해당 글은 FastCampus - '[skill-up] 처음부터 시작하는 딥러닝 유치원 강의를 듣고,
추가 학습한 내용을 덧붙여 작성하였습니다.
1. Threshold와 평가 지표의 관계
- Sigmoid 출력값은 확률로 해석되며, 일반적으로 0.5를 기준으로 이진 분류 수행
- 하지만 상황에 따라 threshold를 조정할 수 있음
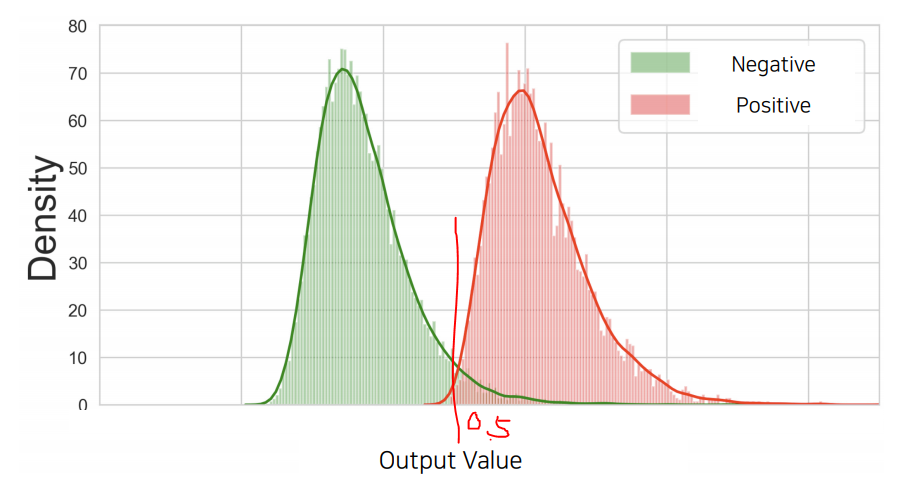
Threshold 조정에 따른 영향
- Threshold ↑: 모델은 더 보수적으로 True를 예측 (Precision ↑, Recall ↓)
- Threshold ↓: 모델은 더 관대하게 True를 예측 (Recall ↑, Precision ↓)
2. Precision & Recall
정의
| 실제값 | 예측값 Positive | 예측값 Negative |
|---|---|---|
| Positive | True Positive (TP) | False Negative (FN) |
| Negative | False Positive (FP) | True Negative (TN) |
-
→ 예측한 Positive 중에서 실제로 Positive인 비율 -
→ 실제 Positive 중에서 모델이 맞게 예측한 비율
(Tip: 회수율 이라고 외워라! → 실제 Positive에서 회수한 비율) -
다만 이 값들은 모두 Threshold에 영향을 받는다!
활용 예시
- 원자력 발전소 누출 감지: Recall 중요 (놓치면 위험)
- 주식 매수 판단: Precision 중요 (잘못된 예측으로 손해 가능)
3. F1 Score
-
Precision과 Recall의 조화 평균
-
Precision과 Recall 간 trade-off를 고려한 단일 지표
-
4. AUROC (Area Under Receiver Operating Characteristic Curve)
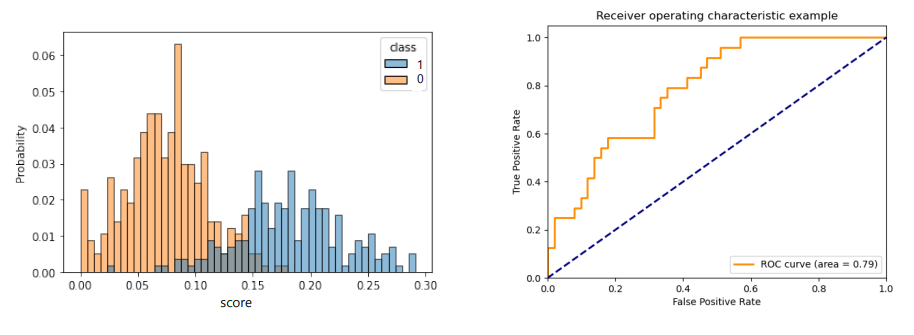
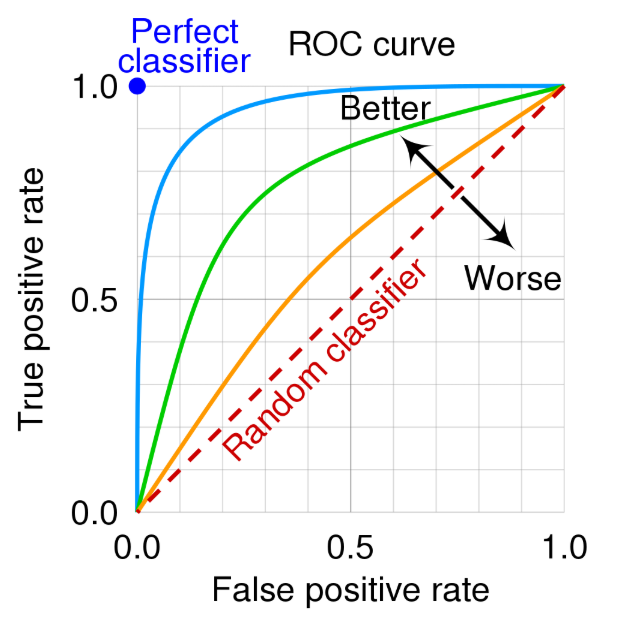
-
분류기의 True Positive Rate (TPR) vs False Positive Rate (FPR) 곡선 아래 면적
-
-
-
모델의 robustness를 평가하는 지표
-
0~1 사이 모든 Threshold 경우에 대해 Confusion Matrix를 만들고, 그 점들을 싹 다 찍어버리면 됨.
-
클래스 간의 분포 분리가 잘 될수록 AUROC는 1에 가까움
-
AUROC = 0.5이면 랜덤 추측과 유사한 성능
-
두 분포가 멀리 있을수록 Curve 넓이가 커짐
5. Pytorch 실습 코드
- early stop 적용
- Confusion Matrix 시각화
- Precision ,Recall, F1_score, AUROC 계산
cancer = load_breast_cancer()
df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
df['class'] = cancer.target
display(df.tail())
print(df.describe())
data = torch.from_numpy(df.values).float()
print(data.shape)
x = data[:, :-1]
y = data[:, -1:]
print(x.shape, y.shape)
# Train / Valid / Test ratio
ratios = [.6, .2, .2]
train_cnt = int(data.size(0) * ratios[0])
