Exploratory Data Analysis
-
탐색적 자료 분석, 줄여서 EDA라고 부른다.
데이터를 활용하기 위해 필요한 전반적인 데이터 탐색 및 분석 과정을 일컫는다. -
신경망 튜닝보다 효율적인 EDA에 기반한 데이터 전처리가 훨씬 효과적일 때가 많다.
데이터 불러오기
데이터 출처 - 관세청 수출입 무역 통계
https://unipass.customs.go.kr/ets/index.do
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
csv_file_path = os.getenv('HOME')+'/aiffel/data_preprocess/data/trade.csv'
trade = pd.read_csv(csv_file_path)결측치 Null 처리
- 현실의 데이터는 결측치를 거의 반드시 포함한다.
- 결측치는 크게 1) 제거하거나, 2) 다른 값으로 대체하는 방법이 있다.
print('전체 데이터 건수:', len(trade))
>>> 전체 데이터 건수: 199
# 결측치 확인
print('컬럼별 결측치 개수')
len(trade) - trade.count()
>>> 컬럼별 결측치 개수
기간 0
국가명 0
수출건수 3
수출금액 4
수입건수 3
수입금액 3
무역수지 4
기타사항 199
dtype: int64- 위 데이터에서는
기타사항컬럼이 전부 결측치로 되어 있다.
# 결측치 컬럼 제거
trade = trade.drop('기타사항', axis=1)
# 잘 제거됐는지 확인
trade.isnull().sum()
>>> 기간 0
국가명 0
수출건수 3
수출금액 4
수입건수 3
수입금액 3
무역수지 4
dtype: int64
# .any() 메소드를 사용해 데이터를 다시 대입하면 값이 True인 데이터만 추출한다.
trade[trade.isnull().any(axis=1)]
>>> 기간 국가명 수출건수 수출금액 수입건수 수입금액 무역수지
191 2020년 04월 미국 105360.0 NaN 1141118.0 5038739.0 NaN
196 2020년 06월 중국 NaN NaN NaN NaN NaN
197 2020년 06월 미국 NaN NaN NaN NaN NaN
198 2020년 06월 일본 NaN NaN NaN NaN NaN- 196, 197, 198행은 삭제하고 191행 데이터는 특정 값으로 대체한다.
# 행 삭제
trade.dropna(how='all', subset=['수출건수', '수출금액', '수입건수', '수입금액', '무역수지'], inplace=True)
# 데이터 대체
# 수출값 = (이전달 + 다음달)/2
trade.loc[191, '수출금액'] = (trade.loc[188, '수출금액'] + trade.loc[194, '수출금액'] )/2
# 무역수지 = 수출금액 - 수입금액
trade.loc[191, '무역수지'] = trade.loc[191, '수출금액'] - trade.loc[191, '수입금액']
trade.loc[191]
>>> 기간 국가명 수출건수 수출금액 수입건수 수입금액 무역수지
191 2020년 04월 미국 105360.0 5946782.0 1141118.0 5038739.0 908043.0중복 데이터 처리
- 데이터가 행 별로 유일(unique)해야 한다면 중복된 데이터를 제거해야 한다.
# df.duplicate()는 데이터 중복 여부를 불리언 값으로 반환함
trade.duplicated()
# 두 행이 중복
trade[(trade['기간']=='2020년 03월')&(trade['국가명']=='중국')]
>>> 기간 국가명 수출건수 수출금액 수입건수 수입금액 무역수지
186 2020년 03월 중국 248059.0 10658599.0 358234.0 8948918.0 1709682.0
187 2020년 03월 중국 248059.0 10658599.0 358234.0 8948918.0 1709682.0
# 중복 제거
trade.drop_duplicates(inplace=True)이상치 Outlier 처리
-
이상치
outlier는 지나치게 크거나 작아서 분석에 악영향을 끼치는 데이터이다. -
이상치 판별 기준으로는
z score또는IQR method를 자주 사용한다. -
이상치 처리 방법에는 크게 1) 제거, 2) 대체, 3) 예측, 4) 변환이 있다.
