Abstract
최근의 LLM은 막대한 모델 크기를 가지며, 이로 인해 상당한 계산 비용과 저장 공간을 필요로 한다.
모델을 리소스가 제한된 환경에서 배포하고 추론 속도를 높이기 위해 Model compression의 한 방법으로서 Pruning 기법을 탐구하였다.
2020-2024까지 3000편 이상의 Pruning 관련 논문이 나왔으나, Pruning의 최신 동향을 포괄적으로 Review하는 논문은 부족하다.
이 문제를 해결하기 위해 이 논문에서는 Pruning에 관한 기존 연구들을 종합적으로 정리하고, 비교 분석한 결과를 제공하고자 한다.
논문은 Pruning 방법은 4가지 주요 관점에서 분류하여 비교하였다.
- 보편적/특정 가속
- Pruning 시점
- Pruning 방법
- 다른 Compression 방법과의 융합
그런 다음, Pruning을 위한 8가지의 대비되는 설정에 대한 비교 분석을 제공한다.
- Structured vs Unstructured
- One-shot vs Iterative
- Data-free vs Data driven
- Initialized vs Pre-trained
연구 결과를 바탕으로, 각 상황에 맞는 Pruning 기법 선택에 대한 기반을 마련한다.
1. Introduction

지난 수년간, DNN(Deep Nueral Network)은 다양한 분야와 응용에서 놀라운 성과를 거두고 있지만, 그 성능은 모델의 파라미터 수와 계산 비용에 크게 의존한다.
- ResNet-50 : 2,300만개
- BERTBASE : 1억 1000만개
- GPT-3 : 1,750억개
- GPT-4 : 이들보다 더 많은 파라미터 수를 포함
이처럼 신경망의 크기가 계속해서 커지는 추세는 앞으로도 지속될 것으로 예상되는데, DNN의 파라미터 수가 많아질수록 입력 데이터를 처리하는 데 필요한 계산 비용과 저장 공간 또한 증가하게 된다.
이로 인해, 높은 Training 및 Inference 비용은 리소스가 제한된 장치에 모델을 배포하는 데 큰 도전 과제가 된다.
자율 주행같은 분야에서는 같은 높은 정확도, 효율적인 자원 사용, 빠른 실시간 응답이 요구된다
최근 LLM의 인기로 인해, 신경망의 크기를 Compression하는 연구에 대한 관심을 증가하고 있으며, 연구자들은 다양한 Compression 기법 중에서도 Pruning이 원래의 DNN과 비교하여 유사하거나 더 나은 성능을 유지하면서 Inference 시 메모리 공간과 계산 비용을 절약할 수 있는 효과적인 방법임을 입증하였다.
2015년 이후 Pruning 관련 논문의 수가 현저하게 증가하여 전체 Model compression 논문의 절반 이상을 차지하고 있다.
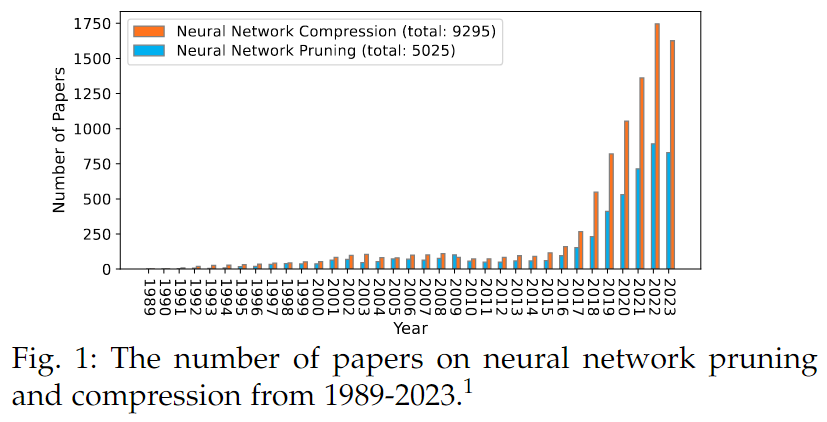
Pruning 연구는 (Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding)논문의 등장 이후 Pruning의 잠재력이 인식되기 시작하면서 많은 관심을 받게 되었다.
- Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding(Song Han, ICLR, 2016)
Pruning(Magnitude) -> Quantization(2bit) -> Huffman coding 순서의 Compression 단계를 제안
그러나, 기존의 여러 리뷰 논문들은 Pruning, Quantization, Distillation과 같은 Compression 기법을 함께 다루면서 Pruning 자체에 대해서는 간략하게만 설명하는 경우가 많다.
예를 들어, Structured pruning에만 집중하여 Unstructured, Semi-structured pruning에 대해서는 언급하지 않는다.
본 논문에서는 DNN pruning에 대한 포괄적인 리뷰를 제공하는 것을 목표로 하여, 대표적인 pruning 기법들을 리뷰하고, pruning 기법들이 어떻게 작동하는지를 분석하여 다양한 요구 사항에 맞게 적절한 pruning 기법을 선택을 할 수 있도록 제시한다.
- 포괄적 리뷰 : DNN pruning 기법에 대한 가장 포괄적인 리뷰를 제공
- 비교 실험 및 분석 : pruning의 여덟 가지의 대비되는 설정에 대한 비교 및 분석 실험을 수행하고, 결과에 대한 논의를 제공
- 풍부한 자료 수집 : 다양한 pruning 응용 분야를 요약하고, 각 응용 분야에 대한 벤치마크 데이터셋, 네트워크 및 평가 기준을 제공하여 여러가지 Neural network pruning 기법을 활용할 수 있도록 지원
- 권고사항 및 향후 연구 방향 : 다양한 요구 사항에 적한한 pruning 기법 선택에 관한 유용하 권고안을 제시하고, 미래 연구 방향을 전망한다.
2. Taxonomy
DNN을 pruning할 때 고려해야 할 세 가지 핵심 질문이 있다.
1. 신경망 pruning을 통해 Universal한 acceleration(보편적 가속)을 달성할 것인가, 아니면 Specific한 acceleration(특정 가속)을 달성할 것인가?
Universal acceleration은 특수한 HW/SW의 지원 없이 독립적으로 동작하는 반면, Specific acceleration 특수한 HW/SW에 의존한다.
Acceleration이 특정 HW/SW에 의존하는지 여부와 관련된다.
일반적으로 pruning은 Structured, Unstructured, Semi-structured로 나뉜다.
Structured pruning만이 특정 HW/SW 없이도 보편적인 신경망 accelaration을 달성할 수 있다.
반면, Unstructured, Semi-structured pruning은 특수한 HW/SW의 지원이 필요로 한다.
Pruning의 주된 목표는 Acceleration이기에 이 질문은 가장 근본적이면서 가장 관심을 많이 갖는 측면을 다룬다.
2. 신경망을 언제 pruning할 것인가?
정적 Pruning를 수행할 때 Training 전(PBT, Pruning Before Training), Training 중(PDT, Pruning During Training), Training 후(PAT, Pruning After Training) 중에 어느 시점에 pruning을 적용할 것인지, 혹은 Dynamic pruning을 수행할 것인지 관건이다.
정적 pruning을 수행할 때, pruning과 신경망 training 간 배치를 어떻게 할 것인가 하는 점이다.
즉, 신경망은 Trainig 전/중/후 중 언제 pruning을 적용할 것인지를 결정해야 한다.
동적 pruning의 경우, 각 입력 데이터에 대해 런타임에 pruning이 수행된다.
3. 특정 기준(Criteria)을 기반으로 pruning할 것인가, 아니면 Learn to prune 방식을 적용할 것인가?
신경망을 특정 기준으로 기반으로 pruning할 것인지, 혹은 training을 통해 pruning을 수행할 것인지에 대한 것이다.
특정 기준이란, 각 가중치의 중요도를 측정하는 score 함수를 말한다.
일반적으로 가장 많이 사용되는 기준으로는 Magnitude(가중치 크기), Norm, Loss change(손실 변화율) 등이 있다.
반면에, Sparsity regularization training이나, Dynamic sparse training 등을 통해 training 방식으로 pruning을 수행하는 방법도 존재한다.
신경망이 자체적으로 어떤 가중치를 제거해야 하는지를 학습하도록 하는 방식
기준을 기반으로 pruning을 하든, Training을 기반으로 pruning을 하든 궁극적으로는 어떤 가중치를 제거해야 할지를 결정하는 것이 pruning의 목적이다.
3. Specific or universal speedup
Unstructured, Semi-structured, Structured pruning에 대해 다룬다
3.1 Unstructured pruning
Unstructured pruning은 가중치 단위(Weight-wise)pruning이라고도 불리며, 가장 미세한 수준의 pruning이다.
가중치 와 입력 , 출력 쌍으로 구성된 데이터셋 , 그리고 보다 작은 0이 아닌 가중치의 총 개수 가 주어졌을 때, Unstructured pruning은 다음과 같이 표현할 수 있다.
- : 데이터셋 에 대해 가중치 의 평균 Loss
(은 개별 샘플에 대해 모델이 처리한 예측값과 간의 loss를 구하는 loss function)1~번째까지의 샘플 데이터에 대한 loss 평균
- : 데이터셋 를 기반으로 전체 가중치 에 대해 전체 손실 을 최소화하는 문제
- : 가중치 에 포함된 0이 아닌 가중치의 수가 최대 개 이하여야 한다는 sparsity를 의미
하지만, 실제 사용에서, 소형, 중형 모델의 경우 Unstructured pruning은 보통 가중치를 직접 0으로 설정하지 않고, 해당 가중치와 대응되는 Mask 을 0으로 만든다.
각 가중치에 Binary mask를 적용하는 것으로 간주한다.
- : 가중치 에 직접 0을 할당하는 대신, 마스크 을 도입한다.
기호는 Hadamard 곱을 의미하며, 은 개별 가중치 에 대응하는 마스크 행렬의 원소 을 곱한 결과를 나타낸다.이면 대응하는 해당 가중치가 제거됨
이면 대응하는 해당 가중치 유지
- : 마스크 에서 0이 아닌 원소의 수가 최대 개 이하여야 한다는 조건으로, 전체적으로 개의 가중치만이 선택되어 활성화된다.
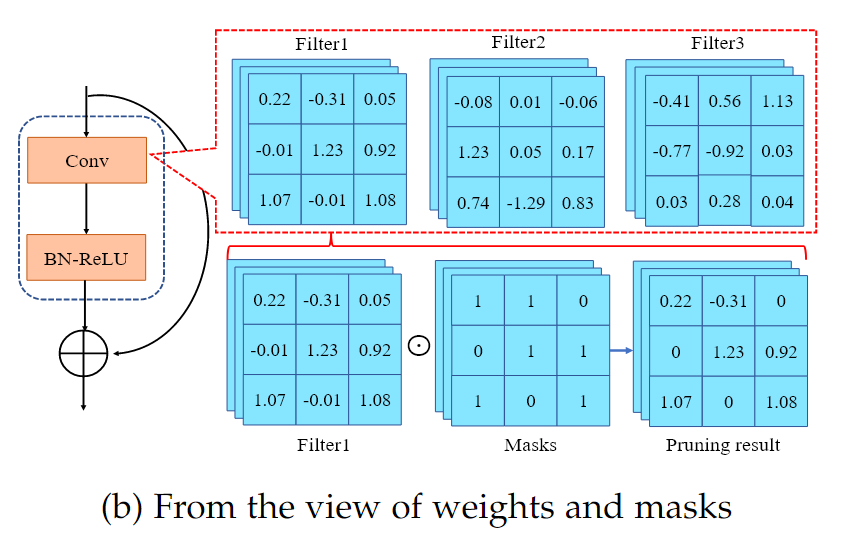
LLM과 같은 대형 모델은 파라미터가 너무 많아 일일이 Mask를 관리하기 어렵기 때문에, pruning할 가중치를 바로 0으로 만드는 방법을 흔히 사용한다.
Unstructured pruning은 신경망 내 어느 위치의 가중치든 제거할 수 있기에 높은 유연성을 지니고 sparsity가 높아도 정확도를 잘 유지할 수 있는 경우가 많지만,
제거된 가중치들이 불규칙하게 분포하기 때문에 실제 Acceleration을 위한 특수한 SW/HW의 지원을 요구하게 된다.
따라서, Unstructured pruning을 Specific speedup 방식으로 분류한다.
3.2 Structured pruning
Pruning 비율과 신경망 이 주어졌을 때, 는 번째 Layer의 채널, 필터, 뉴런, 어텐션 헤드와 같은 모듈의 집합이 될 수 있다.
Structured pruning은 각 Layer에서 모듈의 집합 의 하위 집합인 들을 Pruning 비율에 맞게 선택하여, 전체적으로 를 구성한다.
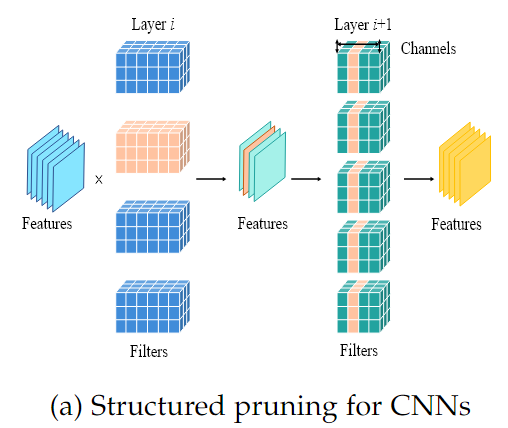
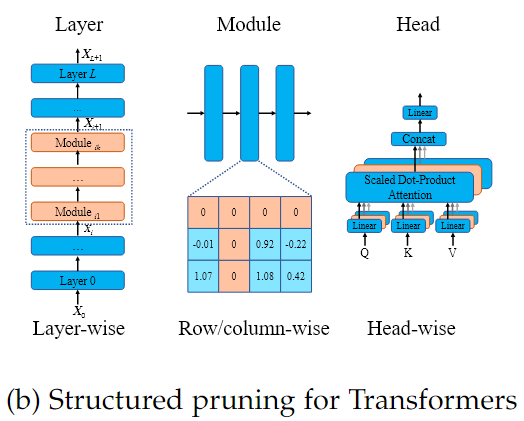
Structured pruning은 특정 구조 단위로 제거하기 때문에, pruning 후에도 모델의 구조가 규칙적이므로 별도의 HW/SW를 필요로 하지 않고, 직접적으로 모델의 추론 속도를 높이고 크기를 줄일 수 있다.
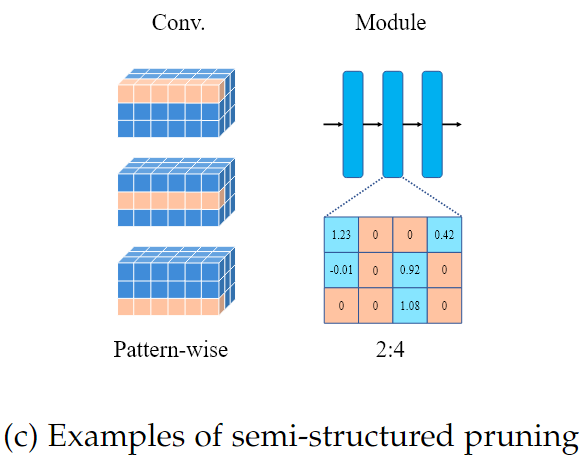
3.3 Semi-structured pruning
Structured pruning의 유연성을 높이되, 구조적인 규칙성을 유지하면서 pruning 비율이 높을 때 발생하는 Accuracy 저하를 완화하기 위해, Semi-structured pruning을 도입하였다.
- Pattern-wise pruning
모듈의 내부를 일정 규칙에 따라 나누고, 그 중 일부를 pruning하는 방법으로, 완전히 Structured하거나 Unstructured하지 않으면서, 규칙성을 지닌 Sparsity를 확보할 수 있다.
- 2:4 pruning
그림에 나타난 행렬 [1.23, 0, 0, 0.42],[0, 0, 1.08, 0] 처럼 연속된 4개의 값 중 최소 2개를 0으로 설정해야 한다는 규칙이다.
이 규칙을 따르면 각 행렬 내 sparse한 pattern이 생기고, 해당 pattern을 HW/SW가 효율적으로 처리할 수 있다.Semi-structured pruning은 규칙성이 존재하기 때문에, 반드시 HW지원이 필요한 것은 아니지만 규칙적인 Pattern의 장점을 활용하기 위해 HW/SW의 지원이 있으면 연산 속도가 더욱 향상된다.
4. When to prune
정적 pruning에 대한 세 가지 Pipeline과 동적 pruning을 설명한다.
4.1 Pruning Before Training
학습 전 Pruning은 무작위로 초기화된 가중치를 활용하여 신경망을 pruning하는 기법들로 구성된다.
PBT의 주요 목적은 Pre-training과정을 제거하는 것이다.
신경망을 이라 정의할 때, 은 초기 가중치 을 pruning하기 위한 마스크이다.
PBT에서는 학습 전 초기 가중치에 대해 pruning 후 신경망 은 의 Epoch의 training을 거쳐 로 수렴하게 된다
(은 pruning을 적용시킨 Mask)
PBT 방식은 보통 두 단계로 진행된다.
