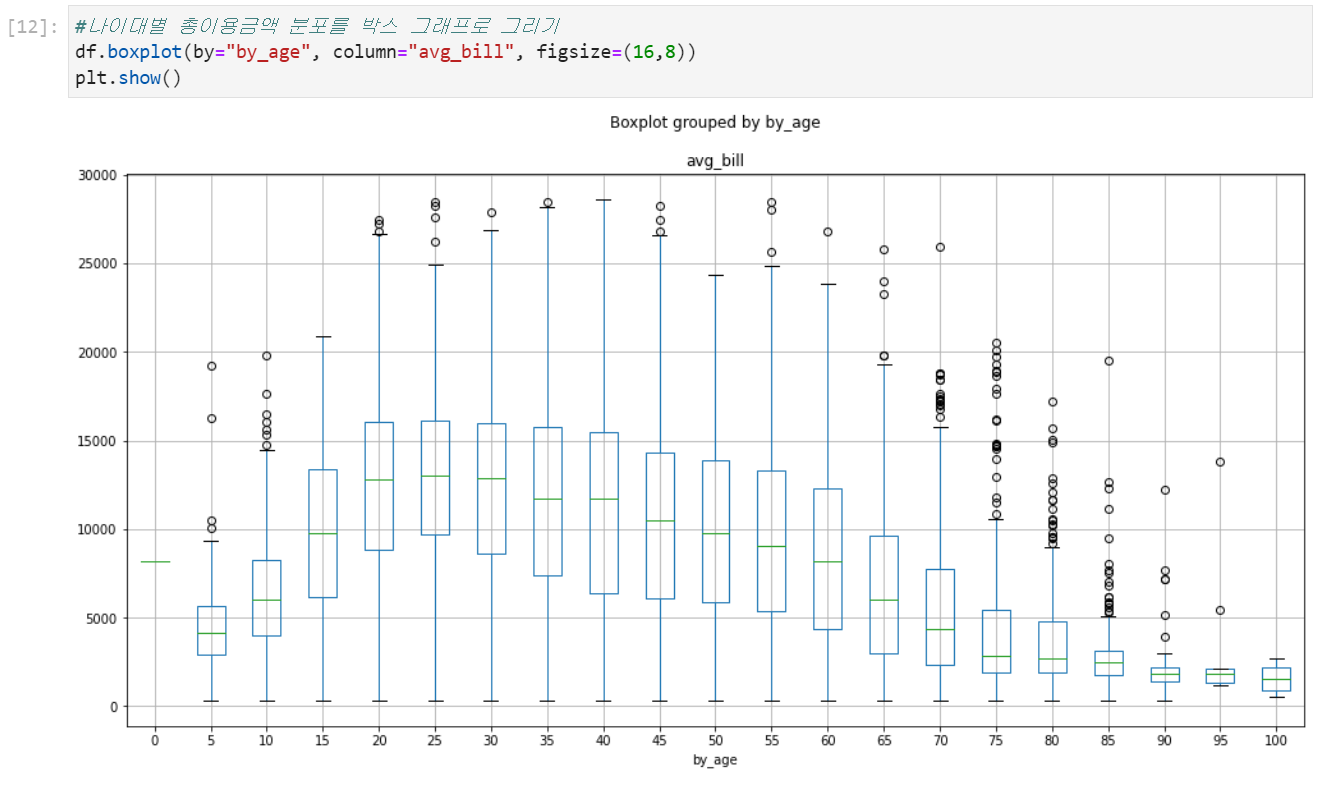
plt.boxplot() & df.boxplot()
수치적 자료를 받아 값의 범위 분포를 표현하는 그래프이다.
데이터프레임에서도 boxplot()메소드를 활용하여 그릴 수 있는데, 이때, by파라미터는 x축 column파라미터는 y축을 담당하기 때문에 x축은 categorical column이 y축은 수치형 column을 지정하는 것이 보기 좋다.
