1. K-NN Classification
K-NN, K-Nearest Neighbor) 알고리즘
가장 간단한 머신러닝 알고리즘
- 분류 알고리즘
- 비슷한 특성을 가진 데이터
- 비슷한 범주에 속한다는 경향성을 가졌다는 전제 하에 사용
- 거리 측정 방식은 유클리드 디스턴스 / 맨하탄 디스턴스를 사용
K값에 따라 분류가 달라질 수 있다는 점을 유의한다
KNN, 장점은?
- 구조가 단순해 구현하기 쉬움
- 특별한 훈련 과정을 거치지 않기 때문에 훈련 단계가 매우 빠름
KNN, 단점?
- 특징과 클래스 간 관계를 이해하는데 제한적
- 적절한 K이 필요하며, 훈련 단계가 빠른 대신 데이터가 많아지면 분류가 느리다
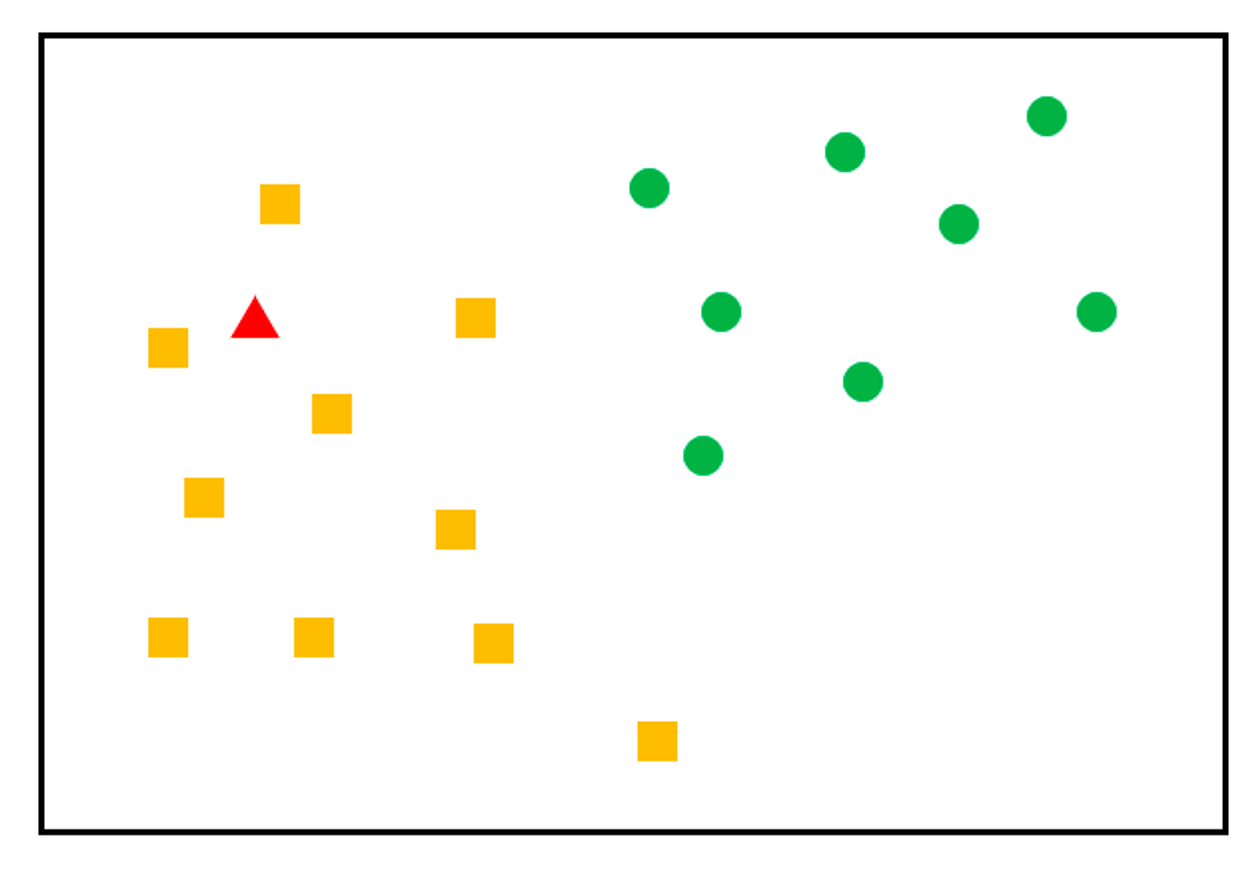
즉, 주변의 가장 가까운 K개의 데이터를 보고 데이터가 속할 그룹을 판단하는 알고리즘이다.
