Presenter : 황보겸
Date : 2022년 10월 8일
Paper : Going Deeper with Convolutions(GoogLeNet)
1. Abstract

이 모델의 주요 특징은 연산을 하는 데 소모되는 자원의 사용 효율이 개선되었다는 것이다. 모델의 정교한 설계 덕분에 네트워크의 depth 와 width 를 늘려도 연산량이 증가하지 않고 유지된다. 이 모델에서는 성능의 최적화를 위해서 Hebbian principle 과 multi-scale processing 을 적용하였다. GoogLeNet 은 22 개의 layer 를 가지며, 주로 classification 과 detection 에 사용된다.
1-1. Hebbian Principle?
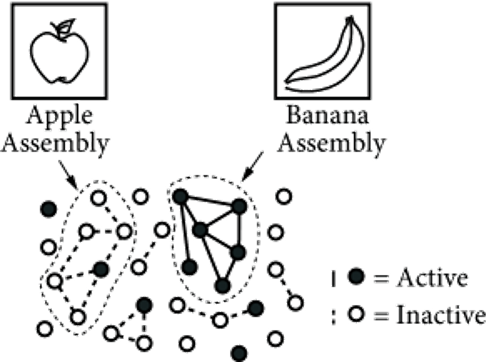
Hebbian Principle은 뇌 이론가인 도날드 헤브 박사가 제안한 이론이다. Hebbian principle 은 “Neurons That Fire Together Wire Together”, 즉 하나의 뉴런이 활성화될때 다른 관련된 뉴런도 활성화됨을 의미한다. 여기서 얻은 직관으로 모든 뉴런을 densly 하게 연결할게 아니라, 연관성이 높은 뉴런들을 sparsely 하게 연결하는 구조를 생각해냈다.
2. Introduction

지난 3 년동안 딥러닝과 컨볼루셔널 네트워크의 발전으로 object classification 과 detection 의 성능이 많이 향상되었다. 이러한 성능의 향상은 더 좋아진 하드웨어의 성능, 더 큰 데이터셋과 모델 때문이라기보다 새로운 아이디어와 알고리즘, 그리고 개선된 신경망 구조 때문이다. 논문의 저자들도 성능의 향상을 위해 노력했으며, 그 결과 이들이 개발한 GoogLeNet 은 AlexNet 보다 파라미터가 12 배나 더 적음에도 불구하고 더 높은 정확도를 보였다.

이 논문의 저자들은 효율성이 매우 중요하다고 생각했기 때문에 GoogLeNet이 합리적인 비용으로 현실에서도 사용될 수 있도록 추론 시간(inference time)에 1.5 billion 이하의 연산만을 수행하도록 설계했다.
논문에서는Inception 이라는 Codename으로 GoogLeNet 을 소개하며, 논문에서 등장하는 deep 은 두 가지 의미를 가진다. 첫 번째 의미는 inception module 의 도입이고, 두번째 의미는 말 그대로 층의 깊어짐이다.
3. Related Work

LeNet-5 를 시작으로 CNN 은 표준 구조를 가지게 되었는데, 이는 Convolutional Layer 가 쌓이고 그 뒤에 1 개 또는 그 이상의 FC Layer 가 따라오는 구조이다. 당시의 트렌드는 Overfitting을 방지하기 위해 dropout을 이용하면서 층의 깊이와 크기를 키우는 것이었다.

이 논문에서 등장하는 Network in Network는 GoogLeNet 에 많은 영향을 끼쳤다.
Network in Network 는 신경망의 표현력을 증가시키기위한 접근법으로, 1x1 convolutional layer 를 추가함으로서 구현할 수 있다. GoogLeNet 에서 이를 사용하는 목적을 두 가지이다.
1) 신경망 의 표현력을 증가시키기 위해서
2) 차원 축소로 병목현상 제거하여 층의 깊이와 넓이 증가.
