분류 성과 지표 정리
- Confusion Matrix
- Accuracy
- Precision
- Recall
- Specificity
- F1 Score
- ROC-AUC Curve
1. Confusion Matrix (혼동 행렬)
Confusion Matrix는 분류 모델의 예측 결과를 정리한 표
- TP(참 양성), TN(참 음성), FP(거짓 양성), FN(거짓 음성)으로 구성
| 실제 / 예측 | Positive(1) | Negative(0) |
|---|---|---|
| Positive(1) | TP | FN |
| Negative(0) | FP | TN |
2. Accuracy (정확도)
분류 모델이 전체 데이터에서 얼마나 정확하게 예측했는지
✅ 장점: 직관적인 성능 평가 가능
❌ 단점: 데이터가 불균형할 경우 성능 해석이 어려움 (예: 99%가 Negative일 때 Accuracy가 높아도 실제 성능이 좋다고 보기 어려움)
3. Recall (재현율, 민감도)
실제 Positive 중에서 모델이 올바르게 Positive로 예측한 비율
FN(거짓 음성)이 중요한 경우 사용 (예: 질병 진단, 사기 탐지)
✅ 장점: FN(실제 Positive를 놓치는 경우)을 최소화할 때 유용
❌ 단점: FP가 증가할 수 있음
4. Precision (정밀도)
모델이 Positive라고 예측한 것 중 실제로 Positive인 비율
FP(거짓 양성)가 중요한 경우 사용 (예: 스팸 필터링, 광고 추천)
✅ 장점: FP(실제 Negative를 Positive로 잘못 예측하는 경우)를 최소화할 때 유용
❌ 단점: FN이 증가할 수 있음
5. Specificity (특이도)
실제 Negative 중에서 모델이 올바르게 Negative로 예측한 비율
Recall과 반대 개념 (예: 정상인을 질병으로 진단하면 안 되는 경우)
✅ 장점: FP를 줄이는 데 유용
❌ 단점: FN이 증가할 수 있음
6. F1 Score (F1 점수)
Precision과 Recall의 조화 평균
두 지표 간 균형을 맞추는 데 사용
✅ 장점: Precision과 Recall의 균형을 맞출 때 유용
❌ 단점: 데이터 불균형이 심할 경우 한계가 있을 수 있음
7. ROC-AUC Curve (ROC 곡선 & AUC)
ROC (Receiver Operating Characteristic) 곡선은 TPR(Recall)과 FPR(1-Specificity) 간의 관계를 나타낸 그래프
AUC (Area Under the Curve)는 곡선 아래 면적으로, 모델의 전체적인 성능을 평가
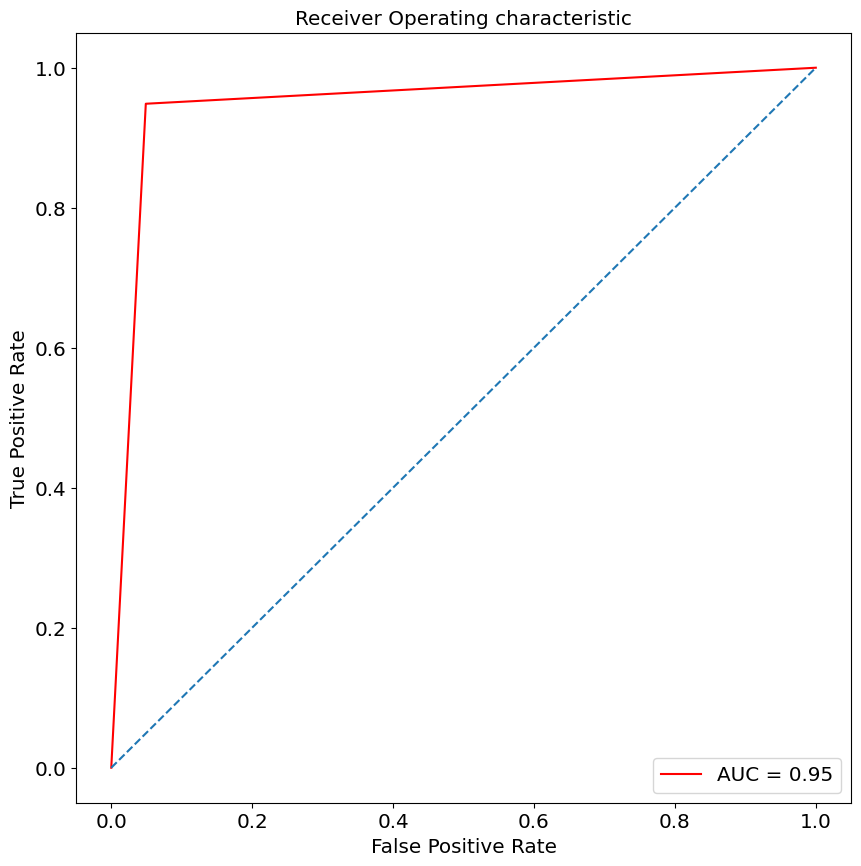
✅ 장점: 임계값 변화에 따른 모델 성능을 비교할 수 있음
❌ 단점: 특정 상황에서는 Precision-Recall Curve가 더 유용할 수도 있음
✅ 정리
| 지표 | 의미 | 활용 예시 |
|---|---|---|
| Accuracy | 전체 샘플에서 맞춘 비율 | 데이터 불균형이 심하지 않을 때 |
| Recall | 실제 Positive 중 예측 성공 비율 | 질병 진단, 사기 탐지 (FN 최소화) |
| Precision | 예측한 Positive 중 실제 Positive 비율 | 스팸 필터링, 광고 추천 (FP 최소화) |
| Specificity | 실제 Negative 중 예측 성공 비율 | 정상인을 질병으로 진단하면 안 되는 경우 |
| F1 Score | Precision과 Recall의 조화 평균 | Precision vs Recall 균형이 필요할 때 |
| ROC-AUC | TPR과 FPR의 관계, AUC로 성능 평가 | 임계값을 조정하면서 모델 성능 비교 |
