
중고 수입차 가격 예측 프로젝트 입니다.
수입 중고차 가격 예측 프로젝트(1)에 이은 발표 PPT 및 설명입니다.
발표 및 PPT

안녕하십니까. 중고 수입차 가격 예측이라는 주제로 이번 머신러닝 프로젝트를 진행한 1조 첫번째 발표를 맡게 된 임정민입니다. 반갑습니다. (인사)
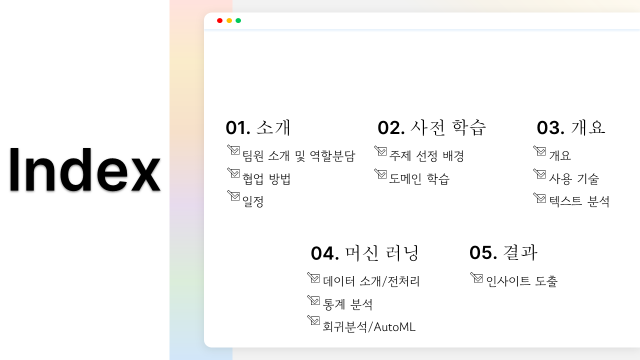
발표 목차입니다. 보이시는 순서대로 팀원 소개, 사전학습, 개요, 머신 러닝 개발 과정, 결과 순으로 말씀드리겠습니다.
먼저 소개입니다.
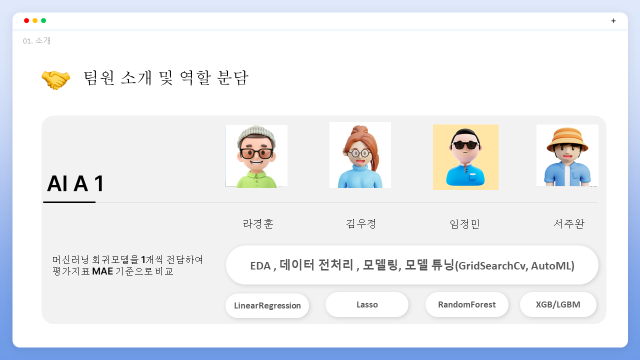
저희 1조는 라경훈님, 김우정님, 임정민님, 서주완님 총 4명으로 이루어진 팀입니다. 역할 분담은 특정 역할을 할당하는 것보다는 팀원들 의견 중 머신러닝 프로세스를 전체를 한번 경험하는 것을 원하는 팀원이 있어서 EDA , 데이터 전처리, 모델링, 모델 튜닝까지 개별적으로 진행하고 회귀모델을 1개씩 전담하였습니다.
보이시는 것처럼 경훈님은 LinearRegression, 우정님은 Lasso, 정민님은 RandomForest, 주완님은 XGBoost/LightGBM 로 진행했습니다.이후 평가지표 MAE 기준으로 결과를 비교하는 방식을 진행했습니다.
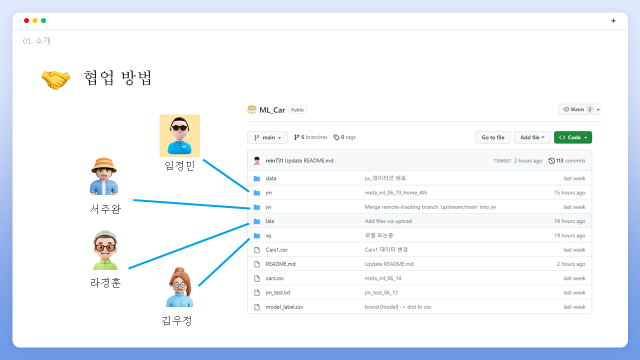
협업 방식은 Github 팀 레포지토리에 개별 브런치를 생성하여 수행하였고 프로젝트 진행 도중 다른 팀원의 개발코드가 필요할 때마다 main브런치에 merge하여 공유하였습니다.

전체 일정입니다. 프로젝트 중간에 팀원 스케줄 사정 상 예비군이나 면접, 박람회 견학 등의 이슈들이 있었지만 서로 믿고 잘 따라준 덕분에 계획한대로 진행된 편이였습니다.

