
[Query] 실행 순서에 대해
✅ 아무리 옵티마이저가 JOIN 순서·실행 순서를 바꿔도 결과는 절대 달라지지 않는다.이건 표준 SQL의 보장 사항이다.🎯 왜 절대 결과가 달라지지 않을까?이유는 간단함:SQL은 선언적 언어이기 때문.즉,“어떻게 실행할지” 가 아니라“어떤 결과가 나와야 하는지” 를
[Spring] Query&Command
https://www.notion.so/2025-09-10-26a820615704807a8872fa1e6feff0d2?source=copy_link
[Architecture] Multi-Module Architecture vs MSA
하나의 애플리케이션(프로젝트) 안을 여러 모듈로 나누어 관리하는 방식.보통 Gradle, Maven 같은 빌드 툴에서 모듈을 정의해서 공통 코드, 도메인별 코드 등을 분리함.하나의 프로세스로 동작 → 배포 시에도 하나의 애플리케이션으로 패키징/배포모듈 간 의존성을 빌드
[JAVA] 맨날 헷갈리는 Stream 중간연산
1️⃣ .map(): 기존 스트림의 요소를 받아서, 어떤 함수로 바꿔서 새로운 스트림을 만듦(중간 연산) => 변환ex :2️⃣ .collect(): 스트림의 최종 결과를 리스트, 세트, 맵 등 컬렉션으로 모을 때 사용 => 결과 ex : 이러한 메서드는 많이 써보는게
[Architecture] DDD
기존 개발 방식의 문제점 > 해당 부분은 현재 회사에서도 지독하게 느끼는 부분이다 DB 스키마를 먼저 기준으로 설계하여 여기에 맞춘 MVC 패턴 구축하여 "DB에 종속적임" (말이 MVC이지 구조만 있고 Controller에서 대부분 로직 처리 + Service로직은
[Build] gradle vs yml
build.gradle > Gradle 빌드 스크립트 파일 프로젝트를 어떻게 빌드하고, 어떤 의존성(dependency) 을 가져올지 정의하는 곳 실행 시점이 아니라 빌드 시점(compile, test, package) 에 영향을 줌 ex) => 즉, 우리가 작성한

[Design Pattern] Facade Service
실제 Legacy 환경의 현업에서 일한지 대략 1년 쯤 된 지금... 어느정도 기능의 측면에서 패키지 구조가 분리되어 있지만, 패키지 안에 단일 Controller, Service, Repository로 구성된 곳에서 일하다보니 일단 하나의 클래스 파일에서 소스가 3~
[DevOps]도커 & 쿠버네티스
가상화 솔루션도 결국 1개의 어플리케이션에 불과함(os 기준) => os한테 자원 받고 자기가 하드웨어가 없음에도 하나의 컴퓨터 처럼 있는거임(겜도 하고 통신도 하고 서버도 되고) cpu, 메모리 ,스토리지 ,네트워크 등 컴퓨터 리소스 + @ 관장하는 OS(host)
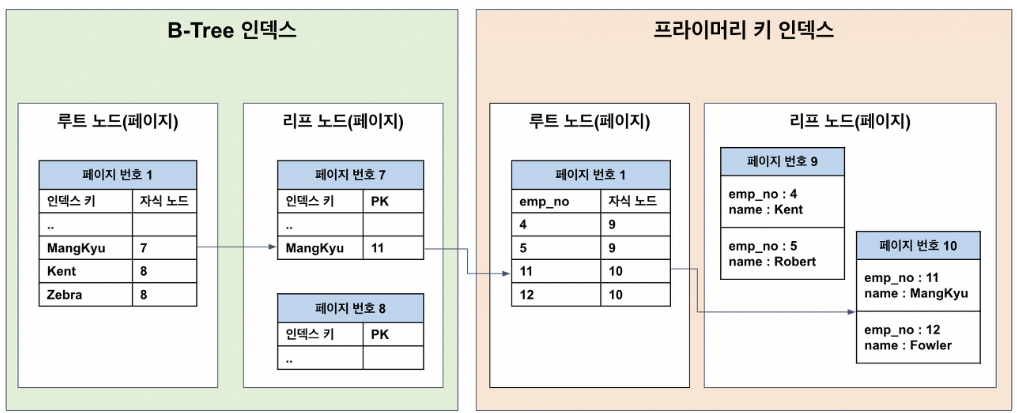
[DB] Index
데이터를 빠르게 탐색하기 위해 사용한다. 특정 컬럼에 대해 값을 정렬하고 이를 통해 빠르게 데이터를 찾을 수 있도록 도와준다.단점인덱스도 데이터기 때문에 저장하기 위해 별도의 저장 공간 필요CUD가 빈번한 테이블에 인덱스를 걸게 되면 데이터 변경 시 인덱스도 함께 수
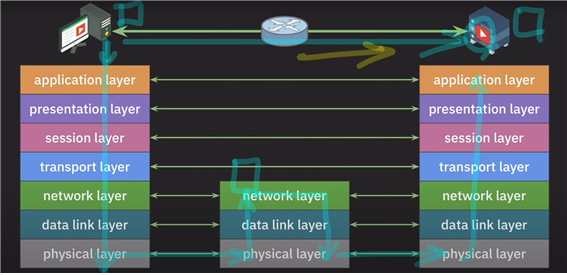
[Network] OSI 7 Layer
항상 이론으로만 대충 알고, 막상 설명은 하지 못했던 OSI 7Layer에 대해 좋은 강의가 있어 참고하여 정리한 글입니다.참고영상: 쉬운코드님의 입문용 프로토콜과 OSI 7 layer 설명https://www.youtube.com/watch?v=6l7xP7A