valid_cnt = int(data.size(0) * ratios[1])
test_cnt = data.size(0) - train_cnt - valid_cnt
cnts = [train_cnt, valid_cnt, test_cnt]
print("Train %d / Valid %d / Test %d samples." % (train_cnt, valid_cnt, test_cnt))
indices = torch.randperm(data.size(0))
x = torch.index_select(x, dim=0, index=indices)
y = torch.index_select(y, dim=0, index=indices)
x = x.split(cnts, dim=0)
y = y.split(cnts, dim=0)
for x_i, y_i in zip(x, y):
print(x_i.size(), y_i.size())
## Preprocessing
scaler = StandardScaler()
scaler.fit(x[0].numpy())
x = [torch.from_numpy(scaler.transform(x[0].numpy())).float(),
torch.from_numpy(scaler.transform(x[1].numpy())).float(),
torch.from_numpy(scaler.transform(x[2].numpy())).float()]
df = pd.DataFrame(x[0].numpy(), columns=cancer.feature_names)
df.tail()
## Build Model & Optimizer
model = nn.Sequential(
nn.Linear(x[0].size(-1), 25),
nn.LeakyReLU(),
nn.Linear(25, 20),
nn.LeakyReLU(),
nn.Linear(20, 15),
nn.LeakyReLU(),
nn.Linear(15, 10),
nn.LeakyReLU(),
nn.Linear(10, 5),
nn.LeakyReLU(),
nn.Linear(5, y[0].size(-1)),
nn.Sigmoid(),
)
print(model)
optimizer = optim.Adam(model.parameters())
## Train
n_epochs = 10000
batch_size = 32
print_interval = 100
early_stop = 1000
lowest_loss = np.inf
best_model = None
lowest_epoch = np.inf
train_history, valid_history = [], []
for i in range(n_epochs):
indices = torch.randperm(x[0].size(0))
x_ = torch.index_select(x[0], dim=0, index=indices)
y_ = torch.index_select(y[0], dim=0, index=indices)
x_ = x_.split(batch_size, dim=0)
y_ = y_.split(batch_size, dim=0)
train_loss, valid_loss = 0, 0
y_hat = []
for x_i, y_i in zip(x_, y_):
y_hat_i = model(x_i)
loss = F.binary_cross_entropy(y_hat_i, y_i)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += float(loss) # This is very important to prevent memory leak.