다음으로 ‘사전학습’, 주제 선정 배경이나 중고차 시장에 대한 도메인 지식을 학습한 과정입니다.
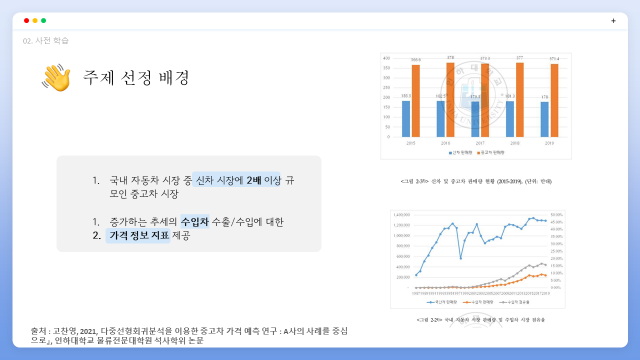
주제 선정 배경은 크게 두가지 근거하여 설정하였습니다.
첫번째로 국내 자동차 시장안에서 중고차 시장(주황색)은 판매량 기준 신차 시장(파란색)에 2배 이상에 해당하는 규모로 형성되어 있습니다. 우측 상단에 보이시는 그래프가 ‘다중선형회귀분석을 이용한 중고차 가격 예측 연구’ 논문에 기재된 연도별 신차 판매량/중고차 판매량 지표인데 파란색,신차판매량 대비 주황색,중고차판매량 건수가 2배 이상에 해당하고 있습니다.
두번째로 국내 자동차 시장에서 수입차(외제차)의 보편화로 인해 외제차의 비율이 점점 증가하는 추세라고 합니다. 우측 하단에 그래프가 동일 논문에 기재된 자료이고 회색 꺾은선이 증가하는 추세의 수입차 점유율에 대한 지표입니다.
이 두가지 요소에 기반하여 활성화되고 있는 중고차 시장에서 수입차를 구매 혹은 판매하는 사람들에게 가격정보의 지표를 제공하여 거래의 이해관계를 높히고자 중고 수입차 가격 예측 이라는 주제를 선정하게 되었습니다.
중고차라는 대상에 대한 이해를 높히기 위해 도메인 학습을 진행하였습니다. 중고 수입차를 국내 시장에서 거래 할 것인지 해외 시장에 수출,수입할 것인지에 따라 그 요소가 다를 것이라고 판단하여 국내 중고차 시장/ 해외 중고차을 구분지어 가격 영향 요인을 분석하였습니다.

먼저 국내 중고차 시장 기준으로 가격 영향 요인입니다. 참고한 논문에서 저희 주제와 유사하게 선형회귀분석을 통해 주요 피처들을 도출해내었습니다. 이때 학습한 데이터는 주행거리,연식,배기량, 최대출력,변속기,보험처리여부 등이 있었습니다.
결론만 보자면 국내 중고차 시장 기준으로 연식,주행거리,배기량,마력 순으로 가격에 영향을 미친다는 결론을 얻을 수 있었습니다. 이는 일반적으로 생각할 때 중고차를 구매하는 기준 연식이 얼마나 오래되었는지, 몇km나 탔는지 등이 자료로써 증명되었다고볼 수 있습니다.
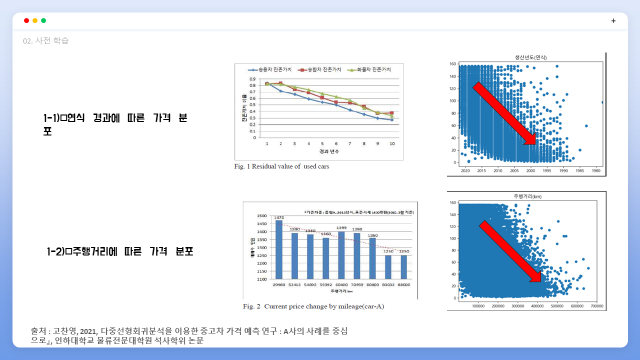
선형회귀모델 결과와 같이 논문에서 조사한 내용에 따르면 연식이 증가함에 따라 잔존가치(가격)이 떨어지는 경향을 볼 수 있고 이후 소개드릴 저희 데이터셋에도 이와 같은 경향을 띄었습니다.
주행거리도 미찬가지로 주행거리가 늘어남에 따라 가격이 낮아지는 경향을 띄었습니다.

해외 중고차 시장 가격 영향 요인 분석입니다. 해외 국가 중, 튀르키예 중고차 시장의 가격을 선형회귀 기법으로 예측한 논문이 있어 참고할 수 있었습니다. 이때 학습한 데이터를 보자면 브랜드, 연식, Gear Type이라고 되어있는 부분은 수동or오토or반오토 여부를 나타내는 변속기 컬럼이고 차체 형식이나 주행거리가 포함된 데이터셋입니다.
결론만 보자면 해외 중고차 가격 영향 주요 요인으로는 브랜드, 주행거리, Gear Type라고 나옵니다. 국내 시장, 해외 시장 분석에서의 공통된 컬럼 기준으로 연식,주행거리는 확실히 가격에 크게 영향을 미치는 요소라고 판단되고 해외 시장에서는 특이하게 국내 시장과 다르게 변속기 작동 방식(수동 or 오토)가 주요한 요소임을 알 수 있었습니다.