4. Motivation and High Level of Considerations

깊은 신경망의 성능을 향상시키는 가장 직접적인 방법은 신경망의 크기를 키우는 것이다. 즉, 깊이를 늘리는 것(level 수의 증가)과 넓이를 늘리는 것(각 level 의 유닛 수 증가) 으로 성능 향상이 가능하다.
그러나 깊이와 넓이의 증가는 두 가지의 문제점을 발생시킨다.
1) 신경망의 크기가 커진다는 것은 파라미터 수의 증가를 의미하고, 이로인해 오버피팅이 일어나기 쉽게된다.
특히 적은 학습 데이터의 환경에서 더욱 그렇다.
Labeled Dataset 은 너무 비싸기 때문에 많은 학습 데이터를 얻는건 쉽지 않은 일이다. 특히 아래의 예시와 같이 전문가만 labeling을 제대로할 수 있는 이미지들의 경우 더욱 비싸다.

2) 네트워크의 크기가 증가하면 컴퓨터 자원의 사용량도 증가한다. Convolution Layer 의 경우, 제곱으로 증가한다.

이 문제의 해결방법은 Dense 한 FC 구조에서 Sparsely Connected 구조로 바꾸는 것이다. Convolutional Layer 내부의 FC 까지도 Sparsely Connceted 로 바꾼다. 입력 Layer 에서 출력 Layer 으로 향하는 Layer간의 관계를 통계적으로 분석한 후, 연관 관계가 높은 것들만 연결하여 sparsely connected 구조로 바꾸는 것이다.
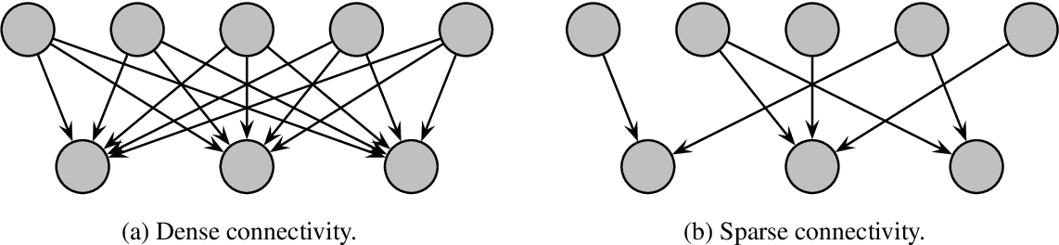
그러나 오늘날의 컴퓨터는 균일하지 않은 Sparse matrix 계산을 효율적으로 수행하지 못한다. Sparse matrix 연산을 다룬 여러 문헌들에서는 Sparse matrix를 클러스터링하여 상대적으로
Dense 한Submatrix 를 만드는 것을 제안하였고, 이는 좋은 성능을 보였다고 한다.
5. Architectural Details

Inception 구조의 주요 아이디어는 CNN 에서 각 요소를 최적의 local sparse structure 으로 근사화하고, 이를 dense component 로 바꾸는 방법을 찾는 것이다. 즉, 최적의 local 구성 요소를 찾고 이를 공간적으로 반복하면 되는 것이다. 이는 Sparse Matrix 를 서로 클러스터링하여 상대적으로 Dense 한Submatrix 를 만듦으로서 가능하다. 낮은 층에서는 이미지를 Units 로 받고, 연관 관계가 높은 unit 들이 한 지역에 모여있게 된다. 따라서 이 클러스터는 다음 Layer 에서 1x1 convolution 으로 처리할 수 있다.
