DL
모호하게 알고 있던 내용들을 부캠강의에서 명료하게 정리해줬다.
당연한 이야기들도 많은데 그냥 다 정리했다.
갖춰야할 능력
- 구현 능력
- 수학 능력(Linear algebra, probability)
- 최신 트렌드의 논문들을 많이 알고 있는 것
정의
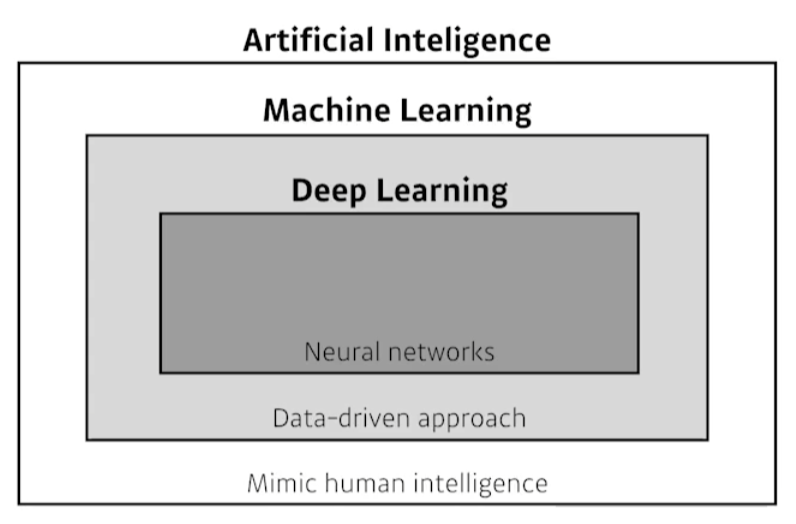
AI = 사람의 지능을 모방하고자 한다
ML = 데이터 기반으로 문제 풀이 접근
DL = 데이터 기반으로 사람의 지능을 모방하고자 할 때, NN을 사용하는 분야
Key components
- Data : the model can learn from
- Model : How to transform the data
- Loss function : that quantifies the badness of the model
- Algorightm : Adjust the parameters to minimize the loss
Data
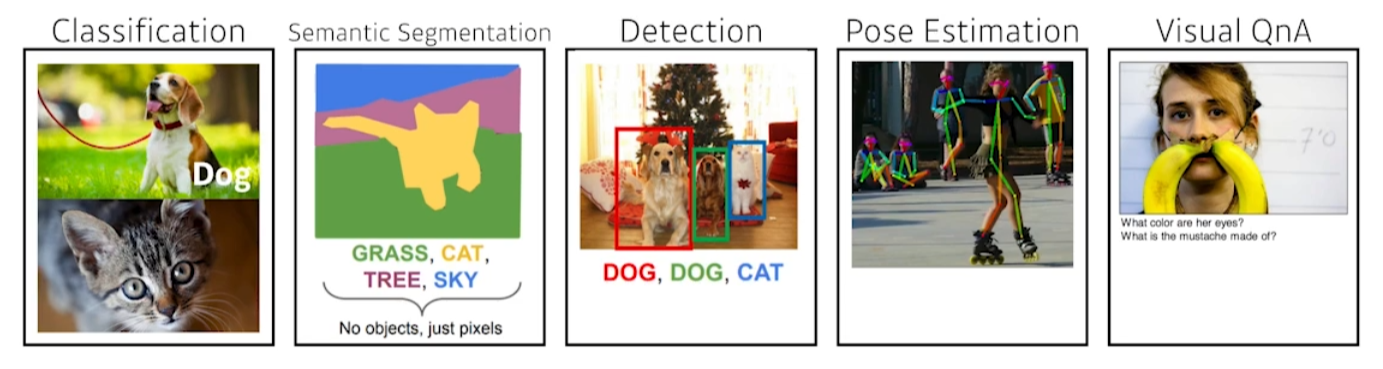
문제의 정의에 따라서 달라진다.
