Regression의 목적은 unseen한 example에 대해서 일반화할 수 있는 model을 개발하는 것입니다.
- Split data into a training set and test set.
- Train model on training set to try to minimize prediction error on it.
- Apply trained model on test set to measure generalization error.
Mean absolute error
( actual value - predicted value )의 절댓값들의 평균
Mean squared error
( actual value - predicted value )의 제곱의 평균
Q: Mean squared error를 더 많이 사용하는 이유는?
A: Mean absolute error는 미분이 불가능하므로 numerical solution만 적용할 수 있습니다. 반면에 Mean squared error는 미분이 가능하므로, 여러번의 logical step을 거듭하며 근을 찾는 analytics solution을 적용할 수 있습니다.
✔️ 따라서 Mean squared error를 더 많이 사용합니다.
Matrices and Vectors
Feature란 각각의 measureable property 혹은 characteristic을 의미합니다. 일종의 독립변수라고 생각하면 됩니다. 하나의 input sample은 아래와 같이 M개의 feature로 구성됩니다.
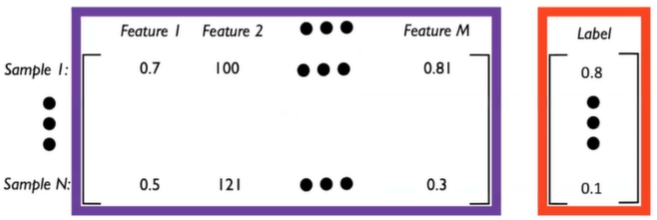
따라서 행의 개수는 데이터 sample의 개수를, 열의 개수는 feature의 개수를 의미합니다.
Linear Regression
X는 feature vector, W는 parameter vector를 의미하며 일차식으로 되어있습니다. Mean squared error를 최소화하는 W를 찾아내는 것이 바로 Linear Regression입니다.
General formula는 아래와 같습니다 :
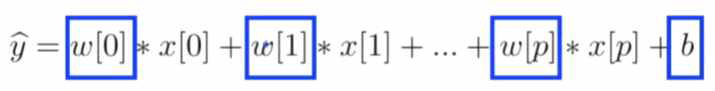
여기서 feature의 개수는 X vector의 원소 개수인 p개가 되고,
parameter의 개수는 W vector의 원소와 b를 포함한 p+1개가 됩니다.
Simple Linear Regression Model은 p=1,
Multiple Linear Regression Model은 p>1인 모델을 의미합니다.
Polynomial Regression
조금 더 복잡한 relationship을 맞추기 위해서 data를 1차원이 아닌 higher dimension에 projection하는 문제로 볼 수 있습니다.
M-th order polynomial function의 General formula는 아래와 같습니다 :
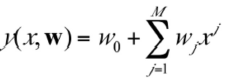
linear regression과 다르게, 를 계산하지 않고, 를 계산하며
이때 가 됩니다.
예를 들면 polynomial degree가 3일 때, feature vector는 아래와 같습니다.

Regularization
polynomial degree가 크면 training error는 굉장히 작아질 수 있지만, overfit될 확률이 높아집니다. 이때 error function에 특정 constraint를 추가하면 overfit을 예방할 수 있습니다.
원리는 error function에 weight값의 크기를 제한하는 제약 조건을 추가하여 weight값이 진동하며 overfit이 발생하는 것을 예방하는 것입니다.
-
Ridge Regression (L2)을 추가
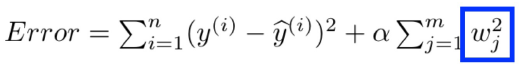
-
Lasso Regression (L1)을 추가
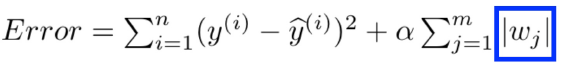
Q: Alpha값을 찾는 방법?
A: Alpha값은 validation set을 추가로 두어 최적의 Alpha값을 찾아내고, 그 alpha를 이용하여 test set을 통해 prediction을 진행합니다.
즉, data set을 training set, validation set, test set으로 나누고 validation set을 이용하여 Alpha값을 구합니다.
Q: Alpha값이 너무 작거나 너무 크면?
A: Alpha값이 너무 작으면 overfit될 경향이 커지고, Alpha값이 너무 크면 predict한 값이 actual한 값으로부터 더 멀어지는 문제가 생깁니다.
