해당 글은 FastCampus - '[skill-up] 처음부터 시작하는 딥러닝 유치원 강의를 듣고,
추가 학습한 내용을 덧붙여 작성하였습니다.
1. Gradient Vanishing
- 딥러닝에서 Backpropagation은 Chain Rule 기반으로 이전 Gradient를 재사용해서 Gradient를 계산
- 하지만 깊은 네트워크에서 입력층으로 갈수록 Gradient가 점점 작아지는 문제가 발생
- Why?
- Sigmoid, Tanh와 같은 활성화 함수(Activation function)의 Gradient는 1보다 작거나 같음
- 입력에 가까운 레이어일수록 여러 Gradient의 곱으로 계산됨
- 각 Gradient 항이 1보다 작기 때문에 입력층으로 갈수록 Gradient는 급격히 작아짐
→ Gradient Vanishing
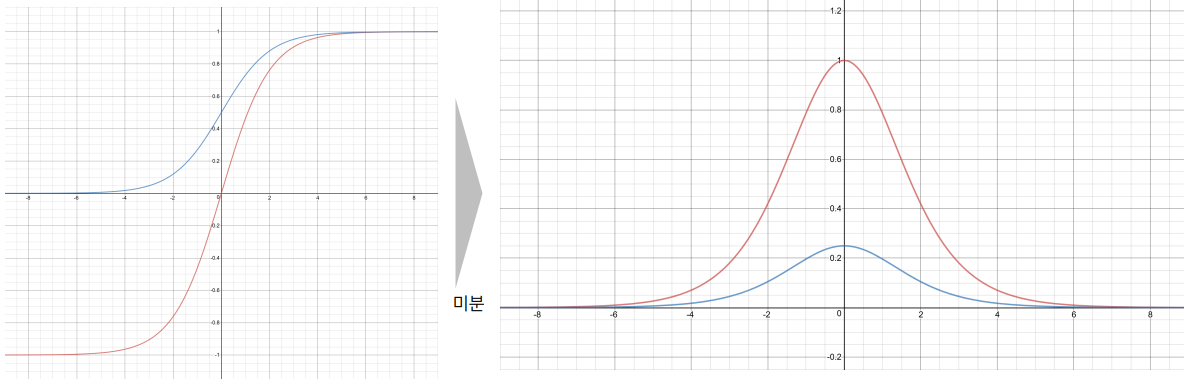
- 그 결과, 앞쪽 레이어의 파라미터는 거의 업데이트되지 않음
- ex) 0.2 0.6 0.2 = 0.024
2. ReLU (Rectified Linear Unit)
2.1 정의
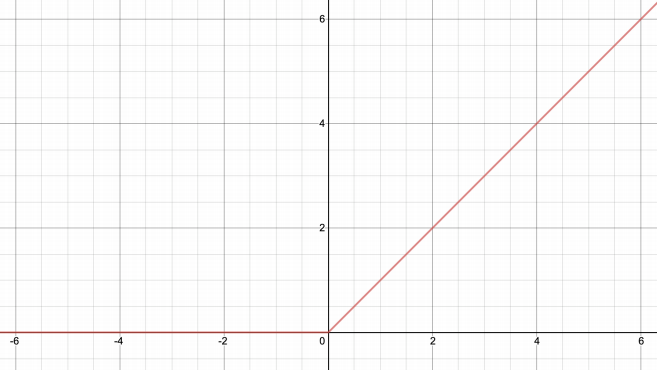
- 입력이 0보다 크면 그대로 출력, 0 이하이면 0 출력
- 두 개의 선형 함수로 구성된 단순한 구조
2.2 특징
- 양수 영역에서의 미분값은 항상 1 → 기존 gradient 흐름 유지
- 비선형성과 선형성을 적절히 조화시킴
- 계산이 매우 단순하고 빠름
- ReLU는 깊은 네트워크에서의 학습 안정성을 높여주는 활성화 함수
3. Leaky ReLU
3.1 정의
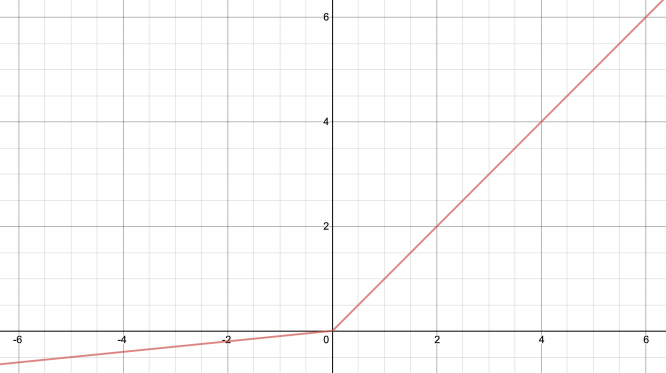
3.2 특징
- ReLU의 단점: 입력이 0 이하일 때 gradient가 0이 되어 학습되지 않음
- Leaky ReLU는 이를 해결하기 위해 음수 영역에도 작은 기울기를 부여
- 항상 Leaky ReLU가 더 좋은 건 아님!
