[pytorch] Pytorch-lightning으로 mnist 구현 코드 분석(3) - 모델 구성(CNN-Convolutional Neural Network)
DeepLearning

✔CNN 모델(Convolutional Neural Network)
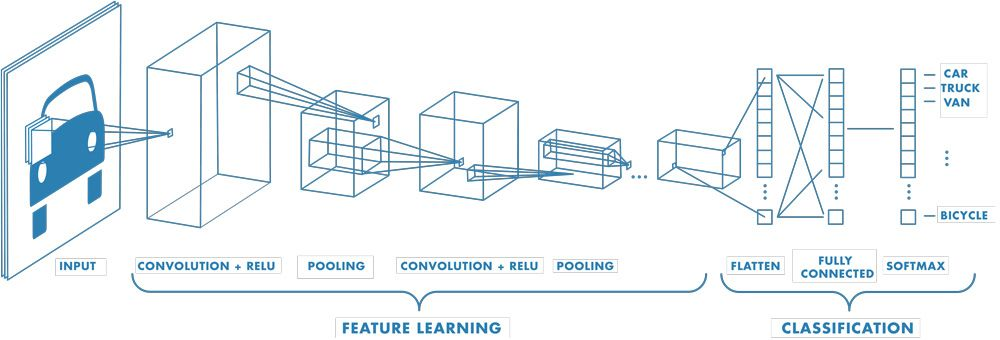
CNN 모델은 Convolutional Neural Network 모델의 약자로 인간의 시신경 구조를 묘사한 구조이다.
주로 이미지나 영상 데이터를 처리할 때 사용한다.
물론 요즘은 트랜스포머 기반의 네트워크를 많이 사용한다. 하지만 CNN도 많이 사용되고 트랜스포머와 CNN의 조합도 많이 사용되고 있다.
⭐Convolution layer - 특징 추출
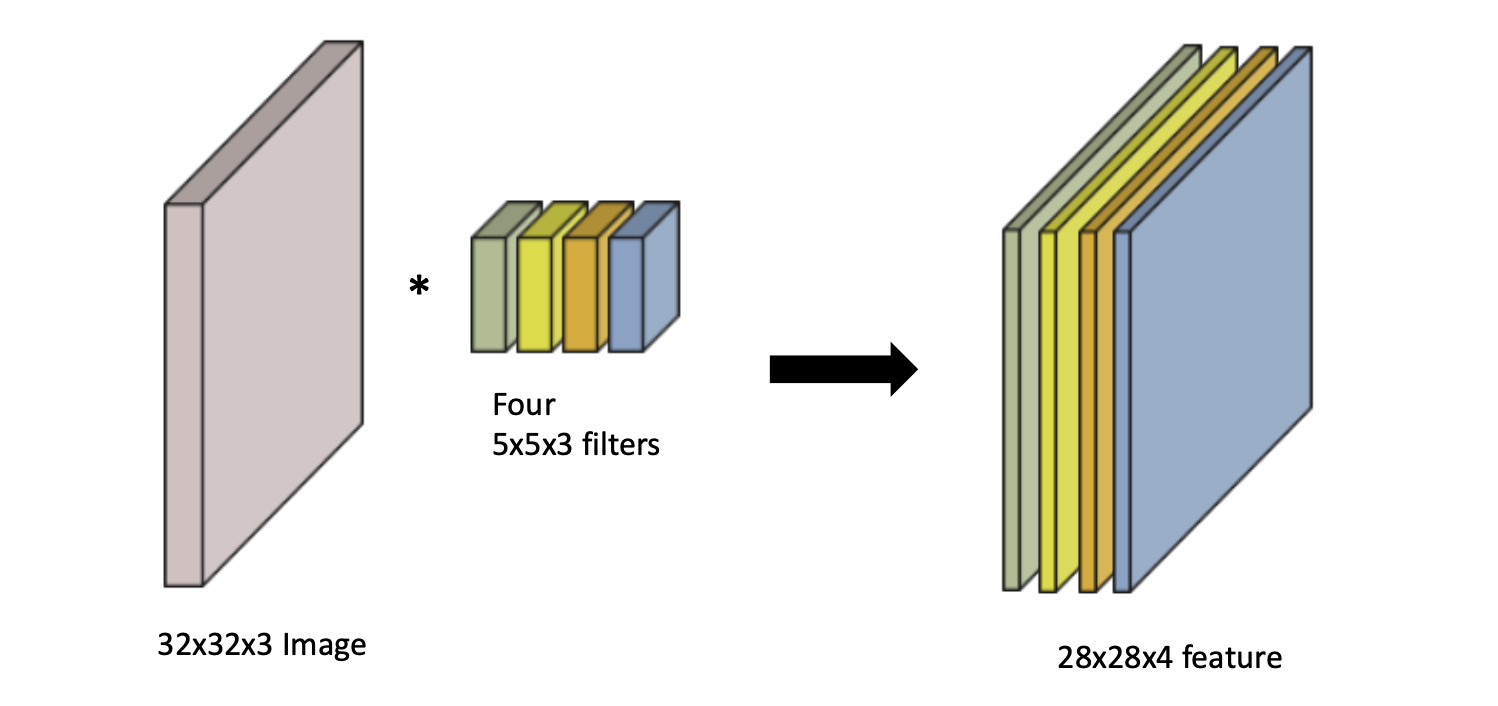
Convolution layer는 한글로 번역하면 합성곱 레이어인 만큼 합성곱 연산을 사용한다.