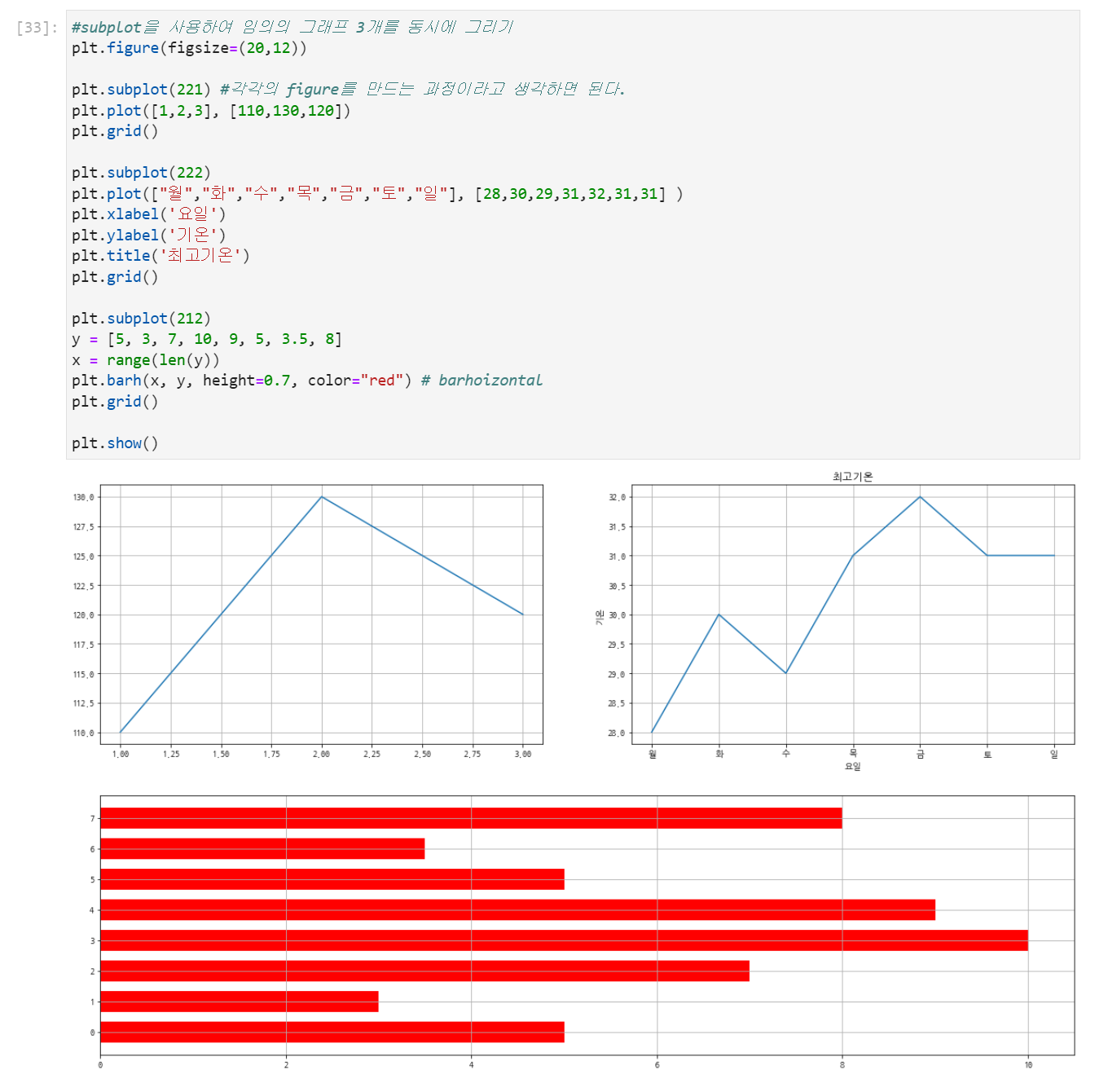
plt.subplot
난 보통 plt.subplots를 이용해서 여러개의 그래프를 한번에 그렸는데, plt.subplot도 이용할만한거 같아서 사용해보겠다.
Seaborn
seaborn은 matplotlib을 기반으로 만든 라이브러리로써, 화려한 시각화를 지원해준다.

