Classification은 discrete한 value를 prediction하는 것이 목적입니다.
- Split data into a training set and test set.
- Train model on training set to try to minimize prediction error on it.
- Apply trained model on test set to measure generalization error.
Evaluation Methods
Confusion Matrix
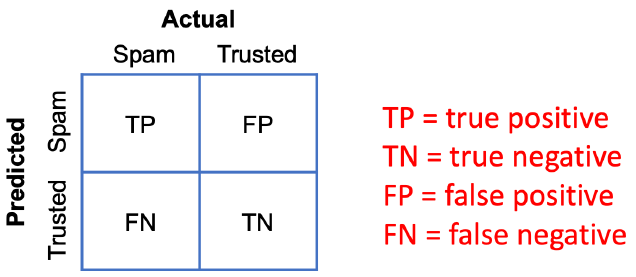
~P는 positive로, ~N은 negative로 prediction한 경우를 말합니다.
TP는 positive를 positive로, TN은 negative를 negative로 판단한 확률을 말하며,
FP는 아닌데 잘못 positive로, FN은 아닌데 잘못 negative로 판단한 확률을 말합니다.
Motivation for new ML era: need non-linear models
Perceptron(= linear function)만으로는 XOR Problem과 같은 문제를 풀지 못합니다. 문제 상황에 맞게 space를 분리할 수 없기 때문입니다.
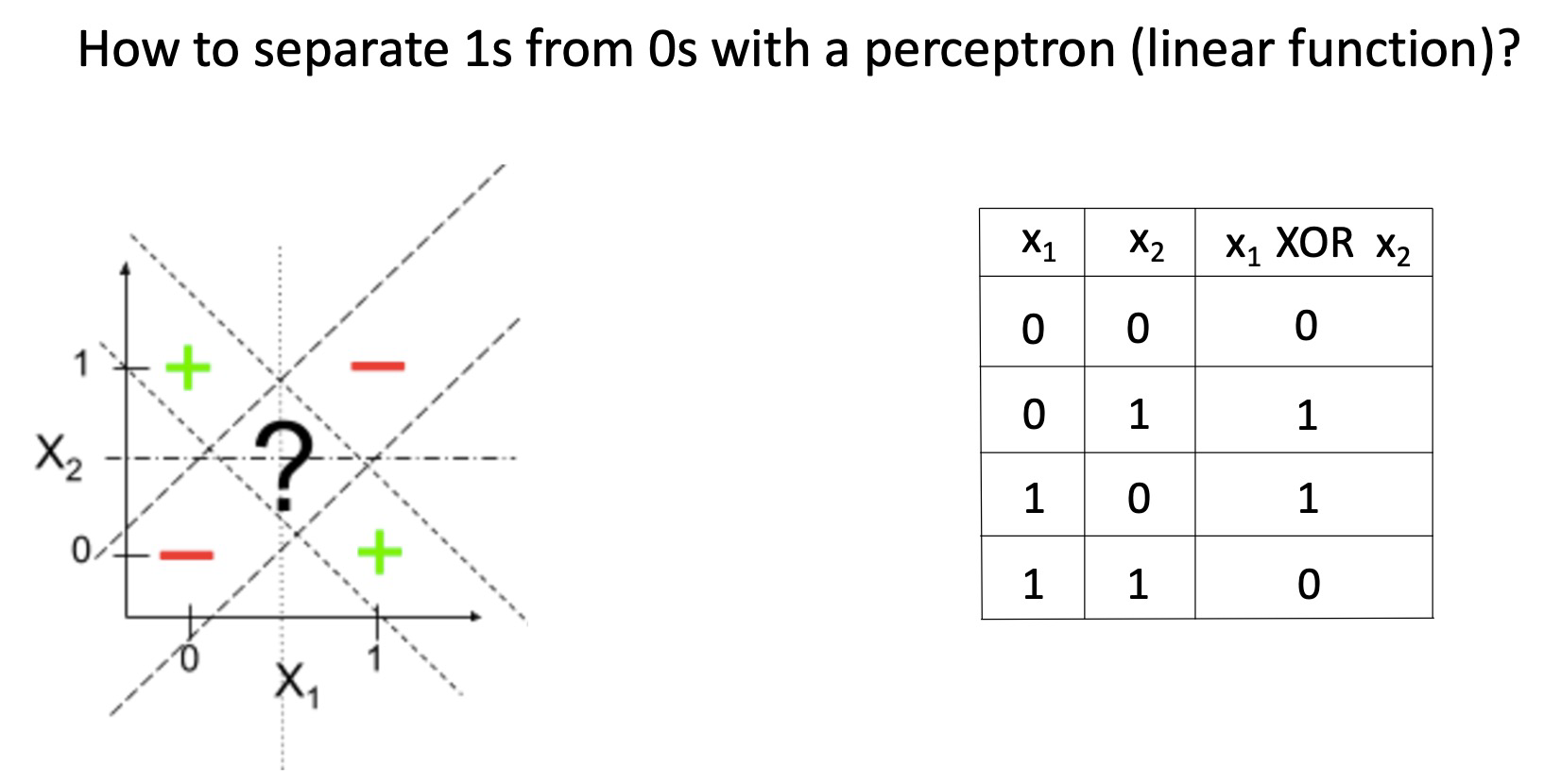
이러한 문제를 해결하기 위해 Non-linear model이 등장했습니다.