Convolutional Layer는 합성곱 연산을 통해서 이미지의 특징을 추출하는 역할을 한다.
커널(필터)를 통해 합성곱 연산을 하여 행렬을 완성한다.
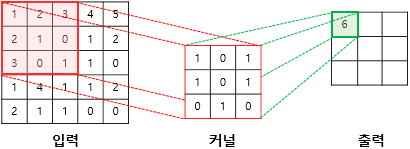
첫번째 칸
두번째 칸
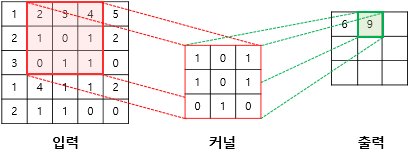
🔎필터(커널)

커널(필터)를 통해 합성곱 연산을 하여 행렬을 완성한다.
이 과정에서 변환된 이미지들은 색상, 선, 형태, 경계 등의 특징(feature)이 뚜렷해진다.
필터를 통과한 이미지는 특성값을 가지고 있어 feature map 또는 activation map이라고 한다.
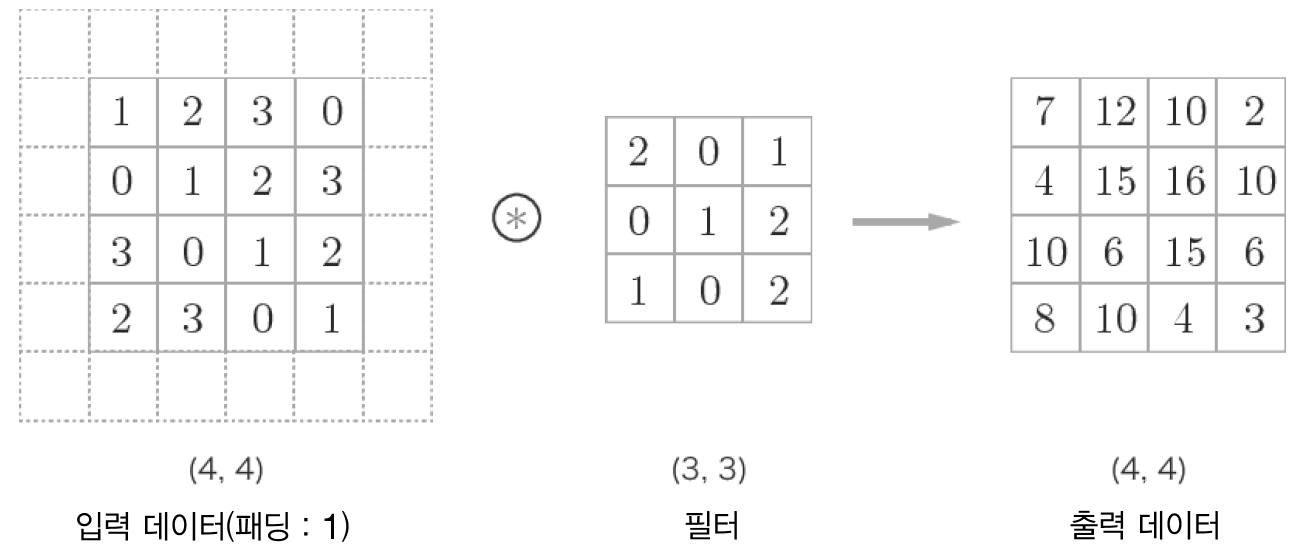
🔎패딩
합성곱 연산을 수행하기 전에 입력 데이터 주변에 특정 값을 채우는 것을 패딩(padding)이라고 한다.