1x1 을 사용하면
1) 차원 축소
2) 신경망의 넓이와 깊이의 증가
3) 차원 축소로 인해 줄어든 파라미터의 수
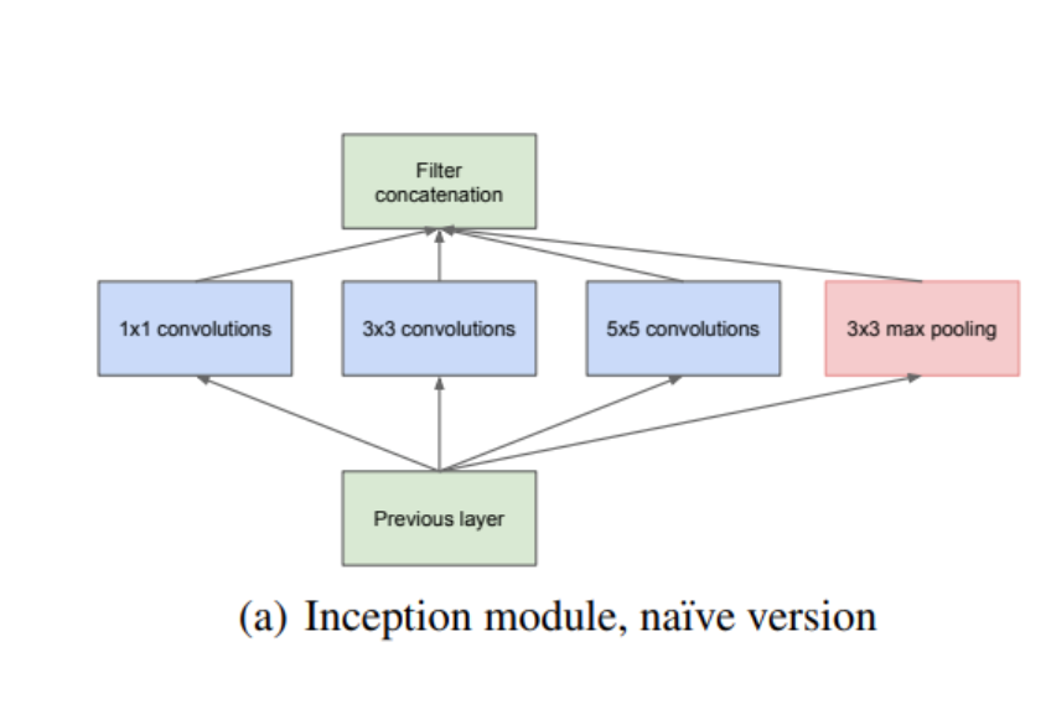
그러나 연관 관계가 높은 unit 들이 한 지역보다 더 넓게 퍼져있을 수 있을 수 있고, 이로 인해 발생하는 문제를 patch-alignment issue 라고 한다. 이를 해결하기 위해 3x3, 5x5 convolution연산을 병렬적으로 수행하여 feature map 을 효과적으로 추출할 수 있도록 한다.
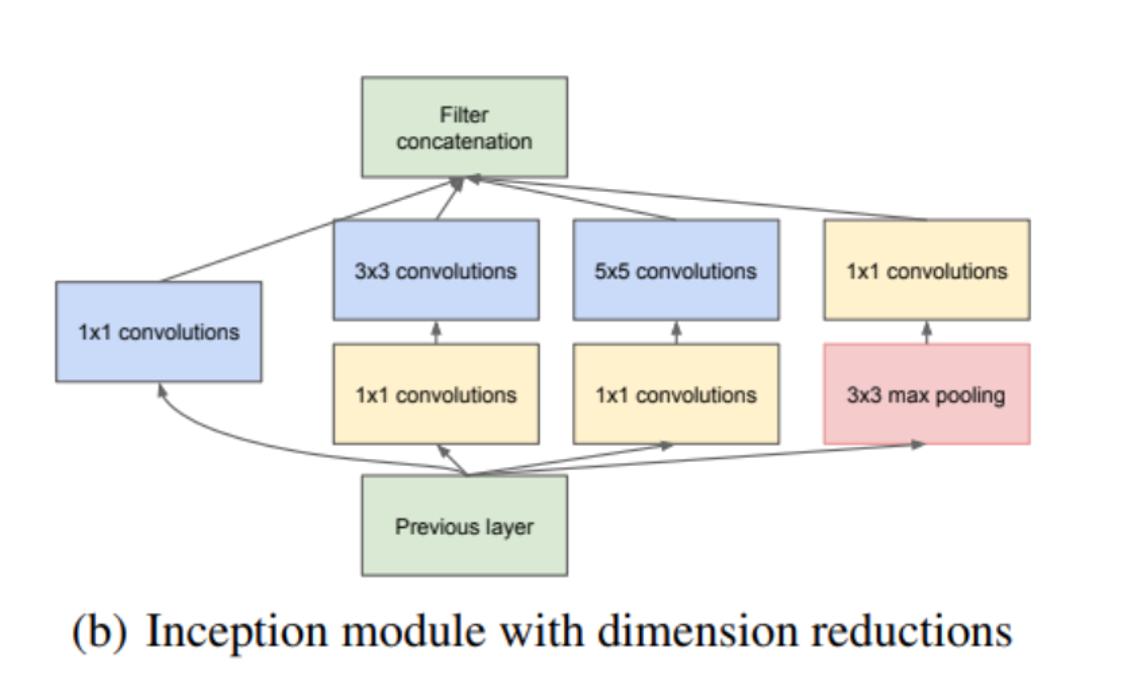
2x2, 4x4 를 사용하지 않는 이유는, 이를 사용할 경우 입력과 출력의 resolution 을 맞추기 위해서 한쪽만 패딩을 해야하기 때문이다. 논문에서도 그랬듯이, 필터 설정은 성능보다 편의에 맞춰 설정했다.
3x3 과 5x5 를 사용하게 되면 적은 수임에도 불구하고 연산량은 많아진다. 또한, 입력 feature map 의 크기가 크거나 5x5 conv filter 의 수가 많아지면 연산량은 더욱 증가한다. 