
첫번째 성과
첫번째 스터디 기간이 끝나고 스터디 진행 과정과 회고에 대한 발표를 진행했다.
PPT 제작과 발표는 내가 맡았다.다른 교육생들한테는 우수 스터디로 선발되면 치킨 기프티콘을 받을 수 있기 때문에
이 악물고 준비한다고 했지만, 사실은 치킨보다 1등이 목적이었다.
발표를 무사히 마치고 우수팀 투표를 기다렸다.
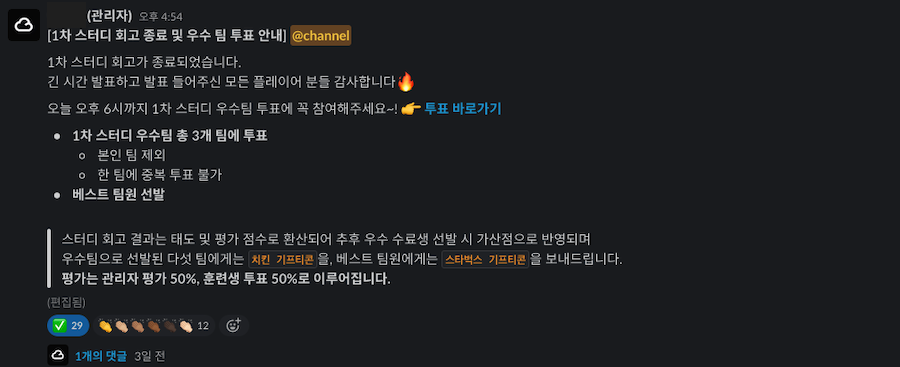
우수 스터디 선발, 그리고 1위
감사하게도 훈련생 투표, 관리자 평가에서 모두 1위를 하게 되어
16개의 스터디 팀 중 1위를 하게 되었다.스터디 시작 당시부터 성과를 수치하고 결과물을 만들어 내려고 계획했고
이 전략이 통했던게 아닌가 싶다.수치화와 결과물 산출의 중요성을 실제로 체감하는 순간이었다.
우리 스터디가 주제로 정했던 것은 알고리즘 문제풀이와 CS 공부였다.
초기에 목표했던 것은 두가지가 있는데
첫 번째는 백준 실버 1~2 문제를 30분 안에 풀 수 있도록 역량을 증가시키기,
두 번째는 각자 CS 공부한 내용을 모아 CS 문서 만들기였다.
첫번째 목표를 달성했는지 알기위해서 모든 문제의 풀이시간을 기록했다.
단 각 문제당 최대 풀이시간을 2시간으로 제한했다.이유는 2시간이 넘어도 풀지 못한다면 풀이를 보는게 더 시간적으로 효율적이라고 생각했기 때문이다.
결과는 우리 팀원 모두가 이 목표를 달성하지 못했다.
하지만, 이후에 성장했을 때
지금보다 얼마나 더 성장했는지 알 수 있는 기준점을 얻어냈다는 것에 대해 의의를 뒀다.

두번째 목표는 팀원 모두가 성실하게 공부해서 모두가 목표에 달성했다.
팀원 3명 중 나를 제외한 2명은 노션에 문서를 만들었고
나는 Velog에 포스팅한 글을 시리즈(자료구조, 운영체제, 네트워크)로 모아 결과물로 제출했다.한달 간의 스터디 기간 동안 공부한 내용은 다음과 같다.

발표 중에 CS 스터디를 하면서 있었던 갈등, 토론 과정에 대해 살짝 언급했다.
대본 중 일부 이다.
저희 팀 모두 최선을 다해서 공부했던 것 같습니다.
그래서 각자,
공부해온 개념에 대해 자신이 있었고 이에 따른 의견의 불일치도 존재했습니다.정말 많이 투닥투닥거렸던 것 같은데요
지금 보시는 내용은 있었던 토론 중 하나입니다.