프로젝트의 개요에 대하여 설명하겠습니다.
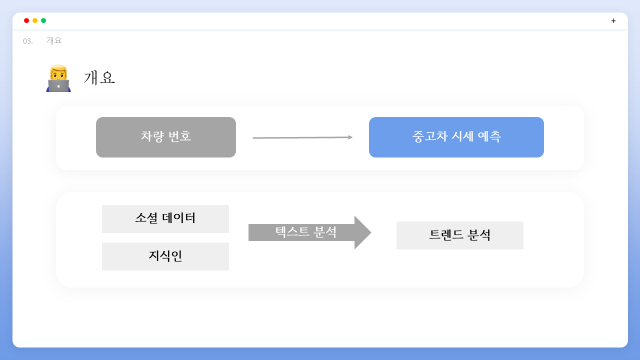
차량 번호를 통해 얻을 수 있는 데이터들을 기반으로 중고차의 시세를 예측하는 서비스에 필요한 모델을 기획하였습니다. 소셜 데이터 분석을 통한 트렌드 분석을 기반으로 중고차 매매와 관련된 외부 요인들에 대해서도 탐색하였습니다.
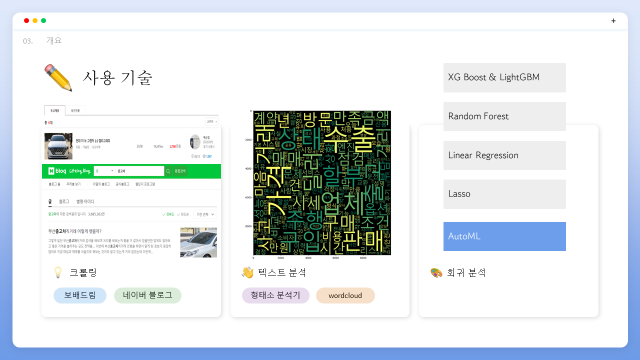
사용한 기술은 크게 크롤링, 텍스트 분석, 회귀 분석입니다. 보배드림과 네이버 블로그를 크롤링하였고, 블로그 텍스트를 분석하여 워드 클라우드로 키워드를 분석하였습니다.다양한 회귀 모델들을 적용, 비교하여 최적의 모델을 선별했습니다.
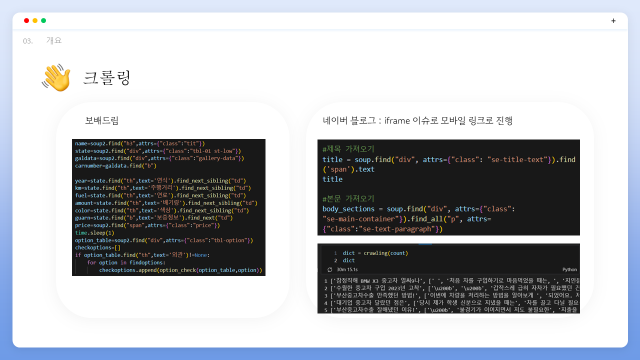
네이버 블로그 크롤링의 경우 iframe 관련 이슈로 모바일 링크로 진행하였습니다.
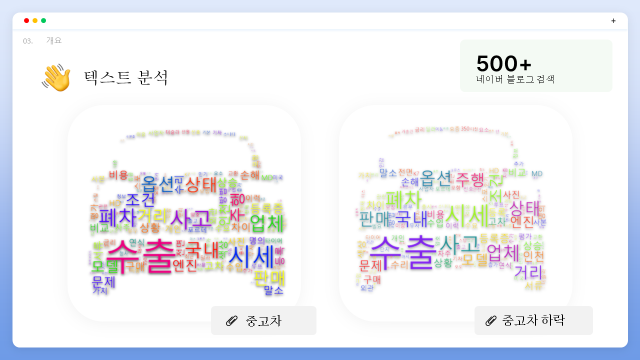
크롤링 데이터는 네이버 블로그 500여개를 검색하여 정확도 순으로 나열한 결과이며, 시간 관계상 ‘중고차’와 ‘중고차 하락’이라는 키워드로 검색하였습니다. 이 후 ‘중고차 감가상각’, ‘중고차 업체’ 등과 관련된 다양한 키워드를 분석해 볼 수 있습니다.
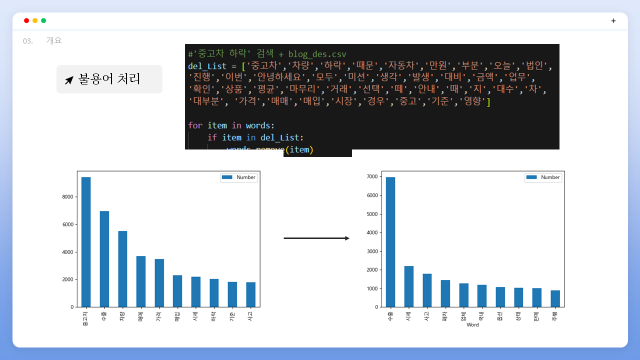
형태소 분석 결과 ‘중고차’ ,’차량’ ,’가격’ 등 검색어와 연관도가 너무 높은 단어들과 트렌드 분석에 불필요한 단어들의 불용어 처리를 진행하였습니다. 그 결과 ‘수출’ 키워드의 빈도수가 가장 높게 나온 것을 확인할 수 있었습니다.
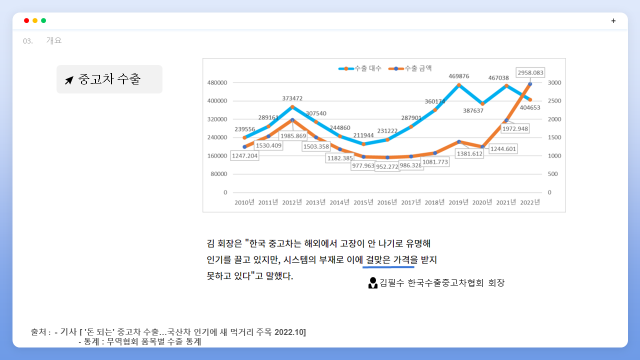
이 결과를 바탕으로 추가 조사를 해본 결과 국내 중고차 시장 규모는 약 380만 대로 신차 규모(약 180만대)의 약 2배로 계속해서 커져가고 있다는 사실을 확인할 수 있었습니다.
또한 해외에서 좋은 성능으로 인정받는 한국 중고차이지만, 시스템의 부재로 인해 알맞은 가격을 받지 못하는 문제 상황을 확인할 수 있었습니다.