이를 해결하기 위해 1x1 conv filter 을 이용하여 차원 축소를 한다. Conv 연산 이후에는 Relu 를 동반하여 비선형적 특징이 더 추가된다.
1x1 를 이용해 차원축소를 하면 아무 문제가 없냐고 물을 수 있는데, 몇개의 채널이 없어진다고 하더라도 높은 연관관계를 가진 채널이 남아 있으므로 충분히 data 를 표현할 수 있다고 한다.
저자들은 효율적인 메모리 사용을 위해 낮은 Layer 에서는 기본적인 CNN 모델을 적용하고, 높은 Layer 에서는 inception module 을 사용하는 것이 좋다고 한다.
5-1. Computations
1x1 convolution의 사용여부는 연산량에 매우 큰 영향을 미친다.
먼저, 1x1 convolution을 사용하지 않은 경우의 연산량을 계산해보자.
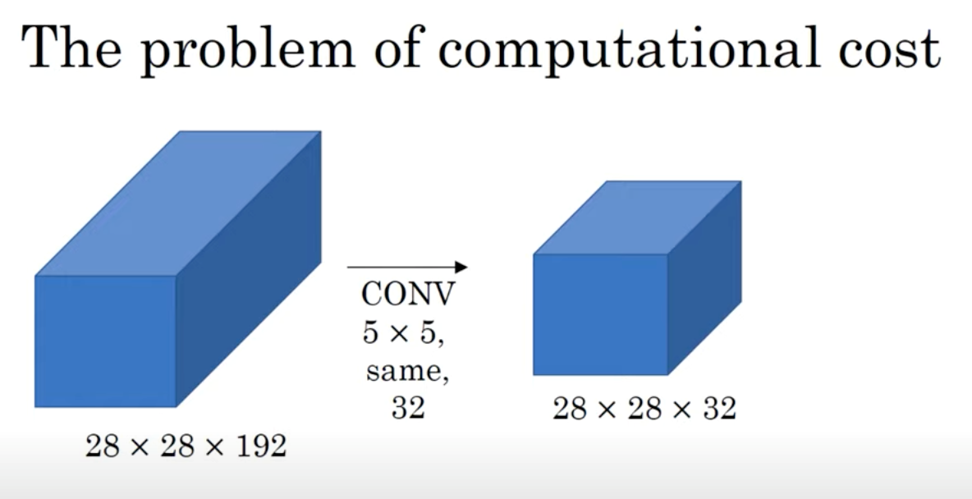
(28x28x32) x (5x5x192)의 결과, 120M이라는 매우 큰 연산량이 나온다.