1단계 : 학습되지 않은(무작위로 초기화된) Dense한 신경망을 특정 기준에 따라 pruning 한다.
2단계 : 1단계에서 생성된 특정한 sparse한 구조(패턴)가 고정된 채로 신경망을 높은 성능이 나올 때까지 Training하여 수렴시킨다.

학습되지 않은 Dense한 신경망을 pruning하는 방법들
1. Single-shot Network Pruning (SNIP)
SNIP는 아직 학습되지 않은, 무작위로 초기화된 신경망에서, 각 가중치를 제거했을 때 Loss에 미치는 영향을 계산하여 그 영향이 가장 작은 가중치들을 pruning하는 방식이다.
실험 결과, Pruning이 신경망이 입력의 변화를 균일하게 전달하는 특성인 동적 Dynamical isometry에 손상을 줄 수 있음을 발견하여, 데이터에 의존하지 않는 Orthogonal initialization 방법을 제안하였다.
2. Gradient Signal Preservation (GraSP)
Pruning 후 Gradient의 크기를 측정하여, Training 시 Gradient flow에 큰 영향을 미치지 않는 가중치를 pruning한다.
학습 과정에서 중요한 정보가 손실되지 않도록 하는 방법이다.
3. Iterative Synaptic Flow Pruning (SynFlow)
데이터 없이, Training 전에 단순히 초기화된 신경망 내의 각 layer 간 상호 작용을 고려하면서 점진적으로 pruning하여 효과적인 서브 네트워크를 식별한다.
한 Layer에서 모든 가중치가 pruning되어 해당 Layer가 완전히 사라지는 상황을 방지하면서, 점진적인 pruning을 통해 전체 신경망의 구조를 안정화시키는 데 기여한다.
일부 연구에서는 개별 가중치에 대한 세밀한 평가 지표보다는, 각 Layer별로 정해진 sparsity 비율을 유지하는 것이 모델의 성능에 더 중요할 수 있다고 주장한다.
1. Smart-ratio
특정 데이터를 사용하지 않고, 단순히 각 Layer에서 일정 비율의 가중치만 남기도록 pruning한다.
2. Edge-popup
Pre-training없이 초기화된 신경망에서도 충분히 Width, Depth을 늘리면 학습된 신경망과 유사한 성능을 내는 서브 네트워크가 존재할 수 있기에, 무작위 초기화된 상태에서 효과적인 부분을 선택하는 방법을 제시
3. Dual Lottery Ticket Hypothesis
서브네트워크와 가중치를 모두 무작위로 선택한 후, 고정된 Sparse한 구조에서 남은 가중치들을 점진적으로 학습
그러나, 같은 pruning 비율을 적용했을 때, Training 중/후에 pruning을 수행한 신경망이 Training 전에 pruning한 신경망보다 성능이 우수하다는 사실을 발견하였다.
4.2 Pruning During Training
Training 중 pruning은 보통 무작위로 초기화된 dense한 신경망 을 모델로 받아, Training 과정에서 가중치 와 마스크 을 함께 업데이트하면서 신경망을 Training하고 pruning을 수행한다.
이러한 동적 접근은 Training 중 마스크를 변경함으로써 번의 Epoch 후에 pruning된 서브 네트워크 을 생성한다.
많은 PDT 기법들은 추가적인 train이나 fine-tuning없이 서브네트워크를 직접 얻는다.

PDT는 PBT,PAT에 비해 복잡한 동적 프로세스를 갖기 때문에 상대적으로 연구가 덜 이루어져 왔다.
기존의 선행 연구들을 네 가지 범주로 요약한다.
- Sparsity Regularization based Methods
- Dynamic Sparse Training based Methods
- Score-based Methods
- Differentiable Pruning based methods
4.2.1 Sparsity Regularization based Methods
Sparsity Regularization은 Dense한 신경망에서 시작하여, Loss function에 sparse 제약(페널티항)을 부과하고 Training 중에 일부 가중치나 해당 가중치의 마스크를 0으로 만들어 낸다.
Training 과정에서 자연스럽게 불필요한 가중치들을 제거하여 모델을 압축하고, 효율적인 Sparse 신경망을 만드는 것을 목표로 한다.
하지만, 가중치에 정규화된 파라미터를 곱해 가중치의 기여도를 0에 가깝게 만드는 방법이므로, 메모리 측면에서는 단순히 0에 수렴하는 파라미터를 곱하여 가중치값을 줄이기 때문에 전체 신경망의 파라미터 수나 메모리 사용량을 직접적으로 줄이지는 않는다.
1. Structured Sparsity Learning (SSL)
Group LASSO 정규화를 사용해 전체 신경망에서 특정 모듈 단위의 가중치들을 동시에 0으로 만드는 방법을 제안
신경망의 구조적인 Sparsity를 학습하게 하여 효율적인 모델 압축 효과를 기대할 수 있지만, 희소성 정규화 항의 Gradient를 모든 가중치에 대해 계산해야 하므로 계산 비용이 많다는 단점이 존재한다.
모델 학습 시 Loss function은 일반 데이터에 대한 loss항과 정규화 항(페널티 항)으로 구성된다.
정규화 항은 가중치 값들이 너무 크지 않게 하거나 희소성을 유도하는 역할을 한다.
(이 감소하는 방향으로 업데이트 -> 정규화항의 불필요한 가중치가 0에 수렴해짐)정규화 항도 전체 Loss function에 포함된 항목이므로
학습 과정에서 경사 하강법을 사용하여 Loss function의 미분값을 계산해, 가중치를 업데이트하기 위해서는 모델에 있는 모들 가중치에 대해 정규화 항의 기울기(기여도)를 계산해야 한다.
2. MorphNet
Batch normalization layer의 파라미터를 재활용하여 그 파라미터에 희소성 정규화를 적용한다.
Batch normalization layer의 파라미터는 각 채널의 출력에 곱해져 그 채널이 얼마나 중요한지 결정하는 척도를 나타낸다.
이 파라미터에 희소성 정규화를 적용하면 불필요한 채널의 파라미터를 0에 가깝게 만들어 모델 구조를 복잡하지 않으면서도 pruning 효과를 얻을 수 있다.
정규화 항은 가중치 값들이 너무 크지 않게 하거나 희소성을 유도하는 역할을 한다.
(이 감소하는 방향으로 업데이트 -> 정규화항의 불필요한 파라미터가 0에 수렴해짐)
이를 통해 BN layer가 있는 모델에서는 희소성 학습을 효율적으로 수행할 수 있지만, 일부 신경망에서는 BN layer가 없기 때문에 적용에 한계가 있을 수 있다.
3. Sparse Structure Selection (SSS)
CNN 내부의 미세 구조에 별도의 scaling factor를 도입하여, 이 scaling factor에 희소성 정규화를 적용하여, 해당 미세 구조의 출력을 0에 가깝게 만듦으로 pruning을 수행한다.
가중치 자체를 0으로 만드는 것이 아니라, 출력 자체를 0에 가깝게 만들어 성능 손실을 최소화하면서 pruning을 진행할 수 있다.
정규화 항은 가중치 값들이 너무 크지 않게 하거나 희소성을 유도하는 역할을 한다.
(이 감소하는 방향으로 업데이트 -> 정규화항의 불필요한 Scaling factor가 0에 수렴해짐)
4. Factorized Convolutional Filter
Convolution filter마다 하나의 binary 스케일러 값을 할당하여 해당 filter의 출력 기여도를 조절한다.
filter마다 할당된 스케일러에 희소성 정규화를 적용하면, 불필요하거나 중요도가 낮은 filter의 스케일러 값이 0에 가깝게 만들어지며 해당 filter의 출력이 실질적으로 pruning되는 효과를 준다.
Convolution filter의 가중치와 함께, 각 filter에 할당된 binary scalar도 전체 신경망의 Loss를 최소화하는 방향으로 학습한다.
4.2.2 Dynamic Sparse Training based Method
Dynamic Sparse Training 기반 방법은 Dense한 신경망 대신 무작위로 초기화된 Sparse 네트워크를 사용한다. Training 도중 pruning와 regrow 과정을 반복하여 최적의 sparse한 신경망 구조를 동적으로 탐색한다.
기본 아이디어
- Sparse한 신경망으로 시작한다:
완전한 Dense 네트워크 대신 무작위로 sparse 네트워크를 초기 모델로 사용한다. - Pruning와 Regrow를 반복한다:
Training 과정에서 중요하지 않은 가중치를 제거(prune)하고, 같은 수의 새로운 가중치를 추가(regrow)한다. 이를 통해 네트워크 구조를 지속적으로 최적화한다.
기존의 Pruning과의 차이점
- 기존 pruning은 모든 가중치가 있는 Dense한 신경망을 학습한 다음에 필요없는 가중치를 prune한다.
- Dynamic Sparse Training은 처음부터 일부 가중치가 이미 0인 sparse한 네트워크로 학습하며, 학습이 진행되는 동안 계속해서 중요하지 않은 가중치를 pruning을 하고 제거된 가중치 수만큼 새로운 가중치를 regrow시키며, 점점 더 좋은 sparse 구조로 발전한다.
주요 방법 및 예시
-
Sparse Evolutionary Training (SET)
- 네트워크 내에서 가장 작은 양의 값과 가장 큰 음의 값을 가진 가중치를 제거한다.
- 제거된 가중치 대신 무작위로 새 가중치를 추가한다.
-
Dynamic Sparse Reparameterization (DSR)
- 고정된 Pruning 비율 대신 동적으로 조절되는 임계값을 사용한다.
- Layer 내부는 물론 Layer 간에도 가중치 재분배를 고려한다.
-
FreeTickets
- FreeTickets는 여러 Sparse 네트워크를 앙상블하여 성능을 개선한다.
- 단일 네트워크가 아니라, 다양한 방식으로 얻어진 희소 서브네트워크들을 결합해 더 나은 성능을 낸다.
-
Gradual Pruning with zero-cost Neuroregeneration (GraNet)
- 가중치 크기(절댓값이 작은 가중치) 기준으로 pruning를 하고, 기울기(gradient)가 큰 위치에 새로운 가중치를 regrow시킨다
그래디언트 흐름의 개선
- 초기 sparse 네트워크에서는 그래디언트 흐름이 원활하지 않다.
- 동적 pruning와 regrow 과정을 반복함으로써 학습이 진행될수록 그래디언트 흐름이 개선된다.
요약
- sparse 네트워크로 시작한다
Dense 네트워크 대신 무작위 sparse 네트워크를 초기 모델로 사용한다.- 동적 pruning–regrow 과정을 반복한다
학습 도중 중요하지 않은 가중치를 제거하고, 동일 수의 가중치를 재성장시켜 sparse 구조를 최적화한다.- 그래디언트 흐름을 개선한다
동적 과정을 통해 초기 희소 네트워크의 한계를 극복하고 모델의 성능을 향상시킨다.
이와 같이 Dynamic Sparse Training based Method은 학습 과정 중에 모델의 희소 구조를 동적으로 최적화하여 최종 성능과 계산 효율성을 동시에 향상시키도록 설계된다.
4.2.3 Score-based Methods
Training 도중, 모델의 각 구성 요소(예, 필터 혹은 채널)의 중요도를 점수로 산출하여, 중요도가 낮은 요소들을 제거한다. 이때 산출된 점수를 기준으로 Pruning을 진행한다.
주요 아이디어
-
중요도 점수를 산출한다:
각 필터나 채널의 중요도를 노름, 기하학적 중앙값, 스케일링 팩터 등으로 계산한다. -
낮은 점수를 가진 요소를 제거한다:
사전에 정해진 pruning 비율에 따라, 점수가 낮은 필터나 채널을 0으로 만들어 제거한다. -
지속적인 학습 중 복원한다:
제거된 필터나 채널은 이후 역전파 과정에서 업데이트되어 어느 정도 회복될 수 있도록 한다.
주요 방법 예시
-
Soft Filter Pruning (SFP)
- 필터의 노름을 이용해 중요도를 산출한다.
- 중요도가 낮은 필터의 가중치를 0으로 설정한다.
- 제거된 필터는 한 Epoch 내에서 0으로 고정되지 않고, 이후 학습 중에 업데이트될 수 있다.
-
Filter Pruning via Geometric Median (FPGM)
- 동일 레이어 내의 필터들 중 기하학적 중앙값에 가까운 필터를 식별한다.
- 동일 레이어 내의 모든 필터를 하나의 벡터(예: 필터의 가중치 값들이 하나의 벡터로 표현됨)라고 생각
- 필터 벡터들의 기하학적 중앙값은 모든 필터로부터 평균적으로 가장 가까운 위치에 있는 "대표" 벡터
- 중앙값에 가까운 필터를 제거하여 중복되는 정보를 줄인다.
- 동일 레이어 내에서 여러 필터가 유사한 특징을 추출한다면, 이들 중 중앙값과 거의 유사한(거리상으로 가장 가까운) 필터는 다른 필터들과 중복된 역할을 하는 것으로 판단
- 중앙값에 가까운 필터는 이미 다른 필터들이 공통적으로 가지고 있는 특성을 대표하기 때문에, 제거해도 전체적으로 중요한 정보가 크게 손실되지 않는다
- 동일 레이어 내의 필터들 중 기하학적 중앙값에 가까운 필터를 식별한다.
-
Network Slimming
- 각 채널(또는 필터)에 스케일링 팩터를 도입한다.
- 스케일링 팩터에 희소성 정규화를 적용하여 값이 작아지도록 유도한다.
- 스케일링 팩터의 값을 해당 채널의 중요도로 사용하고, 중요도가 낮은 채널은 출력에 기여하지 않게 한다.
전체적인 설명
- 모델은 학습 도중 각 구성 요소의 중요도를 정량적으로 평가한다.
- 평가된 점수에 따라, 미리 정해진 pruning 비율에 맞춰 중요도가 낮은 요소를 제거한다.
- 제거된 요소는 학습 과정에서 다시 업데이트되어, 가지치기로 인한 성능 저하를 최소화한다.
- 이러한 점수 기반 방법은 pruning을 위한 기준을 명확하게 하고, 불필요한 구성 요소를 효과적으로 제거하여 모델 압축과 경량화를 동시에 달성한다.
이와 같이, 점수 기반 방법은 학습 중 각 구성 요소의 기여도를 점수로 평가하고, 그 점수에 따라 가지치기를 진행하여 최종 모델의 효율성과 성능을 최적화한다.
4.2.4 Differentiable Pruning based methods
미분 가능 pruning 기반 방법은 전통적인 pruning가 0 또는 1과 같이 이진적으로 결정되는 반면, pruning 결정을 연속적인 값(soft mask)으로 표현하여, 경사 하강법과 같은 미분 기반 최적화 기법으로 End-to-end 학습할 수 있도록 한다.
동작 원리
-
소프트 마스크 사용:
pruning 결정을 0 또는 1처럼 단정짓지 않고, 0과 1 사이의 연속적인 값으로 표현한다. 이를 통해 pruning 비율이나 채널 유지 확률 등을 미분 가능한 형태로 모델링한다. -
연속적 최적화:
소프트 마스크에 대한 손실 항(예: 희소성 정규화 항)을 전체 손실 함수에 포함시켜, 역전파로 해당 항의 기울기를 계산하고, 마스크 값과 가중치를 동시에 업데이트한다. -
모델 통합 최적화:
pruning 결정을 모델의 다른 파라미터와 함께 한 번에 최적화하므로, 데이터 손실과 압축 효과(희소성)가 동시에 고려된다.
주요 구현 기법
-
Differentiable Sparsity Allocation (DSA)
- 각 레이어별 pruning 비율을 미분 가능하게 설정한다.
- 이 비율에 따라 확률 분포에서 소프트 마스크를 샘플링하여, pruning 결정을 부드럽게 적용한다.
- 산출된 기울기를 통해 레이어별 민감도를 평가하며, pruning 비율을 최적화한다.
-
미분 가능 마코프 프로세스 기반 방법
- 각 채널을 하나의 상태(state)로 보고, 이전 채널의 유지 여부에 따라 상태 전이를 구성하여 채널의 유지 확률을 결정한다.
- 이 과정은 미분 가능한 형태로 설계되어, 학습 도중 채널 유지 확률을 최적화한다.
-
추가 파라미터 없는 소프트 마스크 생성 방식
- 별도의 추가 학습 파라미터를 도입하지 않고, 네트워크 내부에서 바로 0과 1 사이의 연속적인 값을 가지는 소프트 마스크를 생성하여 pruning을 수행한다.
- 이 방식은 CNN과 트랜스포머 모델 모두에 적용 가능하며, 학습 과정 중 자연스럽게 업데이트된다.
장점 및 효과
-
End-to-end 학습 가능:
pruning 결정과 관련된 모든 변수(예: 마스크와 가중치)가 하나의 손실 함수로 통합되어 함께 최적화된다. -
유연한 pruning 결정:
소프트 마스크를 사용함으로써, 중요한 부분은 유지하고 덜 중요한 부분은 점진적으로 제거하는 방향으로 학습이 진행된다. -
모델 압축과 성능 최적화 동시 달성:
데이터 손실 최소화와 희소성(모델 압축) 효과를 동시에 고려하여, 불필요한 파라미터를 줄이면서도 모델 성능의 저하를 최소화한다.