이런 일이 여러 번 있었는데
이때마다 저희는 어떤 자료에서 해당 개념을 습득했는지 공유하고
그 자료가 신빙성 있는지 구글링을 통해 같이 검토했습니다.또한 추가적으로 교육팀에서 지원해준 CHATGPT+ 와 혼공컴운 책을 사용하기도 했습니다.
토론 끝에 저희는 외부단편화의 개념을 다음과 같이 수렴했습니다.
이러한 몇번의 과정들을 통해
블로그 글 처럼 인터넷에 존재하는 내용은 100% 옳지 않을 수 있으며
이 글이 사실인지 아닌지 검증할 필요가 있다는 것을 모두가 깨닫게 되었습니다.
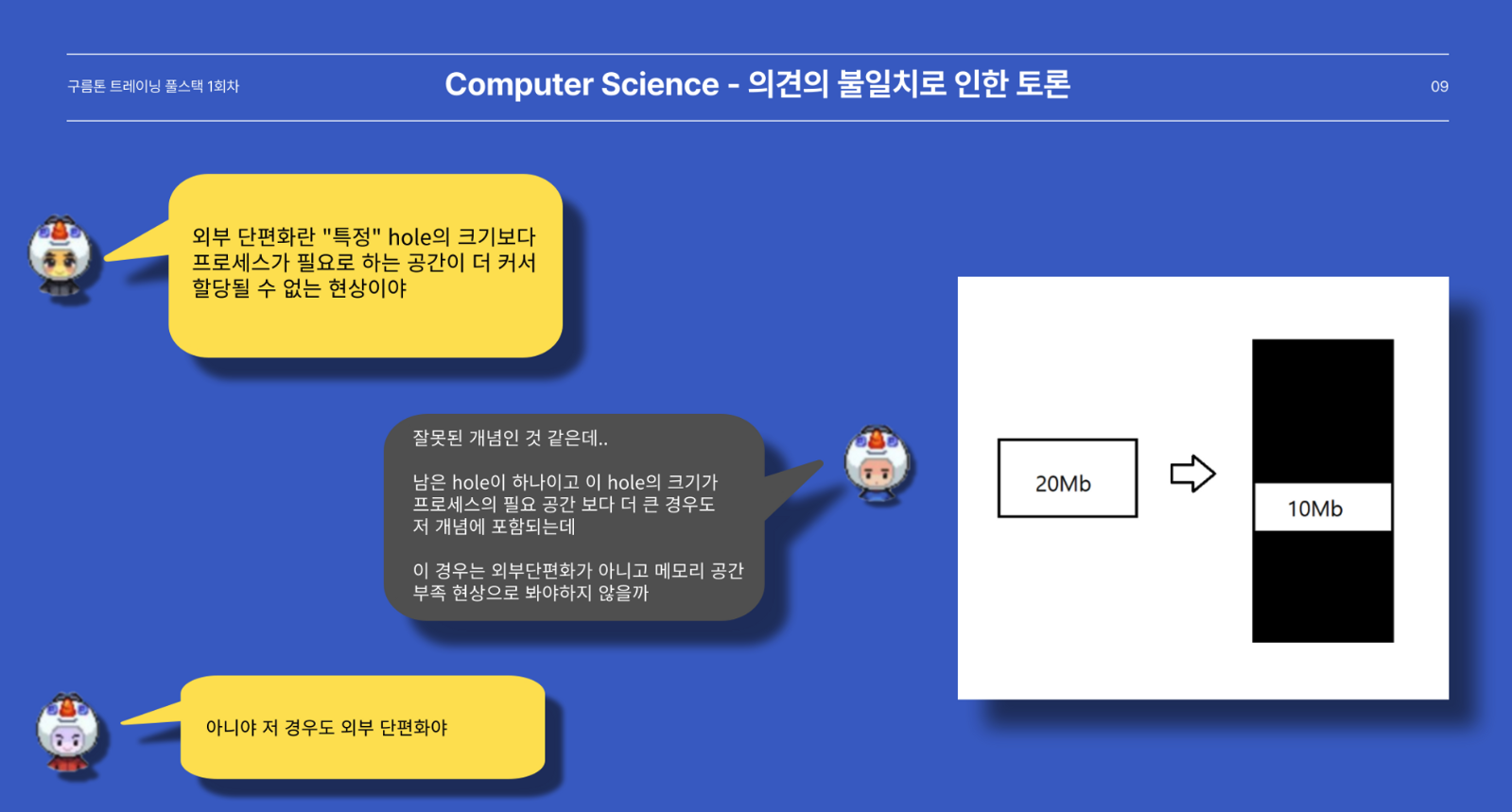

사소할 순 있겠지만 스터디를 하면서 있던 갈등 상황과
우리만의 해결법, 그리고 이러한 갈등속에서 느낀점을
발표에 포함시킨 것도 1위를 할 수 있었던 요소 중에 하나가 아닐까 싶다.
