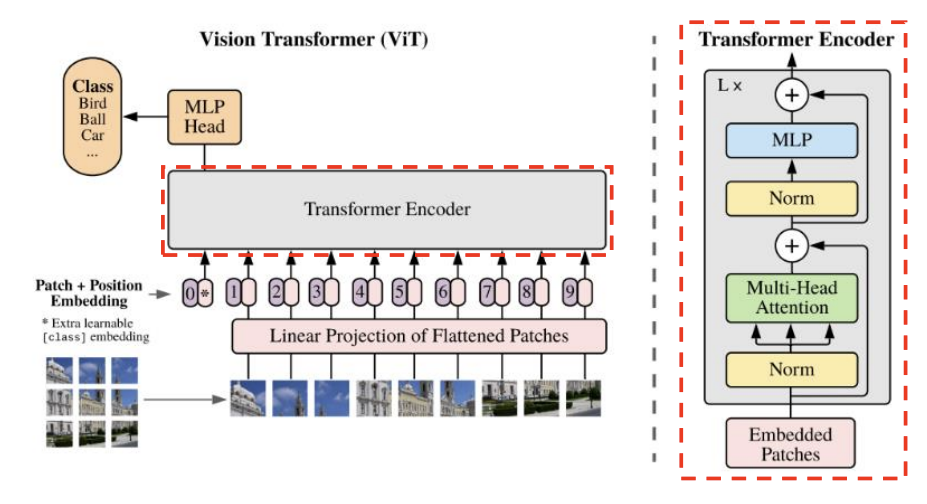
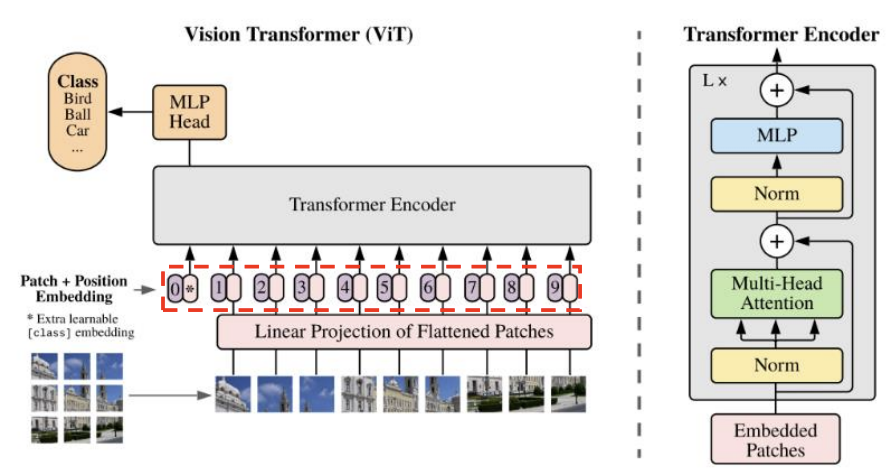
ViT(Vison Transformer) 핵심 구조
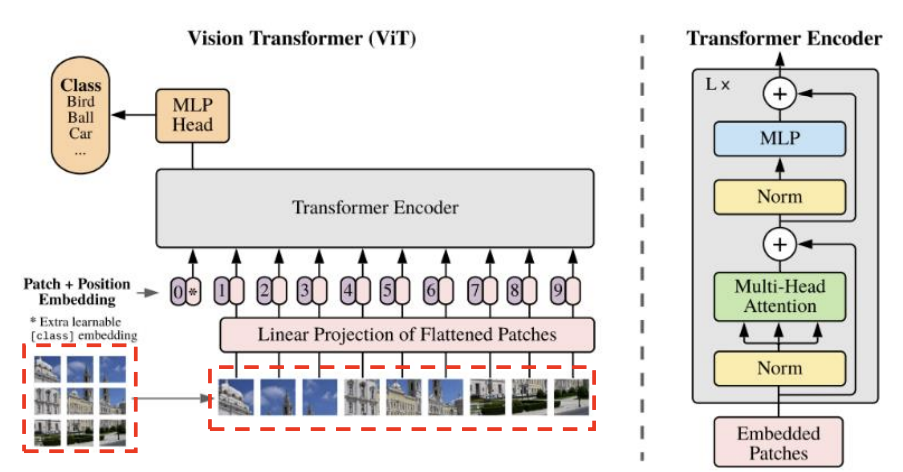
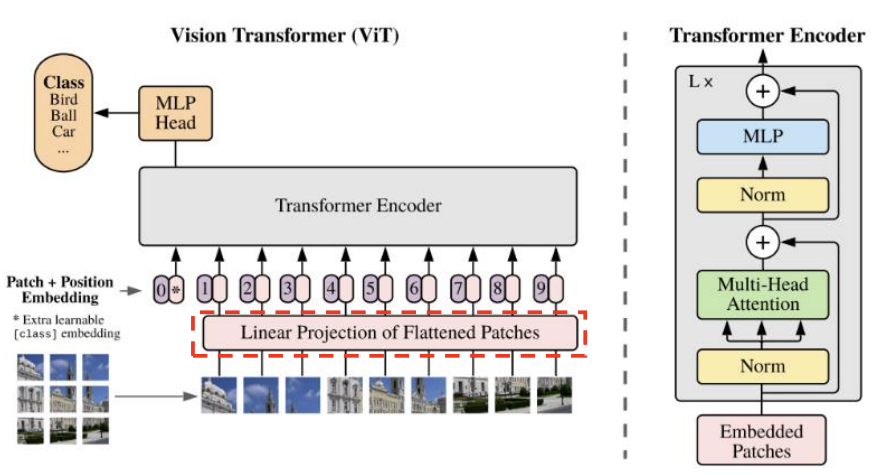
2D Patch 시퀀스 생성
- 이미지(HⅹWⅹC)를 패치(Patch) 단위로 쪼개고, 왼쪽 상단에서 오른쪽 하단의 순서로 나열
- 패치(Patch) 1개의 해상도 = (P, P), Patch의 개수 N = (H/P)ⅹ(W/P)
- 각 패치를 flatten → 1D 벡터 생성
- 1D 벡터 1개의 크기 = (), N 개의 1D 벡터 생성 → 2D() Patch 시퀀스 생성
Patch Embedding
- ViT는 CNN처럼 전체 이미지에서 컨볼루션을 수행하는 것이 아니라, 이미지를 작은 패치(Patch) 단위로 잘라 이를 Transformer의 입력으로 사용함
- 각 Patch를 학습 가능한 벡터로 변환 : 각 Patch()와 행렬 E()의 행렬 곱 연산
▶ N개의 Patch 시퀀스 → N개의 Embedding 벡터(shape:D)로 변환
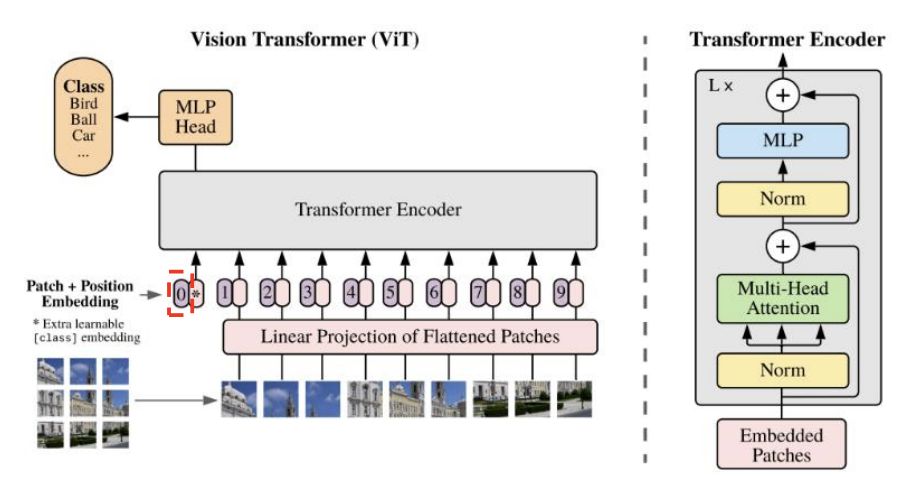
class token 추가