다음으로, 1x1 convolution을 사용한 경우의 연산량을 계산해보자.
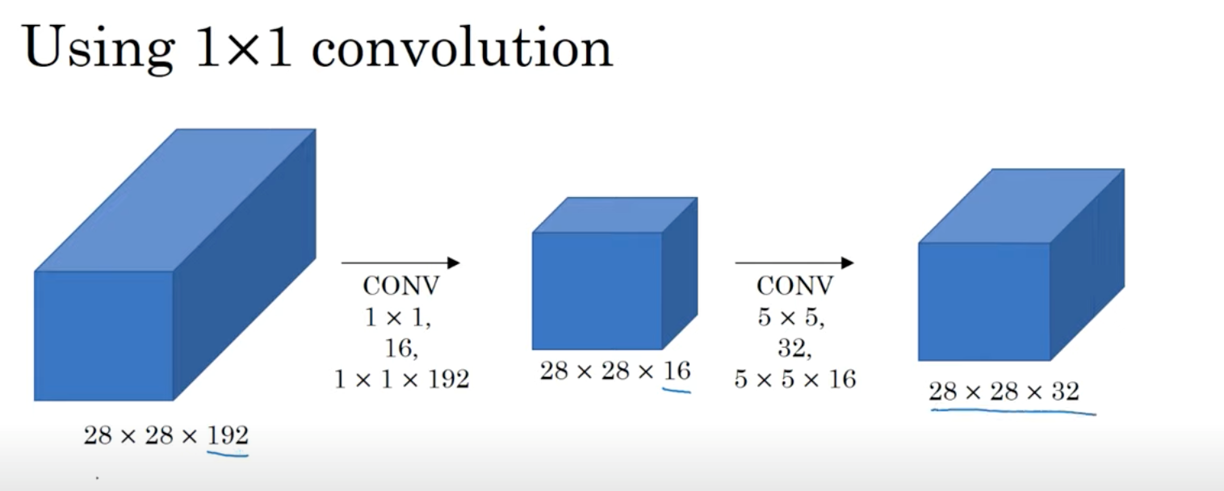
((28x28x16) x (1x1x192)) + ((28x28x32) x (5x5x16))의 결과, 12.4M이라는 연산량이 도출된다.
이를 통해 1x1 convolution을 사용할 경우, 연산량이 매우 크게 줄어든다는 것을 확인할 수 있다.