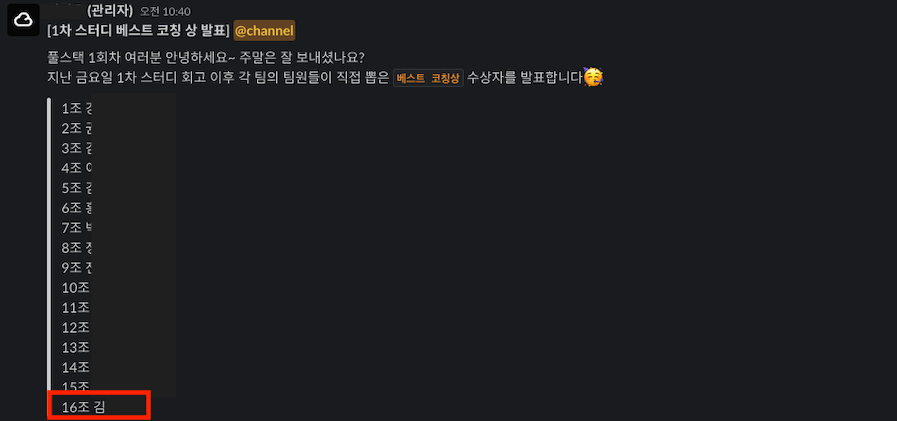
스터디 베스트 팀원상
스터디 1위에 이어 스터디 베스트 팀원상도 받게 되었다.
CS 스터디를 할 때 의문점들이 계속 생겨서 폭풍 질문을 했다.
어떻게 보면 귀찮았을 수도 있는데 우리 팀원들은 내 의문에 대해
같이 의문을 가져주었고 같이 해결해주려고 노력했다.이 점이 사실 감사하다.
스터디가 끝나고 내가 질문을 너무 많이해서 힘들지 않았냐고 물어보니
오히려, 더 깊게 공부할 수 있었고
내가 공부해온 지식을 다시한번 정리하는 시간이 되어서
좋았다고 피드백 받았다.
팀원들을 잘 만난 운이 아닐까 싶다.. 감사합니다...
새로운 팀원
2차 스터디는 약 두 달간 진행된다고 한다.
다음 스터디를 계획하던 중 발표를 듣고 감명받았다며 세 분이 찾아오셨고
스터디에 받아줄 수 없겠냐고 하셨다.얘기를 나눠보니 열정이 있는 분들이셨고 함께하면 좋을 것 같다는 생각이 들어서
함께 하기로 했다.
운좋게도(?) 나를 포함한 기존 팀원들은 모두 프론트엔드를 우선적으로 공부하고 있었는데
이 세 분은 모두 백엔드를 우선적으로 공부하시는 분들이었다.그래서 이후에 있을 기업 연계 프로젝트까지 함께하기로 했다.
