DataFrame
-
판다스는
Series외에도DataFrame이라는 객체를 사용한다.
DataFrame은 표table와 같은 자료형이다. -
Series와dict은 각각 1개의 키/인덱스 컬럼과 1개의 값 컬럼을 지원하지만,
DataFrame객체는 여러 개의 컬럼을 지원하므로 csv, excel 파일 등을 표현할 수 있다.
# Series
data = {'Region' : ['Korea', 'America', 'Chaina', 'Canada', 'Italy'],
'Sales' : [300, 200, 500, 150, 50],
'Amount' : [90, 80, 100, 30, 10],
'Employee' : [20, 10, 30, 5, 3]
}
s = pd.Series(data)
s
>>> Region [Korea, America, Chaina, Canada, Italy]
Sales [300, 200, 500, 150, 50]
Amount [90, 80, 100, 30, 10]
Employee [20, 10, 30, 5, 3]
dtype: object
# DataFrame
d = pd.DataFrame(data)
d
>>> Region Sales Amount Employee
0 Korea 300 90 20
1 America 200 80 10
2 Chaina 500 100 30
3 Canada 150 30 5
4 Italy 50 10 3-
기본적으로
Series객체는 값이 많더라도 1차원 배열 형태로 표현한다.
반면DataFrame은 인덱스와 컬럼을 따로 지정할 수 있다. -
Series의name은 Dataframe의 컬럼명에 해당한다.
d.columns
>>> Index(['Region', 'Sales', 'Amount', 'Employee'], dtype='object')
d.index
>>> RangeIndex(start=0, stop=5, step=1)
d.index=['one','two','three','four','five']
d.columns = ['a','b','c','d']
d
>>> a b c d
one Korea 300 90 20
two America 200 80 10
three Chaina 500 100 30
four Canada 150 30 5
five Italy 50 10 3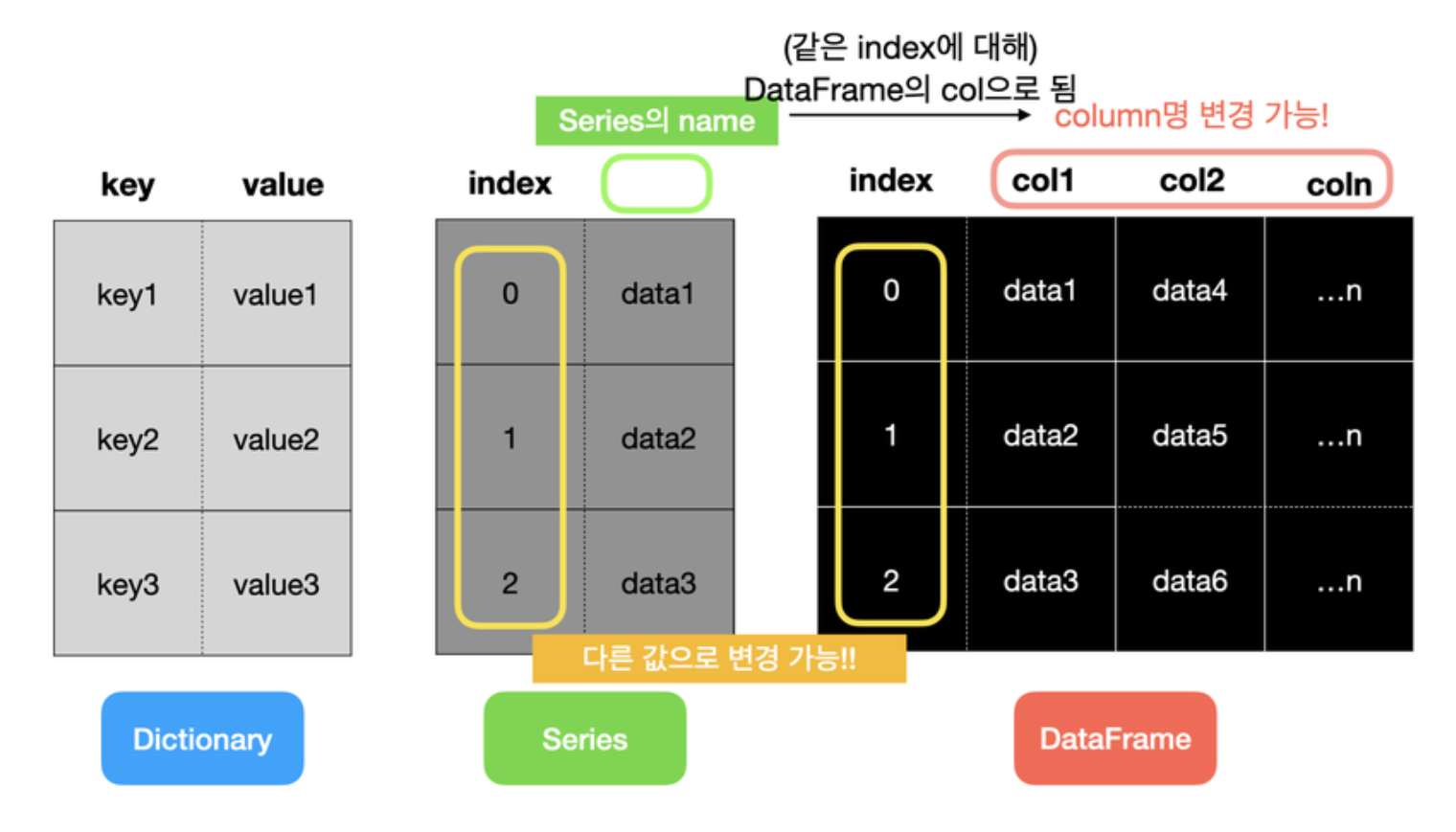

재미있게 살고 싶은 대학원생