Javascript 알고리즘 및 자료구조(Colt Steele 강의 참고)
1.(JS 알고리즘)정렬 알고리즘
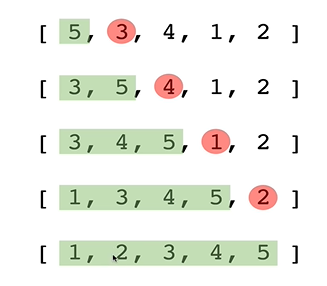
정렬 알고리즘 : 항목을 재정렬 하여 항목이 일종의 순서로 정렬되도록 하는 과정을 의미한다.각 요소를 루프로 돌면서, 다음 요소가 비교하는 값보다 큰 지 작은 지를 확인하고 자리를 바꾸는 과정(swap)을 반복한다. 즉, 바로 옆에 있는 것과 비교해서 크면 자리를 바꾼
2.(JS 알고리즘)정렬 알고리즘_빠른

버블정렬, 선택정렬, 삽입정렬은 확장성이 좋지 않다. 예를 들어 큰 규모의 데이터 정렬에서는 시간이 매우 많이 걸린다.큰 규모의 데이터를 빨리 정렬하기 위해서 합병정렬, 퀵정렬, 기수정렬 등의 알고리즘을 사용할 수 있다.시간복잡도 O(n^2) -> O(n)병합과 정렬을
3.(JS 자료구조)단일 연결 리스트

단일 연결 리스트는 head , tail , length 프로퍼티들을 포함한 자료구조다.단일 연결 리스트는 node 들로 구성되어 있으며, 각각의 node 는 value 와 다른 노드나 null을 향한 pointer 를 갖고 있다.단일 연결 리스트에는 인덱스가 없다.
4.(JS 자료구조)이중 연결 리스트

이중 연결 리스트는 단일 연결 리스트에서 이전의 노드를 가리키는 포인터를 하나 더하는 것 뿐이다. 각각의 노드에 포인터 가 두 개씩 있게 된다.이중 연결 리스트는 이처럼 반대 방향 포인터도 갖게 되어 성능상 유연함을 갖게 됐지만, 더 많은 메모리가 필요하게 됐다.(ne
5.(JS 자료구조)스택(Stack)과 큐(Queue)

스택은 LIFO(Last In Fisrt Out, 후입선출) 자료구조이다. 스택에서는 마지막으로 추가된 요소가 제일 먼저 제거된다.배열에서 push 메서드와 pop 메서드를 사용하여 스택 자료구조를 만들 수 있다. 또는 별도의 클래스로 자신만의 스택 자료구조를 만들 수
6.(JS 알고리즘) 이진탐색트리(Binary Search Tree)
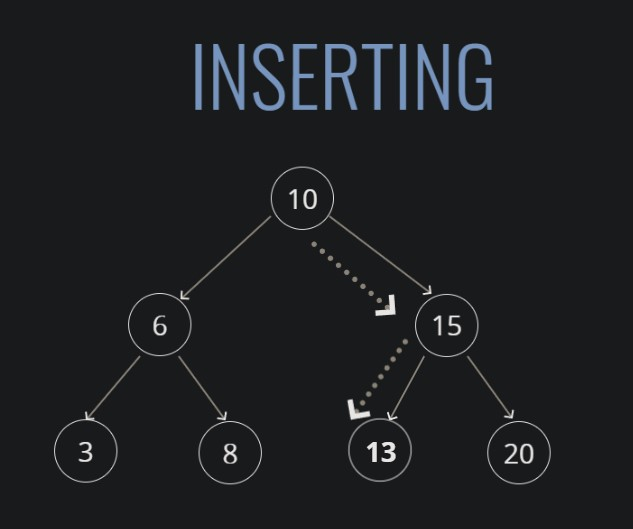
트리는 parent , child 관계를 지닌 노드들로 구성된 자료구조다.리스트는 일렬로 쭉 이어지는 선형(linear) 구조인 반면에, 트리는 여러 갈래로 뻗을 수 있는 비선형(nonlinear) 구조이다.트리에서 노드는 부모-자식 관계에 따라 자식인 노드만을 가리킬
7.(JS 알고리즘) 트리 순회 - BFS(너비우선탐색), DFS(깊이우선탐색)
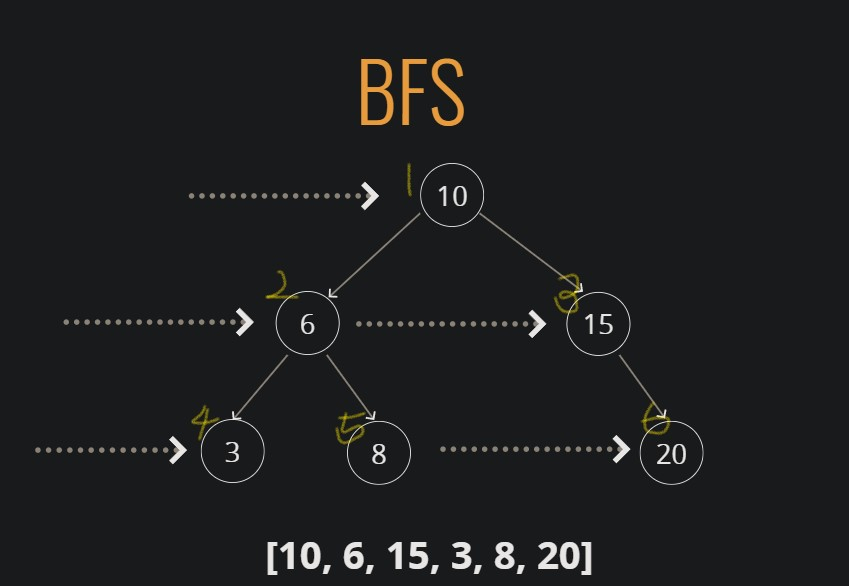
트리의 모든 노드를 순회하는 2가지 방법Breadth-frist Search(BFS, 너비우선탐색)Depth-first Seacrh(DFS, 깊이우선탐색)같은 레벨의 노드들을 우선적으로 탐색(형제요소)깊이우선탐색에는 세 가지 방법이 있다. 모두 재귀를 사용하며, 이 세
8.(JS 알고리즘) 이진 힙(Binary Heap)과 우선순위 큐(Priority Queue)