Seaborn Scatter plot
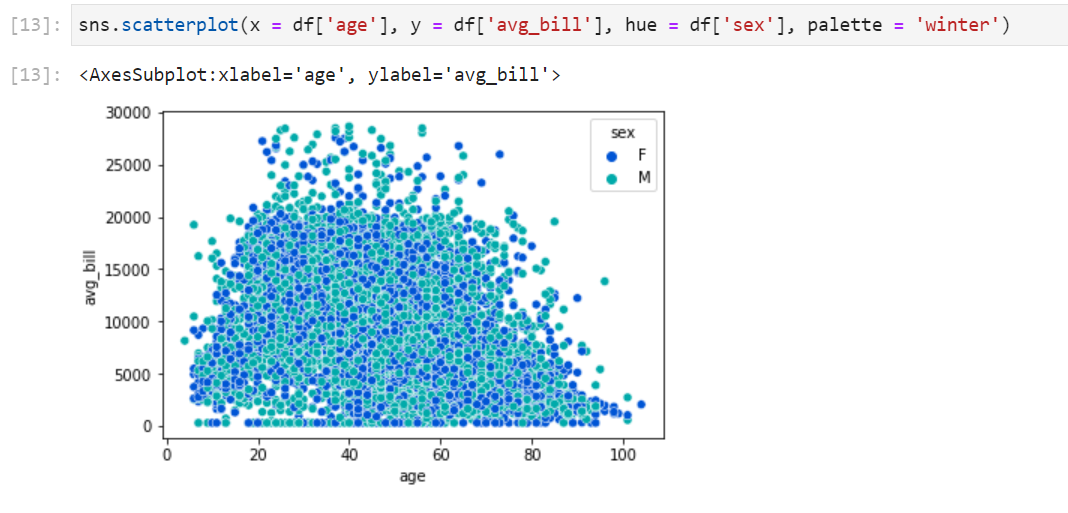
hue = categorical column을 이용해서 그래프 내에서 분류할 수 있다.
catplot(categorical plot)
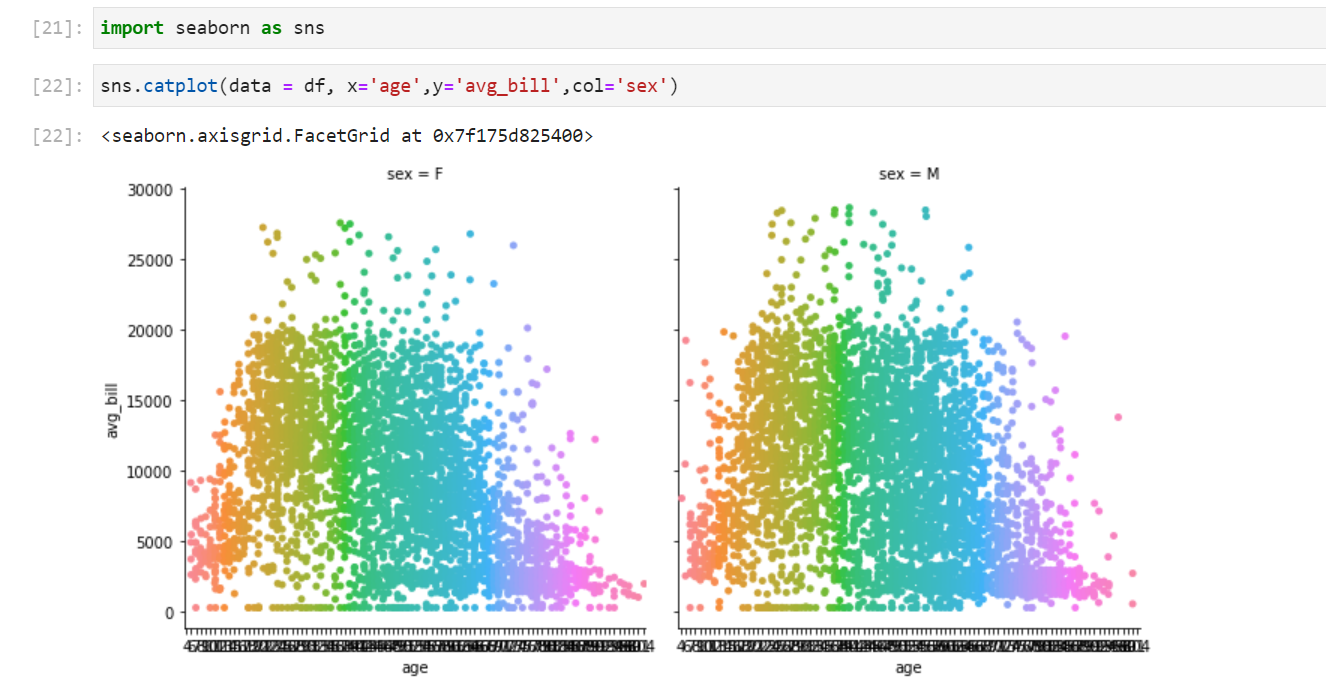
sns.catplot은 col파라미터에 categorical변수를 적어줌으로써 해당 category에 포함된 변수들의 산점도를 그려준다. 다음과 같이 사용한다.
