RT-DETR(Real-Time Detection Transformer) 모델
- DETR 모델 개선 → 실시간 처리 가능 → 높은 정확도와 빠른 처리 속도
- DETR 모델 개선의 내용
- 효율적인 하이브리드 인코더
- 불확실성 최소화 쿼리 선택
RT-DETR(Real-Time Detection Transformer)
- Object Detection에서 실시간 성능과 높은 정확도를 동시에 달성하기 위해 설계된 엔드투엔드(End-to-End) 트랜스포머 기반 모델
- YOLO 시리즈와 같은 실시간 객체 검출기에서 사용되던 비최대 억제(NMS)와 앵커(anchor) 설정 등의 복잡한 후처리 과정을 제거하여, 보다 간결하고 효율적인 구조임
- 개요
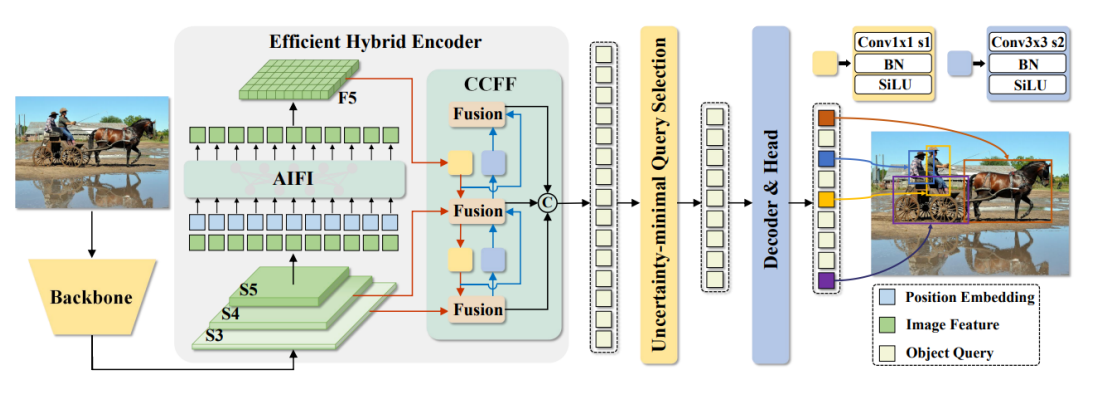
- Backbone Network
- efficient Hybrid Encoder
- Attention-based Intra-scale Feature Interaction (AIFI)
- CNN-based Cross-scale Feature Fusion (CCFF)
- Uncertainty-minimal Query Selection
- Transformer decoder with auxiliary prediction heads
Backbone Network
- 입력 이미지에서 다중 스케일 특징 맵을 추출함
- ResNet과 같은 CNN 기반 네트워크를 사용하여 주요 특징을 추출
- 특징
- 여러 해상도의 피쳐 맵을 생성하여 작은 객체와 큰 객체를 모두 검출 가능
- CNN 기반으로 효율적이며, 다양한 네트워크(ResNet, Swin Transformer 등)와 결합 가능
- 백본 네트워크의 출력은 여러 스케일에서 추출된 피쳐 맵 (각 스케일 𝑙에 대한 특징) 임
- 이를 기반으로 후속 처리 과정 수행함
- 는 백본 네트워크의 연산을 나타내며, 입력 이미지 를 피쳐 맵 로 변환함
efficient Hybrid Encoder
Attention-based Intra-scale Feature Interaction (AIFI)
- 각 스케일의 피쳐 맵 내에서 어텐션을 이용해 정보를 강화함
- 특징
- 동일한 스케일 내 특징 간 관계를 학습하여 표현력을 향상
- 어텐션 연산을 통해 중요한 특징을 강조
- 동일한 스케일 내에서 장거리 의존성을 학습
- transformer의 Multi-Head Attention(MHA)을 활용하여 중요한 특징을 강조
- AIFI는 피쳐 맵 에 대해 transformer의 Self-Attention을 적용하여 새로운 피쳐 맵 을 생성함
- Multi-Head Attention
CNN-based Cross-scale Feature Fusion (CCFF)
- 여러 스케일 간 정보를 융합함. CNN을 활용하여 다중 해상도 특징을 효율적으로 합성
- 특징
- CNN 기반 접근 방식으로 연산량을 줄이면서도 정보 손실을 최소화
- 다양한 크기의 객체를 동시에 고려할 수 있도록 함
- 서로 다른 스케일의 특징을 CNN을 이용해 통합
- CNN의 Convolution Layer를 사용하여 계산량을 줄이면서도 효과적인 정보 융합 수행
- 은 학습 가능한 가중치
- 는 CNN 연산