- Classification : 라벨링 데이터
- Semantic segmentation : segmentation data
- Detection : bounding box data
- Pose estimation : skleton data
- Visual QnA : Color data, etc...
Model
문제의 정의에 맞는 모델 필요
Loss function
data와 model이 정해져있을 때, 문제의 정의에 따라 이를 어떻게 학습할지 정의.
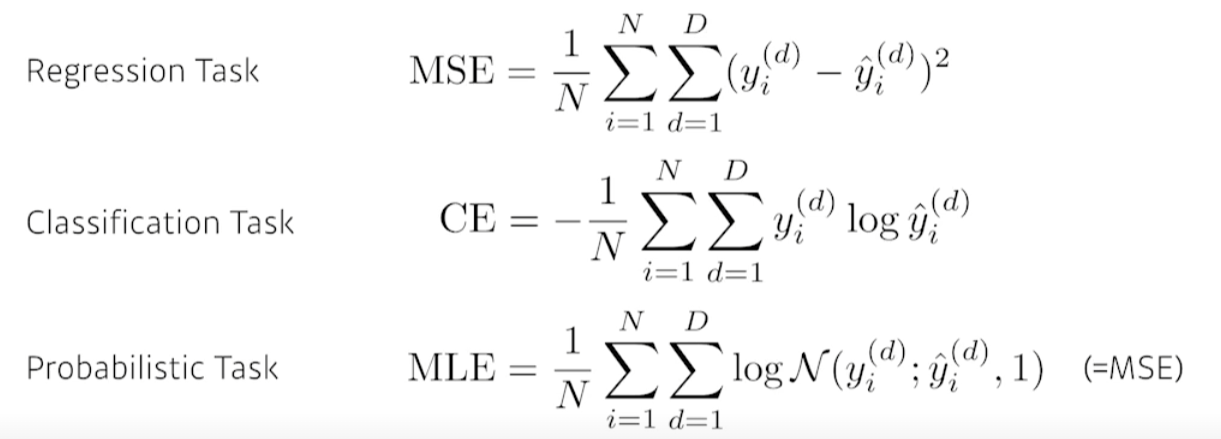
Loss function이 정상적으로 작동한다고 할지라도, 원하는 결과를 뱉을거란 보장은 없다.
가령, 회귀문제라 할지라도 노이즈 굉장히 많이 낀 데이터를 사용한다고 해보자.
그러면 outlier는 MSE의 제곱에 의해 굉장히 커질 것이다.
이런 문제를 방지하기 위해 MSE에서 제곱 대신 절대값을 사용하거나 아예 다른 loss function을 사용하는 것을 고려할 수 있다.