머신 러닝 개발 과정입니다.
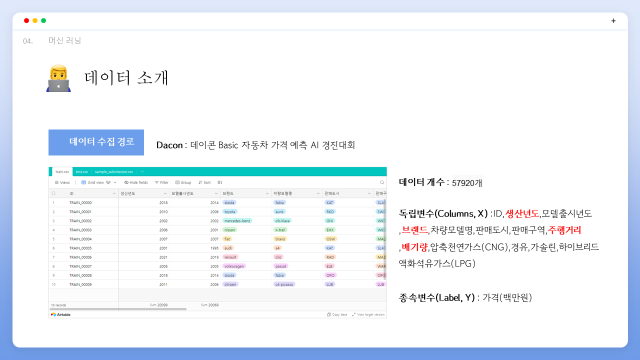
데이터 소개입니다. 데이터는 DACON의 Basic 자동차 가격 예측 AI 경진대회라는 주제의 데이터셋을 활용하였습니다. 약 5만7000개의 갯수이며 앞서 도메인 학습에서 보았던 생산년도,브랜드,주행거리,배기량,연료유형 등의 독립변수를 확인할 수 있었습니다.
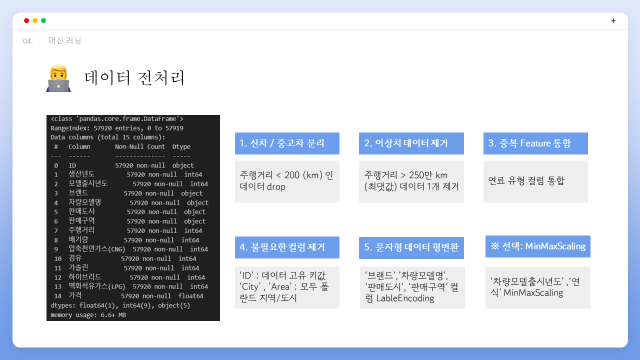
데이터 전처리에 관한 요약입니다. EDA를 통해 얻어낸 인사이트와, 모델이 학습하기 적합한 형태로 전처리하기 위한 과정이였습니다. 다음장에서부터 자세히 설명드리겠습니다.
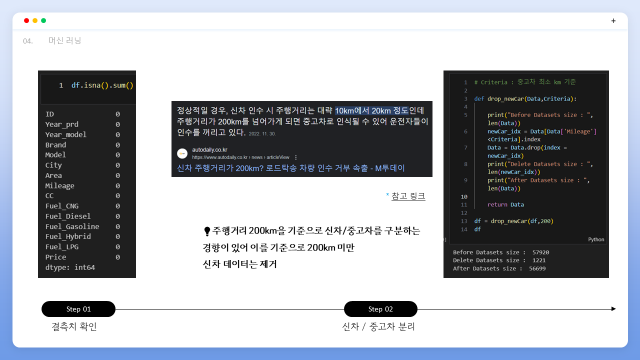
먼저 결측치로 추정되는 값은 없었고 한 자리수의 주행거리가 존재하였습니다. 본 프로젝트는 중고차라는 대상의 가격 예측 프로젝트이기 때문에 참고한 기사를 통해 신차와 중고차를 기준지어 200km미만 주행의 신차 데이터는 제거하였습니다.
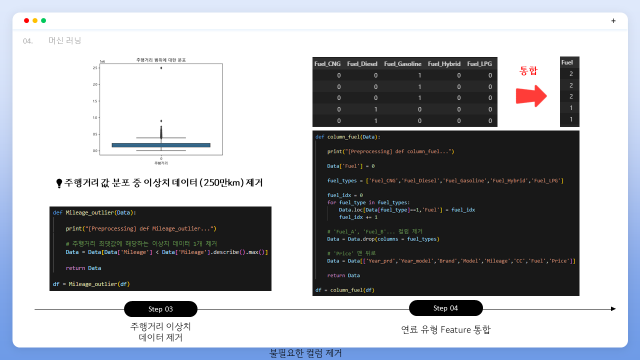
주행거리 분포 박스플롯을 통해 1개의 이상치를 관측하고 제거하였습니다. 또한 원본 데이터에서 의 연료 유형을 뜻하는 컬럼들이 get_dummies화 되어 있어 다중공선성문제를 야기할 가능성이 있기 1개의 컬럼으로 통합하였습니다.
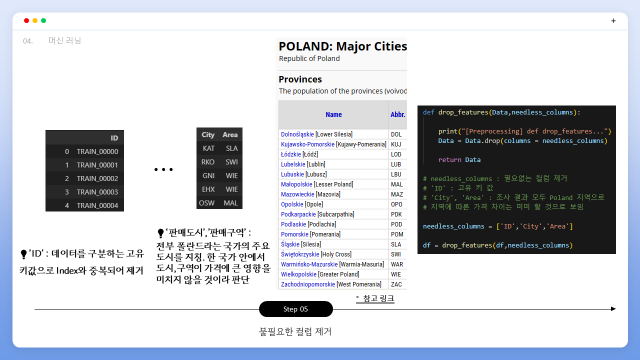
불필요한 컬럼을 추가적으로 제거하였습니다. ‘ID’ 컬럼은 데이터를 구분하는 고유 키값으로 Index과 중복되어 drop하였습니다. ‘판매도시’,’판매구역’ 컬럼 또한 제거하였습니다. 해당 컬럼의 데이터 값들 모두 폴란드에 위치한 도시,지역들로써 한 국가안에서 어느지역에서 판매했느냐에 따라 가격변동이 크지 않을 것이라고 판단하여 제거하였습니다.