# 기준값(z) 이하의 데이터만 추출
def not_outlier(df, col, z):
return df[abs(df[col] - np.mean(df[col]))/np.std(df[col]) <= z].index
trade.loc[not_outlier(trade, '무역수지', 1.5)]
>>> 기간 국가명 수출건수 수출금액 수입건수 수입금액 무역수지
0 2015년 01월 중국 116932.0 12083947.0 334522.0 8143271.0 3940676.0
1 2015년 01월 미국 65888.0 5561545.0 509564.0 3625062.0 1936484.0
2 2015년 01월 일본 54017.0 2251307.0 82480.0 3827247.0 -1575940.0
3 2015년 02월 중국 86228.0 9927642.0 209100.0 6980874.0 2946768.0
4 2015년 02월 미국 60225.0 5021264.0 428678.0 2998216.0 2023048.0
... ... ... ... ... ... ... ...
191 2020년 04월 미국 105360.0 5946782.0 1141118.0 5038739.0 908043.0
192 2020년 04월 일본 134118.0 1989323.0 141207.0 3989562.0 -2000239.0
193 2020년 05월 중국 185320.0 10746069.0 349007.0 8989920.0 1756149.0
194 2020년 05월 미국 126598.0 4600726.0 1157163.0 4286873.0 313853.0
195 2020년 05월 일본 166568.0 1798128.0 133763.0 3102734.0 -1304606.0- IQR은 다음 코드와 같이 사용할 수 있다.
def outlier2(df, col):
q1 = df[col].quantile(0.25)
q3 = df[col].quantile(0.75)
iqr = q3 - q1
return df[(df[col] < q1-1.5*iqr)|(df[col] > q3+1.5*iqr)]
outlier2(trade, '무역수지')정규화
- 단위가 다른 데이터들을 학습 데이터로 사용하는 경우 정규화를 해 줘야 한다.
- 이 경우 당연히 테스트 데이터도 같은 방식으로 정규화해야 한다.
standardization과min-max scaling,로그 변환등을 자주 사용한다.
# Standardization
cols = ['수출건수', '수출금액', '수입건수', '수입금액', '무역수지']
trade_Standardization= (trade[cols]-trade[cols].mean())/trade[cols].std()
# min-max scaling
trade[cols] = (trade[cols]-trade[cols].min())/(trade[cols].max()-trade[cols].min())sklearn에서는StandardScaler,MinMaxScaler를 지원한다.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit_transform(train)
scaler.transform(test)원 핫 인코딩
- 범주형 데이터를 수치형 데이터로 변환할 때 쓴다.
각 범주를 하나의 컬럼으로 변환하고 (0, 1) 값으로 데이터 여부를 판정한다.
# trade 데이터의 국가명 컬럼 원본
print(trade['국가명'].head())
# get_dummies 사용
country = pd.get_dummies(trade['국가명'])
country.head()
>>> 0 중국
1 미국
2 일본
3 중국
4 미국
Name: 국가명, dtype: object
# trade와 country 병합
trade = pd.concat([trade, country], axis=1)
# 변환 완료된 컬럼 삭제
trade.drop(['국가명'], axis=1, inplace=True)구간화 binning
- 다수의 데이터를 구간별로 나눈다.
