
✔ 디바이스 설정
## Device 설정
DEVICE = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
print(f"using PyTorch version: {torch.__version__}, Device: {DEVICE}")출력:
using PyTorch version: 2.2.1+cu121, Device: cpu✔ 데이터 로드
# MNIST 데이터 받아오기
train_dataset = datasets.FashionMNIST(root='FashionMNIST_data/', train=True, download=True,
transform=transforms.ToTensor()) #0~255 이미지 픽셀값을 0~1 사이로 정규화 시킴
test_dataset = datasets.FashionMNIST(root='FashionMNIST_data/', train=False, download=True,
transform=transforms.ToTensor()) #0~255 이미지 픽셀값을 0~1 사이로 정규화 시킴root 는 학습/테스트 데이터가 저장되는 경로.
train 은 학습용 또는 테스트용 데이터셋 여부를 지정.
download=True 는 root 에 데이터가 없는 경우 인터넷에서 다운로드.
transform 과 target_transform 은 특징(feature)과 정답(label) 변형(transform)을 지정.
✔ 데이터 분할
## Train & Test 데이터 shape 확인
## Train = 60_000개
print(len(train_dataset))
## 분리 비율 설정
train_dataset_size = int(len(train_dataset) * 0.85)
validation_dataset_size = int(len(train_dataset) * 0.15)
## 데이터 세트를 분리
train_dataset, validation_dataset = random_split(train_dataset, [train_dataset_size, validation_dataset_size])
## train = 51000개 Validation = 9000 개 test = 1000개
print(len(train_dataset), len(validation_dataset), len(test_dataset))⭐random_split
random_split 함수는 데이터 세트를 주어진 길이의 겹치지 않는 새 데이터 세트로 무작위로 분할한다.
🔎기본형
torch.utils.data.random_split(dataset, lengths, generator=<torch._C.Generator object>)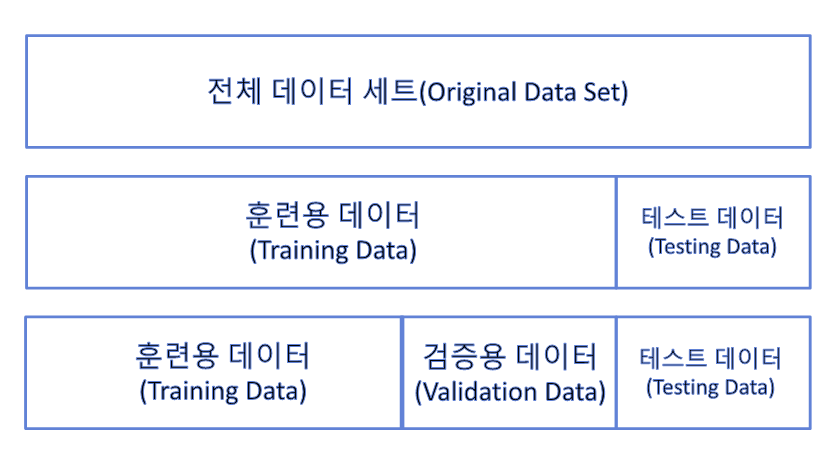
머신러닝에서 우리의 목표
머신러닝에서 우리의 목표는training dataset을 이용하여 모델을 학습하고, 학습된 모델을 이용하여 관측되지 않았던 새로운 데이터에 대해 예측을 수행하는 것이다. 머신러닝 연구 및 개발에서는training dataset에 포함되지 않는 데이터를 모아서test dataset를 구성하고,test dataset에 대해 모델의 성능을 측정함으로써 새로운 데이터에 대한 모델의 성능을 평가한다.
test dataset는 학습 과정에서 참조할 수 없기 때문에 머신러닝 모델은
training dataset만을 가지고test dataset에 대한 정확한 예측이 가능하도록 학습되어야한다.
✔DataLoader로 학습용 데이터 준비하기
## BATCH_SIZE 설정
BATCH_SIZE = 64
'''
DataLoader 객체(iterator)로 전달
DataLoader 객체(iterator)는 일반적으로 샘플들을 《미니배치(minibatch)》로 전달하고,
매 에폭(epoch)마다 데이터를 다시 섞어서 과적합(overfit)을 막고,
Python multiprocessing 을 사용하여 데이터 검색 속도를 높여준다.
'''
train_dataset_loader = DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True)
validation_dataset_loader = DataLoader(dataset=validation_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_dataset_loader = DataLoader(dataset=test_dataset, batch_size=BATCH_SIZE, shuffle=True)⭐DataLoader
Dataset은 데이터셋의 특징(feature)을 가져오고 하나의 샘플에 정답(label)을 지정하는 일을 한 번에 한다. 모델을 학습할 때, 일반적으로 샘플들을 《미니배치(minibatch)》로 전달하고, 매 에폭(epoch)마다 데이터를 다시 섞어서 과적합(overfit)을 막고, Python의 multiprocessing 을 사용하여 데이터 검색 속도를 높이려고 한다.
DataLoader는 간단한 API로 이러한 복잡한 과정들을 추상화한 순회 가능한 객체(iterable)이다
결론적으로 DataLoader는 앞서 만들었던 dataset을 input으로 넣어주면 여러 옵션(데이터 묶기, 섞기, 알아서 병렬처리)을 통해 batch를 만들어준다. DataLoader는 iterator 형식으로 데이터에 접근 하도록 하며 batch_size나 shuffle 유무를 설정할 수 있다.
Over-Fitting(과적합)
과적합이란, train-set에 너무 과하게 모델이 최적화된 상태를 말한다.
모델이 훈련 데이터에만 잘 맞춰진 경우로 결과가 훈련 데이터 정확도는 높지만 새롭게 입력 받는 테스트 데이터의 정확도는 낮아 모델 성능이 떨어지는 현상이다.
모델이 over-fitting되면, train-set에서는 정확도가 매우 높게 나오지만 test-set에서는 낮은 정확도가 나온다.과적합을 예방하는 방법
1. 데이터를 추가 수집.
2. feature의 개수를 감소시키기.
3. Regularization
4. Early Stopping
5. Model Averaging
6. Dropout
설명: https://aistudy9314.tistory.com/14
🔎기본형
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)출처:
https://github.com/a2ran/prac_ds/blob/main/week2/requirements/week2_lecture.ipynb - 코드
https://aistudy9314.tistory.com/14