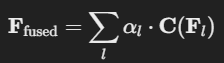
Uncertainty-minimal Query Selection
- 트랜스포머 디코더에 입력할 객체 쿼리를 선택하는 과정
- 높은 신뢰도를 가진 쿼리만을 선택하여 성능을 향상
- 특징
- 불필요한 쿼리를 제거하여 모델의 연산량 감소 및 성능 향상
- 신뢰도가 높은 쿼리만 선택하여 더 정확한 예측 가능
- IoU(Intersection over Union) 기반의 쿼리 선택
- 불확실성이 높은(즉, IoU가 낮은) 후보를 제거하고 신뢰도가 높은 쿼리만 선택
- 선택된 쿼리를 디코더 입력으로 활용

Transformer decoder with auxiliary prediction heads
- 선택된 쿼리를 기반으로 최종 객체를 검출
- 특징
- 보조 예측 헤드를 사용하여 학습을 안정화
- Non-Maximum Suppression 없이 바로 객체 검출 가능
- Transformer decoder
- 디코더는 여러 층으로 구성되며, 각 층에서 쿼리를 반복적으로 업데이트

- Auxiliary Prediction Heads
- 디코더의 중간 결과를 피드백으로 활용하여 학습을 가속화하고 성능을 개선
- Bounding Box Prediction
- 는 Bounding Box Prediction의 가중치
- Class Prediction
- 는 Class Prediction의 가중치
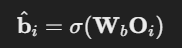
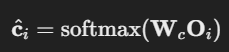
(이 시리즈의 모든 코드는 코랩환경에서 Python으로 작성하였습니다)
RT-DETR(Real-Time Detection Transformer) Code 1 (이미지 데이터 및 모델 불러오기)
# 필요한 라이브러리 설치
!pip install supervision# 필요한 라이브러리, 함수 임폴트
import torch
from transformers import RTDetrImageProcessor, RTDetrForObjectDetection
from PIL import Image
import matplotlib.pyplot as plt# 이미지 읽기
# 이미지 경로 설정
file_path='/content/drive/MyDrive/CV/vit_test.jpg'
# 이미지 읽기
img = Image.open(file_path).convert('RGB')
# 이미지 확인(출력)
plt.imshow(img)
plt.axis('off')
plt.show()# 사전 학습된 이미지 전처리/후처리 모델과 real-time object detection
model_name = "PekingU/rtdetr_r101vd_coco_o365"
rt_processor = RTDetrImageProcessor.from_pretrained(model_name)
rt_model = RTDetrForObjectDetection.from_pretrained(model_name)
print(rt_processor)
print(rt_model)RT-DETR(Real-Time Detection Transformer) Code 2 (모델 사용)
# object detection
# 필요한 라이브러리 임폴트
import supervision as sv
# 이미지 전처리
inputs = rt_processor(images=img, return_tensors='pt')
print(f'이미지 전처리의 결과 : \n{inputs}')
print('-'*80)
# 모델 출력 : class 분류, bbox의 위치 예측 좌표
outputs = rt_model(**inputs)
print(f'모델 출력 : \n{outputs}')
print('-'*80)
# class 예측의 값(softmax 통과 전)
logits = outputs.logits
print(f'class 예측 값의 모양 : {logits.shape}')
print('-'*80)
# bbox의 위치 예측 좌표
boxes = outputs.pred_boxes
print(f'bbox 예측 좌표 값의 모양 : {boxes.shape}')
print('-'*80)
# 이미지 --> pytorch tensor 변환 --> 입력 이미지의 크기 순서 변경
target_size = torch.tensor([img.size[::-1]])
# 모델 출력에 대한 후처리
results = rt_processor.post_process_object_detection(outputs, threshold=0.5, target_sizes=target_size)[0]
print(f'모델 출력에 대한 후처리의 결과 : \n{results}')
print('-'*80)
# 후처리 결과 --> supervision에서 사용할 수 있는 형태로 변환
detections = sv.Detections.from_transformers(results)
print(f'supervision에서 사용할 수 있는 형태로 변환 결과 : \n{detections}')
print('-'*80)
# 모델의 예측 레이블 : 정수 --> 문자열
labels = []
for class_id in detections.class_id:
label = rt_model.config.id2label[class_id]
labels.append(label)
print(f'모델의 예측 레이블 : {labels}')RT-DETR(Real-Time Detection Transformer) Code 3 (결과 확인)
# 이미지 복사
annotated_img = img.copy()
# 이미지에 bounding box 표시
annotated_img = sv.BoxAnnotator().annotate(annotated_img, detections)
# 이미지 정답 레이블 표시
annotated_img = sv.LabelAnnotator().annotate(annotated_img, detections, labels=labels)
# 이미지 출력
plt.imshow(annotated_img)
plt.axis('off')
plt.show()참고 자료

AI & Robotics