# 아래와 같은 연봉 데이터가 있다고 가정
salary = pd.Series([4300, 8370, 1750, 3830, 1840, 4220, 3020, 2290, 4740, 4600,
2860, 3400, 4800, 4470, 2440, 4530, 4850, 4850, 4760, 4500,
4640, 3000, 1880, 4880, 2240, 4750, 2750, 2810, 3100, 4290,
1540, 2870, 1780, 4670, 4150, 2010, 3580, 1610, 2930, 4300,
2740, 1680, 3490, 4350, 1680, 6420, 8740, 8980, 9080, 3990,
4960, 3700, 9600, 9330, 5600, 4100, 1770, 8280, 3120, 1950,
4210, 2020, 3820, 3170, 6330, 2570, 6940, 8610, 5060, 6370,
9080, 3760, 8060, 2500, 4660, 1770, 9220, 3380, 2490, 3450,
1960, 7210, 5810, 9450, 8910, 3470, 7350, 8410, 7520, 9610,
5150, 2630, 5610, 2750, 7050, 3350, 9450, 7140, 4170, 3090])
# 히스토그램
salary.hist()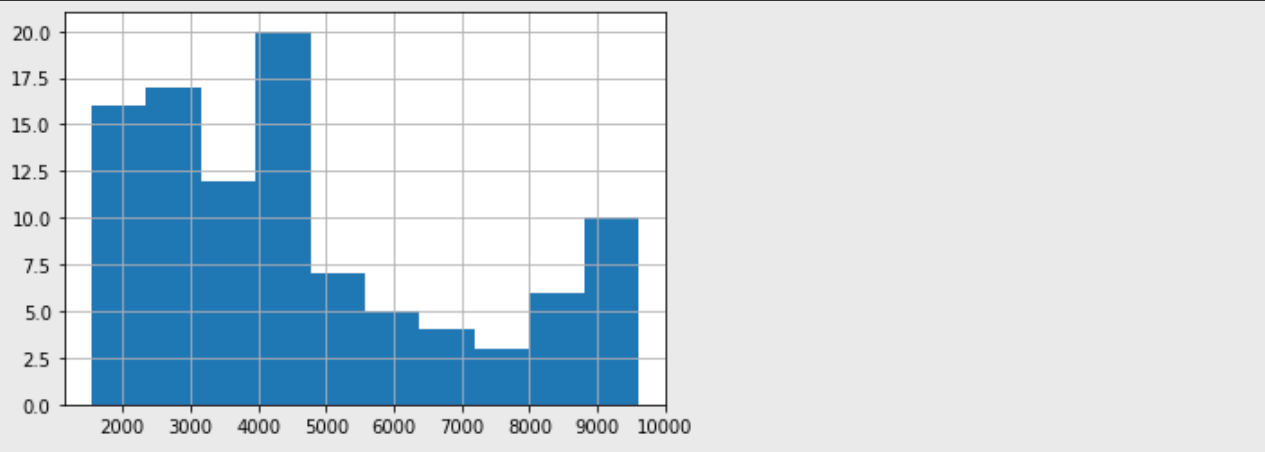
- pandas의
cut기능을 사용하면....
# 범주 지정
bins = [0, 2000, 4000, 6000, 8000, 10000]
ctg = pd.cut(salary, bins=bins)
# 구간당 데이터 수 확인
ctg.value_counts().sort_index()
>>>
(0, 2000] 12
(2000, 4000] 34
(4000, 6000] 29
(6000, 8000] 9
(8000, 10000] 16
dtype: int64
# 범주 지정 대신 개수 지정도 가능
ctg = pd.cut(salary, bins=6)
ctg.value_counts().sort_index()
>>>
(1531.93, 2885.0] 27
(2885.0, 4230.0] 24
(4230.0, 5575.0] 21
(5575.0, 6920.0] 6
(6920.0, 8265.0] 7
(8265.0, 9610.0] 15
dtype: int64qcut기능을 쓰면 비슷한 크기의 그룹으로 나눈다.
ctg = pd.qcut(salary, q=5)
print(ctg.value_counts().sort_index())
>>>
(1539.999, 2618.0] 20
(2618.0, 3544.0] 20
(3544.0, 4648.0] 20
(4648.0, 7068.0] 20
(7068.0, 9610.0] 20
dtype: int64
재미있게 살고 싶은 대학원생