4. Summary
- Sigmoid, Tanh와 같은 활성화 함수는 gradient vanishing 문제 유발
- ReLU는 gradient vanishing을 완화하고 학습 속도를 개선
- Leaky ReLU는 ReLU의 단점(음수 입력 구간의 학습 불능)을 보완
5. Pytorch 실습 코드
🎲[AI] LinearRegression에서 사용했던 Linear model과 비교
5.1 단순 shallow Linear model
- 상관성 높지 않고, 예측에 실패하는 케이스도 많았음
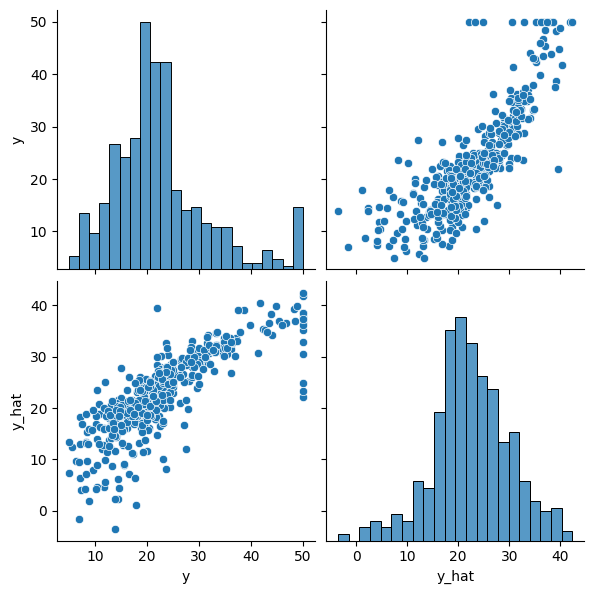
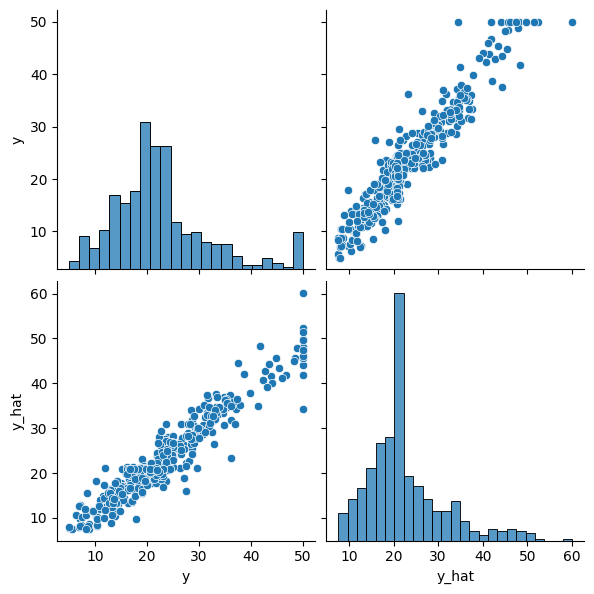
5.2 활성함수가 포함된 좀 더 deep model
- Standardization도 추가되긴 함 → 상관성 매우 높음
boston = fetch_openml(name='boston', version=1, as_frame=True)
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df["TARGET"] = boston.target
# df.head()
# Data Standardization: 입력 데이터 표준화 → 평균을 0으로, 표준편차를 1로 변환하여 데이터를 조정
scaler = StandardScaler()
scaler.fit(df.values[:, :-1])
df.iloc[:,:-1] = scaler.transform(df.values[:, :-1]) # N(0,1)
# df.head()
data = torch.from_numpy(df.values).float()
print(data.shape)
y = data[:, -1:]
x = data[:, :-1]
print(x.shape, y.shape)
n_epochs = 100000
learning_rate = 1e-4
print_interval = 5000
# relu = nn.ReLU()
# leaky_relu = nn.LeakyReLU(0.1)
## 내가 직접 Custom 하는 방법
class MyModel(nn.Module):
def __init__(self, input_dim, output_dim):
self.input_dim = input_dim
self.output_dim = output_dim
super().__init__()
self.linear1 = nn.Linear(input_dim, 3)
self.linear2 = nn.Linear(3, 3)
self.linear3 = nn.Linear(3, output_dim)
self.act = nn.ReLU()
def forward(self, x):
# |x| = (batch_size, input_dim)
h = self.act(self.linear1(x)) # |h| = (batch_size, 3)
h = self.act(self.linear2(h))
y = self.linear3(h) #Regression 문제에서 activation function은 가운데에만!
# |y| = (batch_size, output_dim)
return y
custom_model = MyModel(x.size(-1), y.size(-1))
print(custom_model)
## Sequential한 모델을 만드는 방법
sequential_model = nn.Sequential(
nn.Linear(x.size(-1), 3),
nn.LeakyReLU(),
nn.Linear(3, 3),
nn.LeakyReLU(),
nn.Linear(3, 3),
nn.LeakyReLU(),
nn.Linear(3, 3),
nn.LeakyReLU(),
nn.Linear(3, 3),
nn.LeakyReLU(),
nn.Linear(3, y.size(-1)),
)
print(sequential_model)
optimizer = optim.SGD(model.parameters(),
lr=learning_rate)
for i in range(n_epochs):
y_hat = model(x)
loss = F.mse_loss(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % print_interval == 0:
print('Epoch %d: loss=%.4e' % (i + 1, loss))
만두는 목말라