- 기존 Transformer와 마찬가지로 특별한 CLS Token 을 추가하여 최종적으로 이를 통해 전체 이미지를 대표하는 특징 벡터를 추출함
- 학습 가능한 Embedding 벡터(shape : D) 추가
- Classification Head와 연결 → Pre-Training과 Fine-Tuning 시 class 예측에 사용
- Embedding 행렬의 shape : (N, D) → (N+1, D)
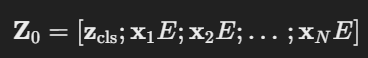
Position Embedding
- Transformer는 CNN과 달리 위치 정보(Spatial Information)를 직접적으로 처리하지 않기 때문에, Patch Embedding의 Position 정보를 유지하기 위해 위치 임베딩(Positional Encoding, PE)을 추가함
- (N+1, D) 크기의 행렬을 덧셈
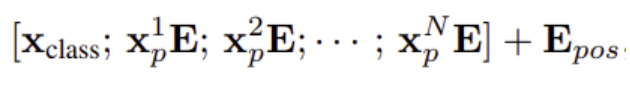
Transformer Encoder
- ViT는 Transformer Encoder만 사용하며, Multi-Head Self-Attention (MHSA)과 Feed Forward Network (FFN)를 여러 번 반복하는 구조임
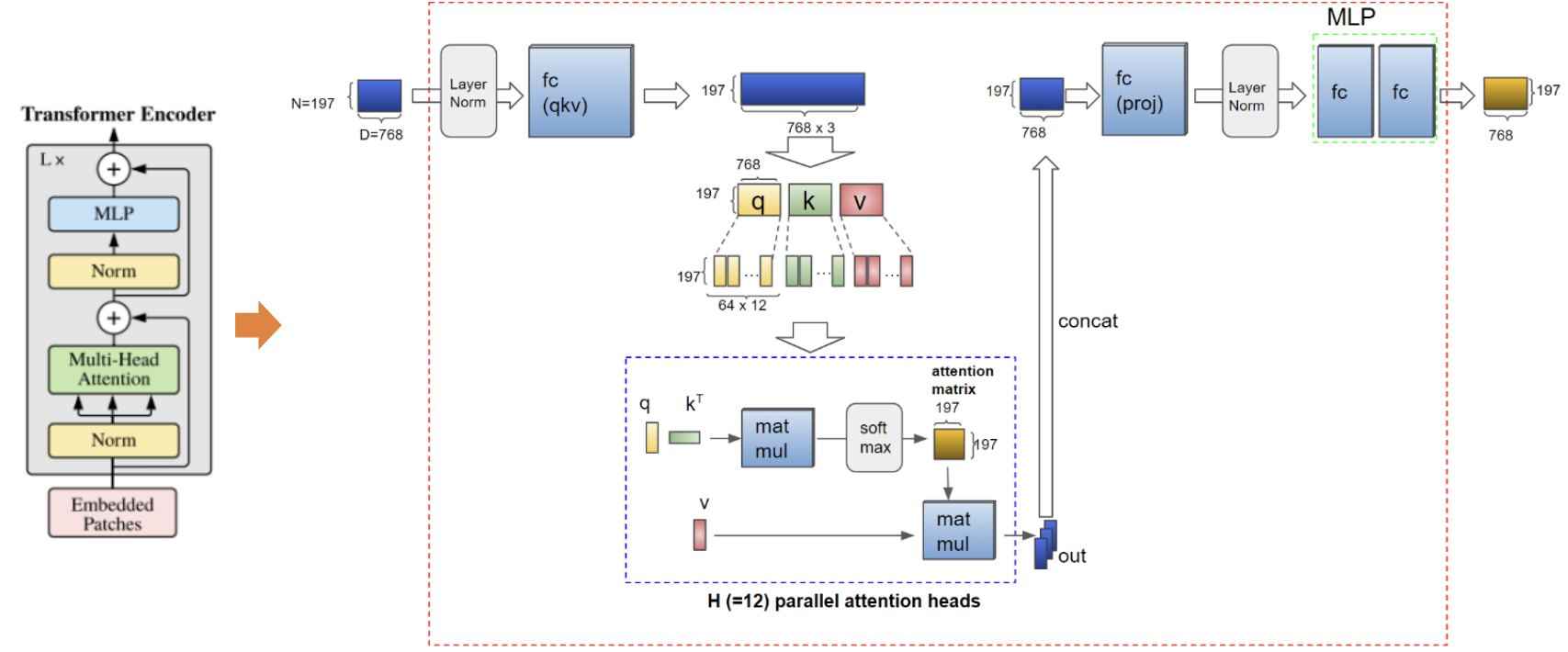