만약, 합성곱 층을 여러개 쌓았다면 최종적으로 얻은 특성 맵은 초기 입력보다 매우 작아진 상태가 되버린다. 합성곱 연산 이후에도 특성 맵의 크기가 입력의 크기와 동일하게 유지되도록 하고 싶다면 패딩(padding)을 사용하면 된다.
🔎편향(bias)
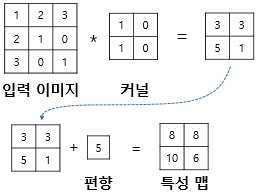
편향과 가중치를 사용하는 이유
https://jh2021.tistory.com/3
⭐Relu layer(Rectified Linear Unit layer) - 활성화 함수
ReLu는 Rectified Linear Unit의 약자로 해석해보면 정류한 선형 유닛이라고 해석할 수 있다
ReLu 함수의 범위는 f(x)=max(0,x) 양수이기 때문에 vanishing gradient 문제점을 극복하고 학습 속도와 성능을 향상시켜 CNN에서 주로 사용되는 활성화 함수이다.
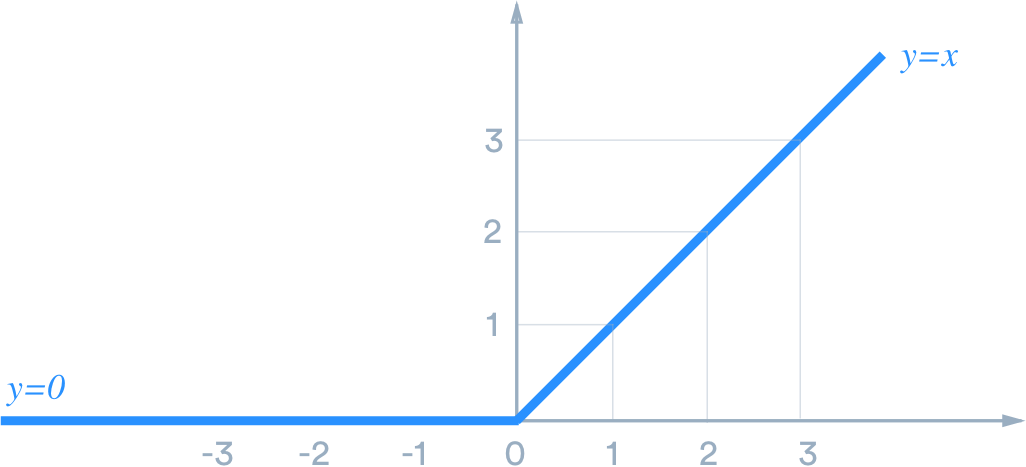
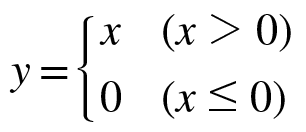
🔎 vanishing gradient 문제점 (기울기 소멸 문제)
신경망의 활성함수의 도함수 값이 계속 곱해지다 보면 가중치에 따른 결과값의 기울기가 0이 되어 버려서, 경사 하강법을 이용할 수 없게 되는 문제이다. 미분을 계속하다보면 음수 영역으로 가는 경우를 방지한다고 이해하면 될 것이다.
Relu layer의 단점 (Dying Relu)
입력값이 음수인 경우 기울기가 0이 되어 가중치 업데이트가 안될 수 있다(가중치가 업데이트 되는 과정에서 가중치 합이 음수가 되면 0만 반환되어 아무것도 변하지 않는 현상이 발생한다.
