Chapter 3 딥러닝 시작하기
Tensorflow
- 머신러닝을 위한 오픈소스 플랫폼: 딥러닝 프레임워크
- 구글이 주도적으로 개발: 구글 코랩에 기본 장착
- Keras라는 고수준 API 병합
- Tensor: 벡터나 행렬
- Graph: 텐서가 흐르는 경로
- Tensorflow: 텐서가 graph를 통해 흐른다

딥러닝의 기초.Keras
-
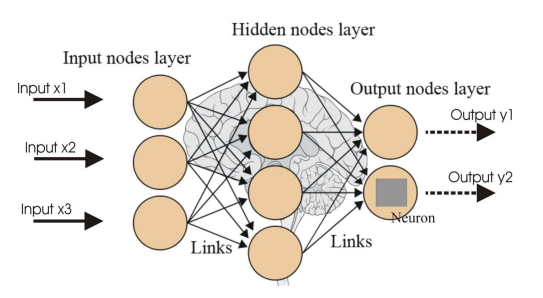
Neural Net
-
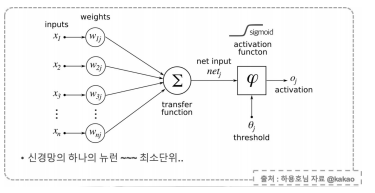
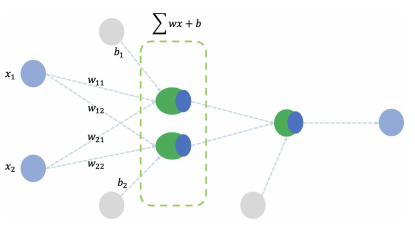
뉴런
-> 입력, 가중치, 활성화 함수, 출력으로 구성
-> 뉴런으로 학습할 때 변하는 것은 가중치, 처음에는 초기화를 통해 랜덤 값 넣고, 학습과정에서 일정한 값으로 수렴
-
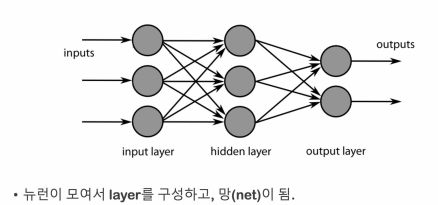
레이어와 망(net)
-
딥러닝
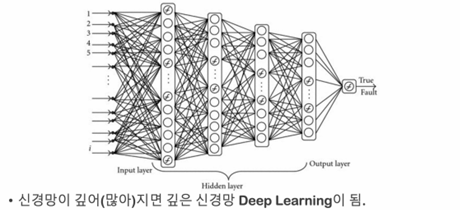
-
loss
-> 학습을 위해서는 loss(cost) 함수를 정해주어야 함
-> loss함수는 정답까지 얼마나 멀리 있는지를 측정하는 함수
-> 옵티마이저 선정: 옵티마이저는 loss를 어떻게 줄일 것인지 결정하는 방법을 선택하는 것 -
optimizer: loss 함수를 최소화하는 가중치를 찾아가는 과정에 대한 알고리즘
XOR 문제

- 선형 모델로는 XOR를 풀 수 없음
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(2, input_shape=(2,), activation='sigmoid'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
분류에 적용
-
One hot encoding
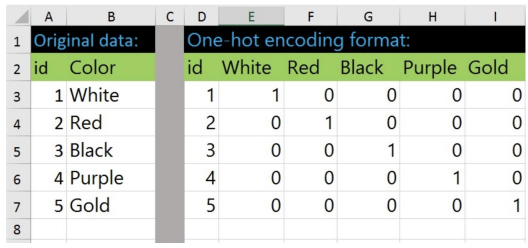
-
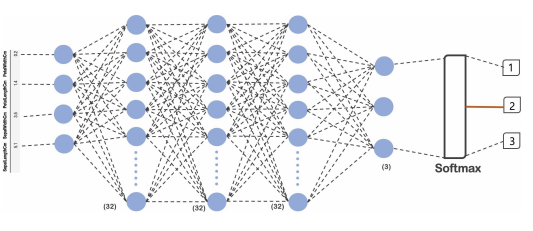
net 구성
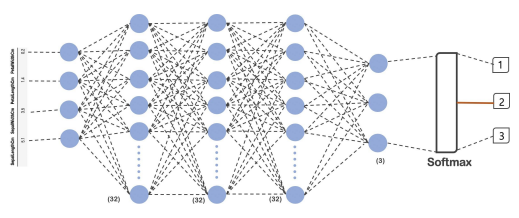
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(32, input_shape=(4,), activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(3, activation='softmax')
]) -
activation
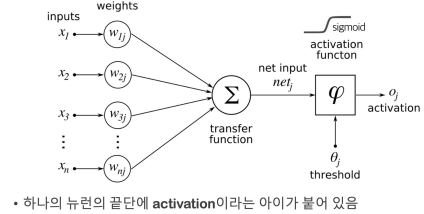
-
역전파 back-propagation
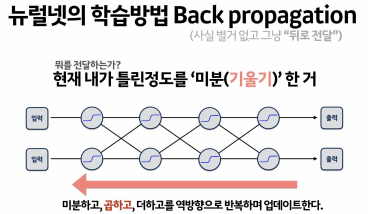
-
역전파에서는 signoid 문제가 있음

-
gradient vanishing
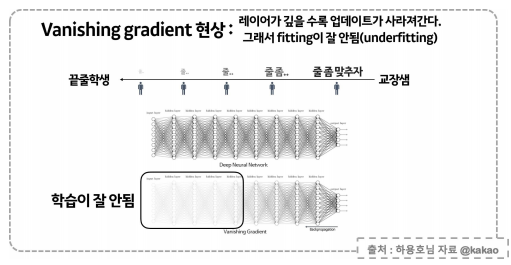
-
ReLU
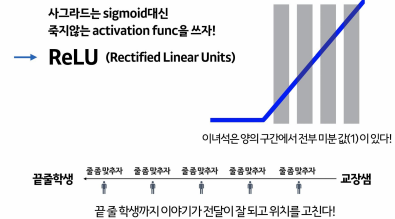
-
출력이 3개 이상 일때는 softmax
-
gradient decent

-
SGD
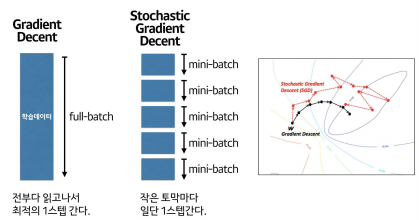
-
GD vs SGD
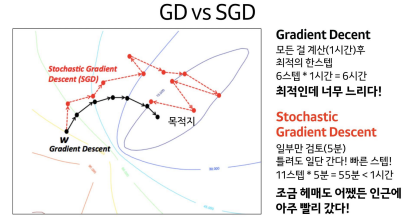
-
옵티마이저 선택은 방향과 보폭이 중요
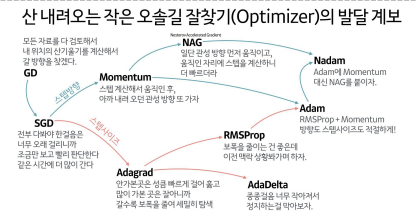
-
데이터가 복잡할 때는 Adam 옵티마이저 사용
이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