6. GoogLeNet
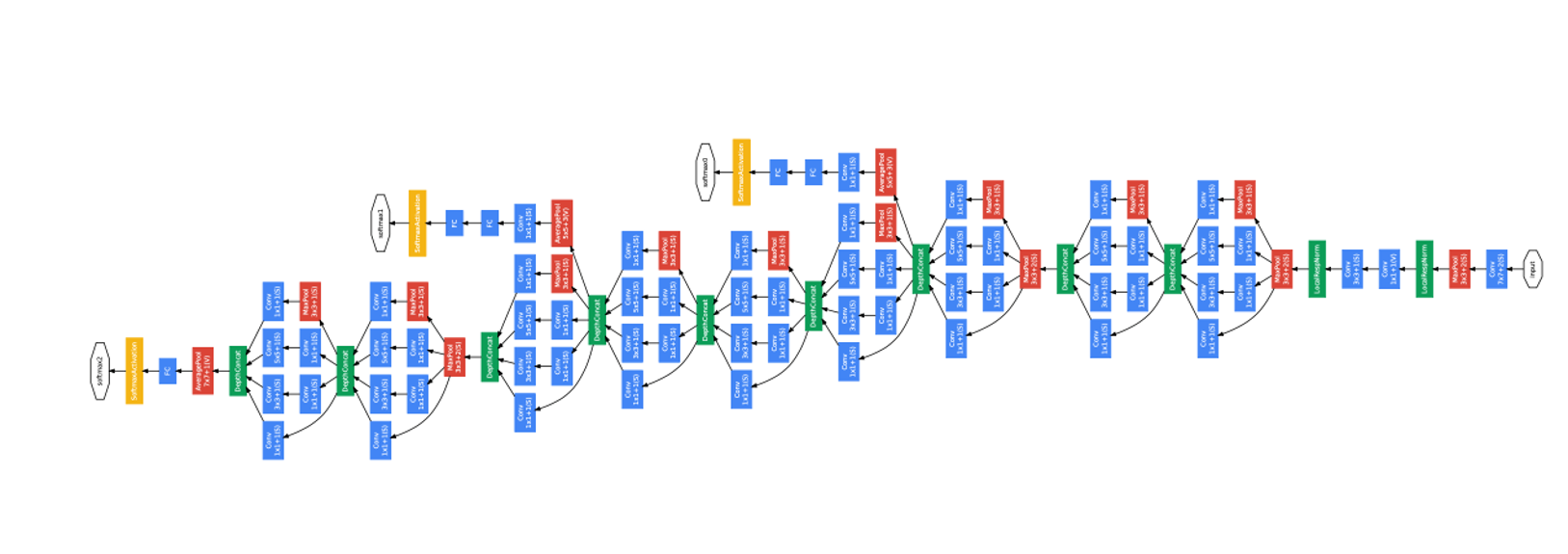
GoogLeNet을 더욱 자세하게 소개하려한다. 위의 사진으로 구조를 한 눈에 파악할 수 있으며, 아래의 표로 각 Layer에 대한 정보를 알 수 있다.
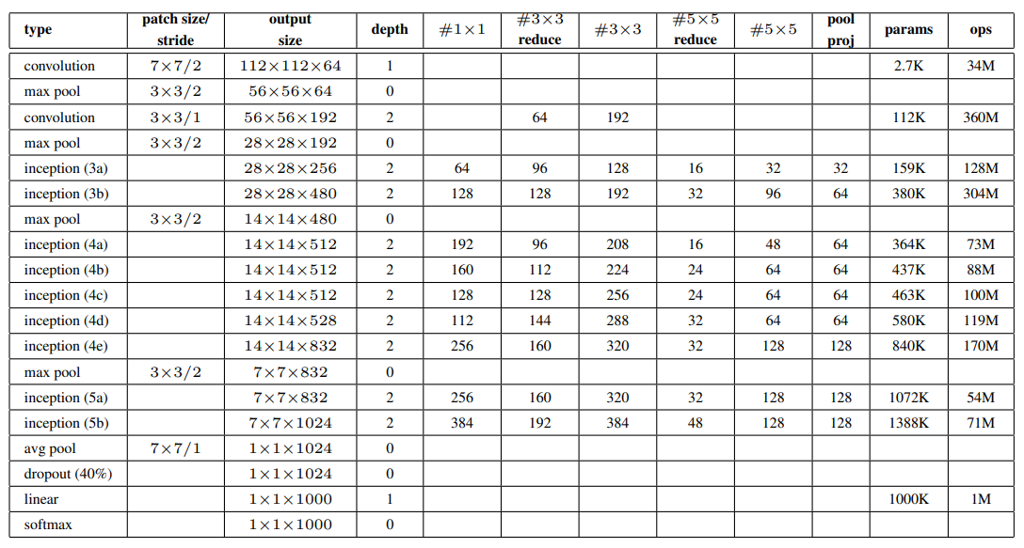
- inception 내부를 포함한 모든 conv layer 에서는 relu 가 적용되어있다.
