#1. code1_normal_histogram
💡 **Q. np.random.normal로 random_data(x_data)를 만들기** ax.hist를 이용해 히스토그램을 그리기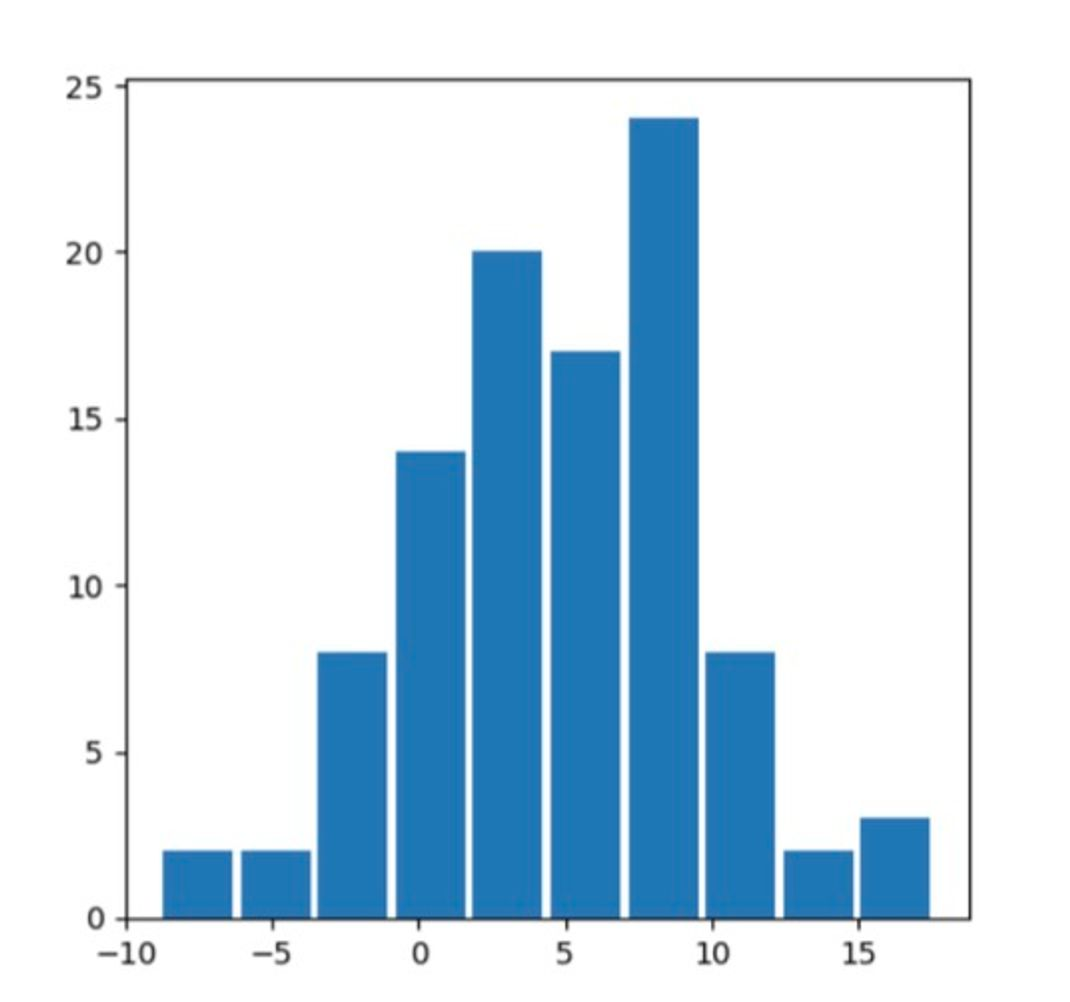
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(22)
n_data = 100
x_data = np.random.normal(loc = 5, scale = 5, size=(n_data, ))
fig, ax = plt.subplots(figsize=(5, 5))
ax.hist(x_data, rwidth=0.9)
plt.show()**질문**
- n_data = 100 / seed(22)를 한 이유?