이후 ‘브랜드’,’차량모델’ 등의 object형 컬럼을 Label Encoding으로 처리해주었습니다. 마지막으로 ‘연식’,’차량모델출시년도’를 MinMaxScaling 하는 모듈을 구현하기는 했지만 다수 논문 기준으로 대부분 값 그대로 사용하는 경우가 많아 저희 또한 그대로 사용하였습니다.
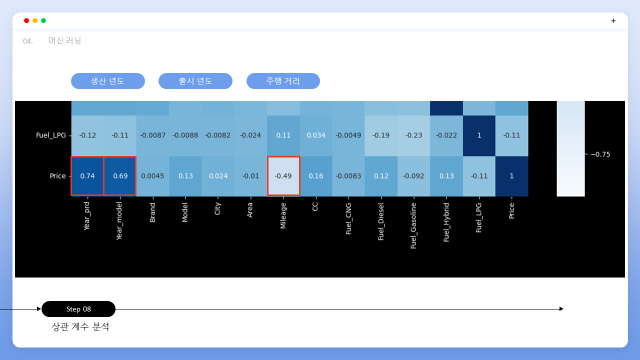
데이터 전처리를 수행하고 상관관계 그래프를 출력해보았습니다. 사전학습했던대로 생산년도와 주행거리가 가격에 대해 가장 높은 상관계수를 갖고 있었습니다.