⭐Pooling layer(feature map의 feature map) - 특징 추출
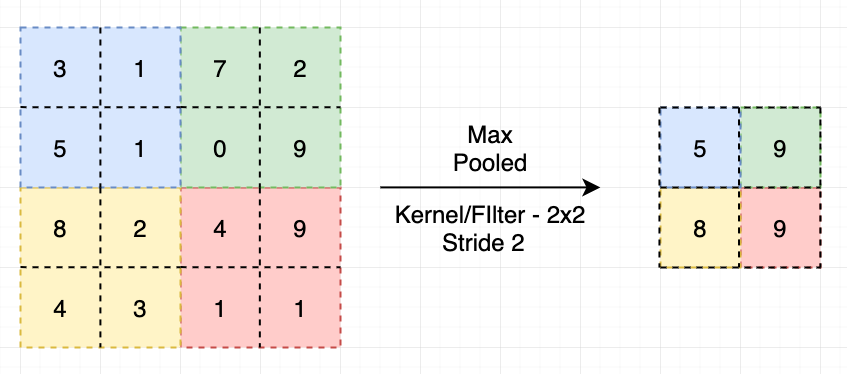
Pooling layer는 대부분 convolutional layer 바로 다음에 위치해 공간(spatial size)을 축소해준다.
CNN 에서 pooling layer는 네트워크의 파라미터 갯수나 연산량을 줄이기 위해 input에서 spatial 하게 downsampling을 진행해 사이즈를 줄이는 역할을 한다.
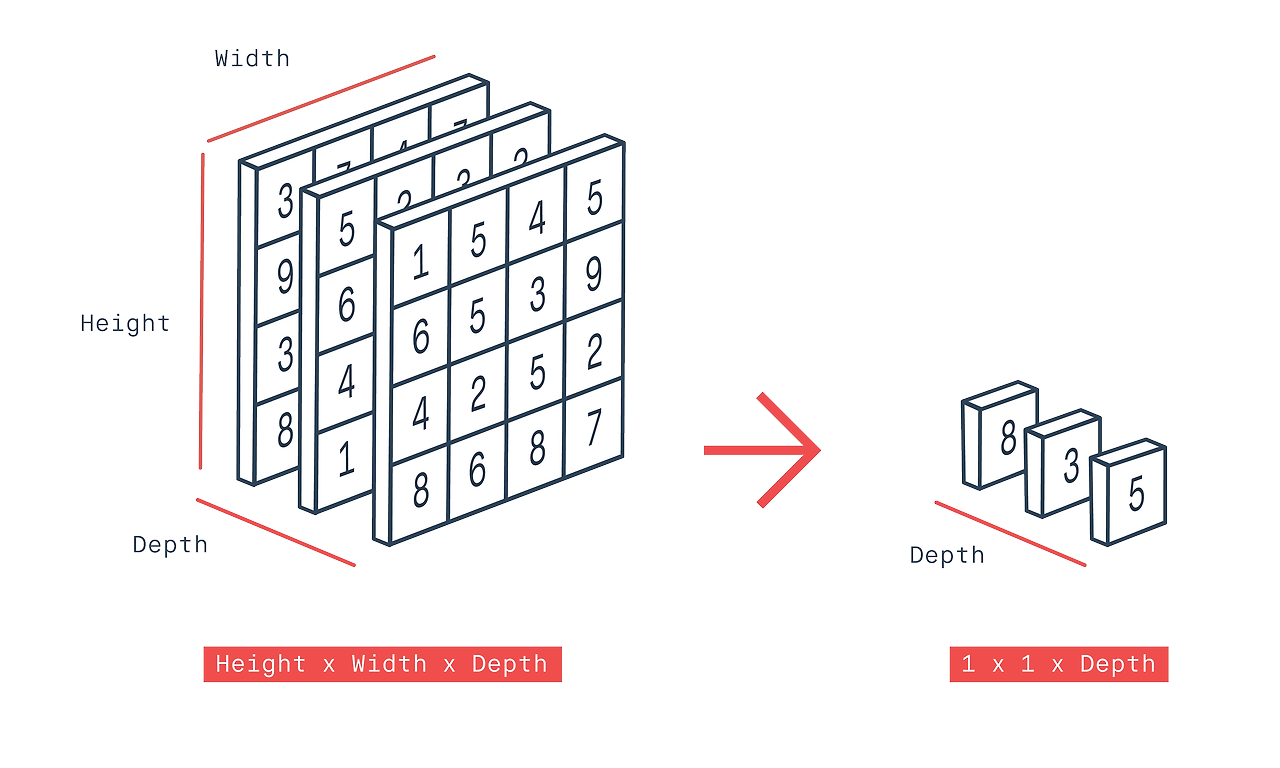
이때 width, height의 크기만 줄어들고 채널의 크기는 고정) 입력 데이터의 크기가 축소되고 학습하지 않기 때문에 파라미터 수가 줄어들어 오버피팅이(Overfitting) 발생하는 것을 방지해준다.