거리계산
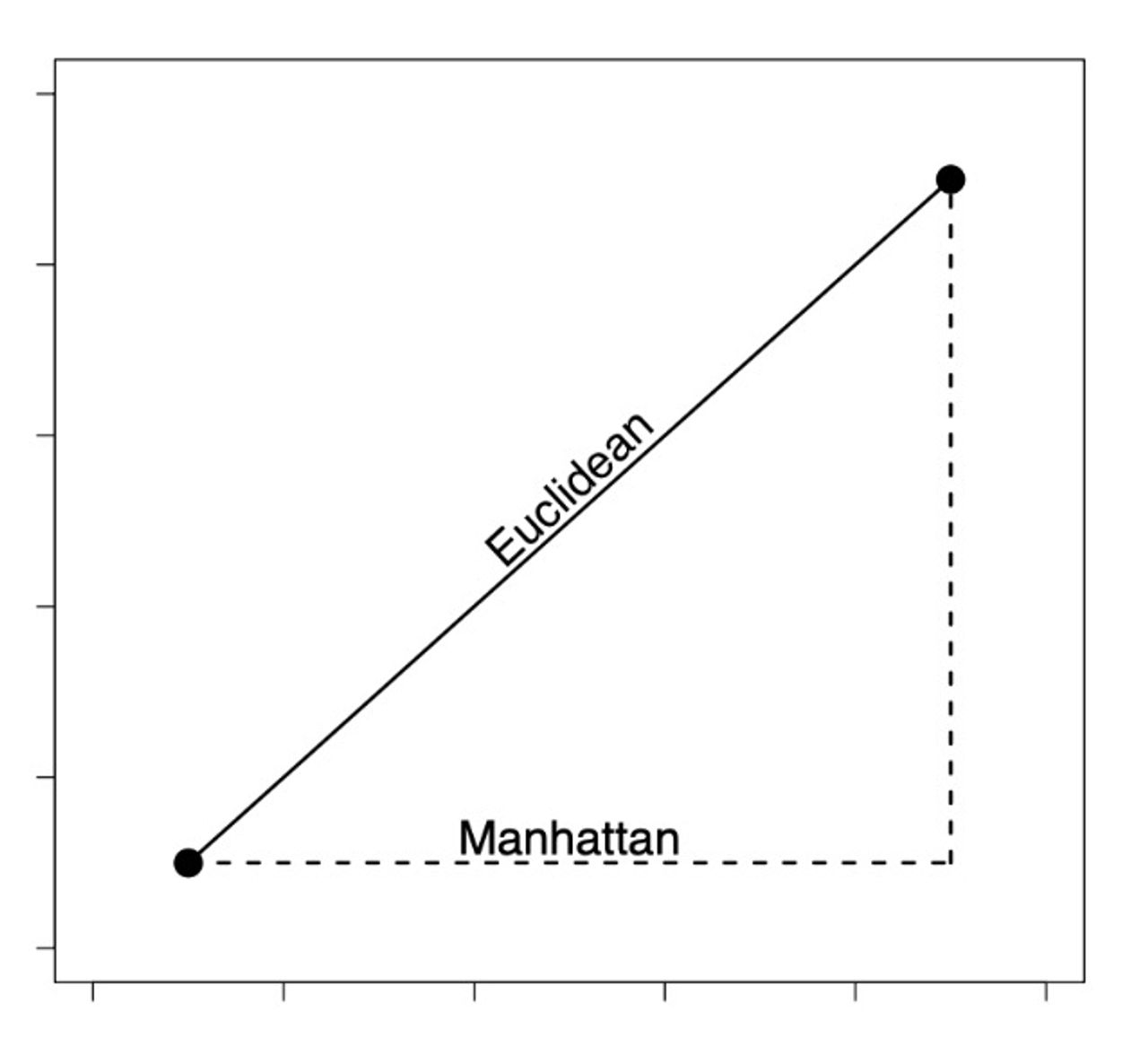
KNN 알고리즘은 유클리디언 / 맨하탄 두 가지 방식을 사용한다. 테스트된 값과 실측치를 구분하기 위해서다.