산점도 분석 그래프입니다.

브랜드별로 가격분포를 박스플롯입니다. 가격 100이 넘어가는 차량들은 대부분 2016년 이후 생산되었습니다. 대부분의 데이터는 생산년도와 상관관계가 높으나, 2016년 이후 특정 데이터들은 상관관계가 적은 것으로 나타나 가지고 있는 독립변수들로는 종속변수의 변화를 설명하기 힘들다고 판단하였습니다. 이후 서칭을 통해 외부의 요인으로 추정되는 것을 찾았고 이는 특정 시기 폴란드의 세금 정책 변화로 인해 중고차 수요가 급상승한 것이 원인으로 추측되었습니다.
추후에 다른 컬럼으로 추가하여 분석할 가치가 있고 주요지표들과 상관계수가 낮아 이상치라고 판명하고 제거했을 때, 랏쏘모델의 MAE가 4 감소하였습니다.
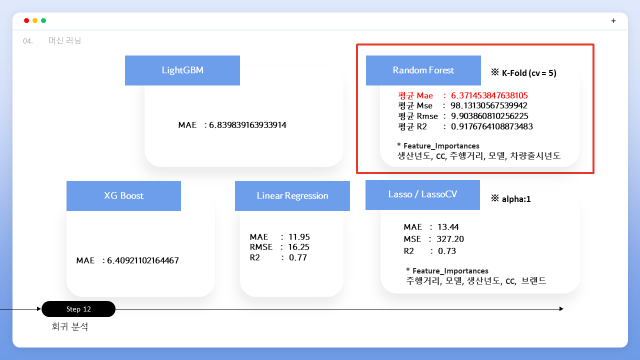
머신러닝 회귀 모델 중 최적의 모델은 MAE 기준 6.37의 RandomForest 였습니다. 해당 지표는 K-Fold 교차 검증 기법에 기반한 값으로 데이터를 여러번 나누어 평가하여 일반화된 성능을 보장하기 위해 교차 검증 방법으로 진행하였습니다. 이때, 가격에 영향을 미치는 가장 주요한 feature로는 생산년도,CC,주행거리,차량모델 등의 순입니다.
앞서 구현한 모델들의 MAE값을 줄이기 위해 AutoML을 사용하였습니다. 활용한 프레임 워크는 Optuna, Auto Gluon, Pycaret 총 3가지의 AutoML을 사용하였습니다.
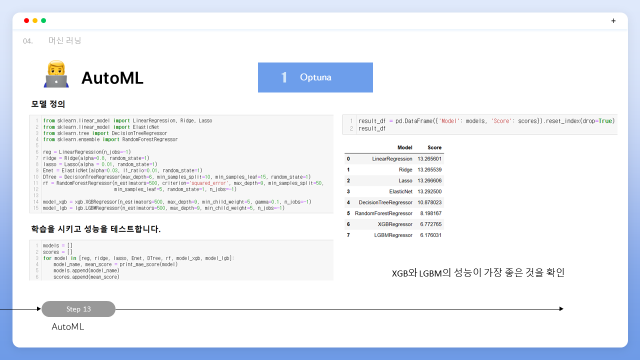
첫번째로 Optuna를 설명드리겠습니다. 활용한 데이터는 앞서 진행된 전처리 및 EDA가 완료된 데이터를 활용하여 진행하였습니다. AutoML을 진행하기 전, MAE값이 가장 적은 모델을 찾아 비교하기 위해 Linear, 릿지, 라쏘, 엘라스틱, 렌덤포레스트, xgb, lgbm 모델을 정의해주고 학습을 진행하였습니다. 그 결과로 xgb와 lgbm의 모델의 성능이 가장 좋은 것을 확인하였고 해당 모델을 기준으로 Optuna를 진행하기로 결정하였습니다.