따라서 문제와 데이터에 따라 적절하게 정의해주자.
Optimization algorithm
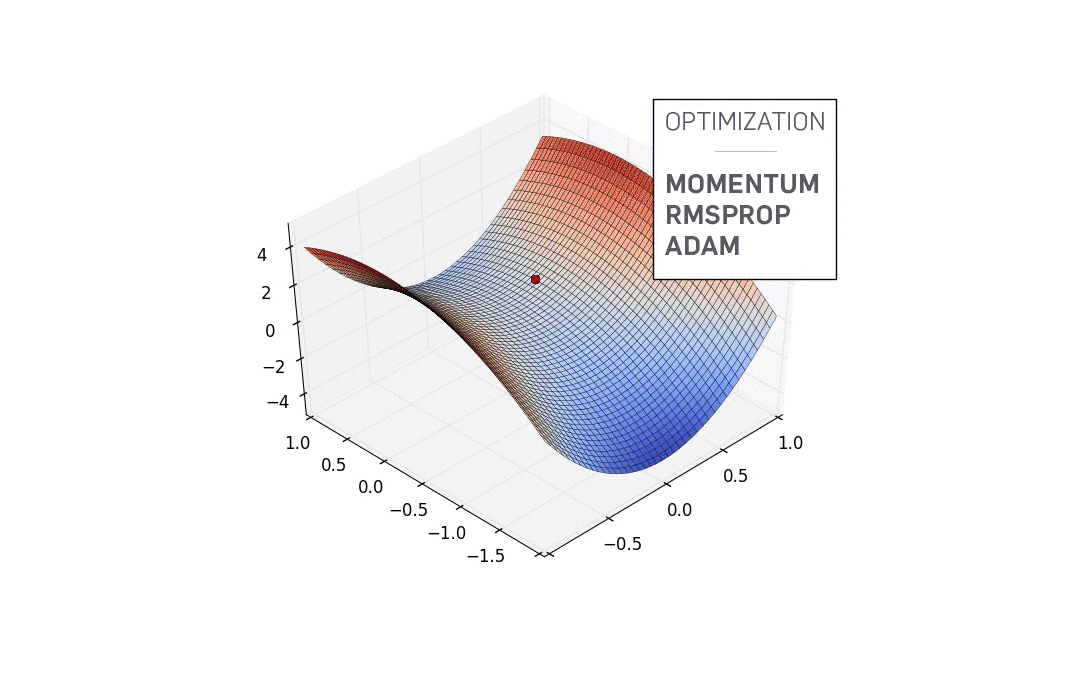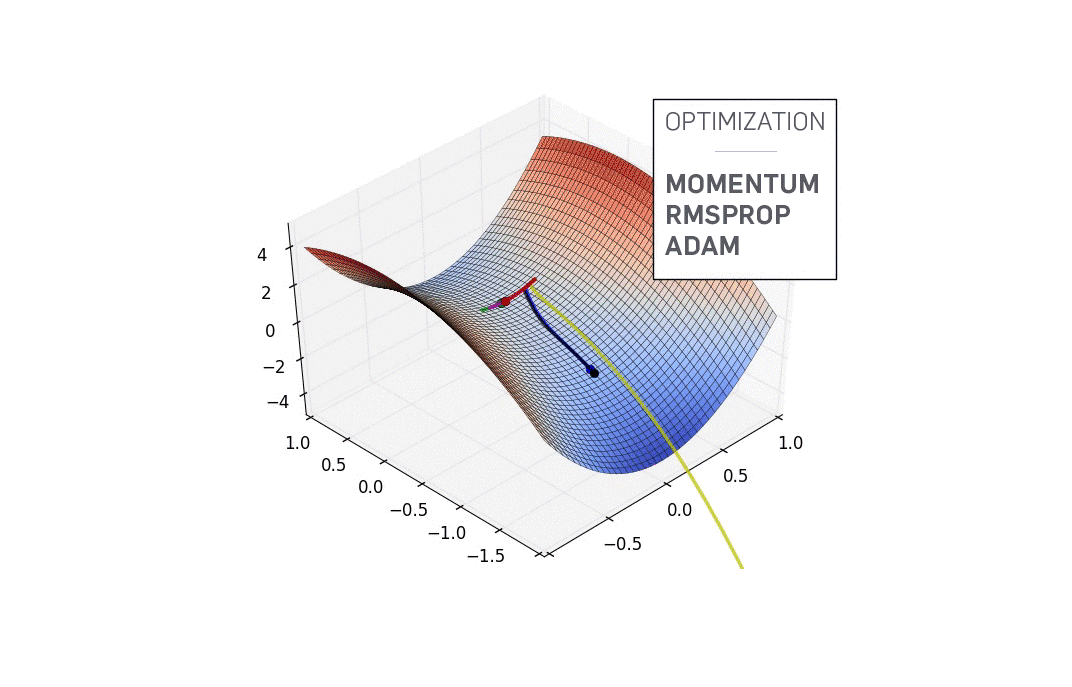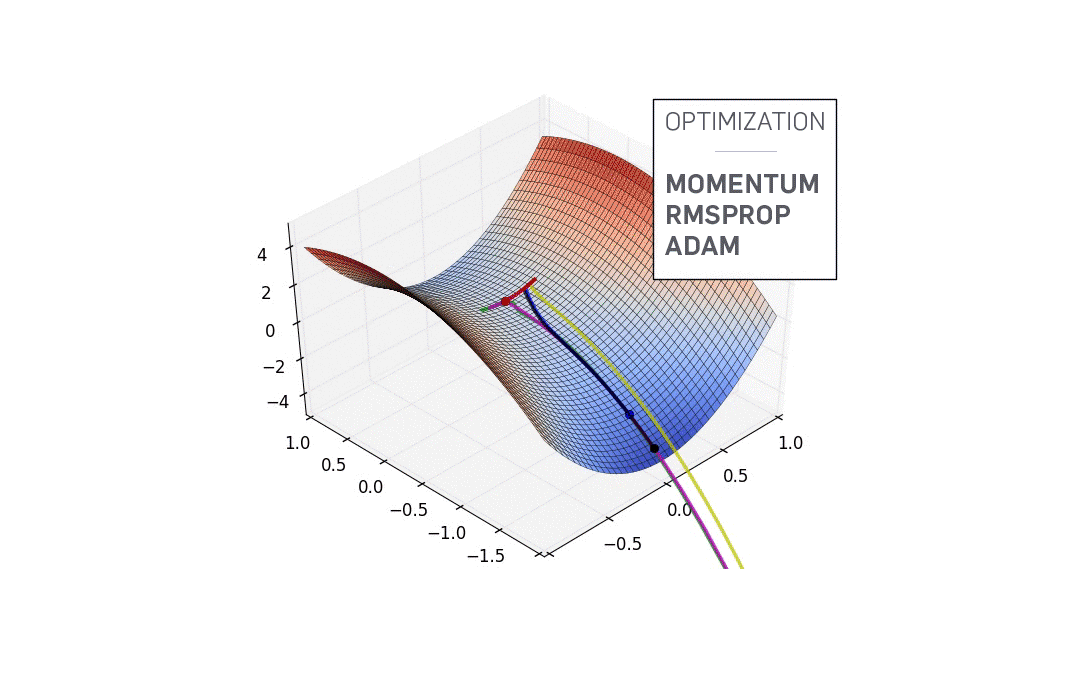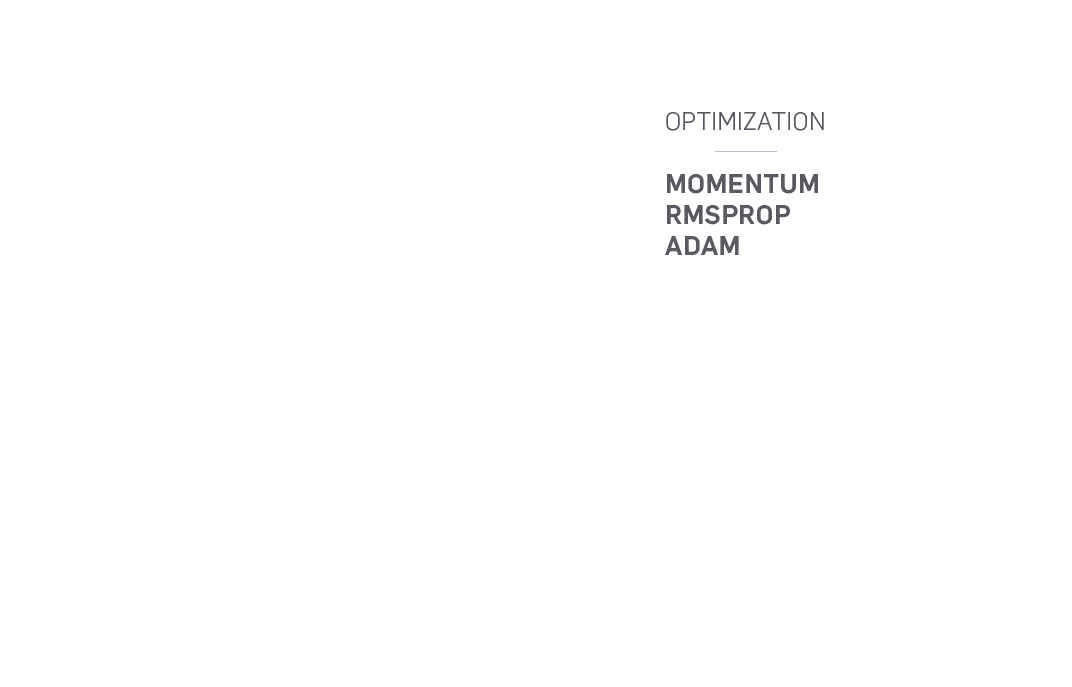
Loss function을 최적화시켜주는 방법들.
