Machine Learning은 최종 모델이 예측을 위해 사용할 데이터 패턴으로부터 학습하는 알고리즘입니다. 사용하는 데이터의 타입은 Audio, Image, Video, Text 등이 있을 수 있고, 혹은 Multi-modal 데이터를 통해 여러 타입을 복합적으로 사용할 수도 있습니다.
Supervised Learning vs Unsupervised Learning
Supervised Learning은 label을 가지고 학습하여 데이터의 label을 분류하는 최종 function을 찾아내는 학습 방법을 말합니다. 반면에 Unsupervised Learning은 label없이 학습하여 데이터 사이의 패턴과 구조를 발견하는 학습 방법을 말합니다.
Unsupervised Learning의 종류
Clustering, Anomaly Detection, Visualization
Supervised Learning의 종류
Y값이 continuous value를 가지면 Regression,
Y값이 discrete value를 가지면 Classification
[ Supervised Learning ] Instance-based learning vs Model-based learning
- Instance-based learning은 test instance가 들어왔을 때, 근시안적으로 주변에 있는 train sample이 어디에 속했는지를 기준으로 예측합니다. 따라서 주변에 아웃라이어가 있다면 잘못 예측할 위험이 있습니다.
- Model-based learning은 데이터의 패턴과 구조를 고려하여 error를 줄일 수 있는 n차 방정식을 구한 다음, n차 방정식에 따라 test instance의 결과값을 예측합니다. 이 방법에서는 학습을 통해 error를 줄이는 방향으로 n차 방정식의 파라미터를 업데이트합니다.
[ Model-based learning ] underfitted vs goodfit vs overfitted
- underfitted: 데이터에 비해 모델이 너무 단순하여 데이터의 패턴에 따라 제대로 예측하지 못하는 상태 (train-error와 test-error값이 모두 높음)
- goodfit: 데이터의 패턴을 적절히 반영하여 모델이 적절한 예측값을 도출하는 상태 (train-error와 test-error 사이의 gap이 작음)
- overfitted: 데이터에 비해 모델이 너무 복잡하여 training data의 noisy한 값까지 반영하여 training data가 아닌 다른 데이터에 대해선 제대로 예측하지 못하는 상태 (train-error와 test-error 사이의 gap이 큼)
In ML, we often need to measure the closeness of two features in vector. Which metric can be used?
cosine similarity를 많이 사용합니다.
Can you introduce many different norms of a vector?
-
L2 norm
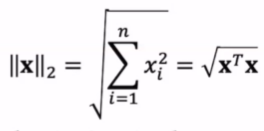
-
L1 norm

-
infinity norm
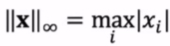
What are the “Tensors”?
Tensor는 n-dimensional arrays of scalars를 말합니다.
예를 들면 vector는 1st order tensor이고, matrices는 2nd order tensor를 말합니다.
Describe what the Bayes’ Theorem is.
를 말합니다.
물리적 의미는 를 구할 수 있는 것 입니다.
: prior probability
: posterior probability
: likelihood
: evidence
Physical meaning of Taylor series
함수 f(x)의 에서의 1차 미분값, 2차 미분값, ... , n차 미분값을 알고 있을 때, 주변에서 함수 f(x)를 이러한 애들의 n차 방정식으로 근사할 수 있습니다.
따라서 의 주변값만 가지고도 전체의 x에 대한 f(x)의 근사값을 구할 수 있습니다. 차수가 작을수록 에 가까운 x에 대해서만 적용되고, 차수가 커질수록 로부터 멀리있는 x까지 적용됩니다.
The benefit of using Taylor series
테일러 시리즈를 사용하여 복잡한 방정식을 이해하기 쉬운 다항식 (알고자 하는 특정 x값 주변에 대한 다항식)으로 대체하면, 계산하기 어려운 방정식을 직접 풀지 않아도 근삿값을 통해 효율적으로 답을 구할 수 있습니다.