xgb, lgbm 각각의 모델에 맞게 파라미터를 조정해준 뒤 optuna를 이용해 MAE가 가장 낮게 나오는 파라미터를 찾아 파라미터를 저장해주는 함수를 구현하였습니다. xgb 같은 경우에는 두번의 파라미터 조정을 통해 더 나은 결과값을 도출하였고 LGBM의 경우엔 XGB보다 높은 MAE의 결과를 도출하여 한번의 파라미터 조정을 진행하였습니다.
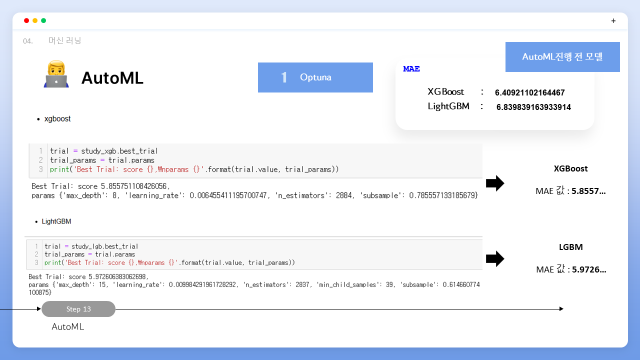
xgb의 경우 best Trial의 값이 5.885..로 기존 모델의 6.409..의 MAE값에 비해 좋은 결과를 도출한 것을 확인하였으며, lgbm의 경우 best trial의 값이 5.9726 으로 기존 모델의 6.839..의 MAE값에 비해 마찬가지로 더 나은 결과를 도출한 것을 확인할 수 있었습니다.
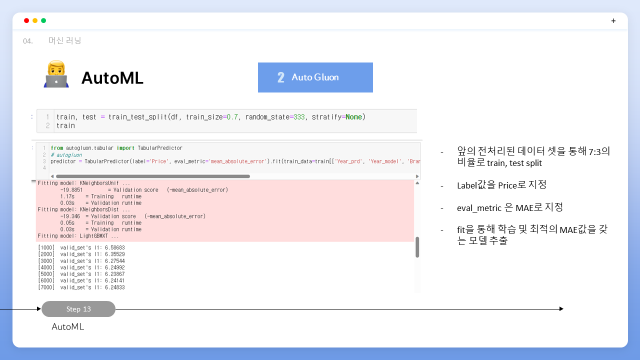
다음으로 Auto Gluon을 설명드리겠습니다. Auto Gluon은 aws에서 개발한 ML로 한 줄의 코드만으로 원시 테이블 데이터를 자동으로 전처리 부터 학습까지 가능하게 해주는 프레임 워크 입니다. 마찬가지로 앞의 전처리된 데이터 셋을 통해 7:3의 비율로 train, test split을 해준뒤 Label을 price로 지정, metric은 mae로 지정해주고 fit을 통해 학습 및 최적의 mae값을 갖는 모델을 추출해줍니다.
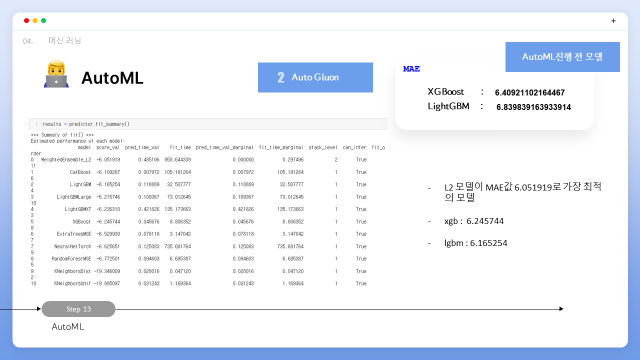
autoGluon의 결과로 L2 모델이 6.051919로 가장 최적의 MAE값을 가지는 것으로 확인되었으며, xgb는 6.245744, lgbm은 6.165254로 automl을 진행하기 전 구현했던 모델의 수치보다 MAE값이 줄은 것을 확인할 수 있었습니다.
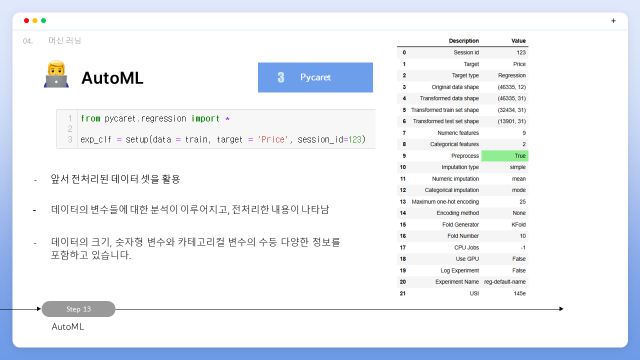
다음은 Pycaret을 설명드리겠습니다. 데이터가 회귀이기 때문에 pycaret.regression을 사용.
마찬가지로 앞서 전처리된 데이터 셋을 활용하였으며 데이터를 setup 해준 결과로로 데이터의 변수들에 대한 분석이 이루어지고, 전처리한 내용이 나타나게 됩니다.