결론
미분 가능 prunign 기반 방법은 가지치기 결정을 단순히 0 또는 1과 같은 이진적 선택이 아니라, 부드럽게(soft하게) 결정함으로써, 전체 모델 학습 과정에 자연스럽게 통합한다. 이를 통해 모델은 불필요한 파라미터를 줄이면서, 성능을 유지하거나 향상시키는 방향으로 최적화된다.
4.3 Pruning After Training
PAT는 Dense 네트워크를 먼저 학습한 후, 불필요한 가중치나 구조를 제거하는 방식이다.
주요 과정
-
사전 학습(Pre-train)
- 무작위로 초기화된 dense 네트워크 를 학습하여, 로 수렴시킨다.
- 사전 학습된 모델은 학습 데이터에 대해 좋은 성능을 보인다.
-
가지치기(Prune)
- 학습된 네트워크에서 성능에 미치는 영향이 가장 작은 가중치(또는 필터, 뉴런 등)를 선택하여 제거한다.
- 가지치기 후 생성된 네트워크는 와 같이 표현된다.
- 여기서 는 pruning 후의 가중치, 는 pruning를 표현하는 마스크이다.
- pruning 한 번에 수행할 수도 있고, 여러 번 반복하면서 점진적으로 sparsity를 높인다.
-
재학습 또는 미세 조정(Retrain or Fine-tune)
- pruning 후의 네트워크를 다시 학습하거나 fine-tuning하여, 제거에 따른 성능 저하를 복구한다.
- 이 과정은 두 가지 방식으로 진행된다.
- 남은 가중치만을 사용하여 처음부터 다시 학습한다
- 혹은 pruning 후의 모델 를 fine-tuning한다.
- 남은 가중치만을 사용하여 처음부터 다시 학습한다
- 여기서 는 최종 pruning 결과를 나타내는 마스크이다.
요약
- PAT는 dense 네트워크를 사전 학습한 후, 성능에 영향이 적은 부분을 제거하여 희소 네트워크로 만든다.
- 제거 후에는 남은 가중치들만을 사용해, 모델을 처음부터 다시 학습하거나 미세 조정하여 최종 성능을 복구한다.
- 이 과정을 통해 모델의 파라미터 수와 연산량을 줄여 경량화 및 추론 효율을 높인다.
이와 같이, PAT 방식은 사전 학습된 모델을 기반으로 불필요한 요소를 제거하고, 최종적으로 압축된 모델로 성능을 유지하거나 개선하는 방법이다.
4.3.1 LTH and its Variants
-
LTH는 사전 학습된(Pre-trained) 모델에서 상대적으로 중요도가 낮은 가중치를 제거(프루닝)하고, 남은 가중치를 초기화 시점(original initialization)으로 되돌려 다시 학습했을 때, 원래 모델과 비슷한 혹은 더 나은 성능을 낼 수 있는 작은 서브네트워크(Winning Ticket)가 존재한다는 가설
큰 네트워크 안에 이미 “좋은 초기화”를 가진 작은 네트워크가 숨어있으며, 이를 찾기만 해도 강력한 성능을 유지할 수 있다는 점을 시사
-
당첨 티켓은 전체 네트워크에서 불필요한 부분을 제거한 상태에서도 원래의 학습된 성능과 유사한 결과를 낼 수 있다.
2. 주요 변형 및 후속 연구
(1) 더 강력한 LTH 가설
- 일부 연구에서는 기존 LTH보다 더 강력한 가설을 제시한다.
- 예를 들어, Multi-Prize LTH는 극단적인 양자화 환경에서도 Winning Ticket을 찾을 수 있음을 보이기 위해 Multi-Prize Tickets (MPTs) 알고리즘을 제안
(2) 전이성(Transferability) 연구
- 한 데이터셋에서 찾은 당첨 티켓이 다른 데이터셋에서도 유효할 수 있음을 보인다.
- 당첨 티켓이 특정 환경에 국한되지 않고 범용적인 특성을 지닐 수 있다고 설명한다.
(3) 다른 문맥으로의 확장
- LTH는 이미지 분류뿐만 아니라 GAN, VAE, GNN, Transformer 등 다양한 신경망 모델에 확장하여 적용한다.
- 예를 들어, Graph Lottery Ticket (GLT)라는 방식이 제안되거나, NLP 모델인 BERT에서도 당첨 티켓이 발견된다.
LTH가 성공하는 이유 분석
- 재학습성 (relearnability)이 당첨 티켓이 성공할 수 있는 중요한 요인으로 작용한다.
(5) LTH에 대한 의문과 재검토
- 최근 연구들은 당첨 티켓의 성능이 학습 조건(학습률, 에폭, 네트워크 규모 등)에 크게 의존함을 지적한다.
- 이에 따라 LTH가 항상 성립하는 것은 아니며, 특정 조건 하에서만 유효할 수 있다고 주장한다.
전체 요약
- LTH는 조밀한 네트워크 내에 초기화된 상태로부터 다시 학습해도 성능을 유지할 수 있는 희소 서브네트워크(당첨 티켓)가 존재한다고 주장한다.
- 이 가설에 기반해 다양한 신경망 모델에서 당첨 티켓을 찾으려는 연구들이 진행된다.
- 후속 연구들은 LTH의 전이성, 이론적 타당성, 확장 가능성 등을 탐구하며, 때로는 LTH가 특정 학습 조건에 따라 달라질 수 있음을 제시한다.
이와 같이 LTH와 그 변형들에 관한 연구는, 학습된 조밀한 모델 안에 효율적인 희소 서브네트워크가 존재한다는 아이디어를 바탕으로, 다양한 접근법으로 이를 증명하고 응용하려는 노력을 보여준다.
4.3.2 Other score-based Methods
- 모델의 각 구성 요소(가중치, 필터, 또는 레이어)의 중요도를 점수로 산출한다.
- 산출된 점수를 기준으로, 중요도가 낮은 요소를 제거하여 모델 압축과 경량화를 달성한다.
- 이때 점수 산출 방법으로는 노름(norm), 테일러 근사(Taylor Approximation), 출력 영향 평가 등이 있다.
주요 평가 기준 및 방법
(1) 노름 (Norm) 기반 평가
- 핵심 아이디어:
각 가중치의 절댓값이나 필터의 전체 L2 노름을 이용하여 중요도를 측정한다. - 실행 방식:
- 가중치의 크기가 작으면 모델에 미치는 영향이 작다고 판단하고, 해당 가중치를 제거 대상으로 선택한다.
- 예시:
Han 등은 각 가중치의 절댓값 크기를 기준으로 중요도를 산출하여 가지치기를 수행한다.
(2) 테일러 근사 (Taylor Approximation) 기반 평가
- 핵심 아이디어:
특정 구성 요소(가중치, 필터 등)를 제거했을 때, 전체 손실 함수가 얼마나 변화하는지를 1차 또는 2차 테일러 근사로 추정한다. - 실행 방식:
- 손실 변화가 작은 구성 요소를 제거하면, 모델 성능에 미치는 영향이 적다고 판단한다.
- 예시:
- Nonnenmacher 등은 2차 테일러 근사를 통해 손실 변화를 예측하는 SOSP 방식을 제안한다.
- Ma 등은 LLM에서 1차 테일러 근사를 통해 가지치기 기준을 마련한다.
(3) 출력 영향 (Output Impact) 평가
- 핵심 아이디어:
특정 레이어 또는 블록이 모델의 출력에 미치는 영향을 평가한다. - 실행 방식:
- 예를 들어, 어떤 레이어를 제거했을 때 모델의 perplexity(PPL)나 중간 출력에 변화가 작다면, 해당 레이어의 중요도가 낮다고 판단한다.
- 예시:
- Men 등은 Block Influence (BI)를 도입하여, 레이어가 히든 스테이트에 미치는 영향도를 측정한다.
- Kim 등은 LLM에서 레이어 제거 시 PPL의 변화를 보고 중요도를 평가한다.
(4) 단계적 가지치기 및 점수 기반 업데이트
- 핵심 아이디어:
학습 과정에서 매 반복마다 누적된 마스크 기울기를 활용하여, 점진적으로 가지치기를 진행한다. - 실행 방식:
- 여러 단계를 거치며 점진적으로 중요도가 낮은 구성 요소들을 제거한다.
- 예시:
Shi 등은 이러한 방식으로, 큰 멀티모달 모델을 단계적으로 가지치기하는 UPop 방법을 제안한다.
종합 정리
- 목표:
각 가중치, 필터 또는 레이어의 중요도를 정량적으로 평가하여, 불필요한 중복이나 기여도가 낮은 요소를 선택적으로 제거한다.- 평가 기준:
- 노름: 가중치의 크기를 기준으로 평가한다.
- 테일러 근사: 구성 요소를 제거했을 때의 손실 변화를 추정한다.
- 출력 영향: 레이어 또는 블록이 모델 출력에 미치는 영향을 측정한다.
- 효과:
점수 기반 가지치기를 통해, 모델의 파라미터 수와 연산량을 효과적으로 줄이면서도 성능 저하를 최소화할 수 있다.
이와 같이 기타 점수 기반 가지치기 방법은 여러 평가 기준(노름, 테일러 근사, 출력 영향 등)을 활용하여, 모델의 불필요한 구성 요소를 효율적으로 제거하는 전략을 사용한다.
4.3.3 Sparsity Regularization based Methods
Sparsity Regularization는 학습 과정에서 불필요한 가중치나 채널, 필터를 0에 가깝게 만들어서, 모델을 압축(경량화)하는 데 기여한다.
주요 아이디어
-
희소성 정규화의 목적
- 모델 내 불필요한(중요도가 낮은) 부분의 값을 0으로 만들도록 유도한다.
- 이를 통해 모델의 연산량과 메모리 사용량을 줄이고, 과적합(overfitting)을 방지한다.
-
정규화 항 적용 방식
- 손실 함수에 L1 정규화나 그룹 라쏘(Group Lasso) 같은 희소성 정규화 항을 추가한다.
- 예를 들어, 전체 손실 함수는
와 같이 구성되며, 는 정규화 강도를 조절한다.
대표적인 방법들
-
2단계 알고리즘
- 단계 1: 사전 학습된 CNN 모델의 각 채널에 대해 별도의 스칼라 마스크(즉, scaling factor)를 연결한다.
- 단계 2: LASSO 회귀를 이용하여, 여러 채널들 중 중복되는 정보(즉, 비슷한 역할을 하는 채널)를 식별하고 제거한다.
L1정규화로 스칼라 마스크를 0으로 만듦
- 추가 처리: 제거되지 않은 채널의 출력은 선형 최소제곱법을 통해 재구성한다.
모델의 예측값과 실제 관측값 사이의 차이(잔차)의 제곱합을 최소화
-
에너지 제약 압축 (Energy-Constrained Compression, ECC)
-
이중선형(bilinear) 회귀 함수를 사용하여 에너지 소비 모델을 구축한다.
이중선형 회귀함수는 두 개의 입력 벡터(또는 변수 집합) 사이의 상호작용을 선형 방식으로 모델링하여 예측 값을 산출하는 함수
와 는 각각의 입력 벡터로 이중선형 회귀함수는 에 대해서도 선형적이고, 에 대해서도 선형적이다.
- 주로 서로 다른 두 변수 집합(예: 이미지의 특징 벡터와 텍스트의 임베딩)의 상호작용을 분석하고자 할 때 사용
-
에너지 소비 측면에서 효율적인 모델을 만들도록 희소성을 유도한다.
-
-
성능 최대화를 통한 네트워크 가지치기 (Network Pruning via Performance Maximization, NPPM)
- 성능 예측 네트워크를 학습하여, 이 네트워크가 모델 정확도의 대리 지표(proxy)로 사용된다.
- 정규화 페널티에 기반해 서브네트워크를 탐색하고, 가지치기할 후보를 결정한다.
-
DepGraph
- CNN, RNN, GNN, 트랜스포머 등 다양한 네트워크 구조에서, 각 구성 요소 간의 종속성(의존관계)을 분석한다.
- 이 정보를 바탕으로, 희소성 정규화를 적용한 구조적 가지치기를 수행한다.
-
정규화 기반 접근
- 정규화를 사용하여, 대형 언어 모델(LLM)에 대해 파라미터의 개수는 최소-모델 성능은 최대(min-max)로하는 목표 함수를 설정한다.
정규화는 전체 파라미터 중 0이 아닌 요소의 개수를 최소화하도록 하는 방법으로 정규화항은 미분이 불가능하기 때문에 근사 기법을 사용하여 학습한다.
- 가중치와 가지치기 마스크를 공동 최적화하여, 목표 아키텍처에 맞는 가지치기 마스크를 효율적으로 학습한다.
-
노름 기반 방법과 희소성 정규화 결합
- 가중치나 필터의 노름(norm) 등과 희소성 정규화를 결합하여, 중요도가 높은 요소를 선택하고 덜 중요한 요소를 제거한다.
전체적인 의의
- 모델 압축 및 경량화:
불필요한 부분을 제거함으로써, 모델의 파라미터 수와 연산량을 줄여 경량화한다.- 일반화 성능 향상:
불필요한 가중치를 줄이면 모델이 과적합되는 것을 방지하여, 새로운 데이터에 대한 일반화 성능을 개선한다.- 효율적인 가지치기:
다양한 기법들을 통해 모델 내 중요한 정보와 그렇지 않은 정보를 구분하며, 성능 저하 없이 가지치기를 수행하도록 한다.
이와 같이, 희소성 정규화 기반 방법들은 모델 학습 중 정규화 항을 통해 불필요한 파라미터를 자연스럽게 0에 가깝게 만듦으로써, 가지치기를 효과적으로 수행하고 모델 압축 및 경량화를 달성한다.
4.3.4 Pruning in Early Training
- 전통적인 pruning는 모델을 완전히 학습한 후에 pruning를 수행한다.
- 학습 초기에 pruning 방법은 전체 학습 전에, 몇 개의 Epoch만 학습한 후에 유망한 서브네트워크(당첨 티켓)를 식별한다.
핵심 아이디어
-
Early-Bird 티켓 발견
- 모델을 초기 몇 epoch만 학습하여, 전체 모델과 유사한 성능을 내는 서브네트워크(당첨 티켓)를 식별한다.
- 초기 단계에서는 비용이 적은 학습 기법(예: 얼리 스토핑, 저정밀도 학습, 높은 학습률 등)을 활용한다.
-
EarlyBERT 적용
- BERT와 같은 복잡한 모델에서도 학습 초기에 구조적 당첨 티켓을 찾아낸다.
- 이를 통해 모델의 중요한 구조를 빠르게 파악한다.
-
대규모 모델에서도 효과 확인
- ResNet-50, Inception-v3와 같이 복잡한 모델을 대상으로도, 학습 초기 단계에서 안정적인 서브네트워크가 존재함을 실험적으로 확인한다.
- 이는 학습 초기에 이미 모델의 중요한 구조가 나타남을 시사한다.
효과 및 의의
- 학습 시간 단축:
전체 학습 전에 유망한 서브네트워크를 식별하므로, 최종적으로 모델을 전부 학습하는 데 걸리는 시간을 단축할 수 있다. - 효율적인 모델 압축:
학습 초기에 pruning를 수행하여, 모델의 불필요한 부분을 빠르게 제거하고, 효율적인 네트워크 구조를 구성한다. - 성능 유지 및 개선:
초기 단계의 서브네트워크를 활용하여, pruning로 인한 정보 손실 없이 모델의 성능을 유지하거나 개선할 수 있다.
요약
- 학습 초기에 가지치기는 전체 학습 전 몇 Epoch만 학습하여, 모델 내 유망한 서브네트워크(당첨 티켓)를 빠르게 식별한다.
- Early-Bird 티켓과 EarlyBERT 기법 등이 이를 지원하며, 대규모 모델에서도 초기 단계에 유망한 서브네트워크가 존재함을 확인한다.
- 이 방법은 학습 비용을 줄이고, 모델을 효율적으로 압축하여 경량화 및 추론 효율성을 높인다.
이와 같이, 학습 초기에 가지치기는 전체 학습 전에 모델의 중요한 구조를 찾아내어, 불필요한 부분을 제거하고 효율적인 서브네트워크를 구성하는 방법이다. 추가로 궁금한 점이 있으면 말씀해 주세요.
Post-Training Pruning
-
사전 학습된 모델에 대해 retrain 없이 pruning를 수행한다.
-
보상 기법이나 재구성 기법을 통해 pruning로 인한 성능 저하를 보완한다.
보상기법은 pruning으로 인해 발생하는 성능 저하를 보완하는 기법으로 fine-tuning도 보상 기법 중 하나이다.
-
특히, 수십억 개의 파라미터를 가진 대형 모델에서 재학습 비용을 크게 줄일 수 있다.
- Retraining은 모델의 파라미터 전체를 완전히 처음부터 다시 학습시키는 과정
- Fine-tuning은 이미 학습된 모델의 파라미터를 약간만 수정하여 pruning 후 성능을 회복시키는 과정
주요 구성 요소
-
재학습 없이 pruning를 진행한다
- 전통적인 Pretrain–Prune–Retrain 방식 대신에, 사전 학습된 모델에 직접 가지치기를 적용한다.