대표적인 Nearest neighbor classification과 Decision tree classification에 대해 알아보겠습니다.
Nearest neighbor classification
(ex) K-Nearest Neighbor Classification
거리 중심으로 제일 가까운 데이터 K개를 선택하고, K개의 데이터가 가장 많이 속한 class로 prediction하는 방법을 말합니다.
이를 위해서는 모든 example을 memorize해야 한다는 문제가 존재합니다. 데이터 사이의 pattern을 찾아내는 Model-based learning이 아니며, Instance-based learning의 형태로 주변 Instance 몇개에 결정이 좌지우지 된다는 특징이 있습니다.
Q: How to aviod ties?
A: 가장 많이 속한 class를 항상 분명하게 가려내기 위해, k를 홀수로 선택하거나 더 가까운 데이터의 class에 가중치를 주는 방법을 선택할 수 있습니다.
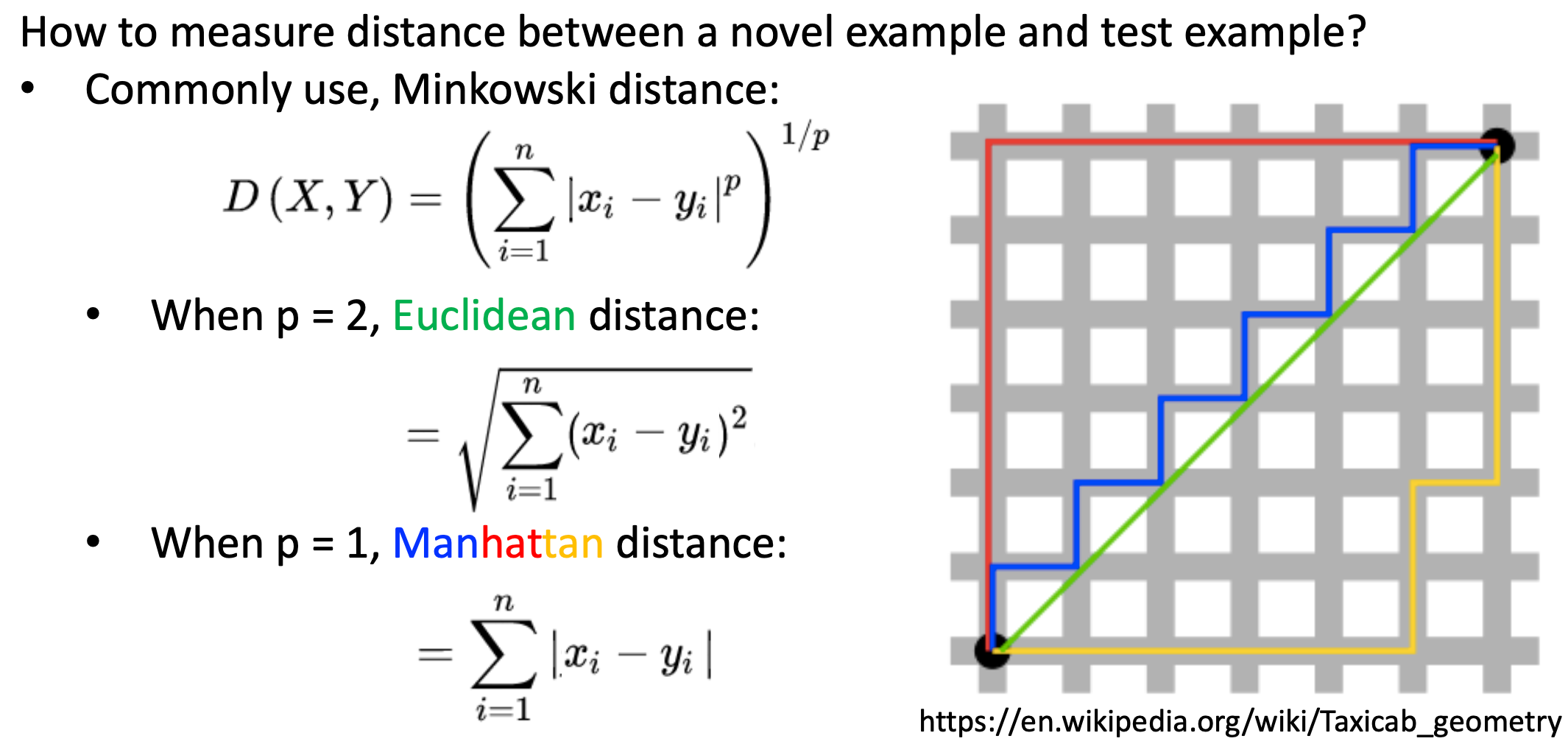
Q: 거리를 계산하는 방법
이때, x와 y의 분포에 따라 k개의 neighbors를 선택하는 과정에서 큰 오류가 생길 수 있으므로 feature 상에서 data를 scale하는 것이 중요합니다.
Q: 적절한 k를 찾는 방법
A: training accuracy와 test accuracy 사이의 gap이 가장 작은 k를 선택하는 것이 바람직합니다.
Decision tree classification