생성된 모델을 비교한 결과 Best 모델은 catboost, xgboost, lightgbm 순으로 mae 값이 좋게 나온 것을 확인할 수 있습니다. 생성된 모델의 파라미터 또한 확인할 수 있습니다.
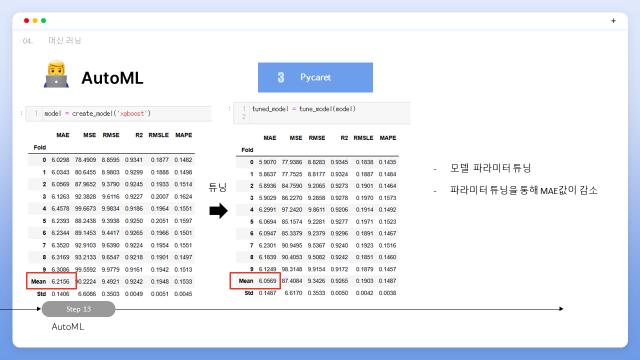
생성된 모델 중 xgboost 모델에 대해 파라미터를 tune_model함수로 튜닝한 결과 mae값이 많이 줄어든 것을 확인할 수 있습니다.
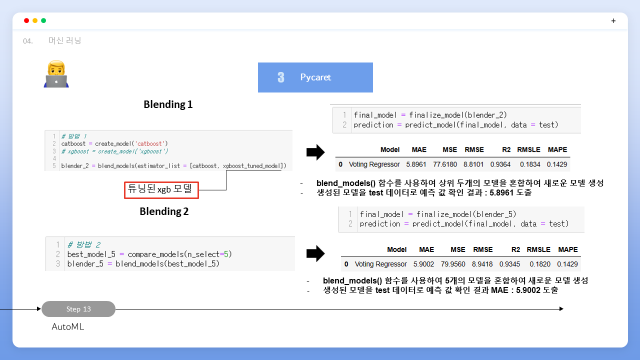
Blending blend_models() 함수를 사용하면 여러 모델들을 혼합하여 새로운 모델을 생성합니다. 모델을 하나씩 생성해서 blend해도 되고 compare_model을 사용하여 모델을 여러개 혼합하여 생성한 모델을 사용해서 blend할 수 있습니다. blending1 의 경우 생성된 모델을 test 데이터로 예측 값 확인 결과 : 5.8961 도출,blending2의 경우 생성된 모델을 test 데이터로 예측 값 확인 결과 MAE : 5.9002 도출할 수 있었습니다.
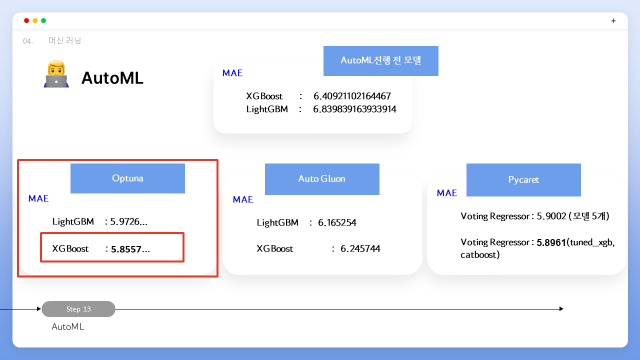
결론적으로 AutoML을 사용한 결과 모든 프레임 워크들이 기존의 K-Fold된된 모델의 MAE값보다 확연히 낮아진것을 확인하였으며, 그 중에서도 Optuna를 통해 생성한 XGBoost 모델의 MAE값이 가장 좋게 나온 것을 확인할 수 있었습니다.

프로젝트 결과 입니다.

결론적으로 이번 중고차 가격 예측 프로젝트에서의 MAE 기준 가장 최적화된 모델은 optuna의 xgboost 모델이고 내부요인 중 가장 높은 상관도와 중요도를 가지는 feature는 차량의 생산년도, 주행거리, 배기량, 모델임을 확인할 수 있었습니다.
또한, 외부요인으로는 나라 별 가격, 금리, 업체(딜러) 등으로 해당요인들을 변수로 추가하여 차량 가격에 대한 신뢰도나 예측의 정확도를 더욱 높일 수 있을것 입니다.
최종적으로 해당 모델을 통해 중고차 구매자 및 판매자들에게 신뢰할 수 있는 객관적인 지표를 제공함으로써 중고차 시장의 활성화를 기대할 수 있으며, 판매자는 합리적인 가격을 제시하며, 소비자는 허의 매물 판단의 자료로 활용할 수 있을 것입니다.

감사합니다. 이것으로 1조의 발표를 마치겠습니다.