Pooling layer의 종류
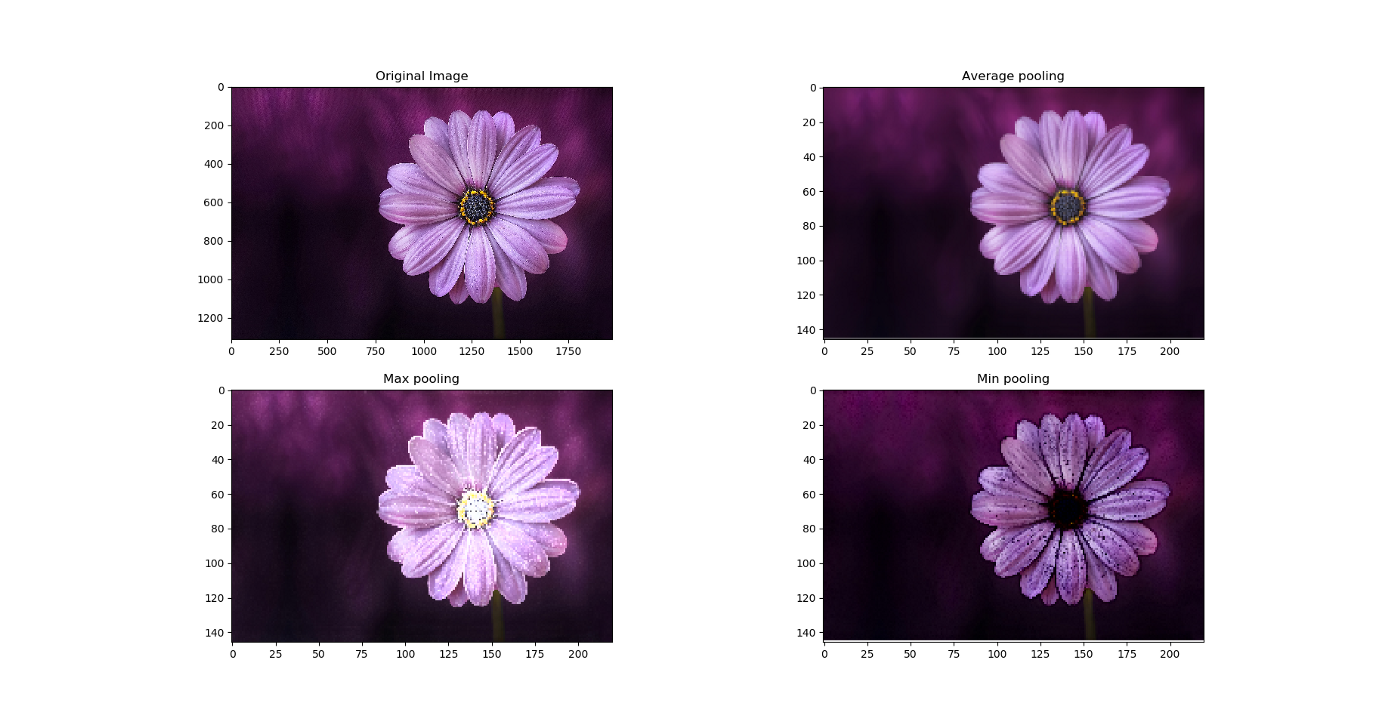
풀링(Pooling)에는 맥스 풀링(Max Pooing)과 평균 풀링(Average Pooling)이 존재한다.