Decision tree에서 decision node는 attribute에 따라 결정이 되고, attribute의 범위에 따라 branch가 나뉘게 됩니다. leaf node는 최종적으로 prdiction하고자 하는 class가 됩니다. 이러한 Decision tree를 ML을 통해 잘 만드는 것이 Decision tree classification에서의 관건이 됩니다.

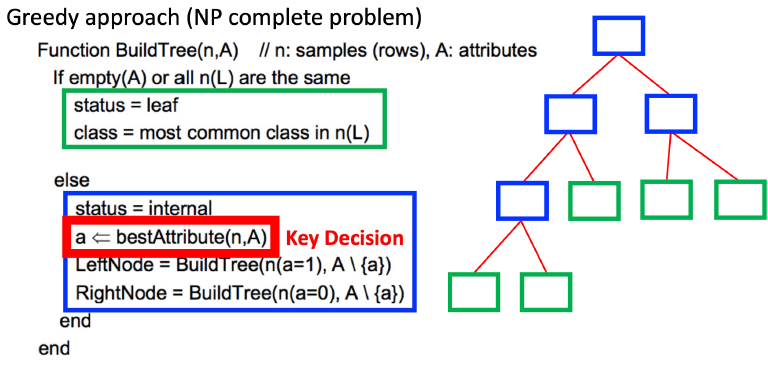
Decision Tree를 만드는 알고리즘
매개변수 n은 데이터 sample들, 매개변수 A는 attribute들을 의미합니다.
먼저 남아있는 attribute를 모두 사용하여 현재 상태가 leaf node라면, 남아있는 데이터 sample들이 가장 많이 가지고 있는 class로 prediction을 합니다.
다음으로, 현재 상태가 internal node라면 현존하는 attribute들 중 가장 최선인 attribute를 뽑습니다. (= )
이후 선택한 attribute의 값을 기준으로 작은건 LeftNode로, 큰건 RightNode로 데이터 sample들을 배치하여 attribute들의 tree를 마저 구성해나갑니다.
bestAttribute를 뽑는 방법?

IG값이 가장 큰 attribute를 선택합니다.
Perceptron vs Adaline
Perceptron에서는 weight update에 사용할 output 값을 threshold function을 거친 이후의 discrete한 값으로 사용합니다.