- loc = 5 는 이해 완료, 하지만 scale = 5가 되어야 하는 이유를 모르겠,,?
- rwidth=0.9의 의미가 무엇인가요?
- 값을 바꾸기
#2. code2_dataset 1cluster
💡 **Q. 평균이 (5,3)이고 표준편차가 x, y 방향으로 모두 1인 (100, 2) dataset 만들기**#method.1
import numpy as np
import matplotlib.pyplot as plt
n_data = 100
x_data = np.random.normal(loc= 5, scale = 1, size=(n_data,))
y_data = np.random.normal(loc= 3, scale = 1, size=(n_data,))
x_data = x_data.reshape(-1, 1)
y_data = y_data.reshape(-1, 1)
data_ = np.hstack([x_data, y_data])
print(data_)#method.2
import numpy as np
import matplotlib.pyplot as plt
n_data = 100
data = np.random.normal(loc = [5, 3], scale=[1, 0.5], size=(n_data, 2))
print(np.mean(data, axis=0))
print(np.std(data, axis=0))**질문**
#3. code3_random_centroid
💡 **Q. 무게중심을 random하기 만들고, dataset의 모양이 (100, 2)이 되도록 만들기 scatter plot으로 시각화**import numpy as np
import matplotlib.pyplot as plt
centroid = np.random.uniform(low=-5, high = 5, size=(2, ))
n_data = 100
data = np.random.normal(loc=centroid, scale=1, size=(n_data, 2))
fig, ax = plt.subplots(figsize=(5, 5))
ax.scatter(centroid[0], centroid[1], c='red')
ax.scatter(data[:,0], data[:,1]
centroid를 중심으로 데이터를 만들어줌.
0,0처럼 보이지만 아님.
임의의 centroid를 뽑고, 그를 중심으로 데이터셋을 만드는 게 중요
따라서 centroid는 uniform / normal 등으로 뽑아도 된다.
#4. **code4_knn_x_dataset**
💡 **Q.** **4 class, class마다 100개의 점을 가지는 dataset 만들기 - (400, 2)** -> class들의 centroid는 랜덤하게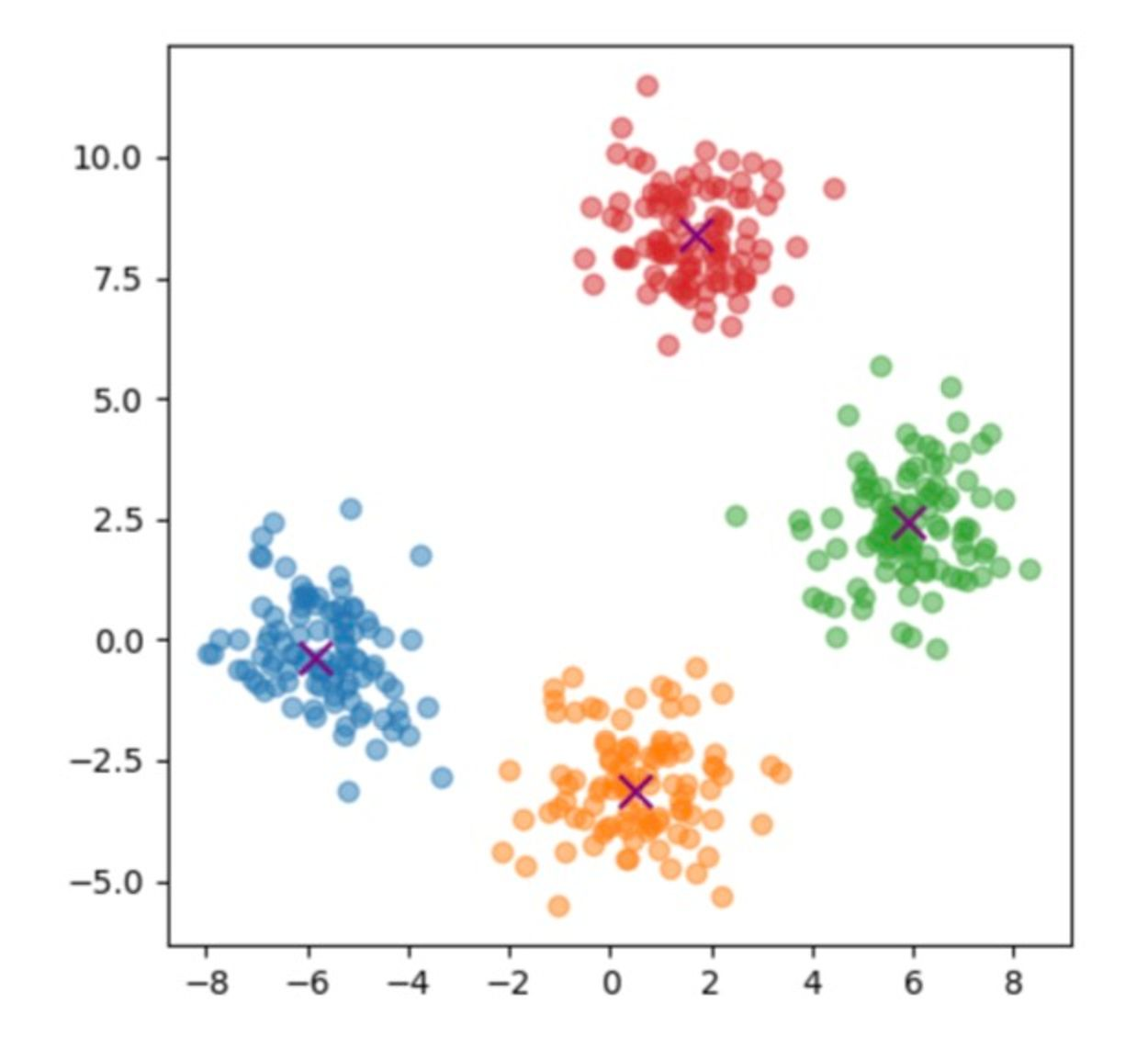
import numpy as np
import matplotlib.pyplot as plt
n_classes = 4
n_data = 100
data = []
centroids = []
for _ in range(n_classes):
centroid = np.random.uniform(low = -10, high = 10, size = (2, ))
data_ = np.random.normal(loc = centroid, scale = 1, size = (n_data,2))
centroids.append(centroid)
data.append(data_)
#연산하기 편하게 쌓기
centroids = np.vstack(centroids)
data = np.vstack(data)
fig, ax = plt.subplots(figsize=(5, 5))
#100개씩 자르려는 행위
for class_idx in range(n_classes):
#**#
data_ = data[class_idx * n_data : (class_idx + 1) * n_data]
ax.scatter(data_[:, 0], data_[:, 1], alpha=0.5)