보통 NN의 parameter를 loss function에 대해 1차 미분한 정보를 활용하는데, 이를 그냥 활용하는 것이 SGD.
실제로 SGD는 잘 안 쓰이고 나머지 것들이 쓰인다.
그 외에도 다음과 같은 기법들이 쓰인다.
- Dropout
- Early stopping
- k-fold validation
- weigth decay
- batch normalization
- MixUp
- Ensemble
- Bayesian Optimization
History of DL
AlexNet(2012)
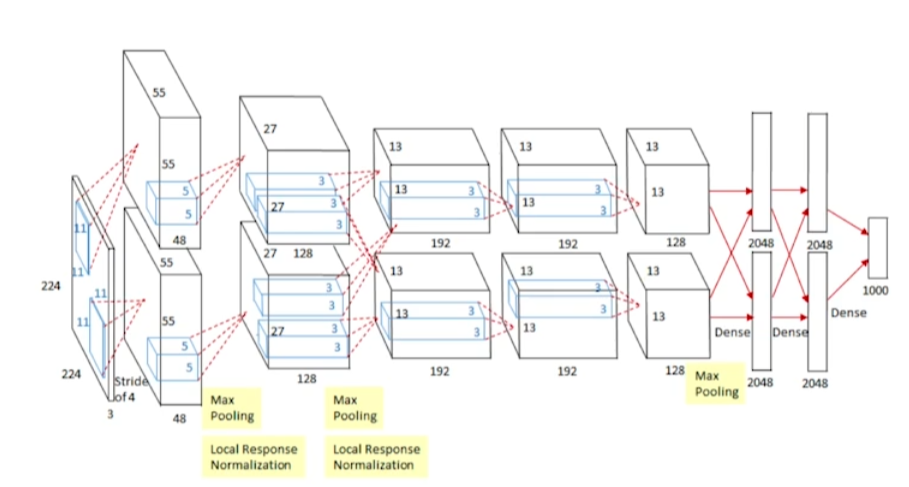
- CNN
- 최초로 DL을 사용해 ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 우승
- 이후의 모든 ILSVRC 회차에서는 DL이 우승했다.
- 이 시점을 기점으로 판도가 바뀐거다.