[객체지향] 객체지향의 사실과 오해
본 글은 객체지향의 사실과 오해를 읽고난 후 저에게 필요한 내용이나 기억에 남는걸 정리한 문서입니다.객체지향이란 시스템이 맡아야할 큰 책임을 결국 자율적인 객체들이 각자 책임을 맡고, 자신이 처리할 수 없는 일은 링크를 통해 메세지를 보내서 다른 객체에게 일임하여 협력

[알고리즘] 위상 정렬
위상 정렬이란? > 깔끔하게 정리해주신 블로그를 첨부(보고 이해가 안 될 수가 없을듯..) https://bcp0109.tistory.com/21 실전 문제 풀이(백준 1005) 얻어갈 점:
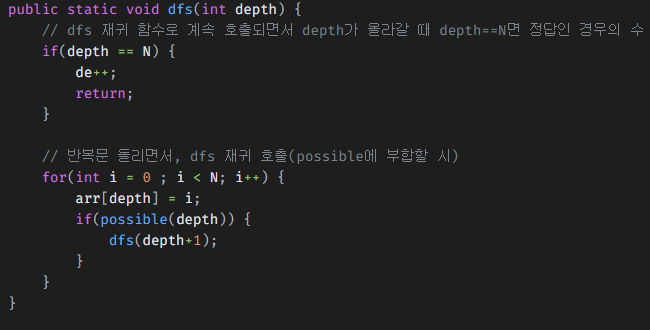
[알고리즘] 백 트래킹 문제 풀이
얻어갈 점:이전에 풀었던 NxN queen 문제와 비슷한 느낌이 들어 백 트래킹 알고리즘 채용스도쿠를 풀어가며(dfs이용) 잘못 입력될 시 돌아오는 로직이기 때문그러나 그때 NxN 문제에서는 초기화하고 돌아가는 로직이 없는데 같은 백트래킹이지만 구현이 다른 건가? 의문
[알고리즘] DFS 문제 풀이
얻어갈 점: 이전의 DFS 구현할 때 인접 행렬을 이용했으나, 이번엔 인접 리스트를 통해 구현했음(성능 상의 이점)DFS 사용 이유? 그래프를 다 뒤져서 가장 거리가 먼 두 수를 찾아서 더해주는 문제라서 사용했음노드의 값은 인덱스와 가중치 두 개의 속성이 있으니 Cla
[알고리즘] 투 포인터 / 이진 탐색(binary search)
백준 2467 투 포인터 풀이 얻어갈 점: 투 포인터로 풀이할 수 있는 이유? 두 개의 용액이 -부터 +까지 정렬된 상태에서 두 개를 골라 0에 최대한 근접한 값을 찾는다(구간 합과 유사) => 양 쪽 끝에서 두 개를 고른 다음 0보다 크면 start를 하나 땡기고
[알고리즘] 정규 표현식
백준 2671 얻어갈 점: 정규 표현식을 사용하는 문제를 처음 접해서 노가다해서 풀려고 했는데 실패했다. 특정 규칙을 가지는 문자열을 체크할 수 있는 정규표현식의 존재를 구글링해서 찾아서 잘 정리된 글을 아래에 첨부함 정규 표현식에서 () 와 []의 차이가 궁금했는데
[알고리즘] 유니온 파인드
얻어갈 점:유니온 파인드를 쓸 수 있는 point => 진실을 알고 있는 사람과 한 번이라도 같은 파티라면 거짓말 불가능 => 그룹핑을 통해 한 번이라도 같은 파티였는지, 아닌지 묶는 알고리즘? => 유니온 파인드유니온 파인드를 묶기 위해서는 union(x,y)와 같이
[알고리즘] 백 트래킹 문제
백준 9663 얻어갈 점: dfs vs 백 트래킹 => dfs: 완전 탐색을 기본으로 그래프를 모두 순회하기 때문에 불필요한 경로를 사전에 차단 불가 / 백 트래킹: 경로를 찾아가는 도중에 해가 되지 않을 것 같은 경로라면 되돌아옴 백 트래킹으로 풀어야겠다 catch
[알고리즘] 투 포인터
얻어갈 점투 포인터를 이용한 문제 풀이 => why? 특정 구간의 합을 구하는 것! => start, end 인덱스를 사용하여 길이를 조절하여 풀면 되겠다!int\[] arr = new intn+1 => 처음엔 배열의 개수를 n개로 지정했다 그러나 아래의 핵심 로직 쪽
[자료구조] Stack 문제 풀이
얻어갈 점:처음에는 배열에 탑들의 정보를 미리 넣고, 맨 끝 인덱스부터 앞과 비교하여 신호를 받을 수 있는 탑을 찾으려 했으나 그렇게 하면 시간 초과가 날 수 밖에 없음(시간복잡도에 의해)Stack을 사용할 수 있었던 이유? 입력된 변수가 가장 가까운 탑과 비교를 통해