-
보상 기법(Compensation Mechanisms)을 사용한다
- pruning로 인한 성능 저하를 보완하기 위해, 보상 기법이나 재구성 기법을 도입한다.
- 예를 들어, 피셔(Fisher) 기반 마스크 탐색, 재배치, 튜닝 기법을 활용하여 모델의 성능을 복구한다.
-
SparseGPT와 Wanda를 사용한 Unstructured pruning
- SparseGPT는 근사적 희소성 재구성 문제(approximate sparsity reconstruction)를 통해 학습 없이 최소 50% 이상의 가지치기를 달성한다.
- Wanda는 Weight magnitude와 Input norm을 활용하여 추가적인 가중치 업데이트 없이 pruning을 수행한다.
-
SliceGPT를 사용한 Structured pruning
- 정방행렬 변환과 주성분 분석(PCA)을 적용하여 LLM의 가중치 행렬에서 열과 행을 제거한다.
- 이를 통해 더 체계적인 구조적 가지치기를 구현한다.
-
FLAP를 통한 성능 복구
- 변동(fluctuation) 지표를 도입하고, 편향 보상 메커니즘을 사용하여 가지치기 후의 성능 저하를 보완한다.
효과
- 재학습 비용을 크게 줄인다:
전체 모델을 retraining하지 않고 pruning를 수행하므로, 대형 모델에서도 빠르고 효율적으로 압축할 수 있다.- 정확도 손실을 최소화한다:
보상 및 재구성 기법을 적용하여, pruning로 인한 모델 성능 저하를 거의 없게 한다.- 모델 압축을 효율적으로 달성한다:
불필요한 파라미터를 제거하여, 모델의 연산량과 메모리 사용량을 줄이고 경량화한다.
이와 같이, 학습 후 pruning은 pre-training된 모델에 대해 retrain 없이 pruning을 적용하고, 여러 보상 및 재구성 기법을 통해 성능 손실 없이 모델을 경량화하는 방법이다.
4.4 Run-time Pruning
- 런타임 pruning는 추론 시, 각 입력마다 불필요한 계산을 동적으로 생략하여 전체 연산량을 줄인다.
- 목표는 입력의 복잡도에 맞춰 최적의 계산 경로(서브네트워크)를 선택함으로써, 효율적이고 빠른 추론을 달성하는 데 있다.
주요 아이디어
-
입력의 다양성을 인지한다:
- 모든 입력이 동일한 계산을 요구하지 않음을 인식한다.
- 간단한 입력은 불필요한 연산을 줄여도 무방하며, 복잡한 입력은 추가 계산이 필요하다.
-
동적 경로 선택을 수행한다:
- 모델이 입력 데이터와 현재 특징 맵을 기반으로, 압축된 경로(서브네트워크)의 일부만 선택하도록 한다.
- 이를 통해, 입력마다 최적의 계산 경로를 동적으로 구성한다.
-
채널 중요도를 사전에 계산한다:
- 입력 데이터를 통해 각 채널의 중요도를 미리 평가한다.
- 추론 시, 중요도가 임계값보다 낮은 채널은 계산에서 건너뛴다.
-
중간 활성화 정보를 활용한다:
- 중간 결과의 일부 합 등 정보를 통해, 실시간으로 계산할 채널을 선택적으로 건너뛰는 전략을 사용한다.
-
자기지도 대조학습 및 DynaTran 기법을 적용한다:
- 대조학습 기반으로 각 채널이나 서브네트워크의 중요도를 평가하여, 실시간 pruning을 수행한다.
- 트랜스포머에서는 입력 행렬의 크기와 활성화 값을 분석해, 불필요한 계산을 건너뛰어 효율을 높인다.
효과
- 연산 효율을 향상시킨다:
불필요한 계산을 생략함으로써 전체 추론 속도를 개선한다. - 동적 최적화를 가능하게 한다:
각 입력의 복잡도에 따라 계산 경로를 조절하여, 자원 사용 및 에너지 소비를 줄인다. - 자원 절약에 기여한다:
GPU나 CPU에서 불필요한 연산이 줄어들어, 전반적인 시스템 효율성이 증가한다.
요약
- 런타임 가지치기는 입력마다 계산해야 하는 부분을 동적으로 결정한다.
- 여러 접근법(런타임 라우팅, 채널 중요도 평가, 중간 결과 활용, 대조학습, DynaTran 등)을 통해, 최적의 서브네트워크를 실시간으로 선택한다.
- 이를 통해 단순한 입력은 불필요한 연산을 줄이고, 복잡한 입력에는 필요한 연산을 제공하여, 전체 추론 속도와 효율성을 크게 향상시킨다.
이와 같이, 런타임 가지치기는 모델이 각 입력마다 동적으로 계산 경로를 최적화하여, 빠르고 효율적인 추론을 가능하게 한다. 추가로 궁금한 점이 있으면 말씀해 주세요.
5. Pruning Criteira
파라미터의 중요도를 평가하기 위해 사용되는 Pruning 기준을 요약한다.
- Magnitude
- Norm
- Saliency/Sensitivity
- Loss change
5.1 Magnitude-based Pruning
-
가중치 크기를 기준으로 한다:
각 가중치(또는 필터)의 절댓값이나 L2 노름이 작으면, 해당 가중치가 모델 출력에 미치는 영향이 작다고 가정한다. -
작은 가중치를 제거한다:
중요하지 않은(작은) 가중치는 모델에 큰 기여를 하지 않으므로, 제거하여 모델을 압축한다.
가지치기 결정 방식
(1) 임계값 기반 선택
- 각 가중치 에 대해,
와 같이 정의한다. - 라는 임계값을 설정하여, 가 (a)보다 작으면 를 0으로 하여 제거한다.
(2) 입력과 결합한 평가 (Wanda 방식)
- 가중치 에 대해, 해당 가중치의 중요도를 입력 의 L2 노름과 결합하여 계산한다.
- 점수 는 다음과 같이 정의한다:
- 값이 낮으면, 해당 가중치의 기여도가 작다고 판단하여 제거 대상으로 선택한다.
3. 왜 사용한다?
- 모델 단순화:
불필요한 가중치를 제거하여 모델의 파라미터 수와 연산량을 줄인다. - 과적합 방지:
중요하지 않은 파라미터가 제거되면, 모델이 학습 데이터에 과도하게 맞춰지는 것을 방지한다. - 효율적 학습:
중요한 가중치들만 남겨 모델을 경량화하고, 향후 추론 효율성과 일반화 성능을 높인다.
요약
- 크기 기반 가지치기는 가중치의 크기를 측정하여 임계값보다 작은 가중치를 제거한다.
- 단순히 가중치의 절댓값이나 L2 노름을 사용하며, Wanda와 같이 입력 정보까지 결합하여 정교하게 평가할 수도 있다.
- 이를 통해 모델의 불필요한 파라미터를 줄여, 경량화와 연산 효율성을 극대화한다.
이와 같이, 크기 기반 가지치기는 가중치의 크기를 평가하여 중요하지 않은 가중치를 제거하는 방식으로 모델을 압축하고 간결하게 만든다.
5.2 Norm
- 노름은 모델의 가중치나 필터의 “크기” 또는 “세기”를 측정하는 방법이다.
- 보통 노름을 계산하면, 필터 내의 모든 가중치의 제곱(또는 p제곱)을 더하고, 그 합의 p제곱근을 구한다.
- 이는 각 필터의 전체적인 활성 정도를 나타내며, 값이 크면 해당 필터가 중요한 정보를 담고 있다고 판단한다.
수식 설명
-
예를 들어, 한 필터 에 대한 노름은 다음과 같이 계산된다:
여기서:
- 는 해당 레이어 의 입력 채널 수이다.
- 는 레이어 (i)의 커널(필터) 크기를 의미한다.
- 는 필터 의 특정 위치에서의 가중치 값을 나타낸다.
가지치기 기준으로서의 활용
- 중요도 평가:
- 노름 값이 크면, 해당 필터의 가중치들이 전체적으로 큰 값들을 가지며, 중요한 정보를 학습하는 데 기여한다고 판단한다.
- 반대로, 노름 값이 작으면, 그 필터가 모델 출력에 미치는 영향이 작다고 보고, 가지치기 대상으로 선정된다.
- 희소성 정규화와의 결합:
- 노름 기반 평가와 희소성 정규화(L1 정규화 등)를 결합하면, 중요하지 않은 필터들을 효과적으로 0에 가깝게 만드는 방식으로 모델을 압축할 수 있다.
- 이를 통해 모델은 불필요한 파라미터를 줄이고, 경량화 및 효율적인 계산이 가능해진다.
**요약
- 노름은 필터나 가중치의 전체 크기를 측정하는 지표로 사용된다.
- 계산된 노름 값이 작으면, 해당 필터가 모델 출력에 기여하는 정도가 낮다고 간주한다.
- 가지치기에서는 이러한 노름을 기준으로, 중요도가 낮은 필터들을 제거하여 모델을 압축한다.
- 또한, 희소성 정규화 기법과 결합하여 모델의 불필요한 정보를 효과적으로 줄인다.
이와 같이, 노름을 활용하면 각 필터의 “크기”를 정량적으로 측정하여, 상대적으로 작은 값을 가진 필터들을 가지치기 대상으로 선택할 수 있다.
5.3 Sensitivity and/or Saliency
감도(Sensitivity)
- 의미
어떤 가중치(또는 필터, 뉴런)를 제거했을 때 손실(오차)이 얼마나 변화하는지를 측정한다.- 즉, 한 가중치를 제거했을 때 전체 모델의 성능이 급격히 떨어진다면, 그 가중치는 감도가 높다라고 판단한다.
- 예시
LeCun 등은 가중치 살리언시를 제거 후 손실의 변화량으로 정의한다.- 예를 들어, 만약라는 가중치를 제거했을 때 손실이 많이 증가한다면, 는 중요한 역할을 한다고 평가한다.
살리언시(Saliency)
- 의미
가중치나 채널이 모델 출력에 기여하는 정도, 즉 “중요도”를 나타내는 척도이다. - 예시
- 가중치의 미분값, 즉 그래디언트(gradient)의 크기를 활용해 “연결 감도(connection sensitivity)”를 계산한다.
여기서 는 가중치 의 감도 또는 살리언시를 의미하며, 는 마스크에 관해 를 미분한 값이다. - 이 값이 높으면, 해당 가중치가 모델 출력에 큰 영향을 준다고 판단한다.
- 가중치의 미분값, 즉 그래디언트(gradient)의 크기를 활용해 “연결 감도(connection sensitivity)”를 계산한다.
BN(Batch Normalization)에서의 채널 Saliency
-
방법
Zhao 등은 배치 정규화(BN) 레이어의 Scale factor 와 이동 항 를 결합하여, 이를 채널 saliency로 해석한다. -
수식
여기서 로 정의된다.
-
의미
- 값만 단순히 사용하는 대신, 와 의 조합 혹은 분포를 참고하여, 각 채널의 출력 기여도가 낮은 채널을 판단한다.
- 중요하지 않은 채널은 Saliency 값이 낮게 측정되어 가지치기 대상으로 선정된다.
요약
- 감도/살리언시 기준을 사용한다:
- 각 가중치 또는 채널이 제거되었을 때 손실이 어떻게 변화하는지, 즉 모델 성능에 미치는 영향을 평가하여, 중요도를 정량화한다.
- Pruning 대상 결정에 활용한다:
- 감도나 살리언시 값이 낮은(제거해도 성능에 미치는 영향이 작은) 부분은 가지치기하여, 모델의 불필요한 파라미터를 줄인다.
- 모델 압축 및 경량화를 달성한다:
- 중요하지 않은 구성 요소를 제거함으로써, 모델 크기와 연산량을 줄이고, 효율성을 높인다.
요약하면, 감도와 살리언시는 가지치기에서 각 가중치나 채널이 모델 성능에 얼마나 중요한지를 수치로 나타내는 척도이다.
- 감도는 해당 요소를 제거했을 때 손실 함수가 얼마나 변하는지로 측정하며,
- 살리언시는 그래디언트와 같은 정보를 기반으로 해당 요소의 중요도를 정량화한다.
이러한 척도를 활용해 중요도가 낮은 부분은 제거함으로써, 모델 압축과 효율화를 달성한다.
5.4 Loss change
손실 변화 기반 Pruning은, 특정 가중치나 필터를 제거했을 때 전체 손실 함수가 얼마나 변하는지를 측정하여 그 요소의 중요도를 평가한다. 손실 변화가 작으면 해당 요소의 제거가 모델 성능에 미치는 영향이 적다고 판단하여 가지치기 대상으로 선정한다.
1차 테일러 전개를 통한 손실 변화 추정
-
기본 원리
- 가중치 에 미세한 변화 를 주었을 때 손실 가 어떻게 변하는지를 1차 테일러 전개를 통해 근사한다.
-
수식:
-
의미
-
은 가중치 (W)에 대한 손실 함수의 기울기(gradient)이다.
손실 함수 가 가중치 에 대해 얼마나 민감하게 변하는지를 알려주는 값
가중치를 조금 바꿨을 때 손실이 얼마나 변하는지
-
만약 특정 가중치를 제거하는 변화 에 대해, 의 절댓값이 작다면, 해당 가중치가 제거되어도 손실이 크게 증가하지 않으므로 중요도가 낮다고 판단하여 제거한다.
-
2차 테일러 전개를 통한 손실 변화 추정
- 기본 원리
- 1차 항에 더해, 가중치 변화에 따른 2차 미분(헤시안, ) 항까지 고려하여 손실 변화를 보다 정밀하게 추정한다.
- 수식
- 설명
- 여기서 는 손실 함수 의 2차 미분(헤시안) 행렬이다.
헤시안 행렬 는 손실 함수의 곡률(즉, 기울기의 변화율)을 나타낸다
2차 항을 포함하면, 가중치 변경으로 인한 손실 변화량을 보다 정밀하게 예측
- 는 제거하고자 하는 가중치에 해당하는 변화 벡터이다.
- 2차 테일러 전개를 사용하면, 1차 근사보다 더 정확하게 가중치 제거에 따른 손실 증가량을 예측할 수 있다.
- 여기서 는 손실 함수 의 2차 미분(헤시안) 행렬이다.
1차 Tayler vs 2차 Tayler
1차 테일러 근사는 가중치 변경의 "즉각적인" 효과만 반영한다.
하지만 실제로는 가중치 사이의 상호작용으로 인해 비선형 효과가 발생할 수 있는데, 2차 항을 포함하면 이런 비선형 효과도 고려할 수 있다
-
1차 테일러 전개는 모델의 손실 함수가 작은 변화에 대해 직선적인 변화를 보인다고 가정
만약 특정 가중치를 아주 소량만 바꾼다고 생각하면, 이 변화는 가중치의 기울기(gradient)에 비례하여 손실 함수가 변화한다고 보는 것
즉, 가중치 하나의 영향이 곧바로 그 가중치의 기울기에 의해 결정된다고 보는 것
-
2차 테일러 전개에서는 실제로는 각 가중치들이 서로 상호작용하며 모델의 성능에 영향을 미치는 것을 고려한다
신경망 내에서는 여러 가중치가 복합적으로 작용하여 출력에 영향을 미친다
1차 근사는 개별 가중치의 변화가 독립적이라고 가정하지만, 실제로는 가중치들이 서로 영향을 주기 때문에 이들의 변화가 단순 선형 반응을 넘어서게 된다
가지치기 기준으로의 활용
- 중요도 평가:
- 각 가중치나 필터를 제거했을 때의 손실 변화를 계산하여, 그 값이 작으면 해당 요소가 모델에 중요하지 않다고 판단한다.
- 선택 및 제거:
- 손실 변화가 작게 측정된 요소들을 가지치기 대상으로 선택하여 제거한다.
- 모델 압축:
- 이러한 과정을 통해 불필요한 요소들을 제거하고, 모델의 파라미터 수와 연산량을 줄여 경량화한다.
요약
- 1차 테일러 전개는 간단하게 변화량을 예측하여 빠르게 중요도를 평가한다.
- 2차 테일러 전개는 헤시안 항까지 고려하여 보다 정밀하게 손실 변화를 측정한다.
- 두 방법을 통해, 제거 후 손실 변화가 적은 요소를 선택하여 가지치기하면 모델 성능을 크게 저하시키지 않고 모델을 압축할 수 있다.
이와 같이, 손실 변화 기준은 가중치나 필터를 제거했을 때 모델 손실이 얼마나 변화하는지를 측정하여, 중요도가 낮은 요소를 제거함으로써 모델을 압축하는 데 사용된다.
6. Learn to Prune
- pruning 학습:
네트워크가 스스로 pruning을 수행하도록 만드는 여러 방법들을 연구한다.- 희소성 정규화 기반 가지치기
- 메타 학습 기반 가지치기
- 그래프 신경망(GNN) 기반 가지치기
- 강화 학습(RL) 기반 가지치기 등
6.1 희소성 정규화 기반 가지치기 (Sparsity Regularization based Pruning)
- 희소성 정규화란:
학습 과정에서 모델의 가중치 혹은 가지치기 마스크 등에서 불필요한(중요하지 않은) 값들을 0에 가깝게 유도하여, 모델을 희소한(sparse) 상태로 만든다. - 목표
모델 내 불필요한 요소들을 제거하여, 모델의 파라미터 수와 연산 비용을 줄이고 경량화한다.