1. 맥스 풀링(Max Pooing) : 대상 이미지 영역에서 최대값을 구함
2. 평균 풀링(Average Pooling) : 대상 이미지 영역에서 평균값을 구함
⭐Dropout - 정규화
Dropout은 오버피팅을 줄이기 위한 정규화(regularization) 기술이다.
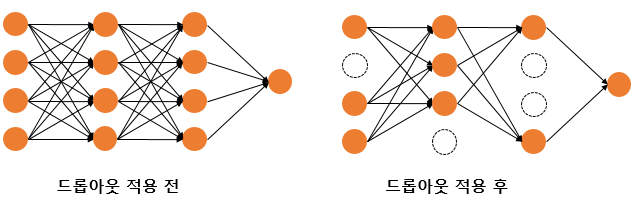
Dropout의 비율을 0.5로 한다면 학습 과정마다 랜덤으로 절반의 뉴런을 사용하지 않고, 절반의 뉴런만을 사용한다.
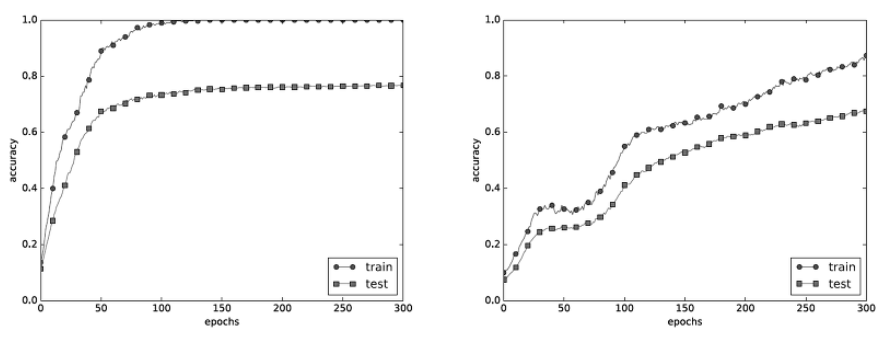
그림과 같이 드롭아웃을 적용하니 훈련 데이터와 시험 데이터에 대한 정확도 차이가 줄었다.
또, 훈련 데이터에 대한 정확도가 100%에 도달하지도 않게 되었다.
이처럼 드롭아웃을 이용하면 표현력을 높이면서도 오버피팅을 억제할 수 있다.
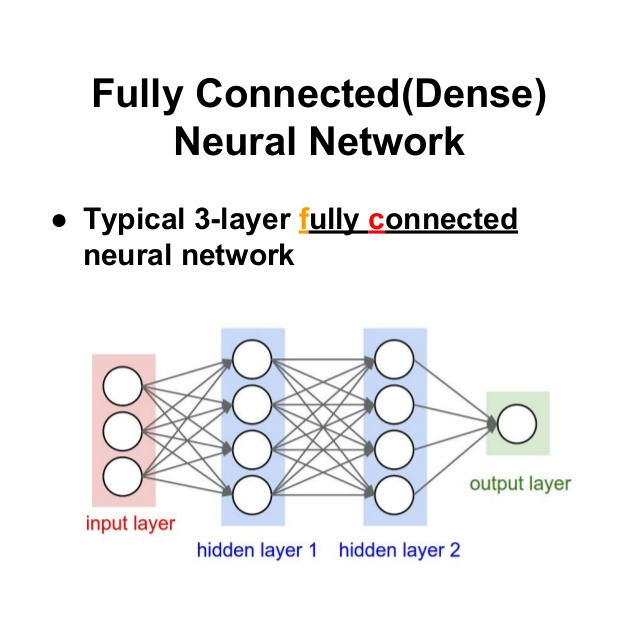
⭐FC layer(Fully Connected Layer) - 평탄화/분류
Fully Connected Layer는 이전 레이어의 출력을 평탄화하여 다음 스테이지의 입력이 될 수 있는 단일 벡터로 변환한다.