for centroid in centroids:
ax.scatter(centroid[0], centroid[1], c='purple', marker='x', s=100)
plt.show()#5. **code5_targets**
💡 **Q.** **모든값이 0,1,2,3 모양이 (100,)인 ndarray**import numpy as np
import matplotlib.pyplot as plt
n_classes = 4
n_data = 100
data = []
for class_idx in range(n_classes):
data_ = class_idx * np.ones(100, )
data.append(data_)
data= np.hstack(data)
print(data.shape)#6. **code6_knn_dataset**
💡 **4개의 class를 가지는 dataset 만들기 X: (400, 2) / y: (400,)**import numpy as np
import matplotlib.pyplot as plt
n_classes = 4
n_data = 100
y_data = []
x_data = []
centroids = []
for _ in range(n_classes):
centroid = np.random.uniform(low = -10, high = 10, size = (2, ))
x_data_ = np.random.normal(loc = centroid, scale = 1, size = (n_data,2))
centroids.append(centroid)
x_data.append(x_data_)
for class_idx in range(n_classes):
y_data_ = class_idx * np.ones(100, )
y_data.append(y_data_)
X = np.array(x_data).reshape(-1, 2)
y = np.array(y_data).reshape(-1,)
print(X.shape)
print(y.shape)#7. code7_euclidean_distances
💡 **KNN 구현 시작 테스트 데이터와 dataset에 들어있는 샘플들 사이의 거리 구하기** **(2,) ~ (400,2)**(2,) 짜리 테스트 데이터 = X[0]
(400,2) 전체 데이터셋간의 거리를 구하라는 의미
import numpy as np
import matplotlib.pyplot as plt
#e_distance = (x1 - x2)**2 + (y1 - y2)**2 + (z1 - z2)**2
#e_distance **= 0.5
#X[0]가 test data
n_classes = 4
n_data = 100
y_data = []
x_data = []
centroids = []
for _ in range(n_classes):
centroid = np.random.uniform(low = -10, high = 10, size = (2, ))
x_data_ = np.random.normal(loc = centroid, scale = 1, size = (n_data,2))
centroids.append(centroid)
x_data.append(x_data_)
for class_idx in range(n_classes):
y_data_ = class_idx * np.ones(100, )
y_data.append(y_data_)
X = np.array(x_data).reshape(-1, 2) #(400, 2)
y = np.array(y_data).reshape(-1,) # (400, )
test_data = X[0] #(400, 2)
test1 = X - X[0] #(400, 2)
e_distance = (test1)**2
e_distance = np.sum(e_distance, axis = 1)
e_distance = e_distance**0.5
print(e_distance.shape)
print(e_distance)#8. code8_classify