수식
-
최적화 문제를 설정:
모델의 전체 손실은 데이터 손실과 희소성 정규화 항으로 구성된다.- : 가지치기가 반영된 모델의 데이터 손실
- : 구조적 희소성을 강제하는 정규화 항
- : 정규화 강도를 조절하는 하이퍼파라미터
-
스케일링 팩터 활용한다:
각 채널 또는 필터에 스케일링 팩터(예: BN 레이어의 또는 별도로 도입한 스칼라)를 부여하고, 이 값에 L1 정규화 같은 희소성 정규화를 적용하여, 중요하지 않은 채널의 스케일링 값이 0에 가깝게 된다.- 결과적으로, 해당 채널은 출력에 거의 기여하지 않게 되어 pruning 효과를 얻는다.
예시
-
단계 1:
- 사전 학습된 CNN 모델의 각 채널에 대해 별도의 스칼라 마스크(즉, 스케일링 팩터, 등)를 연결한다.
-
단계 2:
-
LASSO 회귀를 활용하여, 여러 채널 중 중복되는 정보 또는 비슷한 역할을 하는 채널을 식별한다.
만약 두 개 이상의 채널이 비슷한 정보(동일한 특징)를 추출할 경우,해당 특징을 "대표"할 수 있는 채널만 남기고, 나머지 채널의 값은 줄어들어 0에 가까워진다.
-
이때 L1 정규화와 유사한 방식으로 스칼라 마스크의 값을 0에 가깝게 만들어, 중요하지 않은 채널을 제거 대상으로 결정한다.
-
-
추가 처리:
- 제거되지 않은 채널의 출력은 선형 최소제곱법을 사용해 재구성하여, 가지치기로 인한 정보 손실을 보완한다.
효과
- 모델 압축을 달성한다:
불필요한 가중치와 채널을 제거하여 전체 모델의 파라미터 수와 연산량을 줄인다.- 성능 유지 및 개선:
중요한 요소는 유지하면서, 제거 대상은 0에 가깝게 만들어 성능 저하를 최소화한다.- 효율적인 최적화를 가능하게 한다:
가중치와 가지치기 마스크를 동시에 최적화하여, 목표로 하는 희소한 모델 구조를 효과적으로 학습한다.
이와 같이, "희소성 정규화 기반 가지치기" 방법은 모델 학습 중에 정규화 항을 추가하여 중요하지 않은 가중치나 채널(또는 스칼라 마스크)을 0에 가깝게 만들고, 이를 통해 불필요한 부분을 제거하여 모델을 경량화하고 효율적으로 압축한다.
6.2 Meta-Learning based Pruning
- 메타 학습 기반 가지치기는, pruning 작업 자체를 학습하도록 만든다.
- 이 방식은 모델을 가지치기할 때, 단순히 규칙이나 손실 기반으로 제거할 대상을 결정하는 대신, 메타 네트워크를 학습시켜 pruning된 네트워크의 가중치를 예측하도록 한다.
PruningNet의 역할
- PruningNet은 메타 네트워크로, 다양한 가지치기 설정(예: 레이어별 채널 수 등)을 인코딩한 벡터를 입력으로 받아, 해당 가지치기 설정에 맞는 새로운 가중치 를 생성한다.
- 입력으로 사용되는 네트워크 인코딩 벡터는 형태이며, 여기서 는 번째 레이어에서 남기고자 하는 채널 수 등과 같은 정보를 포함한다.
메타 네트워크를 사용하면 pruning 대상(채널이나 필터)를 결정할 때 후보가 매우 많은데 여러 가지 설정 중에서 최적의 pruning 구조를 찾아낼 수 있다
메타 학습 기반 가지치기의 구체적 과정
-
메타 네트워크 학습:
- PruningNet을 학습하여, 다양한 가지치기 설정에 따른 가지치기된 네트워크의 가중치를 예측할 수 있도록 한다.
- 학습된 PruningNet은 주어진 네트워크 인코딩 벡터를 입력받으면, 그에 상응하는 pruning된 네트워크의 가중치를 출력한다.
여러 레이어에 대해 남길 채널 수나 구조 정보를 입력받으면,
그 입력을 바탕으로, 어떤 채널을 남기고 어떤 채널은 제거할지, 그리고 제거된 후 남은 네트워크의 가중치를 어떻게 조정할지를 예측한다
-
네트워크 인코딩 벡터 탐색:
- pruning 후보로 고려되는 다양한 네트워크 인코딩 벡터의 탐색 공간은 매우 크다.
- 따라서, PruningNet을 통해 직접 모든 후보를 평가하기는 어렵고, 이를 진화적 탐색(evolutionary search)과 같은 방법을 사용하여 효율적으로 탐색한다.
- 이를 통해 제약 조건 하에서 최적의 pruning 설정과 해당 가중치를 찾는다.
기대 효과 및 장점
- 자동 가지치기:
- PruningNet을 통해 pruning할 네트워크의 가중치를 예측하므로, 수동으로 pruning 비율 등을 설정할 필요 없이, 자동으로 pruning된 네트워크를 생성할 수 있다.
- 유연성 증대:
- 다양한 pruning 설정(예: 각 레이어별 남길 채널 수 등)을 메타 네트워크의 입력으로 사용하여, 복잡한 모델에서도 최적의 pruning를 수행한다.
- 효율적 탐색:
- 진화적 탐색을 사용해, 방대한 후보 공간에서 효율적으로 최적의 가지치기 설정을 찾는다.
요약
- 메타 학습 기반 pruning는, 메타 네트워크(PruningNet)를 학습시켜, 주어진 가지치기 설정에 맞는 네트워크 가중치를 예측한다.
- 네트워크 인코딩 벡터를 통해 가지치기 정보를 전달하고, 진화적 탐색 등으로 최적의 설정을 찾는다.
- 이를 통해, pruning 과정이 자동화되고 모델의 경량화와 성능 유지가 동시에 달성된다.
이와 같이 메타 학습 기반 pruning는, pruning 작업을 별도의 규칙이나 손실 함수 대신 메타 네트워크가 예측하도록 함으로써, 더 유연하고 자동화된 가지치기를 가능하게 한다.
6.3 Graph Neural Network based Pruning
-
네트워크를 그래프로 본다:
- 임의의 신경망은 노드와 엣지로 구성된 그래프로 표현할 수 있다.
- 각 레이어나 구성 요소(예: 채널, 필터 등)를 노드로 보고, 이들 간의 관계를 엣지로 연결한다고 생각한다.
-
그래프 어그리게이터 를 사용한다:
- 그래프 어그리게이터는 각 노드에 대해 고차원 특징(embedding features)을 추출하는 역할을 한다.
- 입력으로 각 노드의 임베딩 를 받아, 전체 네트워크에 걸친 정보를 집합적으로 처리하여, 각 레이어에 대한 요약 정보를 로 만든다.
전체 신경망의 각 레이어나 채널을 하나의 노드로 보고, 이 노드들로부터 중요한 특징(임베딩, 집계 정보 등)을 추출
가지치기된 네트워크 생성 과정
- 노드 임베딩 추출:
-
각 레이어에 대응하는 임베딩 특성 를 사용한다.
-
그래프 어그리게이터 는 이 임베딩들을 입력받아,
와 같이 각 레이어별 요약 정보를 산출한다.
-
- FC 레이어를 통해 가중치 생성:
- 각 요약 정보 에 대해, 해당 레이어의 완전연결(FC) 레이어 가 작동한다.
- 이를 통해, 가지치기된 네트워크의 가중치 를 아래와 같이 생성한다:
- 여기서 는 -번째 FC 레이어의 가중치이다.
FC 레이어는 "요약 정보"를 입력받아, 해당 레이어에서 중요한 부분은 남기고 불필요한 부분은 제거한, 최종적인 가중치 집합을 결정 - 추출된 추상적 특징을 구체적인 가중치 값으로 매핑하여, 최종 모델에 적용
- 여기서 는 -번째 FC 레이어의 가중치이다.
- Pruned Network 완전 학습:
- 위 과정을 통해 생성된 가지치기된 네트워크(“Pruned Network”)는 이후 완전히 학습된다.
- 강화 학습을 통한 최적 탐색:
- 계산 제약 조건 하에서 최적의 가지치기 구조를 찾기 위해, 강화 학습(RL) 방법을 사용하여 가지치기된 네트워크의 구성(예: 어떤 채널을 남길지 등)을 탐색한다.
- 이 과정에서 그래프 어그리게이터와 FC 레이어의 가중치는 업데이트되지 않고 고정된 상태로 유지된다.
요약
- 네트워크를 그래프로 해석한다:
- 신경망의 각 구성 요소를 노드로 보고, 이들 간의 관계를 통해 전체 모델을 그래프로 표현한다.
- 그래프 어그리게이터 와 FC 레이어를 사용하여 가지치기된 가중치를 생성한다:
- 는 각 노드(레이어)의 임베딩 특징을 집계하여, 요약 정보를 생성한다.
- 각 FC 레이어는 이 요약 정보를 바탕으로, 해당 레이어에 적용할 가지치기된 가중치를 생성한다.
- 강화 학습을 통해 최적의 가지치기 구조를 탐색한다:
- 계산 제약 하에서 최적의 모델 구조를 찾기 위해, 강화 학습 기법을 적용하여 가지치기된 네트워크의 구성을 결정한다.
결과적으로, Graph Neural Network 기반 가지치기 방법은 신경망 전체를 그래프로 보고, 그래프 어그리게이터와 FC 레이어를 통해 가지치기된 네트워크를 생성한 후, 강화 학습을 통해 최적의 구조를 탐색하여 모델을 경량화한다.
이와 같이, 이 방법은 기존의 가지치기 방식과 달리 네트워크의 구조적 관계를 고려하여 효과적으로 불필요한 구성 요소를 제거한다.
6.4 Reinforment Learning based Pruning
-
강화 학습이란:
에이전트가 환경과 상호작용하며 어떤 행동을 선택하고, 그에 따른 보상을 받아 최적의 정책을 학습하는 방법이다. -
pruning에서의 강화 학습:
- 신경망의 각 레이어(또는 구성 요소)에 대해 어떤 pruning(제거할 가중치 또는 채널)를 적용할지 결정하는 문제를 강화 학습으로 해결한다.
- 에이전트는 각 레이어의 상태를 관찰한 후, 특정 행동(예: 얼마만큼 가지치기를 할지)을 선택한다.
- 이렇게 선택된 행동들이 모델의 최종 성능과 계산 복잡도에 미치는 영향을 평가하여 최적의 가지치기 정책을 찾는다.
보상 함수(Reward Function)
강화 학습에서 보상 함수는 에이전트의 선택(행동)이 얼마나 좋은지를 평가하는 기준이다
에이전트는 보상 함수를 최대화하도록 정책을 학습한다.
-
목표:
가지치기를 통해 모델의 오류(Error)를 최소화하면서, 동시에 계산 복잡도(FLOPs)나 파라미터 수를 줄이는 것을 목표로 한다. -
보상 함수 정의:
에이전트가 선택한 pruning 행동의 결과에 따라 보상이 주어지며, 보상 함수는 다음과 같이 구성된다:
- 이 보상 함수는, 에러(오류)가 낮아지면서 동시에 계산 복잡도(또는 파라미터 수)가 줄어드는 행동을 에이전트가 선택하도록 유도한다.
에이전트는 단순히 가지치기를 많이 해서 모델을 작게 만드는 것(계산 복잡도 감소)만을 목표로 하지 않고, 모델 성능(정확도)도 유지하도록 학습
- 이 보상 함수는, 에러(오류)가 낮아지면서 동시에 계산 복잡도(또는 파라미터 수)가 줄어드는 행동을 에이전트가 선택하도록 유도한다.
강화 학습 알고리즘 적용
- 알고리즘 사용:
- 예를 들어, 딥 결정론적 정책 경사법(DDPG)과 같은 강화 학습 알고리즘을 사용하여, 각 레이어에 대해 가지치기 정책을 학습한다.
- 에이전트의 역할:
- 에이전트는 각 레이어의 상태(예: 현재 레이어의 가중치 분포, 중요도 등)를 관찰한 후, 어떤 pruning 행동을 취할지를 결정한다.
- 한 레이어에서의 결정이 끝나면, 에이전트는 다음 레이어로 이동해 또 다른 가지치기 행동을 선택하고, 이를 모든 레이어에 적용할 때까지 반복한다.
전체 과정 흐름
1. 에이전트 결정:
- 각 레이어의 상태를 보고, 가지치기 행동(어느 정도 요소를 제거할지)을 결정한다.
2. 보상 함수 평가:
- 결정된 행동으로 인한 결과(모델의 예측 에러와 계산 복잡도 변화)를 보상 함수가 평가한다.
- 이 평가 결과를 바탕으로, 에이전트는 정책을 갱신(학습)하여 다음 번 행동을 조정한다.
3. 최적의 가지치기 구조 도출:
- 반복 학습을 통해, 에이전트는 장기적으로 모델의 오류를 최소화하면서도 계산 비용을 줄이는(모델을 압축하는) 최적의 가지치기 정책을 습득한다.
전체적인 효과
- 효율적인 모델 압축:
강화 학습을 통해 최적의 가지치기 구조를 자동으로 탐색하므로, 가지치기 후에도 모델의 오류는 최소화되면서 계산 복잡도와 파라미터 수를 줄일 수 있다. - 재학습 비용 감소:
모델 전체를 재학습하지 않고도, 최적화된 가지치기 정책에 따라 모델을 압축할 수 있다. - 동적 최적화:
입력 데이터와 네트워크 상태에 따라 가지치기 정책을 동적으로 결정함으로써, 다양한 모델 구성에 효과적으로 대응할 수 있다.
요약
- 강화 학습 기반 가지치기는 에이전트가 각 레이어에서 최적의 가지치기 행동을 결정하도록 학습시키며,
- 보상 함수는 모델의 오류와 계산 복잡도(또는 파라미터 수)를 결합하여, 에러를 최소화하면서도 모델 압축 효과를 극대화하는 방향으로 유도한다.
- 이를 통해, 모델을 효율적으로 압축하고 재학습 비용을 크게 줄일 수 있다.
이와 같이, 강화 학습 기반 가지치기는 에이전트가 각 레이어에서 가지치기 정책을 자동으로 선택하도록 하여, 전체 모델의 성능 저하 없이 경량화와 계산 효율성을 달성할 수 있도록 설계된다.
7. A comprehensive Comparative Analysis
흔히 사용되는 모델을 대상으로 몇몇 pruning 방법을 비교한다
7.1 Unstructured vs. Structured Pruning
Unstructured Pruning
-
어떻게 제거하나:
- 모델 내 어디든, 가중치 단위로 개별적으로(remove weights anywhere) 제거한다.
- 즉, 중요도가 낮은 특정 가중치들만 골라서 0으로 만든다(마스크를 씌워 제거).
-
장점:
- 높은 제거 비율(Prune Ratio)에서도 정확도 손실을 작게 유지할 수 있는 경우가 많다.
- 세밀하게(개별 가중치 단위) 조정하므로, 비구조적 방식이 높은 유연성을 가진다.
-
단점:
- 가중치가 불규칙하게 제거되므로, 실제 하드웨어 가속(실제로 연산량과 메모리 사용을 줄이는 것)을 위해서는 특별한 라이브러리나 지원이 필요하다.
- 구조적으로는 여전히 "밀집된(dense) 형태"라서, 기본 연산에서 직접적인 속도 향상을 얻기 어렵다.
Structured Pruning
-
어떻게 제거하나:
- 필터나 채널 등, 모델 내 완전한 구조 단위(entire filters or channels)를 제거한다.
- 예: CNN에서 특정 필터(또는 채널) 전체를 통째로 없앤다.
-
장점:
- 제거 후 모델이 규칙적인(좁아진, reduced) 형태가 되므로, 하드웨어나 딥러닝 라이브러리에서 자연스럽게 속도 향상을 누릴 수 있다.
- 추가 라이브러리 지원 없이도 연산량이 직접적으로 줄어든다.
-
단점:
- 동일한 가지치기 비율에서, 비구조적 가지치기 대비 정확도 손실이 좀 더 크게 나타날 수 있다.
- 채널이나 필터 단위를 통째로 제거하므로, 정밀한(세밀한) 가지치기가 어렵다.
3. 핵심 비교 포인트
-
정확도 변화:
- 비구조적 가지치기는 미세 조정이 가능해서, 높은 제거 비율에서도 정확도를 더 잘 유지하는 편이다.
- 구조적 가지치기는 채널이나 필터 단위로 제거되어, 같은 비율에서 정확도 손실이 클 수 있다.
-
실제 가속 효과:
- 비구조적 가지치기는 불규칙한 희소성(irregular sparsity)이 생겨, 기본 라이브러리나 하드웨어에서 직접 속도 향상이 작다.
- 구조적 가지치기는 필터나 채널 단위로 제거되므로, 실제 연산량(FLOPs)이 효과적으로 줄어든다.