DQN(2013)
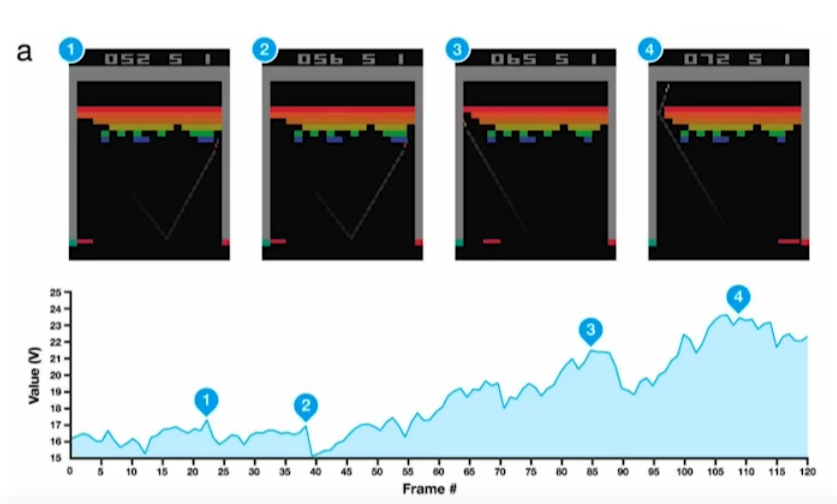
- Atari 게임을 강화학습으로 풀게한 DL
- DeepMind가 개발
- 알파고에 사용된 알고리즘
Encoder/Decoder(2014)
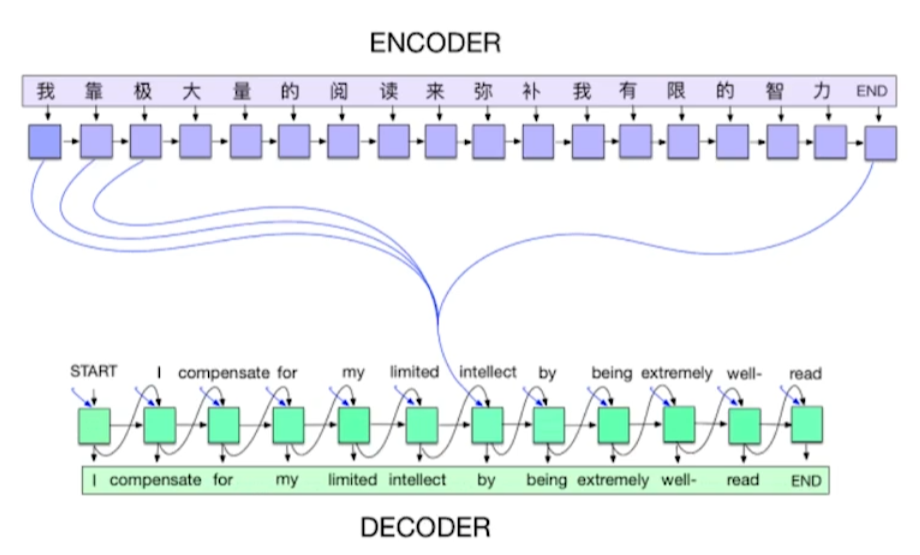
- NMT(Neural machine translation) 개발을 위해 개발
- sequence to sequence model
- 이 시점을 기준으로 NMT가 바뀜.
Adam Optimizer(2014)
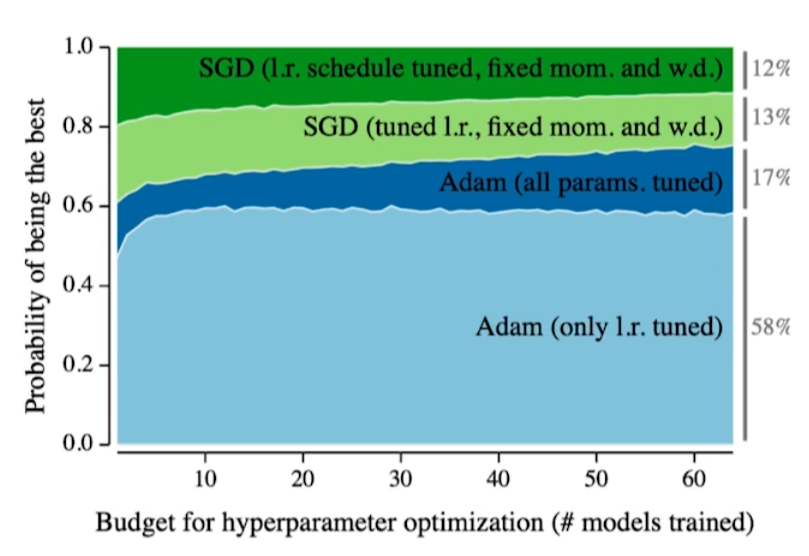
보통 논문들은 다양한 learning schedule을 통해 구현된다.
learning rate를 epoch마다 바꾼다던지, SGD를 사용한다던지 등등...