Fully connected layer의 목적은 Convolution/Pooling 프로세스의 결과를 취하여 이미지를 정의된 라벨로 분류하는 데 사용하는 것이다.
✔ 모델 구성 (클래스 정의)
class MyCNNModel(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=1,
out_channels=32,
kernel_size=3, padding=1) # 필터 32개(output channel이 32이기 때문에), 패딩이 적용되었기 때문에 컨볼루션 layer를 통과한 데이터의 크기는 변경되지 않는다.
self.conv2 = nn.Conv2d(in_channels=32,
out_channels=64,
kernel_size=3, padding=1) # 필터 64개(output channel이 64이기 때문에), 패딩이 적용되었기 때문에 컨볼루션 layer를 통과한 데이터의 크기는 변경되지 않는다.
self.pooling = nn.MaxPool2d(kernel_size=2, stride=2) #커널 사이즈
#가 2이므로 데이터의 크기가 1/2로 바뀜
self.fc1 = nn.Linear(7 * 7 * 64, 256)
self.fc2 = nn.Linear(256, 10)
self.dropout25 = nn.Dropout(p=0.25)
self.dropout50 = nn.Dropout(p=0.5)
def forward(self, data):
data = self.conv1(data) #(28,28,1)
data = torch.relu(data) #(28,28,32)
data = self.pooling(data) #(28,28,32)
data = self.dropout25(data) #(14,14,32)
data = self.conv2(data) #(14,14,32)
data = torch.relu(data) #(14,14,64)
data = self.pooling(data) #(14,14,32)
data = self.dropout25(data) #(7,7,32)
data = data.view(-1, 7 * 7 * 64)
data = self.fc1(data)
data = torch.relu(data)
data = self.dropout50(data)
logits = self.fc2(data)
return logits ⭐nn.Conv2d (Convolution)
🔎기본형
nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)in_channels (int): 입력 채널의 개수. 예를 들어, RGB 이미지의 경우 3개의 채널을 가지므로 in_channels는 3이 된다.
out_channels (int): 출력 채널의 개수, 즉 컨볼루션 필터의 개수이다. 이 값이 클수록 더 복잡한 특징을 학습할 수 있지만, 모델의 파라미터 수가 증가하게 된다.
kernel_size (int 또는 tuple): 컨볼루션 필터의 크기. 예를 들어, 3x3 필터의 경우 kernel_size는 3 또는 (3, 3)으로 지정할 수 있다.
stride (int 또는 tuple, optional): 필터의 이동 간격, 즉 스트라이드(stride)입니다. 기본값은 1이며, 더 큰 값으로 설정하면 출력 특징 맵의 크기가 작아지게 된다.
padding (int 또는 tuple, optional): 입력 데이터의 가장자리에 추가되는 패딩의 크기이다. 기본값은 0이며, 패딩을 사용하면 출력 특징 맵의 크기를 보존하면서 입력 데이터의 가장자리 정보를 유지할 수 있다.
dilation (int 또는 tuple, optional): 딜레이션(dilation) 레이트이다. 딜레이션은 필터의 간격을 더 크게 두어 더 넓은 영역의 정보를 가져오는 데 사용된다. 기본값은 1이며, 값이 커질수록 필터의 영역이 더 넓어지게 된다.
groups (int, optional): 입력 및 출력 채널을 묶는(grouping) 개수이다. 기본값은 1이며, 값이 크면 채널 간의 관련성을 줄이는 효과가 있다.
bias (bool, optional): 편향(bias)을 사용할지 여부를 결정하는 플래그이다. 기본값은 True이며, False로 설정하면 편향이 사용되지 않는다.
⭐nn.MaxPool2d (Pooling)
🔎기본형
torch.nn.MaxPool2d(kernel_size, stride=None,
padding=0, dilation=1, return_indices=False,
ceil_mode=False)kernel_size: 커널 사이즈 (int or tuple)
stride: stride(몇 칸씩 이동할지) 사이즈 (int or tuple, 기본 값 = 1)
padding: zero padding 사이즈 (int or tuple, 기본 값 = 0)
dilation: 커널 사이 간격 사이즈를 조절한다.
return_indices: True 일 경우 최대 인덱스 를 반환한다.
ceil_mode: True 일 경우, Output Size에 대하여 바닥 함수대신, 천장 함수를 사용한다.