요약
- Unstructured Pruning:
- 가중치를 선택적으로 제거 → 정확도 유지에 유리하지만, 실제 연산 가속에 특별 지원 필요.
- Structured Pruning:
- 채널/필터 등 완전한 구조 단위로 제거 → 실제 계산량 감소 효과가 큼, 그러나 높은 비율에서 정확도 손실이 클 수 있다.
7.2 One-shot vs. Iterative pruning
pruning을 한 번에 수행하는 원샷(one-shot) 방식과, 여러 번 반복하는 점진적(iterative) 방식의 차이에 대해 설명한다.
원샷 가지치기 (One-shot Pruning)
- 원칙:
- 네트워크의 모든 가중치(또는 필터, 채널 등)에 대해 한 번만 점수를 계산하고, 그 점수를 기준으로 목표 pruning 비율에 도달하도록 한 번에 제거한다.
- 장점:
- 계산 비용이 적고, 가지치기 과정이 단순하다.
- 빠르게 모델 압축을 시도할 수 있다.
- 단점:
- 초기 점수 계산 시, 아직 가중치의 진정한 중요도가 명확하게 드러나지 않을 수 있다.
- 중요한 가중치라도 초기에는 낮게 평가될 위험이 있다.
- 일부 연구에서는 원샷 가지치기가 초기 레이어의 “붕괴(early layer collapse)” 현상을 일으켜, 모델 정확도가 크게 떨어질 수 있다고 지적한다.
Layer collapse
모델의 특정 레이어(특히 초반 레이어)에서 너무 많은 가중치나 뉴런이 한꺼번에 제거되어, 해당 레이어의 출력이 급격히 감소하거나 아예 0에 가까워지는 현상
점진적 가지치기 (Iterative Pruning)
- 원칙:
- 가지치기를 여러 단계로 나누어 수행한다.
- 각 단계마다 가중치의 점수를 계산하고, 일부만 제거한 후, 짧은 시간 동안 재학습(또는 fine-tuning)을 거친 후 다시 점수를 업데이트하고 추가로 제거한다.
- 장점:
- 가지치기를 여러 번 반복하면서 점차적으로 모델을 압축하므로, 중요한 가중치들이 시간이 지나면서 제대로 평가된다.
- 단계별 재학습을 통해 모델이 가지치기로 인한 성능 저하를 보완할 수 있다.
- 결과적으로, 점진적 가지치기는 높은 가지치기 비율에서도 전체 성능을 유지하거나 더 좋은 성능을 얻을 가능성이 높다.
- 단점:
- 가지치기-재학습 과정을 여러 번 반복하기 때문에 계산 비용과 시간이 많이 소요된다.
비교 및 결론
- 계산 비용:
- 원샷 가지치기는 한 번에 이루어지므로 계산 비용이 낮지만, 점진적 가지치기는 여러 단계를 거치기 때문에 계산 비용이 높다.
- 성능 유지:
- 원샷 가지치기는 초기 점수에 의존하므로 잘못된 제거로 인해 성능이 크게 떨어질 수 있다.
- 점진적 가지치기는 반복적인 재학습을 통해 중요한 가중치와 덜 중요한 가중치를 보다 정확하게 구분하므로, 전체 성능을 더 잘 유지할 수 있다.
- 실험 결과:
- 일부 연구에서는 CIFAR-10, VGG-16, ResNet-32 등의 모델에서 원샷과 점진적 가지치기를 비교했으며, 특정 상황에서는 두 방식이 유사한 성능을 보이기도 하지만, WikiText2와 같이 대규모 데이터셋에서는 점진적 가지치기가 전반적으로 더 우수한 성능을 나타낸다고 보고된다.
- 그림 7 (a–c)는 점진적 가지치기가 더 나은 성능을 보이는 경우를, 그림 7 (d)는 원샷 가지치기의 결과를 시사한다.
요약
- 원샷 가지치기:
- 한 번 점수를 계산하고 한 번에 제거한다.
- 빠르고 간단하지만, 초기 점수의 부정확성으로 성능에 문제가 생길 수 있다.
- 점진적 가지치기:
- 여러 단계에 걸쳐 점수 계산, 가지치기, 재학습을 반복한다.
- 계산 비용은 높으나, 중요한 가중치를 보다 신중하게 선택하여 모델 성능을 유지하거나 개선한다.
따라서, 어느 방식이 적합한지는 모델의 규모, 계산 자원, 그리고 요구하는 최종 성능에 따라 달라진다.
이와 같이, 원샷 가지치기와 점진적 가지치기의 차이는 한 번에 모든 것을 처리하는지, 여러 번 반복하면서 점진적으로 최적의 구조를 찾아가는지에 달려있으며, 각 방식은 장단점이 존재한다.
7.3 Data-free vs. Data-driven Pruning
가지치기 방식의 분류
-
Data-free Pruning:
- 의미:
가지치기 과정에서 학습 데이터나 실제 입력 데이터를 사용하지 않고, 오직 모델의 초기화된 가중치나 구조 정보만을 기반으로 가지치기를 수행한다. - 예시:
SynFlow, 랜덤 방식, 크기 기반 방식 등이 이에 해당한다.
- 의미:
-
Data-driven Pruning:
- 의미:
가지치기 과정에서 실제 학습 데이터를 사용하여, 가중치나 필터의 중요도(점수)를 평가하고 가지치기를 수행한다. - 예시:
SNIP, GraSP, Wanda, LLM-Pruner, LoRA Pruner 등은 데이터를 활용해 가지치기 후보를 결정한다.
- 의미:
Data-driven Pruning의 필요성
- 좋은 서브네트워크를 찾기 위해서는, 일반적으로 실제 데이터에 의한 평가가 중요하다고 여겨진다.
- 대부분의 가지치기 연구는 데이터를 활용해 모델을 평가하고 가지치기 결정을 내리는 데이터-driven 방식을 사용한다.
- 그러나 데이터-프리 방식 역시 일부 연구에서 사용되며, 반드시 데이터에 의존하지 않아도 어느 정도 효과를 낼 수 있음을 보여준다.
3. 실험 비교
-
PBT 방식:
- PBT(Pruning Before Training)를 적용할 때, SynFlow와 SNIP와 같은 방법을 사용해 CIFAR-10/100 및 ImageNet에서 VGG-16, ResNet-32/50 모델을 가지치기한다.
- 실험 결과, SynFlow와 SNIP는 유사한 수준의 가지치기 효과를 보이며, SynFlow가 GraSP보다 상당히 우수한 성능을 보인다.
- 이는 PBT 방식의 효과가 반드시 데이터 사용 여부에 전적으로 의존하지 않을 수 있음을 시사한다.
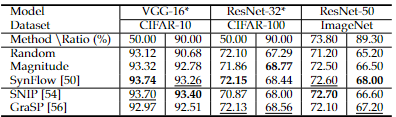
-
PAT 방식:
- PAT(Pruning After Training)를 적용할 때는, 랜덤이나 L1/L2-노름 기반 방식 같은 데이터-프리 가지치기 방법과 Wanda, LLM-Pruner, LoRA Pruner 같은 데이터-드리븐 가지치기 방법을 비교한다.
- 실험 결과(표 8 참조), 데이터-드리븐 방식이 대체로 데이터-프리 방식보다 더 좋은 성능(예: 높은 정확도, 낮은 펄플렉서티 등)을 보인다.
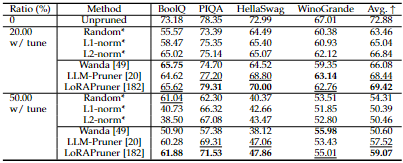
결론
- 데이터 사용의 효과:
- 데이터-드리븐 가지치기는 실제 데이터를 활용해 모델의 성능에 미치는 영향을 구체적으로 평가할 수 있으므로, 가지치기 후에도 모델 성능 유지가 상대적으로 용이하다.
- 데이터-프리 방식의 장점:
- 데이터에 의존하지 않기 때문에, 학습 데이터가 제한적이거나 모델 초기 단계에서 빠르게 가지치기를 수행해야 하는 경우 유리할 수 있다.
- 선택 기준:
- 어느 방식을 사용할지는 모델의 특성, 사용 가능한 데이터의 양, 가지치기 후 성능 유지에 대한 요구 등에 따라 달라진다.
- 실험 결과에 따르면, 특히 PAT 방식에서는 데이터-드리븐 가지치기가 전반적으로 더 우수한 성능을 보인다고 시사한다.
이와 같이, "Data-free vs. Data-driven Pruning" 섹션은 pruning 방법을 데이터 사용 여부에 따라 구분하고, 각각의 방식이 가지는 장단점과 실험적 결과를 설명한다. 데이터-드리븐 가지치기는 실제 데이터를 사용해 모델의 중요도를 평가하므로, 성능 유지 측면에서 유리한 반면, 데이터-프리 가지치기는 데이터에 의존하지 않아 빠른 처리가 가능하다는 점을 강조한다.
7.4 Pruning on Initialized vs. Pre-trained Weights
무작위 초기화된 가중치 기반 프루닝 (Initialization-based Pruning)
작동 원리
- 과정:
- 모델의 학습 전 단계에서, 모든 가중치가 무작위로 초기화된 상태에서 프루닝 기법(예: SNIP, GraSP, SynFlow)을 적용합니다.
- 프루닝 대상이 되는 가중치(또는 연결)는 미리 정의된 기준(예: 기울기, 손실 변화 등)에 따라 선택됩니다.
초기화 단계에서 중요한 서브네트워크(Winning Ticket)가 이미 존재할 수 있음을 가정하고 데이터 없이, 또는 최소한의 데이터 정보만을 사용하여 프루닝을 수행한다
- 프루닝 후 처리:
- 선택된 가중치는 제거되거나, 가중치의 역할이 0인 마스크 형태로 유지됩니다.
- 프루닝 후에는 프루닝된 서브네트워크를 별도의 학습 단계에서 다시 학습(fine-tuning)하거나, 처음부터 다시 학습시키는 경우도 있습니다.
특징 및 장점
- 강인성(Robustness):
- 프루닝 후 마스크의 위치를 섞거나, 가중치를 재초기화하는 등의 조작(ablations)을 가해도 서브네트워크의 성능이 크게 떨어지지 않는 경우가 많습니다.
- 이는 무작위 초기화 시에 가중치 분포가 상대적으로 균일하게 유지되며, 프루닝 과정에서 제거되는 가중치들이 전체적인 구조에 미치는 영향이 작기 때문입니다.
pruning 후 생성된 구조적 패턴 자체가 이후 학습에서 중요한 역할을 하기 때문에, 개별 가중치의 초기 값은 상대적으로 덜 중요하게 됩니다
- 복잡도 감소:
- 학습 전에 바로 불필요한 가중치를 제거하므로, 전체 모델 구조가 간소화되어 학습 과정에 필요한 연산량이 줄어들 수 있습니다.
단점 및 고려 사항
- 초기 학습 성능 한계:
- 사전 학습 단계 없이 프루닝을 진행하기 때문에, 원래 학습된 네트워크보다 최적의 성능에 도달하는 데 추가적인 학습 노력이 필요할 수 있습니다.
- 예측 가능성 부족:
- 무작위 초기화 기반 방법은 동일한 환경이라 하더라도 여러 번 반복 시 결과가 다르게 나타날 가능성이 있으며, 일관된 성능 보장이 어려울 수 있습니다.
사전 학습된 가중치 기반 프루닝 (Pre-trained Weight-based Pruning)
작동 원리
- 과정:
- 이미 학습된, 즉 데이터에 대해 최적화된 모델의 가중치를 활용하여 프루닝을 진행합니다.
- 예를 들어, Lottery Ticket Hypothesis(LTH)에서는 학습된 네트워크에서 중요도가 낮은 가중치를 제거하고, 남은 가중치를 유지하여 동일한 초기화로 재학습하는 전략을 취합니다.
- 프루닝 후 처리:
- 프루닝된 모델은 보통 재학습(fine-tuning)을 거치며, 이 과정에서 사전 학습된 가중치에 담긴 정보를 최대한 보존하려고 합니다.
특징 및 장점
- 학습된 정보 활용:
- 사전 학습을 통해 이미 데이터의 패턴과 특징이 잘 반영되어 있는 가중치 정보를 활용하기 때문에, 초기 모델보다 높은 성능을 기대할 수 있습니다.
- 특히, 가중치의 “위치” 정보(어떤 부분에 위치하는지가 중요한 정보)가 중요한 역할을 합니다.
- 정밀한 프루닝:
- 가중치의 중요도를 평가하는 기준(예: 가중치 절대값, 기울기, 손실 변화)을 보다 정교하게 적용할 수 있어, 보다 미세한 프루닝이 가능해집니다.
단점 및 고려 사항
- 민감도 문제:
- 사전 학습된 가중치에는 이미 최적화된 정보가 담겨 있기 때문에, 프루닝 과정에서 가중치의 위치나 값이 변경되면 전체 모델 성능에 큰 영향을 줄 수 있습니다.
- Qiu와 Suda에서는 가중치를 “위치”와 “정확한 값” 두 가지 관점에서 분석하며, 특히 “위치” 정보가 변경되면 성능 저하를 불러올 수 있다고 분석합니다.
- 프루닝 후 재학습 비용:
- 사전 학습된 상태에서 프루닝한 후, 해당 정보에 맞춰 모델을 재조정해야 하므로 재학습 비용이 증가할 수 있습니다.
모델 유형에 따른 적용 차이
CNN (Convolutional Neural Networks)
- 무작위 초기화 기반 프루닝:
- CNN에서는 무작위 초기화된 가중치로 프루닝을 수행해도 어느 정도 강인한 서브네트워크가 도출될 수 있음.
- 가중치 분포가 비교적 균일하며, 불필요한 가중치를 제거하더라도 구조적 안정성이 유지됨.
- 사전 학습 기반 프루닝:
- CNN에서도 사전 학습된 가중치를 활용하면 좋은 성능을 얻을 수 있으나, 가중치의 재배치나 변화에 민감해질 수 있음.
트랜스포머(Transformers)
- 필수적인 사전 학습:
- 트랜스포머 모델은 대개 자기지도 학습(self-supervised learning) 단계를 거쳐야 하는데, 이는 모델의 성능 향상을 위해 필수적입니다.
- 따라서 트랜스포머의 프루닝은 보통 사전 학습된 모델을 대상으로 진행합니다.
- 실험 결과:
- 일부 연구 결과(PBT 방식, 예: GraSP [56])에서는 사전 학습된 가중치를 사용했어도 항상 Top-1 정확도가 향상되지는 않았습니다.
- 반면, PAT 방식(PAT: 사전 학습 후 프루닝; 예: WDPruning [159])에서는 사전 학습이 성능 개선에 더 큰 기여를 하는 것으로 나타났습니다.
요약
- 무작위 초기화 기반 프루닝
- 장점:
- 프루닝 후 다양한 변화(마스크 재배치, 가중치 재초기화 등)에 대해 강인함
- 모델 구조가 간소화되어 학습과 추론 효율이 개선될 가능성이 있음
- 단점:
- 초기 학습 단계에서 최적 성능 달성까지 추가 학습 필요
- 결과의 일관성이 다소 낮을 수 있음
- 사전 학습된 가중치 기반 프루닝
- 장점:
- 이미 최적화된 가중치 정보를 활용하여 보다 정밀한 프루닝 가능
- 데이터에서 학습된 유용한 패턴을 보존할 수 있음
- 단점:
- 가중치의 위치나 값 변화에 민감하여, 프루닝 후 재학습이나 조정 비용 증가
- 민감한 가중치 정보 손실 시 전체 모델 성능 저하 우려
결론
프루닝 기법 선택은 모델의 구조(CNN vs. 트랜스포머), 학습 상태(초기화 vs. 사전 학습), 그리고 프루닝 후 재학습 과정에 따라 달라집니다.
- 무작위 초기화 기반 방식은 강인성 측면에서 유리하지만, 초기 성능 면에서 한계가 있을 수 있습니다.
- 사전 학습 기반 방식은 정밀한 프루닝을 가능하게 하지만, 변화에 민감하여 재학습 비용이 증가할 수 있습니다.
따라서, 각각의 프루닝 기법은 적용 대상 모델의 특성과 최종 목표(예: 추론 시간, 모델 경량화, 성능 유지 등)를 고려하여 선택해야 합니다.