💡 **test data가 어떤 클래스에 속하는지 구하기 K=5 e_dists: (400,)**import numpy as np
import matplotlib.pyplot as plt
n_classes = 4
n_data = 100
y_data = []
x_data = []
centroids = []
for _ in range(n_classes):
centroid = np.random.uniform(low = -10, high = 10, size = (2, ))
x_data_ = np.random.normal(loc = centroid, scale = 1, size = (n_data,2))
centroids.append(centroid)
x_data.append(x_data_)
for class_idx in range(n_classes):
y_data_ = class_idx * np.ones(100, )
y_data.append(y_data_)
X = np.array(x_data).reshape(-1, 2) #(400, 2)
y = np.array(y_data).reshape(-1,) # (400, )
test_data = X[0] #(2, 2)
test1 = X - X[0] #(400, 2)
e_distance = (test1)**2
e_distance = np.sum(e_distance, axis = 1)
e_distance = e_distance**0.5
# 1. argsort: 오름차순 정렬 후 인덱스 반환
k = 5
indices = np.argsort(e_distance)[:k]
k_nearest_labels = y[indices]
unique_labels, counts = np.unique(k_nearest_labels, return_counts=True)
predicted_label = unique_labels[np.argmax(counts)]
fig, ax = plt.subplots(figsize=(7,7))
plt.show()#9. knn_visualization
💡import numpy as np
import matplotlib.pyplot as plt
n_classes = 4
n_data = 100
y_data = []
x_data = []
centroids = []
for _ in range(n_classes):
centroid = np.random.uniform(low = -10, high = 10, size = (2, ))
x_data_ = np.random.normal(loc = centroid, scale = 1, size = (n_data,2))
centroids.append(centroid)
x_data.append(x_data_)
for class_idx in range(n_classes):
y_data_ = class_idx * np.ones(100, )
y_data.append(y_data_)
X = np.array(x_data).reshape(-1, 2) #(400, 2)
y = np.array(y_data).reshape(-1,) # (400, )
test_data = X[0] #(2, 2)
test1 = X - X[0] #(400, 2)
e_distance = (test1)**2
e_distance = np.sum(e_distance, axis = 1)
e_distance = e_distance**0.5
# 1. argsort: 오름차순 정렬 후 인덱스 반환
k = 5
indices = np.argsort(e_distance)[:k]
k_nearest_labels = y[indices]
unique_labels, counts = np.unique(k_nearest_labels, return_counts=True)
predicted_label = unique_labels[np.argmax(counts)]
fig, ax = plt.subplots(figsize=(7,7))
plt.show()