1. 유클리드 디스턴스
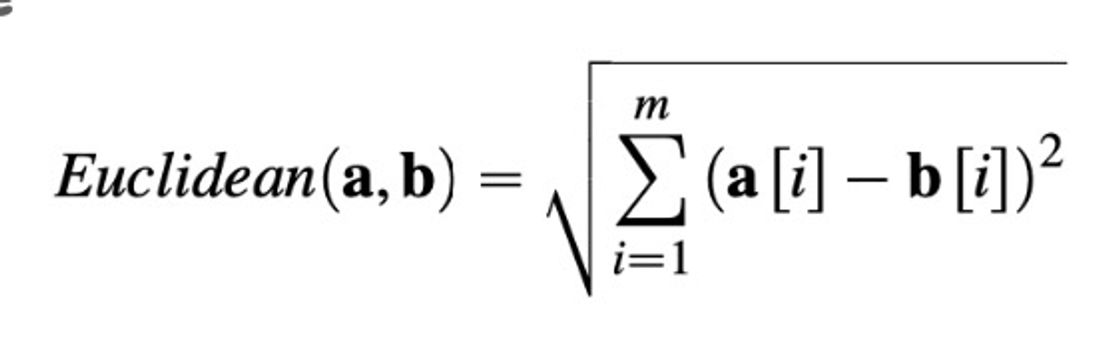
점과 점 사이의 거리를 계산한다. 이 공식의 장점은 차원에 구애받지 않고 사용할 수 있다는 점이다.
2. 맨하탄 디스턴스
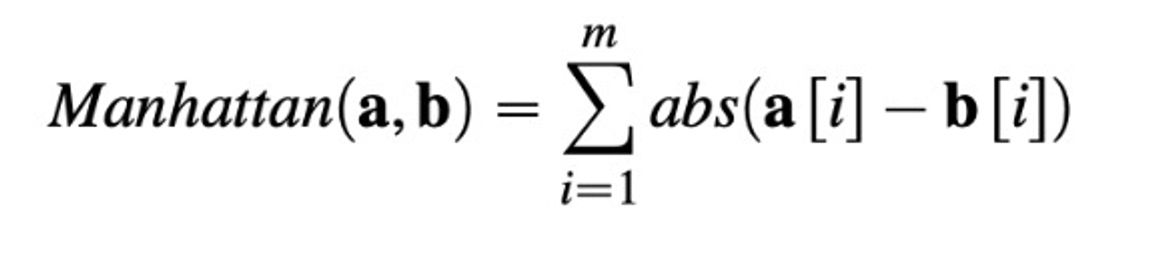