7.5 Global vs. Local Pruning
Global Pruning
정의 및 작동 원리
- 정의:
네트워크 전체에서 모든 레이어의 가중치나 구조 요소를 하나의 통합된 기준으로 평가하여, 중요도가 낮은 요소부터 순서대로 제거하는 방식입니다. - 작동 원리:
- 전체 네트워크의 각 요소(가중치, 채널 등)에 대해 중요도(예: 가중치 절대값, 기울기, 손실 변화 등)를 산출함
- 레이어별로 개별 비율을 미리 정하지 않고, 전체 순위를 매겨 가장 중요도가 낮은 요소들을 제거함
- 이 과정에서 각 레이어 간 가중치의 스케일 차이를 고려하여 정규화 등의 추가 처리가 필요할 수 있음
장점 및 단점
-
장점:
- 유연성: 전체 네트워크를 고려하여, 불필요한 요소가 많은 레이어에서는 더 많은 프루닝을 적용할 수 있음
- 구조 최적화: 네트워크 전반의 중복이나 불필요한 부분을 집중적으로 제거하여, 효율적인 구조를 도출할 수 있음
-
단점:
- 스케일 문제: 네트워크 내 레이어마다 가중치 분포가 상이할 경우, 단순 비교 시 일부 레이어의 큰 값이 중요도를 왜곡할 위험이 있음
- 정규화 필요성: 레이어 간 스케일 차이를 보정하기 위한 정규화 기법이 추가로 요구됨
Local Pruning
정의 및 작동 원리
- 정의:
각 레이어별로 미리 정해진 고정 프루닝 비율(예: 해당 레이어에서 30%의 가중치를 제거)을 적용하는 방식입니다. - 작동 원리:
- 개별 레이어 내에서 가중치나 필터의 중요도를 산출하고, 해당 레이어 내에서 사전에 설정한 제거 비율에 따라 낮은 중요도를 가진 요소를 제거함
- 레이어 단위로 프루닝이 이루어지므로, 전체 네트워크의 통합적 평가보다는 각 레이어 내부의 상대적인 중요도에 초점을 맞춤
장점 및 단점
-
장점:
- 구현의 단순성: 각 레이어에 동일한 비율을 적용하므로 알고리즘이 직관적이고, 적용하기 쉬움
- 스케일 문제 완화: 각 레이어 내부에서 처리되기 때문에 레이어 간 가중치 크기 차이의 영향을 상대적으로 줄일 수 있음
-
단점:
- 비효율적 프루닝 가능성: 모든 레이어에 동일한 비율을 적용하면, 실제로 더 많이 제거해도 되는 레이어와 그렇지 않은 레이어의 차이를 반영하지 못할 수 있음
- 최적의 성능 미보장: 사전에 정해진 고정 비율이 네트워크의 최적 구조를 보장하지 않을 수 있음
대규모 언어 모델(LLM)에서의 적용 이슈
-
LLM의 특성:
- LLM은 수십억 개 이상의 파라미터를 가지며, 각 레이어 간에 가중치 크기(스케일)나 분포의 차이가 매우 큰 경우가 많습니다.
-
Global Pruning의 문제점:
- 네트워크 전체에서 중요도를 산출할 때, 일부 레이어의 가중치 값이 다른 레이어보다 월등히 크면 그 요소들이 과도하게 중요하게 평가될 위험이 있음
- 스케일 차이를 보정하기 위한 정규화가 필요함
-
Local Pruning의 한계:
- 모든 레이어에 고정된 비율을 적용하면, 레이어별 기여도 차이를 고려하지 못해 최적의 서브네트워크 구조를 얻기 어려울 수 있음
- 일부 레이어에서는 너무 많이 제거되거나, 반대로 필요 이상으로 유지되어 전체 성능에 부정적 영향을 줄 가능성이 있음
-
연구 동향:
- 최근 연구에서는 Global Pruning 기반 기법(SparseLLM 등)이 LLM의 레이어별 스케일 차이를 보다 잘 처리할 수 있는 방법으로 제안되고 있음
- 기존에는 주로 Local Pruning 방식이 사용되었으나, 이러한 한계를 극복하기 위한 새로운 접근법이 주목받고 있음
종합 비교 및 결론
-
Global Pruning
- 장점:
- 네트워크 전체를 고려해 불필요한 요소를 집중적으로 제거할 수 있음
- 각 레이어의 프루닝 정도를 자동으로 결정하여 유연한 구조 최적화가 가능함
- 단점:
- 레이어 간 가중치 스케일 차이가 큰 경우, 중요도 평가에 왜곡이 발생할 수 있음
- 추가적인 스케일 보정 및 정규화 기법이 필요함
- 장점:
-
Local Pruning
- 장점:
- 구현이 단순하며, 레이어 내부의 상대적 중요도를 기준으로 프루닝 적용 가능
- 레이어 간 스케일 차이 문제를 상대적으로 회피할 수 있음
- 단점:
- 모든 레이어에 동일한 비율을 적용함으로써, 실제 최적 구조와 맞지 않을 수 있음
- 고정된 프루닝 비율이 전체 네트워크의 성능 최적화를 보장하지 못할 수 있음
- 장점:
결론:
모델이나 데이터의 특성에 따라 Global Pruning과 Local Pruning은 각각 장단점을 보임.
- 대규모 언어 모델(LLM)에서는 레이어 간 가중치 스케일 차이가 크므로, Global Pruning 방식이 유리할 수 있으며, 이를 보완하기 위한 정규화 및 혼합 방식 연구가 진행되고 있다.
- 프루닝 기법 선택은 모델 구조, 목표(경량화, 추론 속도 개선 등), 그리고 데이터 특성을 종합적으로 고려하여 결정해야 한다.
이와 같이 Global과 Local Pruning은 각각 고유의 장점과 단점을 가지며, 특히 LLM과 같이 대규모 모델에서는 두 방식의 특성을 충분히 고려한 최적의 프루닝 전략을 선택하는 것이 중요하다.
7.6 Training from Scratch vs. Fine-tuning
- 프루닝(pruning) 후 모델의 성능을 회복하기 위하여 두 가지 주요 재학습 전략을 사용한다.
- 해당 전략은 프루닝된 서브네트워크를 처음부터 학습하는 것(Training from Scratch)과 사전 학습된 가중치를 기반으로 재조정(파인튜닝, Fine-tuning)하는 것이다.
- 또한, Weight Rewinding 기법을 사용하여 초기 학습 단계의 가중치를 다시 불러와 재학습하는 절충안도 존재한다.
Training from Scratch
정의
- 프루닝된 서브네트워크를 완전히 무작위 초기화한 후 처음부터 재학습한다.
특징 및 결과
- 무작위 초기화 후 재학습함으로써, 일부 연구에서는 사전 학습된 모델과 유사한 성능을 달성할 수 있다(예를 들어, Liu 등 [110]에서 ResNet, VGG 등이 그러하다).
- 그러나 특정 연구에서는 Training from Scratch 방법이 프루닝 후 성능이 낮아진다고 보고한다(Li 등 [63] 등).
- 프루닝 기법, 모델 아키텍처, 데이터셋 등에 따라 결과가 달라진다.
Fine-tuning
정의
- 사전 학습된 모델의 가중치를 재사용하여 프루닝된 모델을 추가로 학습시킴으로써 성능을 회복한다.
특징 및 결과
- Fine-tuning 방식은 대형 모델이나 복잡한 데이터셋(예: ImageNet)에서 높은 성능을 유지하는 데 유리하다.
- 이미 사전 학습된 모델이 데이터에서 학습된 유용한 패턴을 보유하므로, 프루닝 후 빠르고 안정적인 성능 회복이 가능하다.
- 재학습 과정에 추가 비용과 시간이 소요된다.
Weight Rewinding (절충안)
정의
- 프루닝 후 완전히 무작위로 초기화하는 대신, 초기 학습 시점의 특정 가중치(시드)를 다시 불러와서 재학습하는 방법이다.
특징 및 결과
- 초기 학습 단계에서의 정보를 부분적으로 보존한다.
- Fine-tuning 방식보다 높은 성능을 달성할 수 있는 경우가 있으며, 최신 연구에서는 이 기법으로 최종 정확도를 개선한다고 보고한다
실험 결과 및 종합 비교
-
여러 모델(예: ResNet-152, DeiT-Tiny)과 데이터셋(CIFAR-100, ImageNet)에서 실험한 결과, Fine-tuning 방식이 Training from Scratch 방식보다 대체로 높은 정확도를 보인다.
-
모델의 크기, 데이터셋의 복잡성, 프루닝 기법 등에 따라 상황이 달라진다.
- 작은 모델이나 특정 상황에서는 Training from Scratch이 유리할 수 있다.
- 대형 모델 및 복잡한 데이터셋에서는 Fine-tuning 방식이 우세한 결과를 나타낸다.
-
종합 비교 표는 다음과 같다.
| 항목 | Training from Scratch | Fine-tuning | Weight Rewinding |
|---|---|---|---|
| 정의 | 무작위 초기화 후 완전 재학습한다 | 사전 학습된 가중치로 재조정한다 | 초기 학습 시점의 가중치를 불러와 재학습한다 |
| 장점 | 일부 연구에서 사전 학습과 유사한 성능을 낸다 | 대형 모델/복잡 데이터셋에서 성능 회복에 유리하다 | 초기 정보를 보존하여 성능 개선 가능하다 |
| 단점 | 특정 상황에서는 성능 저하가 발생할 수 있다 | 재학습 비용과 시간이 추가로 소요된다 | 구현 및 관리가 다소 복잡할 수 있다 |
결론
- 프루닝 후 성능 회복 방법은 모델 아키텍처, 데이터셋의 크기 및 특성, 그리고 프루닝 기법에 따라 달라진다.
- 대형 모델 및 복잡한 데이터셋에서는 Fine-tuning 방식이 일반적으로 우세하다.
- Weight Rewinding과 같은 절충 기법은 두 방식의 장점을 조합하여 최적의 성능을 얻을 수 있도록 한다.
- 최종 선택은 실험과 검증을 통해 결정한다.
7.7 Original Task vs. Transfer Pruning
- 전이 학습(Transfer Learning)은 기존에 학습된 모델을 재사용하여 새로운 작업에서 빠르게 학습하고 높은 성능을 달성한다.
- 프루닝된 모델을 전이 학습에 활용하거나, 프루닝 과정을 전이 시점에 맞추어 조정하는 것을 Transfer Pruning이라 한다.
- 본 내용은 원래 작업(Original Task) 기준으로 프루닝할 것인지, 아니면 전이 작업(Target Task)에 맞춰 프루닝할 것인지를 비교한다.
Transfer Pruning의 개념
- Transfer Pruning은 원래 작업에서 모델을 프루닝하여 서브네트워크를 찾은 후, 이를 새로운 작업에 전이한다.
- 두 가지 주요 유형으로 구분한다.
- Task Transfer Pruning
원래 데이터셋에서 프루닝한 서브네트워크를 새로운 데이터셋이나 과제에 전이한다. - Architecture Transfer Pruning
한 네트워크(예: ResNet-9)에서 찾은 프루닝 티켓(서브네트워크)을 동일 계열의 다른 모델(예: ResNet-50, ResNet-18)로 전이한다.
- Task Transfer Pruning
Task Transfer Pruning
- 원래 데이터셋에서 학습한 모델을 프루닝하여 서브네트워크를 도출한 후, 이를 다른 데이터셋(새 과제)에 전이한다.
- 연구에서는 원래 작업에서 높은 정확도를 달성한 서브네트워크라도, 전이 시에 성능 차이가 발생할 수 있음을 보고한다.
- 예를 들어, ImageNet이나 Places365에서 높은 정확도를 보이는 서브네트워크가 CIFAR-10 또는 CIFAR-100와 같은 작은 데이터셋에 전이되었을 때 성능 변화가 나타난다.
- LLM(대규모 언어 모델) 분야에서는 프루닝된 모델을 다운스트림 과제에 직접 맞춰 프루닝할 때 성능이 더 크게 향상된다고 보고한다.
Architecture Transfer Pruning
- 한 네트워크 아키텍처에서 찾은 서브네트워크를 동일 계열이지만 다른 구조(깊거나 얕은 모델)로 전이한다.
- 이를 통해 작은 네트워크에서 빠르게 찾은 프루닝 티켓(Winning Ticket)을 더 복잡한 모델로 손쉽게 옮길 수 있다.
- 예를 들어, ETTs(Elastic Ticket Transformations) 기법은 작은 네트워크에서 발견한 티켓을 더 큰 네트워크로 매핑한다.
- 이 방법은 전체 모델 학습 비용을 줄이고, 전이 시 자원 소모를 절감한다.
작은 모델에서 프루닝을 통해 효율적인 서브네트워크를 빠르게 탐색한다.
찾아낸 서브네트워크를 더 크거나 다른 크기의 네트워크로 전이하여, 전반적인 모델 학습과 압축 비용을 절감
핵심 요약
-
Transfer Pruning의 목적
- 프루닝된 서브네트워크를 재활용하여 새로운 작업에서도 빠른 학습과 높은 성능을 달성한다.
-
Task Transfer Pruning
- 원래 데이터셋에서 프루닝한 서브네트워크를 새로운 작업으로 전이한다.
- 데이터셋 크기, 클래스 수 등의 차이에 따라 전이 성능에 영향을 미친다.
-
Architecture Transfer Pruning
- 한 아키텍처에서 찾은 프루닝 티켓을 다른 아키텍처로 전이한다.
- 네트워크의 구조적 확장성을 고려하여 티켓 매핑 방법을 고안한다.
-
주의사항
- 원래 작업에서 얻은 높은 성능이 전이 시에도 그대로 유지된다고 보장하지 않는다.
- 특히 LLM과 같은 대규모 모델에서는 전이 대상 작업에 맞추어 프루닝하는 것이 성능 향상에 결정적 역할을 할 수 있다.
- 아키텍처 전이 시, 단순히 레이어 개수나 깊이만 달라지면 가중치 및 구조 매핑 방법을 세심하게 고려해야 한다.
결론
- Transfer Pruning은 프루닝된 서브네트워크를 새로운 작업이나 다른 아키텍처에 전이함으로써 학습 비용을 절감하고 빠른 전이를 가능하게 한다.
- 원래 작업(Original Task) 기준 프루닝과 전이 학습 대상(Transfer Task)에 맞춘 프루닝 간에는 성능 차이가 발생할 수 있으며, 특히 LLM에서는 새로운 과제에 맞추어 프루닝하는 것이 유리하다.
- 전이 프루닝 기법은 기존 연구들을 토대로 계속해서 개선되고 있으며, 다양한 모델 및 데이터셋에 대해 최적의 방법을 실험적으로 검증한다.
7.8 Static vs. Dynamic Pruning
- Static Pruning은 학습 전, 중 또는 후에 한 번(또는 반복적으로) 중요도가 낮은 가중치나 채널 등을 제거하여 모델의 최종 구조를 고정한다.
- Dynamic Pruning은 런타임(실행 시점)에서 입력 데이터의 특성에 따라 계산 경로를 동적으로 선택하여, 불필요한 연산을 건너뛴다.
Static Pruning
정의
- Static Pruning은 모델을 학습하기 전, 중 또는 후에 프루닝을 수행하여, 제거된 부분은 복원하지 않고 고정된 경량 모델을 생성한다.
특징
- 프루닝 시 결정된 마스크(제거 여부)가 고정된다.
- 최종 모델 구조가 경량화되어 배포 및 추론 단계에서 그대로 사용된다.
- 필요에 따라 프루닝 후 재학습(예, fine-tuning)을 진행한다.
장단점
-
장점:
- 모델 구조를 간소화하며, 배포가 용이하다.
- 최종 추론 시 추가적인 동적 연산 없이 고정된 모델을 사용할 수 있다.
-
단점:
- 한 번 결정된 프루닝 결과를 변경할 수 없으므로, 입력에 따른 유연성이 부족하다.
- 프루닝 후 재학습을 통해 성능 회복이 필요하다.
Dynamic Pruning
정의
- Dynamic Pruning은 런타임에서 입력 데이터나 중간 피처의 특성을 기반으로, 매번 중요도가 낮은 부분은 계산하지 않고 건너뛴다.
특징
- 모델 파라미터는 모두 유지하되, 필요 없는 경로는 실행 시 동적으로 비활성화한다.
- 입력마다 계산해야 할 경로가 달라진다.
- 사전에 결정된 고정된 프루닝 마스크가 없으므로, 재학습 없이도 입력별로 유연하게 작동한다.
- 동적 프루닝은 네트워크 내의 일부 가중치나 채널을 영구적으로 제거하는 것이 아니라, 실행 시점에 선택적으로 비활성화하거나 계산에서 건너뛴다
- 즉, 프루닝을 적용해도 네트워크의 아키텍처(레이어 구성, 연결 구조 등)는 그대로 유지된다
장단점
-
장점:
- 입력별로 세밀하게 연산량을 조절할 수 있다.
- 모델 구조를 변경하지 않고도 동적으로 계산 비용을 줄일 수 있다.
-
단점:
- 런타임에서 추가적인 제어 로직이 필요하다.
- 하드웨어 최적화 및 구현이 다소 복잡할 수 있다.
종합 비교
| 항목 | Static Pruning | Dynamic Pruning |
|---|---|---|
| 프루닝 시점 | 학습 전/중/후에 한 번 고정된 프루닝을 수행한다. | 런타임에서 입력에 따라 동적으로 프루닝한다. |
| 모델 구조 | 최종 모델 구조가 경량화되어 고정된다. | 모델 구조는 그대로 유지하면서 계산 경로만 동적으로 선택된다. |
| 재학습 여부 | 필요 시 프루닝 후 재학습(fine-tuning)을 진행한다. | 일반적으로 런타임 제어만 수행하며 재학습 과정은 없다. |
| 장점 | 모델 경량화 및 배포가 용이하다. | 입력 특성에 따른 유연한 계산량 조절이 가능하다. |
| 단점 | 입력에 따른 유연성이 부족하다. | 추가 로직 구현 및 하드웨어 최적화가 어려울 수 있다. |
결론
- Static Pruning은 프루닝 후 고정된 경량 모델을 생성하여 배포나 추론 환경에서 효율적으로 활용한다.