기존 스터디 주제에서 추가적으로 미리 세미 프로젝트를 진행하기로 했다.
이때 세워진 규칙과 컨벤션들을 기업 연계프로젝트에서도 사용하여
작업의 효율성을 높이려 한다.
공부하면서 어려웠던 점
[구름톤 트레이닝 풀스택 1기] 4주차 회고 - 적응 의 일부이다.
어렵지만 조금씩이라도 실천하고자 작성한다.

내가 요새 가장 많이하는 말 은 "왜..?" 인 것 같다.
내가 "왜 그렇게되지..?" 라고 질문하면 사람들은 말한다.
그냥 그런건데 뭘 이해하려고 하냐..?1+1 이 2 인거에 대해 "왜"라는 질문을 던지지 말라는 것 처럼..
나도 안다..
근데 정확하게 설명할 수 없는.. 알아야만 할 것 같은 그런 느낌??
이런 미묘한 의문과 호기심에 꽂히는 순간들이 많다..모두가 시간 낭비라고 할 수 있는데
궁금한 걸 어떡합니까.. 이 악물고 알아내야지
React useState에서 이전 값을 사용하려면 왜 화살표 함수를 파라미터로 넣어야하는가
위에서 설명했던 설명할 수 없는.. 호기심
쓸때없는 것 같은데 미묘하게 알아야할 것 같고 궁금한 그런 의문이
이런 의문이다.
이전 값 사용하려면 화살표함수를 사용해야합니다왜?!!!!!!!!!!!
왜써야되는데??????? ..ㅎㅎ이런 의문을 해결하기 위해 세웠던 하루 계획을 최대한 빨리 끝내고 알아봤다.
[React] useState 에서 이전 값을 사용하는 방법
100% 완벽하게 이해하진 못했다..
저기까지 알아내는데 많은 시간이 소요됐다..
그리고 타입스크립트에 대한 역량이 부족해서 조금 더 성장한뒤에 다시 보려고 한다.이에 대해서 존 안 코치님께 멘토링을 다녀왔는데
내부 코드에 대해서 조사할때 구 버전의 모듈을 열어서 보는게 조금 더 자세한 내용이 나와있을 거라고 해주셨다.역량 증진 후 반드시 다시 조사해볼 예정이다.
이게 된다면 useEffect에 의존성 배열에 State가 아닌 객체가 있을 때
그 객체의 프로퍼티를 변경해도 useEffect가 실행되는 이유에 대해서도 조사해볼 예정이다.
그래프 문제에서 모든 노드를 탐색할 땐 DFS 보다 BFS
그래프 순회가 필요한 문제에서 모든 노드를 탐색할 때는 DFS, BFS 모두 사용할 수 있다.
팀원 3명 중 나를 포함한 2명은 Recursion DFS로 노드를 순회했고
1명은 BFS로 순회해서 문제를 풀었는데Recursion DFS로 풀면 시간초과 가 발생했다.
시간 복잡도는 두 알고리즘 모두 동일한데 왜 그런지에 대해 궁금해 조사를 하기 시작했다.
도중에 대화를 자주해서 친분이 생겼던 쿠버네티스 코치님이
우리 대화를 엿듣고(?) 계셔서 달려가서 여쭤봤다.
조사한 게 맞았다.
재귀함수를 사용하면 메모리에 함수가 할당되고 해제되는 과정에서 오버헤드가 발생한다.
그렇기 때문에 실제로 더 많은 시간이 요구된다는 것이었다.완전히 같게 만들려면 Queue를 사용한 DFS를 해야한다는 것이었다.
Python의 경우 일반 배열을 Queue 처럼 사용할 수 있는데
이 경우 시간 복잡도는 동일해지지만 Python의 배열은 동적 Array 이기 때문에
공간 복잡도에서 차이가 날 것이다.동적 Array는 공간이 꽉 찼을때 새로운 값이 들어오면 기존 크기의 2배로 증가한다.