sns.catplot(data = df, x='age',y='avg_bill',col='sex')
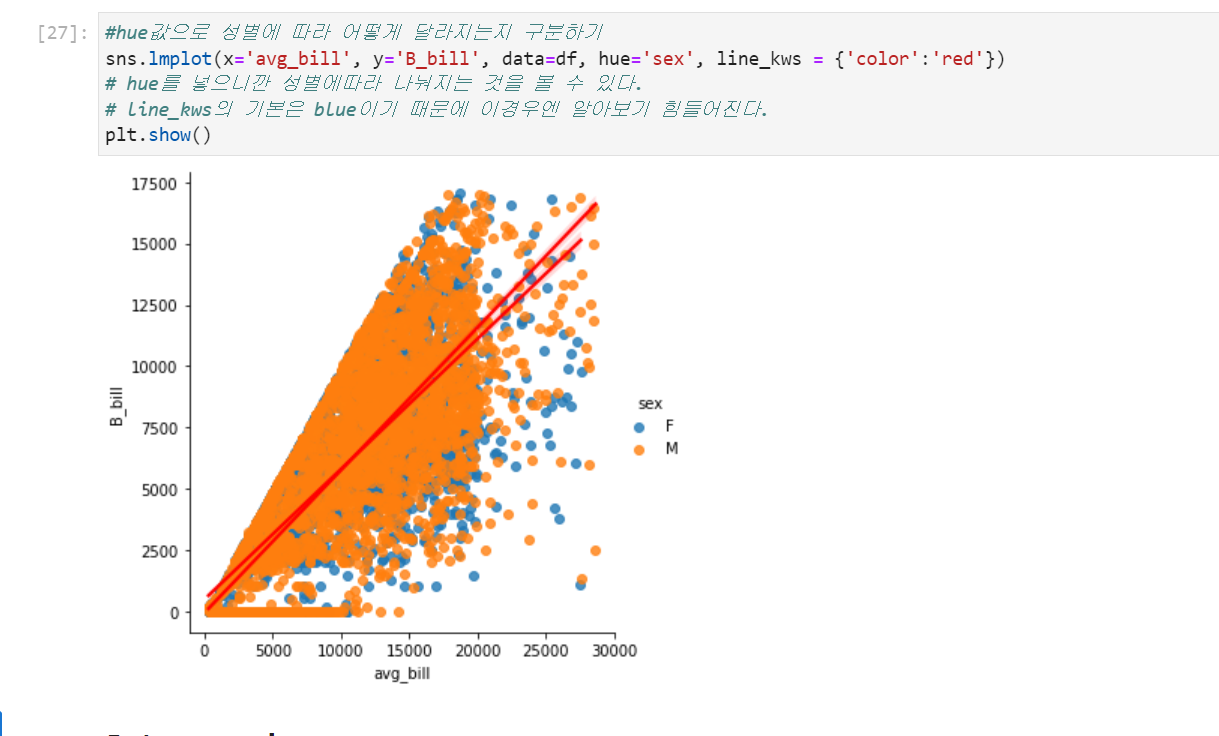
lmplot(산점도+회귀선)
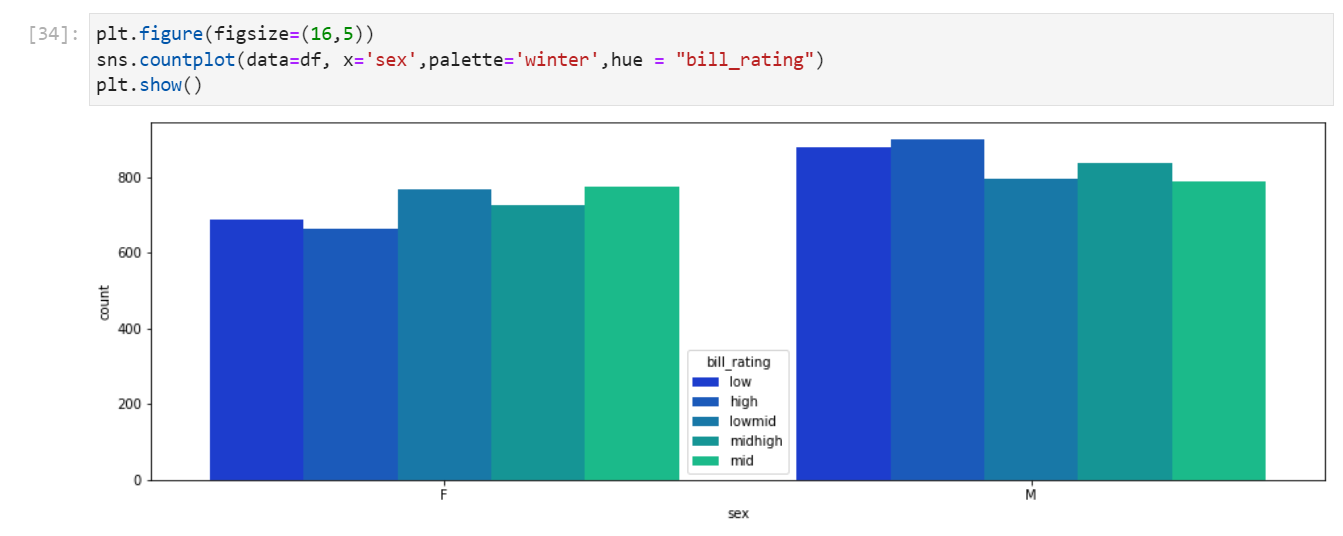
countplot(범주형 데이터의 개수 파악)
histplot(plt.hist에 대응(연속형 데이터의 범주에 따른 개수 파악+ seaborn은 범주형도 깔끔함))