Heap의 사전적 의미는 무엇인가 차곡차곡 쌓여있는 더미를 의미한다. 이를 통해, 자료 구조에서 힙이란 모래 더미처럼 삼각형 구조로 쌓여있는 구조임을 추측할 수 있다.메모리 영역 Heap과 자료구조 Heap은 서로 상관관계가 없다. 메모리 영역 Stack은 자료구조 S
9.(JS 자료구조) 해시 테이블(Hash Table) - 해시 맵
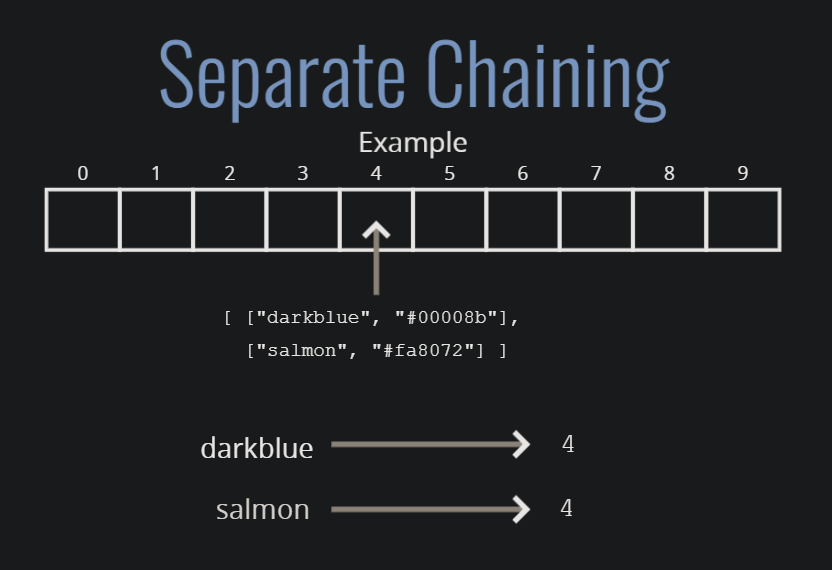
참조https://evan-moon.github.io/2019/06/25/hashtable-with-js/해시 테이블은 key-value 쌍을 저장하는 데 사용한다.해시 테이블의 key는 순서를 갖지 않는다.(배열은 인덱스)해시 테이블은 값을 찾거나 추가하거나
10.(JS 자료구조) 그래프(Graph)
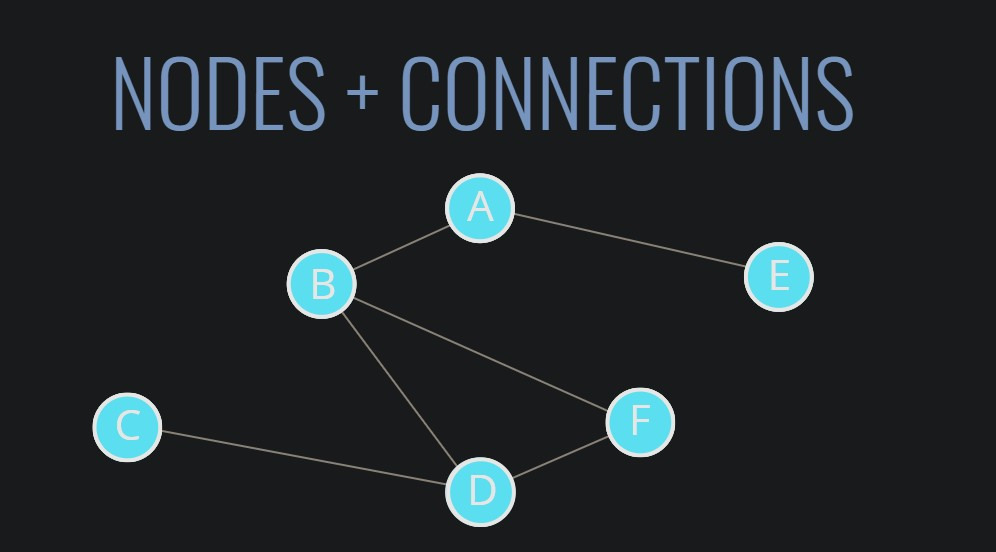
그래프는 노드나 노드들의 연결을 모은 것이다.(노드+연결선)그래프는 트리는 포괄하는 개념이다. 트리는 그래프의 일종으로 볼 수 있다.트리는 그래프의 한 종류지만 한 노드에서 다른 노드로 가는 경로가 하나만 존재그래프를 코딩하는 방법에는 여러가지가 있지만 인접 리스트,인
11.(JS 알고리즘) 그래프 순회(Graph Traversal) - DFS(깊이우선탐색), BFS(너비우선탐색)
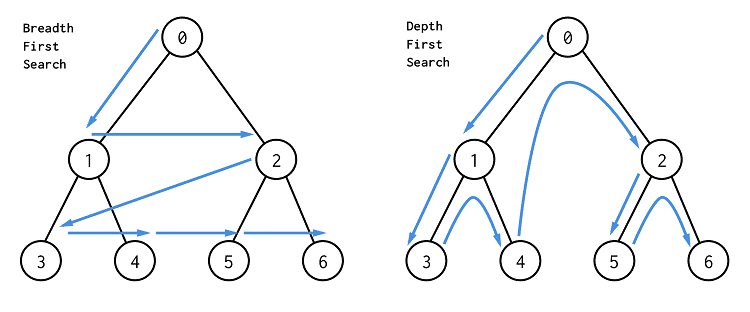
그래프에서 순회하는 코드를 짤 때, 루트가 있는 트리 순회와는 달리 시작점을 정해줘야 한다.그래프의 한 노드에서 다른 노드로 갈 때 유일한 하나의 길만이 있다는 보장은 없다. 이미 방문한 노드를 다시 방문해야 할 수도 있다.DFS(깊이우선탐색)은 다른 형제를 방문(ba
12.(JS 알고리즘) 다익스트라(Dijkstra) 알고리즘