반면에 Adaline에서는 Activation function만을 거친 continuous한 값을 weight update에 사용하는 output값으로 이용하고, 이후 threshold function을 거쳐 prediction합니다.
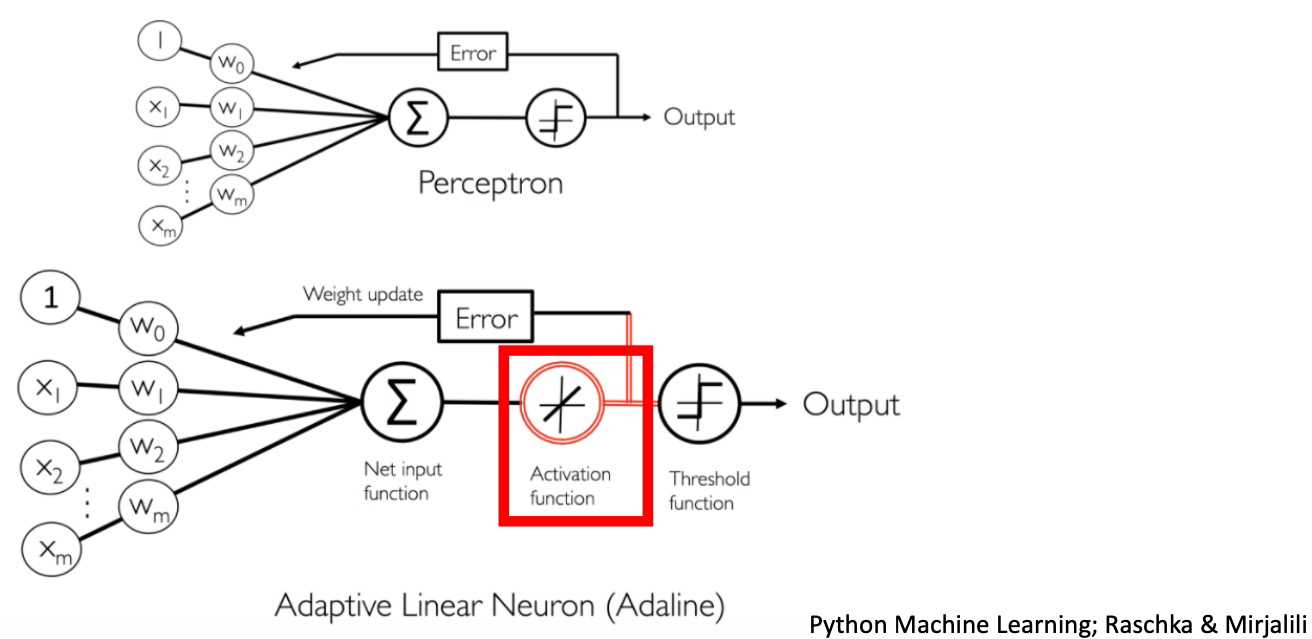
또한 Perceptrion에서는 한 sample에 대해서 prediction한 이후 바로 weight를 update했다면, Adaline에서는 weight update value를 일시적으로 저장해두었다가 1 epoch가 끝난 후 한꺼번에 바꿉니다.
(cf) Adaline vs Linear regression
activation function까지는 같지만, Adaline은 threshold function을 통해 categorical한 output으로 바꿔주고 Linear regression은 continuous한 값을 output으로 도출한다는 차이점이 있습니다.
Gradient Descent
Batch Gradient Descent (BGD)
모든 training sample들을 다 계산하고, 한번에 weight를 update하는 방법을 말합니다. 하나의 training sample에 좌지우지되는 것을 예방할 수 있지만, 모든 training sample을 다 계산하는 과정에서 많은 비용이 필요하다는 단점이 있습니다.
Stochastic Gradient Descent (SGD)
하나의 training sample마다 weight를 update하는 방법을 말합니다. 1 iteration에 필요한 계산량이 많지 않아서 huge data set이어도 괜찮다는 장점이 있지만, 하나의 training sample에 좌지우지될 수 있어 아웃라이어에 민감할 수 있다는 단점이 있습니다.
Mini-batch Gradient Descent
BGD와 SGD의 단점을 보완한 방법으로, 하나의 batch마다 weight를 update하는 방법을 말합니다.