3. 실습
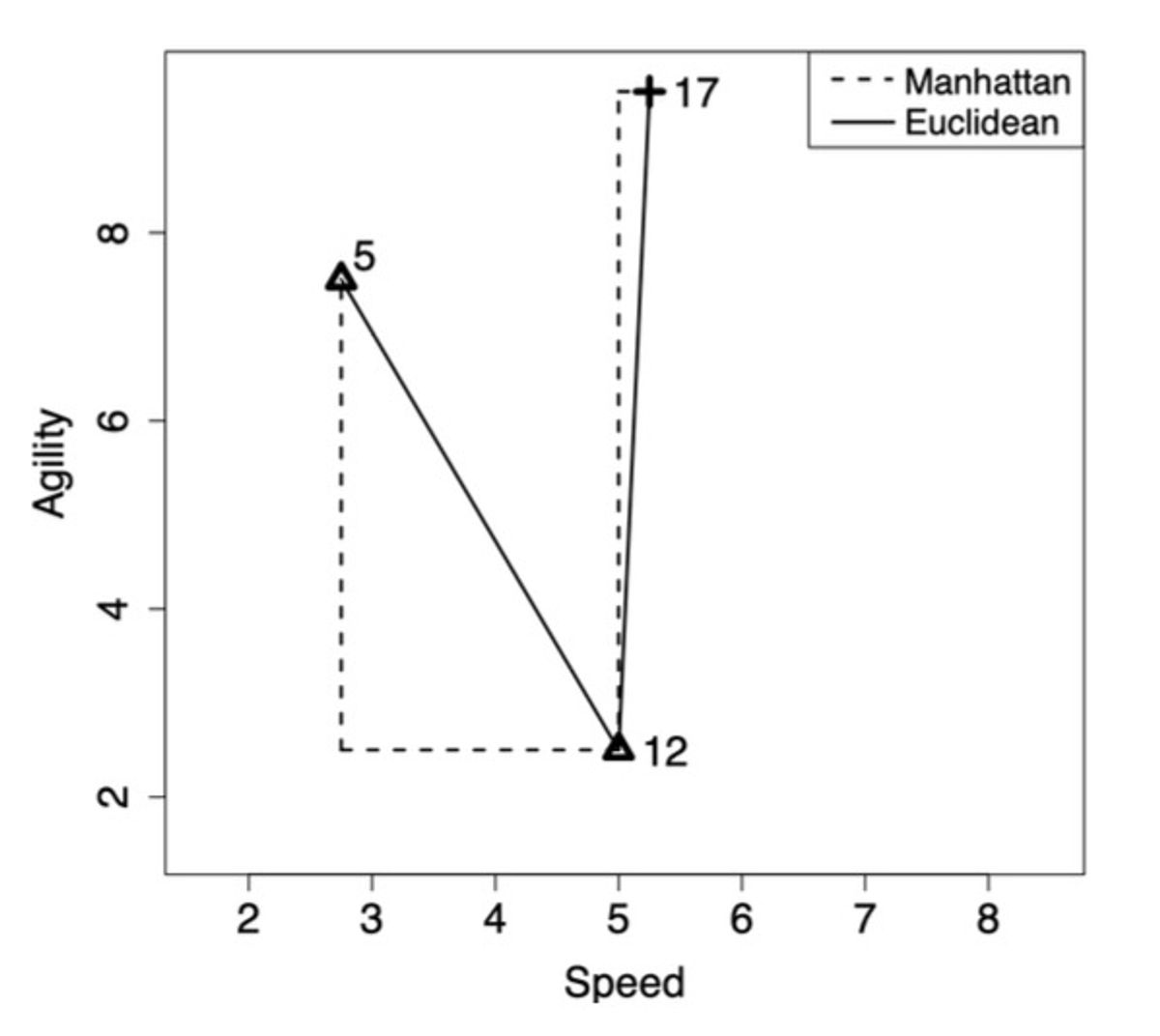
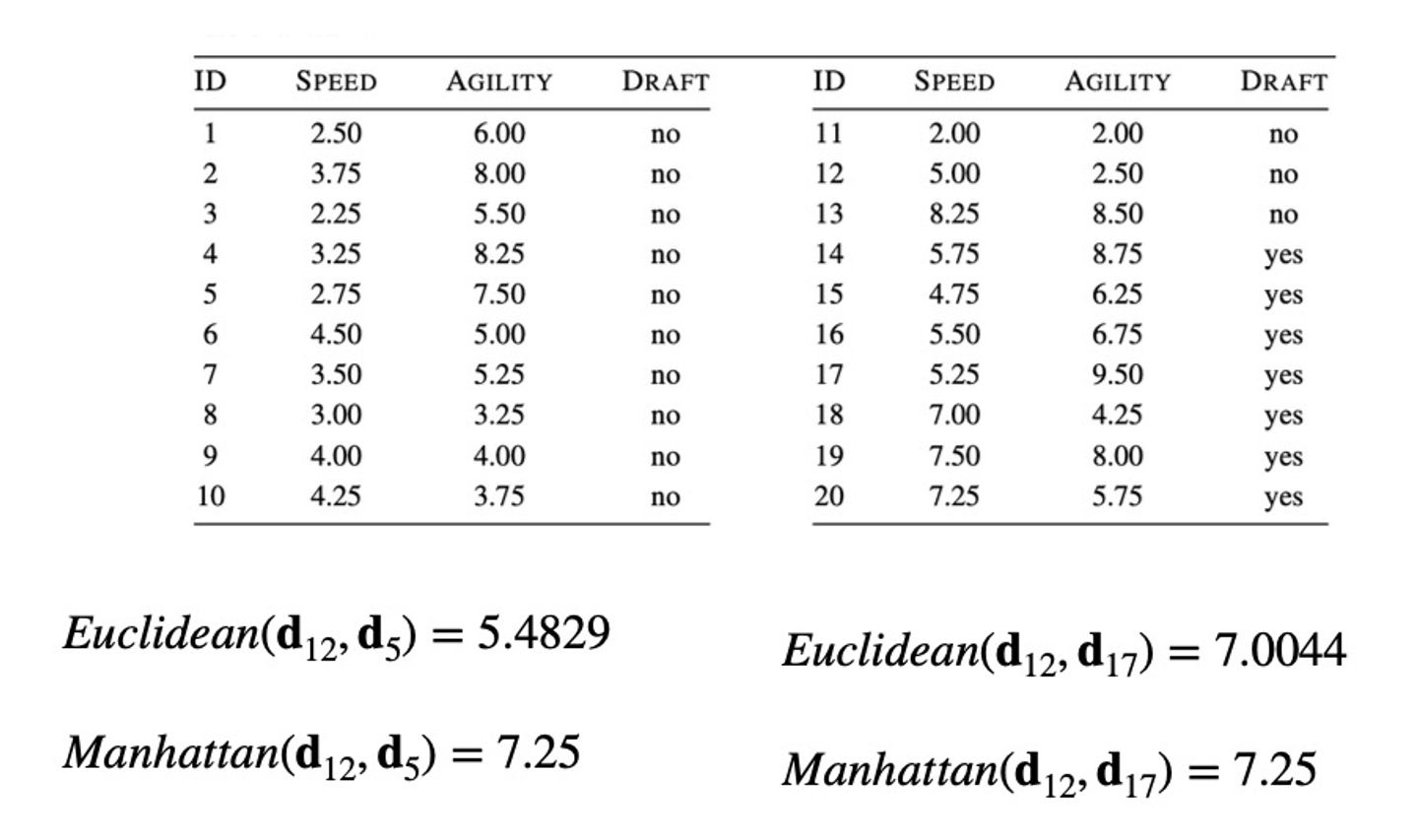
**실습문제 1**
예시로 실습을 해보자. d12와 d5의 Euclidean distance 는 speed와 agility 값을 보고 계산하면 된다.