plt.figure(figsize = (16,5))
sns.histplot(data = df, x = 'avg_bill', bins = 20)
plt.show()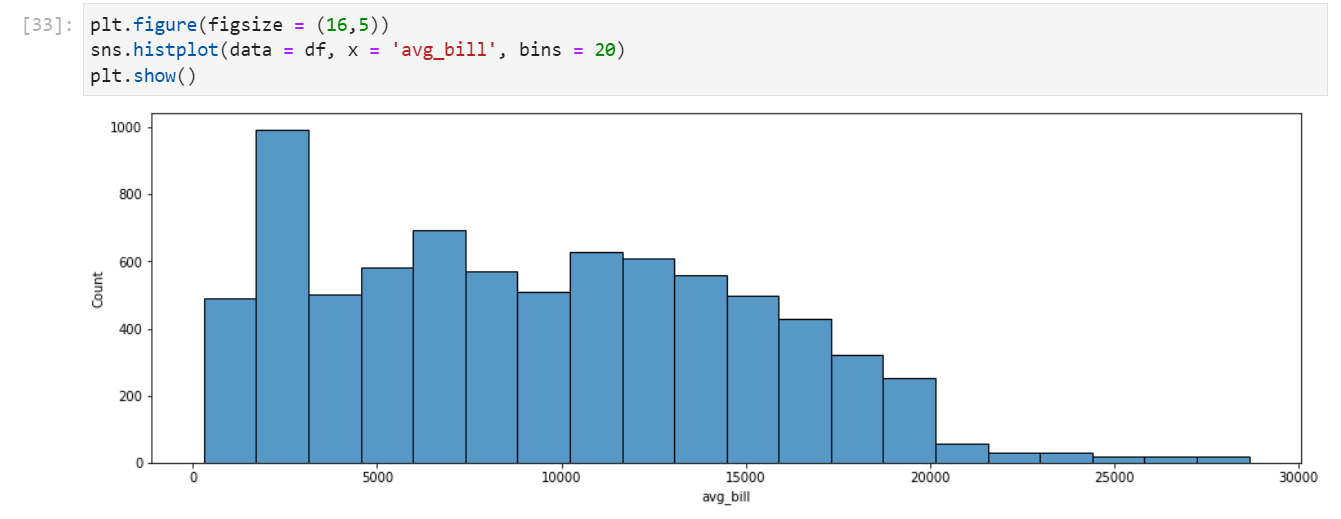
유용한 jointplot(산점도+ histplot)
산점도와 동시에 데이터의 밀도를 보여주는 plot이다.
