해당 글은 FastCampus - '[skill-up] 처음부터 시작하는 딥러닝 유치원 강의를 듣고,
추가 학습한 내용을 덧붙여 작성하였습니다.
1. 문제점: Layer가 많아졌을 때는?
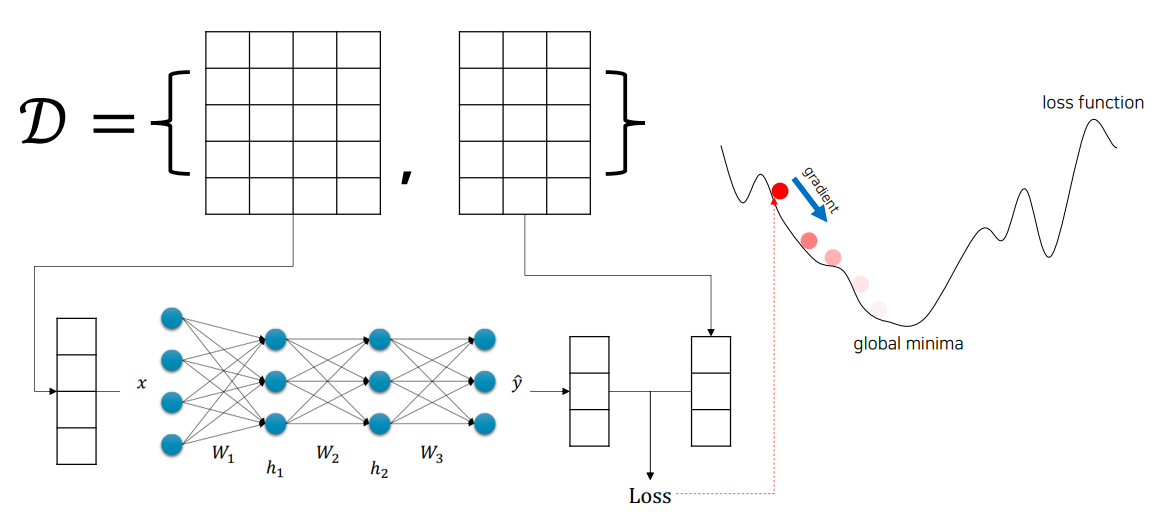
- 딥러닝 모델은 여러 층(layer)으로 구성되며, 각 층의 파라미터가 많음
- 모든 파라미터에 대해 매번 Loss를 직접 미분하면 매우 복잡하므로 비효율적
- 중복된 연산이 많아 계산 비용이 큼
2. 해결책: Back-propagation
2.1 개념
- 심층 신경망은 합성함수로 표현됨
- Chain Rule(연쇄 법칙)을 활용하여 복잡한 함수의 미분을 각 구성 함수별로 나눠서 처리
- 즉, 기존에 계산한 각 함수별 미분값들을 재활용하여 미분 과정을 효율적으로 만드는 것
- 뒤쪽으로 퍼져나가는 것처럼 보이기 때문에 back-propagation이라고 함
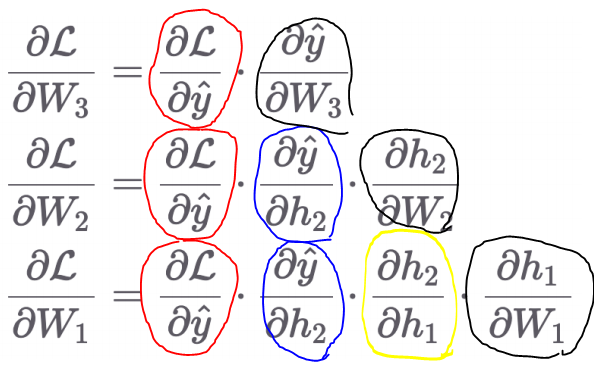
2.2 원리
-
신경망은 합성 함수의 구조:
f(x) = f3(f2(f1(x))) -
Chain Rule을 적용하면 다음과 같이 분해:
∂L/∂x = ∂L/∂f3 * ∂f3/∂f2 * ∂f2/∂f1 *∂f1/∂x
2.3 계산 절차
- Feed-forward로 출력값 및 Loss 계산
- Back-propagation을 통해 출력층부터 역방향으로 각 층의 gradient 계산 (미분)
- Gradient Descent로 파라미터 업데이트
- 물론 Pytorch에서 Backward() 함수가 다 해줌..!

만두는 목말라