유클리디언 디스턴스
((|2.75 - 5.00|)2 + (|2.50 - 7.5|)2)**0.5 = 5.4829
맨하탄 디스턴스
(|2.75 - 5.00|) + (|2.50 - 7.5|) = 7.25
이런 식으로 계산하면 됨!
실습문제 2
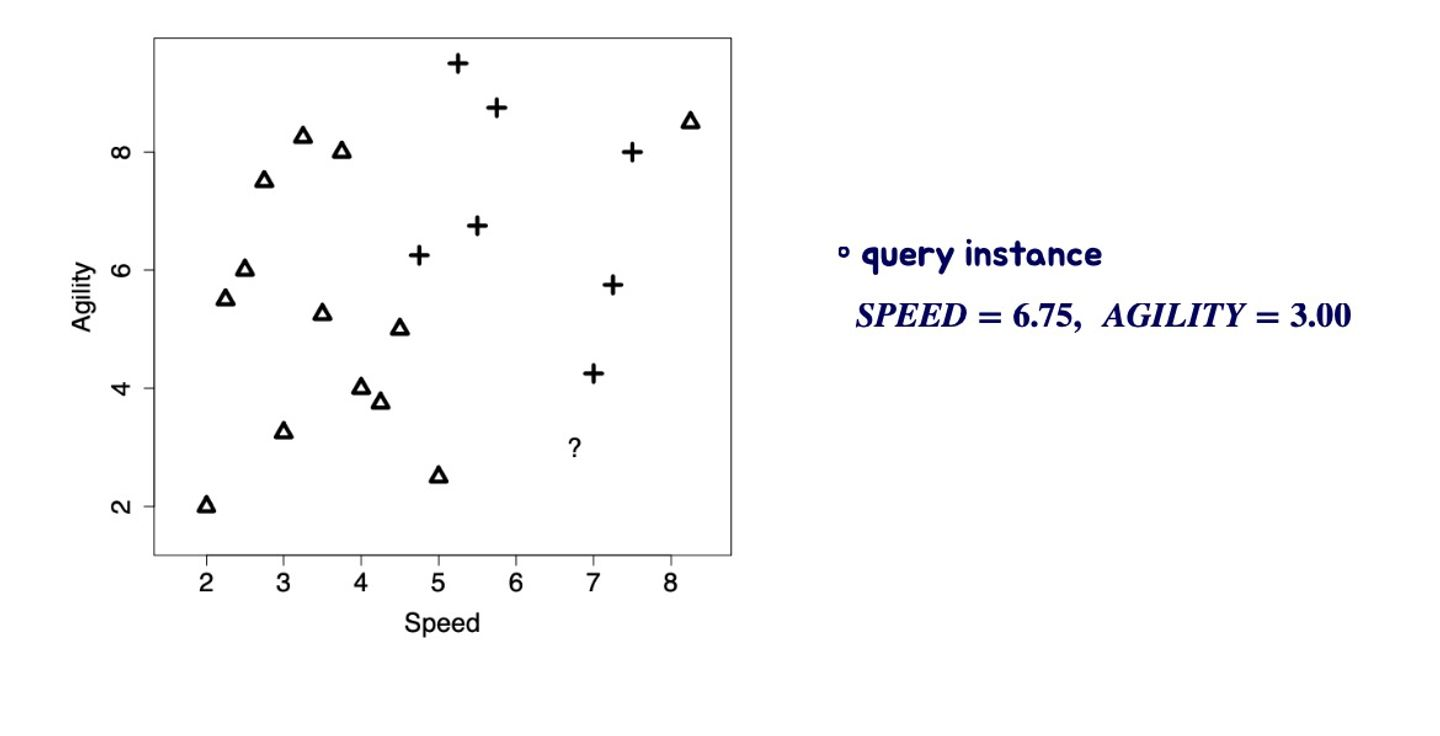
이렇게 제시되어 있다면 어떻게 해야할까? test instance를 기준으로 계산을 하나 하나 하다보면 이런 결과값이 나온다
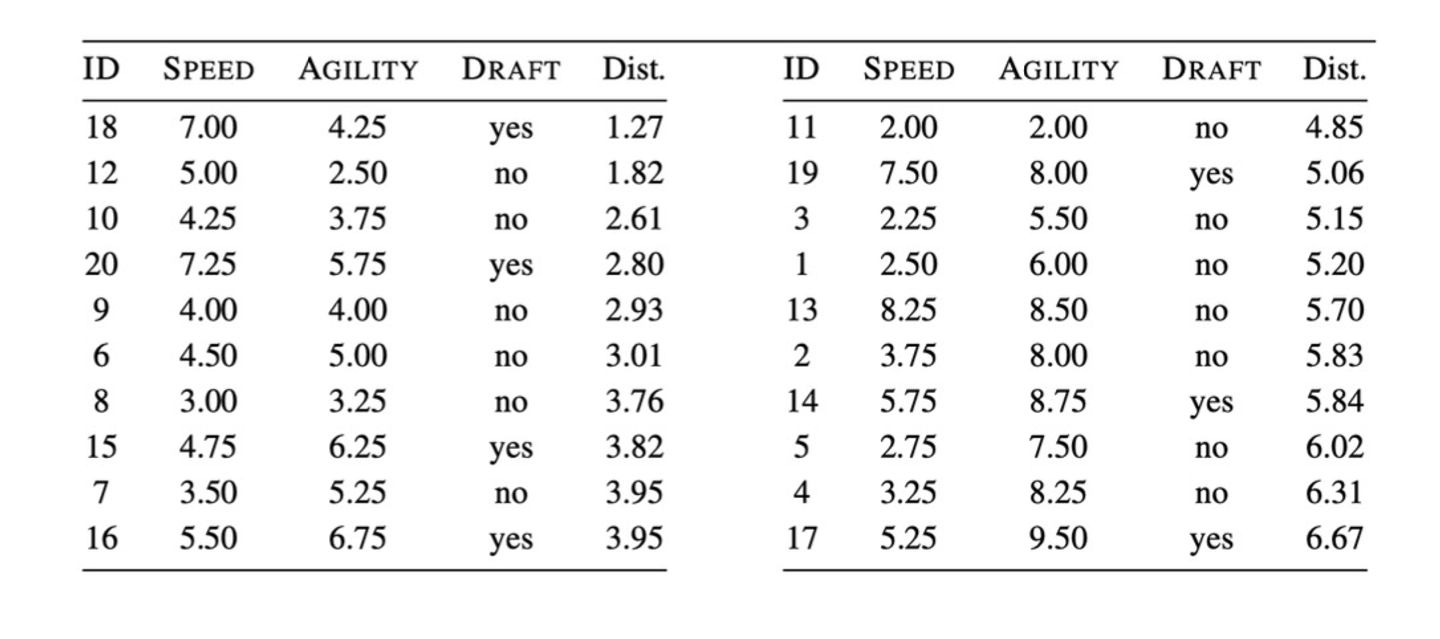
계산식 자체는 어려우지 않으니 직접 해보면 될듯.