- 모든 reduction 및 projection layer 에 Relu 가 사용된다.
- 입력은 평균을 뺀 RGB 값을 가진 224*224 이미지이다.
- “#3x3 reduce”와 “#5x5 reduce”는 각각 3x3, 5x5 convolution 전에 사용 된 reduction layer 의 1x1 filter개수를 나타낸다.
- “pool proj” 는 max-pooling 뒤에 따라오는 projection layer 의 1x1 filter 개수를 나타낸다.
GoogLeNet - Part 1
입력 이미지가 가까운 낮은 레이어가 위치해 있는 부분
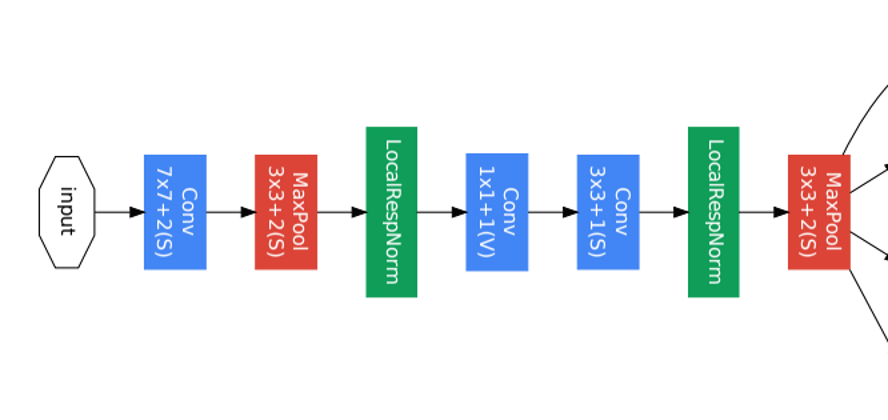
효율적인 메모리 사용을 위해 기본적인 CNN 모델을 적용했다.
GoogLeNet - Part 2
Inception Module
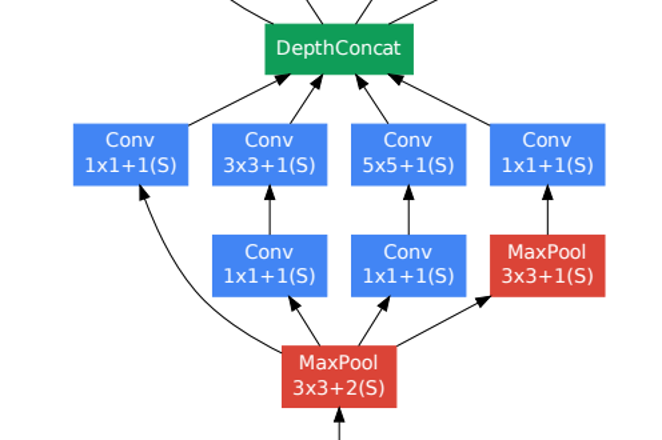
다양한 특징 추출하기 위해 1x1, 3x3, 5x5 convolution layer 가 병렬적으로 연산 수행. 차원 축소하여 연산량 줄이기 위해 1x1 convolution layer 적용되어있다.