다익스트라 알고리즘은 그래프의 두 개의 정점 간에 최단 경로를 찾는 알고리즘이다.우선순위 큐를 활용하여 그래프의 두 정점 사이에 존재하는 최단 경로를 찾는다.루프를 돌면서, 새로운 노드를 방문할 때마다 기록된 거리가 가장 짧은 노드부터 먼저 확인한다.방문할 노드로 이동
13.(JS 알고리즘) 동적 프로그래밍
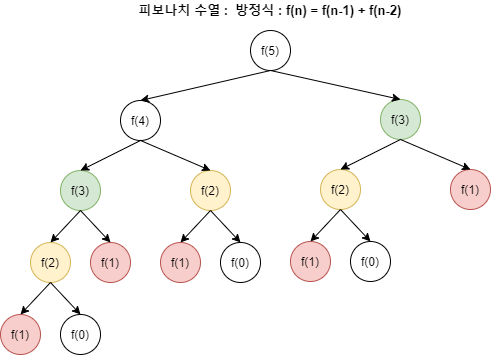
큰 문제를 한 번에 해결하기 힘들 때 작은 문제로 나누어 푸는데, 이 때 이전에 계산한 값을 저장해두었다가 다시 사용한다.큰 문제를 작은 문제로 분할하여 푼다는 점에서 분할정복 알고리즘(ex)합병정렬)과 유사하지만, 한 번 계산했던 값은 저장한다는 점에서 (Memoiz