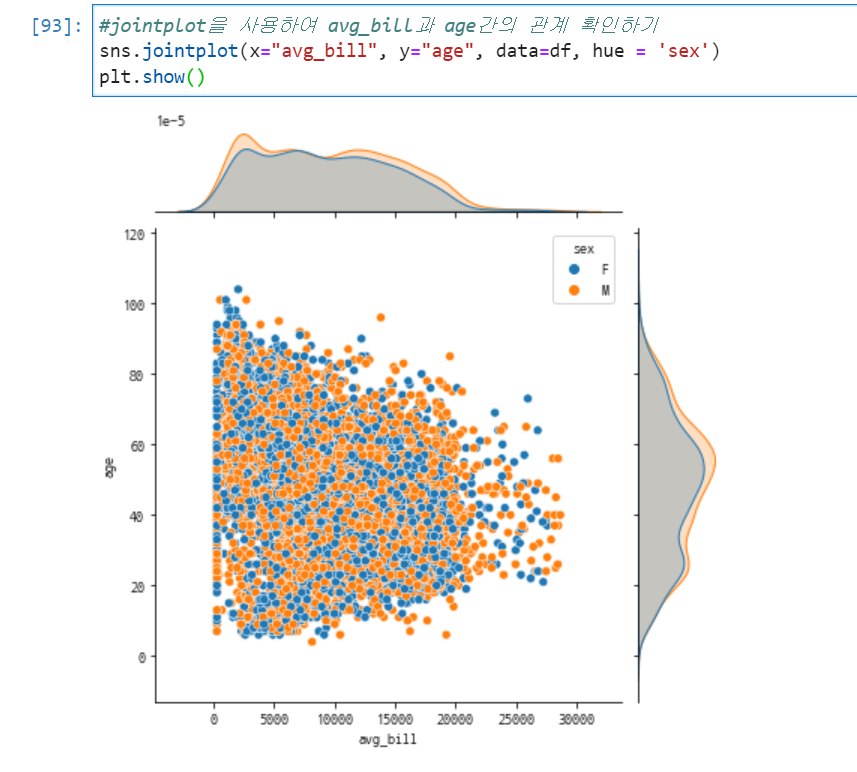
여기서 kind를 사용하면 산점도 영역의 그래프를 다른 모양으로 변경 가능하다.
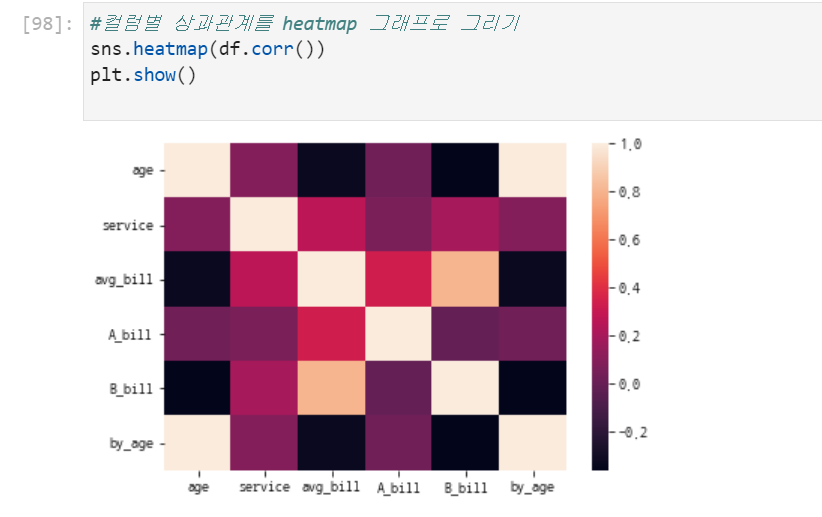
매우 유용한 heatmap(연속형 변수의 상관관계를 그려줌)
seaborn의 heatmap을 사용하기 위해서는 df.corr()을 알아야한다. 이는 데이터프레임의 모든 수치형 변수에 대한 상관관계를 데이터프레임 형태로 반환해준다.