GoogLeNet - Part 3
Auxiliary Classifier
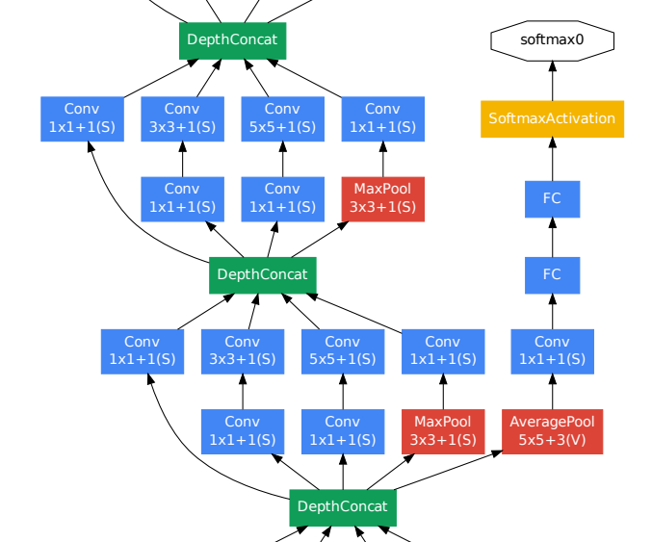
모델의 깊이가 매우 깊을 경우, gradient vanishing 문제가 발생 가능하다. 이 문제를 해결하기 위해 모델 중간에 보조 분류기(auxiliary classifier)을 추가하여 중간중간에 결과를 출력하여 추가적인 역전파를 일으켜 하위층에 gradient 가 잘 전파되도록 했으며, 정규화 효과도 나타나도록 하였다. 지나치게 영향을 주는 것을 막기 위해 auxiliary classifier 의 loss 에 0.3 을 곱했고, 실제 테스트 시에는 auxiliary classifier 을 제거했다고 한다.
GoogLeNet - Part 4
예측 모델이 나오는 모델의 끝 부분
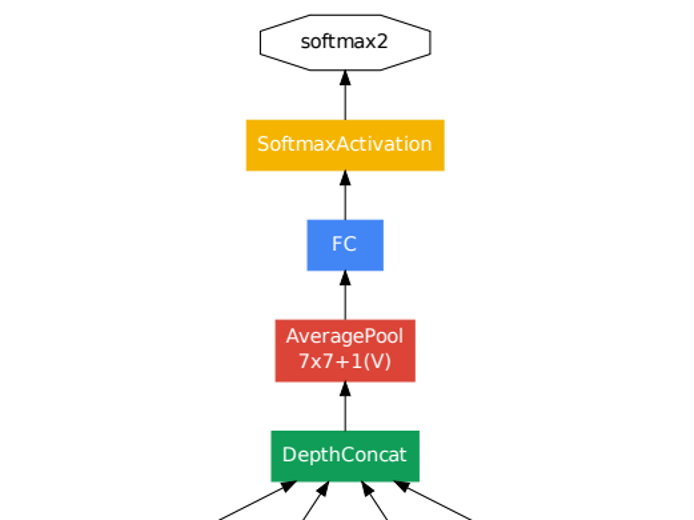
Average pooling layer 에서 Global Average Pooling 으로 이전 layer 에서 추출된 feature map 을 각각 평균낸 것을 모두 이어서 1 차원 벡터로 만들어준다. 그 이후 softmax layer 으로 연결한다.
Answers to 4 Questions
1. 저자가 이루고 싶어한 것은?
저자들은 논문에서 언급한 것처럼 Sparse한 구조를 가진 모델로 높은 성능의 신경망 만들려고 한 것 같다.
2. 해당 연구에서 중요한 요소는?
Sparse한 구조를 Dense 구조로 근사화하는 부분과 1x1 convolutional layer을 사용하여 연산량을 줄이는 부분이 제일 중요한 것 같다. 이 두 가지 요소들로 성능은 큰 폯으로 증가시키는 반면, 연산량은 소폭 증가시키기 때문에 중요하다고 생각했다.
3. 이 논문에서 내가 무엇을 사용할 수 있을까?
나는 이 논문에서 연산량을 줄이기 위해 사용된 1x1 convolutional layer을 사용할 것 같다.
4. Reference 중에서 더 읽어볼만한 것이 있는가?
Reference 중에서는 더 읽어볼 것이 없다. 예전의 논문들보다 이 논문과 연관된 최근의 논문들을 읽어보고 싶다.