Multi-Head Self-Attention (MHSA)
- 패치 간의 관계를 학습하며, 각 패치가 다른 패치들과의 관계를 학습
- Q,K,V 행렬을 생성하고, Self-Attention을 수행함
- 다중 헤드를 적용하여 여러 관점에서 정보를 추출
MLP Head (Feed Forward Network, FFN)
- 비선형성을 학습하기 위해 두 개의 완전연결층(Dense Layer)과 GELU 활성화 함수를 사용

Layer Normalization & Residual Connection
- 각 블록마다 LayerNorm과 Residual Connection을 적용하여 안정적인 학습을 유도함
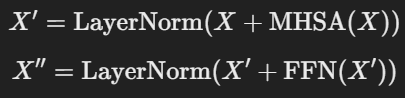
출력 (Classification Head)
- 마지막 Transformer 인코더 블록을 통과한 CLS Token을 최종적으로 사용하여 분류를 수행
- 일반적으로 MLP Head (Fully Connected Layer) 를 거쳐 Softmax를 적용하여 최종 class를 예측
- Pre-Training과 Fine-Tuning 시 class token 부분만 사용하여 class 예측

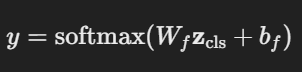

AI & Robotics
잘 읽고 가요.-유나♡-