train_loss = train_loss / len(x_)
with torch.no_grad():
x_ = x[1].split(batch_size, dim=0)
y_ = y[1].split(batch_size, dim=0)
valid_loss = 0
for x_i, y_i in zip(x_, y_):
y_hat_i = model(x_i)
loss = F.binary_cross_entropy(y_hat_i, y_i)
valid_loss += float(loss)
y_hat += [y_hat_i]
valid_loss = valid_loss / len(x_)
train_history += [train_loss]
valid_history += [valid_loss]
if (i + 1) % print_interval == 0:
print('Epoch %d: train loss=%.4e valid_loss=%.4e lowest_loss=%.4e' % (
i + 1,
train_loss,
valid_loss,
lowest_loss,
))
if valid_loss <= lowest_loss:
lowest_loss = valid_loss
lowest_epoch = i
best_model = deepcopy(model.state_dict())
else:
if early_stop > 0 and lowest_epoch + early_stop < i + 1:
print("There is no improvement during last %d epochs." % early_stop)
break
print("The best validation loss from epoch %d: %.4e" % (lowest_epoch + 1, lowest_loss))
model.load_state_dict(best_model)
## Loss History
plot_from = 2
plt.figure(figsize=(20, 10))
plt.grid(True)
plt.title("Train / Valid Loss History")
plt.plot(
range(plot_from, len(train_history)), train_history[plot_from:],
range(plot_from, len(valid_history)), valid_history[plot_from:],
)
plt.yscale('log')
plt.show()
## Let's see the result!
test_loss = 0
y_hat = []
with torch.no_grad():
x_ = x[2].split(batch_size, dim=0)
y_ = y[2].split(batch_size, dim=0)
for x_i, y_i in zip(x_, y_):
y_hat_i = model(x_i)
loss = F.binary_cross_entropy(y_hat_i, y_i)
test_loss += loss # Gradient is already detached.
y_hat += [y_hat_i]
test_loss = test_loss / len(x_)
y_hat = torch.cat(y_hat, dim=0)
print("Test loss: %.4e" % test_loss)
y_act = y[2]
y_pred = y_hat > 0.5
# Confusion Matrix
cm = confusion_matrix(y_act, y_pred)
print("Confusion Matrix:")
print(cm)
# Accuracy
acc = accuracy_score(y_act, y_pred)
print(f"Accuracy: {acc:.4f}")
# Recall (기본: binary 이면 1 class 기준)
rec = recall_score(y_act, y_pred)
print(f"Recall: {rec:.4f}")
# F1 Score
f1 = f1_score(y_act, y_pred)
print(f"F1 Score: {f1:.4f}")
df = pd.DataFrame(torch.cat([y[2], y_hat], dim=1).detach().numpy(),
columns=["y", "y_hat"])
sns.histplot(df, x='y_hat', hue='y', bins=50, stat='probability')
plt.show()
from sklearn.metrics import roc_auc_score
roc_auc_score(df.values[:, 0], df.values[:, 1])
만두는 목말라