- Dynamic Pruning은 런타임에서 입력에 따라 동적으로 불필요한 연산을 건너뛰어, 같은 모델 구조 내에서 계산 비용을 줄인다.
- 적용 환경과 요구 사항에 따라 두 방식 중 적절한 방법을 선택하거나, 필요에 따라 혼합하여 활용한다.
7.9 Layer-wise Weight Density Analysis
- 레이어별 가중치 밀도는 각 레이어가 모델 전체 가중치 중 어느 정도의 비율을 유지하는지를 나타낸다.
- 연구에서는 프루닝 후 각 레이어마다 서로 다른 가중치 밀도가 남게 된다고 보고한다.
- 이는 전체 프루닝 비율과는 별개로, 모델의 구조와 프루닝 기법 간의 상호 작용으로 발생한다.
레이어별 가중치 밀도 차이가 발생하는 원인
- 구조적 특성과 프루닝 기법의 상호 작용
- 네트워크의 각 레이어는 고유한 역할과 기능을 수행한다.
- 프루닝 기법에 따라, 어떤 레이어는 가중치가 많이 남고, 어떤 레이어는 많이 제거된다.
- Ambient 레이어 vs. Critical 레이어
- Ambient 레이어는 가중치 변경에 상대적으로 민감도가 낮아, 프루닝을 진행해도 성능에 큰 영향을 주지 않는다.
- Critical 레이어는 아주 소량의 가중치 손실에도 전체 성능에 큰 영향을 주므로, 프루닝 비율을 낮게 유지한다.
- 초기화 기반 프루닝의 경우
- 초기 무작위 가중치 분포로 인해, 레이어별로 남는 가중치 밀도가 일정하지 않게 나타난다.
- 이로 인해 레이어마다 가중치 밀도의 비균일성이 발생한다.
프루닝 전략에 따른 접근 방식
- Non-uniform (비균일) 프루닝
- 각 레이어의 중요도와 역할을 고려하여 서로 다른 프루닝 비율을 적용한다.
- 중요한 레이어에는 낮은 프루닝 비율을 적용하고, 덜 중요한 레이어에는 높은 프루닝 비율을 적용한다.
- Uniform (균일) 프루닝
- 모든 레이어에 동일한 프루닝 비율을 적용한다.
- 구현은 단순하지만, 레이어별 중요도 차이를 반영하지 못한다.
- 연구에서는 비균일 프루닝 방식을 통해 모델 성능을 극대화할 수 있음을 보고한다.
실제 적용 사례
- CNN의 경우
- 초기 레이어는 특징을 넓게 추출하는 역할을 하며, 이후 레이어는 추출한 특징을 종합하여 분류를 수행한다.
- 이러한 구조적 특성에 따라, 각 레이어에서 최적의 가중치 밀도는 달라진다.
- Vision Transformer(ViT) 및 대규모 언어 모델(LLMs) 경우
- 각 레이어의 역할과 스케일 차이가 크므로, 프루닝 기법을 적용할 때 레이어별로 다른 비율을 적용하는 것이 효과적이다.
- 연구에서는 단순한 Uniform 프루닝보다, Non-uniform 프루닝이 성능을 개선한다고 보고한다.
결론
- 레이어별 가중치 밀도는 프루닝 기법과 모델 구조에 따라 비균일하게 나타난다.
- Critical 레이어와 Ambient 레이어의 특성을 고려하여, 레이어별로 최적의 프루닝 비율을 설정해야 한다.
- 비균일 프루닝 전략을 사용하면, 전체 모델 성능을 더욱 효율적으로 유지할 수 있다.
- 이러한 분석은 다양한 모델(CNN, ViT, LLM 등)에서 프루닝 기법을 적용할 때 중요한 참고 자료가 된다.
7.10 Pruning with Different Levels of Supervision
- 신경망 프루닝은 학습 과정에서 사용하는 감독(supervision) 수준에 따라 여러 방식으로 진행된다.
- 프루닝은 다음 네 가지 감독 수준으로 구분한다.
- Supervised Pruning을 수행한다.
- Semi-supervised Pruning을 수행한다.
- Self-supervised Pruning을 수행한다.
- Unsupervised Pruning을 수행한다.
- 일반적으로 Supervised Pruning이 가장 많이 사용되지만, 대규모 데이터셋에서는 라벨 비용 문제로 한계가 발생한다.
Supervised Pruning
- 모든 데이터에 라벨이 존재하는 상황에서 학습 후 프루닝을 수행한다.
- 라벨 정보를 이용하여 가중치의 중요도를 평가하고, 낮은 중요도의 가중치를 제거한다.
- 이 방식은 정확하고 풍부한 라벨 정보가 필요하다.
- 다만, 라벨링 비용이 크며 대규모 데이터셋에서는 확장성이 떨어진다.
Semi-supervised Pruning
- 일부 데이터에만 라벨이 존재하는 상황에서 프루닝을 수행한다.
- 라벨이 있는 데이터에서 얻은 정보를 다른 비라벨 데이터에 확장하여 학습한다.
- 라벨 전부를 요구하지 않으므로 라벨링 비용을 절감할 수 있다.
- Semi-supervised 학습 기법과 함께 적용하여 프루닝 성능을 보완한다.
Self-supervised Pruning
- 라벨이 없는 데이터에서 자체적인 학습 목표를 설정하여 모델을 학습한 후 프루닝을 수행한다.
- 대조 학습(contrastive learning)이나 생성 모델(generative learning) 등으로 학습한 후, 해당 모델을 프루닝한다.
- 라벨이 전혀 필요하지 않으므로 대규모 무라벨 데이터에 대해 효과적으로 확장할 수 있다.
- 다만, Self-supervision으로 학습된 모델은 Supervised 방식만큼의 성능 향상을 보장하지 않을 수 있다.
Unsupervised Pruning
- 라벨 정보 없이 데이터의 구조나 분포를 기반으로 모델을 학습하고 프루닝한다.
- 라벨이 없으므로 추가적인 라벨링 비용이 발생하지 않는다.
- Unsupervised Pruning은 모델의 성능을 유지하기 어렵다는 한계가 있으며, 원래 모델의 정확도를 그대로 유지하는 데 어려움을 겪는다.
추가 사례 및 논의
- 프루닝 라운드마다 다른 감독 방식을 사용할 수 있다.
- Self-supervised 또는 Semi-supervised 방식과 Supervised Pruning을 결합하여 성능을 향상시키는 연구가 진행된다.
- 예를 들어, ImageNet에서 IMP(Iterative Magnitude Pruning)를 적용하면서 자기지도 학습 기법(CLR, MoCo 등)을 같이 사용하는 연구가 있다.
- 일부 연구에서는 자가 지도 방식의 프루닝 모델을 음성 인식 등 다른 영역에 전이하여 프루닝 효과를 분석한다.
결론
- Supervised Pruning이 가장 일반적으로 사용되나, 대규모 데이터셋에서는 라벨 비용 문제로 어려움을 겪는다.
- Semi-supervised, Self-supervised, Unsupervised Pruning을 통해 라벨 의존성을 줄이려는 노력을 한다.
- 실제 적용에서는 데이터의 라벨 상태와 비용, 모델 특성 등을 고려하여 적절한 감독 수준의 프루닝 방식을 선택한다.
- 다양한 감독 수준의 프루닝 기법을 혼합하여 최적의 성능과 비용 효율을 달성한다.
8 FUSION OF PRUNING AND OTHER COMPRESSION TECHNIQUES
- 여러 신경망 압축 기법들이 상호보완적으로 작동한다.
- 프루닝과 함께 양자화, 텐서 분해, 지식 증류, 네트워크 아키텍처 검색(NAS) 등을 결합하여
모델 크기를 크게 줄이고 연산 효율을 극대화한다. - 이러한 융합 기법을 통해 단일 기법만 사용할 때보다 더 높은 압축률과 성능을 달성한다.
프루닝 & 양자화 (Quantization)
- 양자화는 모델의 가중치와 활성화 값을 표현하는 비트 수를 줄인다.
- 프루닝 후 남은 가중치를 낮은 비트 수로 표현하여 모델 크기와 메모리 사용량을 줄인다.
- 예를 들어, Han 등은 먼저 프루닝을 수행한 후 가중치를 양자화하여 모델 압축과 가속화를 동시에 달성한다.
- 일부 접근은 파인튜닝 단계에서 프루닝과 양자화를 함께 수행한다.
프루닝 & 텐서 분해 (Tensor Decomposition)
-
텐서 분해는 합성곱 연산 등을 저랭크 텐서나 행렬로 분해하여 파라미터 수를 줄인다.
합성곱 계층의 가중치는 보통 4차원 텐서로 구성된다.
4차원 텐서는 많은 파라미터를 포함하므로, 직접 사용하면 모델의 크기와 연산 비용이 매우 크다. -
프루닝과는 달리, 텐서 분해는 모델의 내부 구조를 재구성한다.
원래 4차원 텐서를 두 개 또는 세 개의 작은 행렬 곱으로 대체하며 분해된 저랭크 텐서나 행렬은 원래의 텐서를 근사하도록 구성한다.
-
두 기법을 결합하면, 불필요한 가중치를 제거하는 프루닝과 저랭크 구조 활용을 통해 압축 효과를 극대화한다.
원래 4차원 텐서를 두 개 또는 세 개의 작은 행렬 곱으로 대체하여, 메모리 사용량과 계산량을 절감
-
예를 들어, 일부 연구는 필터 프루닝과 텐서 분해를 동시에 적용하여, CNN 모델의 효율성을 높인다.
프루닝 & 지식 증류 (Knowledge Distillation)
- 지식 증류는 크고 성능이 우수한 Teacher 모델의 지식을 더 작은 Student 모델로 전수한다.
- 프루닝을 단독으로 사용하면 모델 성능이 떨어질 수 있는데,
KD를 함께 사용함으로써 프루닝으로 인한 성능 손실을 보완하고 Student 모델이 Teacher의 지식을 흡수하도록 한다. - 특히, Transformer나 BERT와 같은 모델에서 프루닝과 KD를 함께 적용하면 성능 회복에 큰 도움이 된다.
프루닝 & 복합 압축 기법 (Multi-compression Techniques)
- 일부 연구에서는 프루닝, 양자화, 지식 증류 등의 여러 기법을 동시에 결합한다.
- 복합 압축 기법은 단일 기법만 사용할 때보다 더 높은 압축률과 효율성을 달성한다.
- 예를 들어, GAN 압축을 위해 프루닝, 양자화, KD를 동시에 적용하거나, 이미지 변환 작업에 프루닝, NAS, KD를 결합하는 연구들이 있다.
- 이와 같이, 서로 다른 압축 기법 간의 상호보완적 특성을 활용하여 최적의 압축 성능을 도모한다.
결론
- 프루닝과 다른 압축 기법의 융합은 모델 압축률과 연산 효율성을 크게 향상시킨다.
- 각 기법은 서로 상호보완적인 역할을 하므로, 단일 기법보다 결합했을 때 보다 뛰어난 성능을 발휘한다.
- 실제 적용 시에는 모델 구조, 대상 작업, 하드웨어 제약 등을 고려하여 적절한 압축 기법들을 혼합하여 최적의 결과를 얻는다.
9 SUGGESTIONS AND FUTURE DIRECTIONS
- 프루닝 기법은 여러 가지 방법이 존재한다.
- 특정 기법이 항상 최고라고 단정할 수 없으며, 응용 환경과 하드웨어/소프트웨어 리소스, 모델의 특성에 따라 적합한 방법을 선택한다.
- 다양한 상황에서 프루닝 기법을 선택할 때 참고할 만한 지침을 제공한다.
하드웨어 및 소프트웨어 지원이 부족한 경우
- 권장 사항:
- 특수 하드웨어(예: FPGA, ASIC)가 없고, 스파스 연산을 지원하는 라이브러리가 없는 경우에는 구조적 프루닝을 사용한다.
- 설명:
- 비구조적 프루닝은 스파스 행렬 연산을 위한 전용 라이브러리나 하드웨어 지원이 필요하다.
- 구조적 프루닝은 필터나 채널 단위로 제거하여, 일반 하드웨어에서 효율적으로 가속할 수 있다.
계산 자원이 충분한 경우와 PAT 방식 고려
- 권장 사항:
- 프루닝 단계에서 계산 자원이 충분하다면, 반복적인 Pruning After Training (PAT) 방식을 사용한다.
- 설명:
- PAT 방식은 여러 번의 프루닝-재학습 과정을 거쳐 성능 저하를 점진적으로 줄인다.
- 반면 계산 자원이 제한적이라면, 원-샷(One-shot) 방식의 Pruning Before Training (PBT)이나 프루닝 후 즉시 추론 단계에 적용할 수 있는 기법을 선택한다.
- 예시:
- 대형 언어 모델(LLM)에도 원-샷 방식의 프루닝 기법이 적합할 수 있다.
감독 학습(supervised)이 가능한 경우
- 권장 사항:
- 성능 목표가 명확한 작업이라면, 라벨이 풍부한 데이터셋을 이용한 감독 학습 기반 프루닝을 사용한다.
- 설명:
- 감독 학습 방식은 정확한 라벨 정보를 활용하여 가중치 중요도를 평가하고 프루닝하므로, 해당 작업의 성능 회복에 유리하다.
- 반면, 라벨이 없는 도메인이나 초기화 단계에서는 자기지도(self-supervised) 또는 Data-free 방식이 더 적합할 수 있다.
메모리 사용량 최적화
- 권장 사항:
- 프루닝 과정에서 메모리 사용량을 최소화하려면, 입력 배치 크기나 입력 형태(shape)를 신중하게 설정한다.
- 설명:
- 입력 크기나 형태가 변경되면, 실제 연산과 메모리 사용량에 큰 영향을 줄 수 있다.
- 작업에 따라 최적의 입력 환경을 구성하여, 프루닝된 모델의 성능 및 효율성을 향상시킨다.
네트워크 축소 방향 고려
- 권장 사항:
- 네트워크를 여러 차원(깊이, 너비 등)에서 축소해야 할 경우, 레이어별 프루닝, 채널 프루닝 등 다양한 기법을 종합적으로 고려한다.
- 설명:
- 단순히 전체 파라미터 수만 줄이는 것이 아니라, 레이어별, 채널별 분포 및 중요도를 고려하여 프루닝을 수행한다.
- 양자화나 지식 증류와 같은 추가 압축 기법을 병행하면, 전체 모델 크기와 메모리 사용량을 더욱 줄일 수 있다.
속도와 정확도 균형 맞추기
- 권장 사항:
- 속도와 정확도 사이의 균형을 원한다면, 사전 학습된 모델을 사용하고 프루닝 후 파인튜닝을 여러 에폭 동안 진행한다.
- 설명:
- 프루닝된 모델을 충분히 재학습(파인튜닝)하면, 원래 모델의 성능을 최대한 회복할 수 있다.
- 또한, 지식 증류(KD), 네트워크 아키텍처 검색(NAS) 등 다른 기법과 결합하여 최적의 정확도와 속도 향상을 동시에 달성한다.
메모리 제약 상황 대응
- 권장 사항:
- 전체 프루닝 또는 추론 단계에서 dense 형태의 모델을 저장할 메모리가 부족할 경우, 중간 레이어나 부분 연산에서 계산 및 메모리 사용량을 줄인다.
- 설명:
- 입력 크기를 조절하거나, 프루닝된 모델의 특정 부분에서 압축 기법을 사용하여 전체 메모리 사용량을 최적화한다.
잔차 연결과 학습률 조절
- 권장 사항:
- 서브네트워크가 잔차 연결을 포함하는 경우, 낮은 학습률로도 높은 정확도를 달성할 수 있다.
- 잔차 연결이 없는 네트워크인 경우, 더 높은 학습률 또는 긴 학습 에폭이 필요하다.
- 설명:
- Ma 등은 잔차 연결이 있는 서브네트워크가 상대적으로 작은 학습률에서도 좋은 성능을 낼 수 있음을 보고한다.
대규모 사전 학습과 FLOPs 최적화
- 권장 사항:
- 대규모 사전 학습의 효과를 극대화하려면, 모델의 핵심 파라미터보다 실제 연산량(FLOPs)을 최소화하는 데 집중한다.
- 설명:
- 동적 스파스 접근법 등을 통해 적은 FLOPs로 모델 용량을 유지하고, 사전 학습이나 추론 시 연산량을 줄여 전체 성능을 높일 수 있다.
결론
- 프루닝 기법 선택은 응용 환경과 모델 특성, 데이터 라벨링 상태, 하드웨어 자원 등을 종합적으로 고려하여 결정한다.
- 여러 추천 사항들은 프루닝 과정 및 후속 학습(파인튜닝)에서 성능과 효율성을 극대화하기 위한 방향을 제시한다.
- 실제 환경에서는 위의 권장 사항들을 바탕으로 다양한 기법들을 조합하거나 혼합하여 최적의 결과를 달성한다.