바닥 함수와 천장 함수
수학과 컴퓨터 과학에서 바닥 함수는 각 실수 이하의 최대 정수를 구하는 함수이다. 천장 함수는 각 실수 이상의 최소 정수를 구하는 함수이다. 바닥 함수는 내림 함수 · 버림 함수 · 최대 정수 함수라고도 하며, 천장 함수는 올림 함수 · 최소 정수 함수라고도 한다.
⭐nn.Linear (Fully Connected)
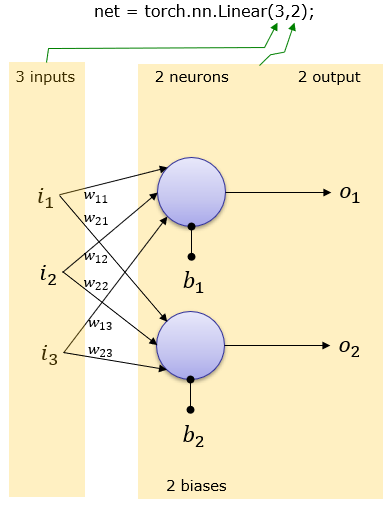
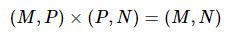
행렬곱 연산을 이용한 것으로써
예를 들어 fc = nn.Linear(P, N)를 예로 들면 P개의 input 노드를 받아 N개의 output 노드를 얻기 위해
(1,P) * (P,N) = (1,N)를 한다고 생각하면 된다.
🔎기본형
torch.nn.Linear(in_features, out_features, bias=True)in_features (int) – 입력 텐서의 크기. 입력 텐서의 차원(dimension) 또는 특성(feature)의 수
out_features (int) – 출력 텐서의 크기. 출력 텐서의 차원(dimension) 또는 특성(feature)의 수
bias (bool) – 편향(bias)을 사용할지 여부를 지정 , 기본값: True
⭐nn.Dropout (Dropout)
🔎기본형
torch.nn.Dropout(p=0.5, inplace=False)p: drop_prob, 노드를 얼만큼 활용 안 할지 ( Default: 0.5 - 50%만 활용)
inplace: true로 설정하면 제자리에서 작업 수행 (Default: False)
⭐TORCH.TENSOR.VIEW
파이토치 텐서의 뷰(View)는 넘파이에서의 리쉐이프(Reshape)와 같은 역할을 한다. Reshape라는 이름에서 알 수 있듯이, 텐서의 크기(Shape)를 변경해주는 역할을 합니다.
1개의 차원에 한해서 -1로 값 지정이 가능한데, 이 경우 자동으로 변환이 가능한 차원이지정되어 차원 배정이 이루어지게 된다.
자세한 설명
https://wikidocs.net/52846
✔ 모델 인스턴스 생성
model = MyCNNModel().to(DEVICE)
loss_function = nn.CrossEntropyLoss()
#CrossEntropy 손실 함수에는 softmax 함수가 포함되어 있다. 그렇기때문에 CrossEntropy 함수는 내부적으로 model 출력값인 logits에 softmax 함수를 먼저 적용 후 손실함수값을 계산한다.
optimizer = torch.optim.Adam(model.parameters(), lr = 1e-3) 출처:
https://github.com/neowizard2018/neowizard/blob/master/PyTorch/PyTorch_LEC16_CNN_FashionMNIST_Example_CPCP_9262.ipynb
https://kr.mathworks.com/discovery/convolutional-neural-network.html
https://jh2021.tistory.com/3
https://wikidocs.net/152775
https://m.blog.naver.com/bananacco/221928562116
https://deep-learning-study.tistory.com/169 - 사이토 고키 <밑바닥부터 시작하는 딥러닝> 정리
https://indiantechwarrior.com/fully-connected-layers-in-convolutional-neural-networks/
https://ko.wikipedia.org/wiki/%EB%B0%94%EB%8B%A5_%ED%95%A8%EC%88%98%EC%99%80_%EC%B2%9C%EC%9E%A5_%ED%95%A8%EC%88%98