이러한 방법론들을 보통 매우 큰 컴퓨팅 리소스를 요구한다.
가령, 대기업이 TPU를 1000개를 보유하고 있다고 할 때, 해당 기업은 한번에 1000개의 configuration을 돌려볼 수 있다. 학생들은 보통 GPU를 많아야 1, 2개 가지고 있는데 대기업 역량의 논문을 쓰고자 한다면 1년이 넘어갈 수도 있다.
이 때, Adam은 대부분의 방법론에서 매우 잘 작동한다. 즉, 많은 configuration을 실험해야 하는 의무를 어느 정도 벗어주게 한 것이다.
GAN(Generative Adversarial Network, 2015)

기존의 이미지들을 사용해, 실제와 같은 이미지를 생성하는 DL.
연구자가 술집에서 술 먹다가 아이디어가 떠올랐다고 한다...
Residual Networks(ResNet, 2015)
DL을 DL이라고 불리게 해준 연구. NN을 굉장히 깊게 쌓은 논문.
이전에는 깊은 layer를 구성하지 않았다. 왜냐하면 학습 데이터는 잘 학습될지라도 테스트 데이터를 사용하면 성능이 별로였다.
ResNet 이후에는 깊은 layer를 쌓기 시작했다. 물론 1000 layer와 같은 구성방식은 여전히 안되고 비효율적이다. 하지만 이전에는 20 layer 밖에 쌓지 못했던 것을 100 layer로 쌓게 해주는 것과 같은 성과를 보여줬다.
Transformer(2017)
"Atten is All You Need"라는 제목의 논문.
당시에는, 해당 분야에서만 잘 작동하는 것이라 생각됐지만 현재는 거의 모든 분야의 RNN을 대체했다. CV까지 넘보는 중.
BERT(fine-tuned NLP models, 2018)
Bidirectional Encoder Representations from Transformers.
- fine-tuned NLP models
- 커다랗고 범용적인 학습데이터를 활용해 pre training을 한다.
- 원하고자 하는 범주에 대해서 fine-tuning을 한다.
BIG Language Models(GPT-X, 2019)
- 약간의 fine-tuning을 통해 원하는 데이터 구성.
- 굉장히 많은 parameter로 구성(175billion)
Self Supervised Learning(2020)
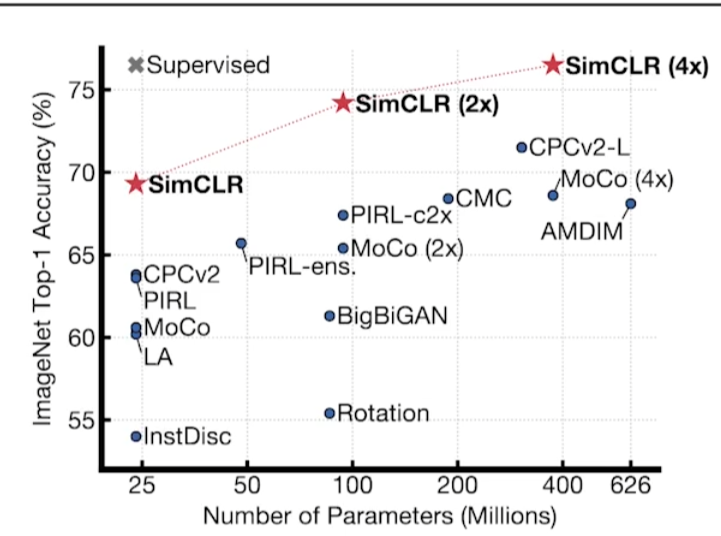
- 대표적으로 SimCLR과 같은 논문
- 라벨을 모르는 데이터를 활용하겠다.
- unsueprvised learning을 활용해, 학습 데이터 외에서도 좋은 representation을 얻겠다.
- self supervised data sampling
- 정의된 문제에 대한 고도의 도메인 지식이 있을 때, 학습 데이터를 스스로 만드는 방법론