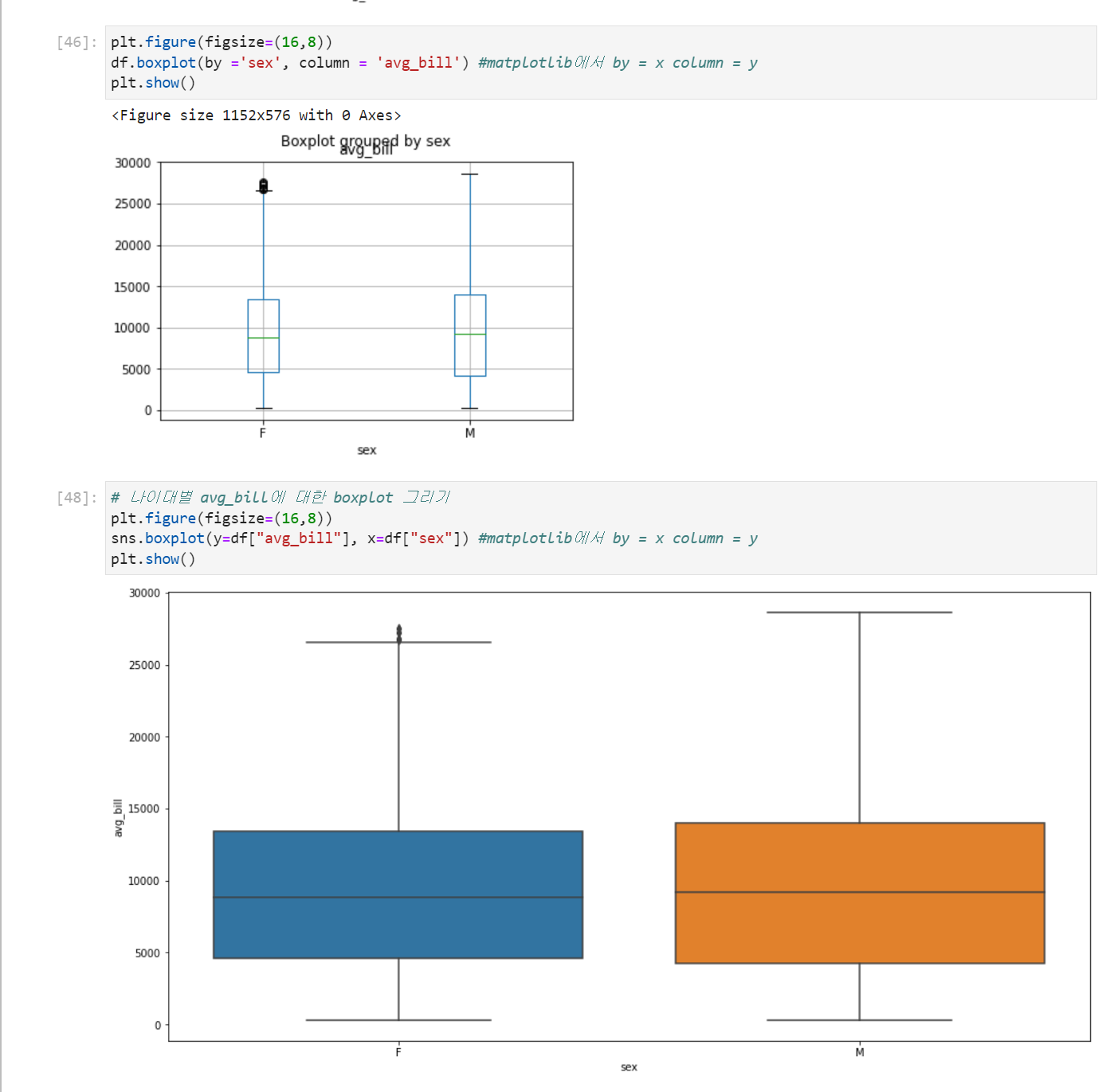
1변수만 받았던 boxplot과 달리 2변수(x = categorical, y = numerical)를 받아 표현하는 boxplot
우리는 위에서 df.boxplot(by,column)을 통해서 boxplot을 그릴 수 있었다 seaborn과 비교해보겠다.

잘 읽었습니다. 좋은 정보 감사드립니다.