포켓몬 데이터로 피처 엔지니어링 연습하기
이번에 사용할 데이터는 캐글에 올라와 있는 포켓몬 데이터셋이다.
캐글이나 모두의말뭉치같은 데이터 소스들은 데이터에 대한 간략한 설명을 함께 제공한다.
본격적인 분석 전에 이런 정보들을 통해 데이터셋을 이해하는 것은 필수 과정이다.
데이터 가져오기
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import os
csv_path = os.getenv("HOME") +"/aiffel/pokemon_eda/data/Pokemon.csv"
original_data = pd.read_csv(csv_path)
pokemon = original_data.copy()
print(pokemon.shape)
>>> (800, 13)target 데이터는 Legendary 컬럼에 있으므로 따로 추출한다.
# 전설의 포켓몬 데이터셋
legendary = pokemon[pokemon["Legendary"] == True].reset_index(drop=True)
print(legendary.shape)
>>> (65, 13)(1) 결측치 확인
pokemon.isnull().sum()
>>> # 0
Name 0
Type 1 0
Type 2 386
Total 0
HP 0
Attack 0
Defense 0
Sp. Atk 0
Sp. Def 0
Speed 0
Generation 0
Legendary 0
dtype: int64Type2 컬럼에 386개의 결측치가 존재한다.
데이터 설명을 보니 속성을 1개만 가진 포켓몬의 수로 생각된다.
(2) id
# 컬럼은 포켓몬의 id에 해당한다.
# 몇 종류 있는지 확인
len(set(pokemon["#"]))
>>> 721전체 데이터셋에 1대1 매칭이 불가능하므로 인덱스로 쓸 수 없다.
결측치가 없는 컬럼이므로 중복된 id를 갖는 데이터가 있다는 것을 알 수 있다.
(3) Name
len(set(pokemon["Name"]))
>>> 800name 컬럼의 데이터는 중복되지 않으므로(=unique하므로), 인덱스로 사용할 수 있다.
(4) Type 1 & 2
포켓몬들이 갖는 속성은 총 몇 종류일까?
# 각 경우별로 속성 몇 개씩 가졌는지 확인
len(list(set(pokemon["Type 1"]))), len(list(set(pokemon["Type 2"])))
>>> (18, 19)
# 듀얼에 추가된 1개 속성 확인
set(pokemon["Type 2"]) - set(pokemon["Type 1"])
>>> {nan}
# 타입 종류 저장
types = list(set(pokemon["Type 1"]))
print(types)
>>> ['Dark', 'Fighting', 'Dragon', 'Normal', 'Steel', 'Ground', 'Fairy',
'Electric', 'Fire', 'Water', 'Bug', 'Poison', 'Ice', 'Flying', 'Rock', 'Ghost', 'Grass', 'Psychic']정답은 18개이다.
혹시 일반 포켓몬과 전설 포켓몬의 속성 분포는 어떨까?
plt.figure(figsize=(10, 7))
# Type1 컬럼을 기준으로 함
plt.subplot(211)
sns.countplot(data=ordinary, x="Type 1", order=types).set_xlabel('')
plt.title("[Ordinary Pokemons]")
plt.subplot(212)
sns.countplot(data=legendary, x="Type 1", order=types).set_xlabel('')
plt.title("[Legendary Pokemons]")
plt.show()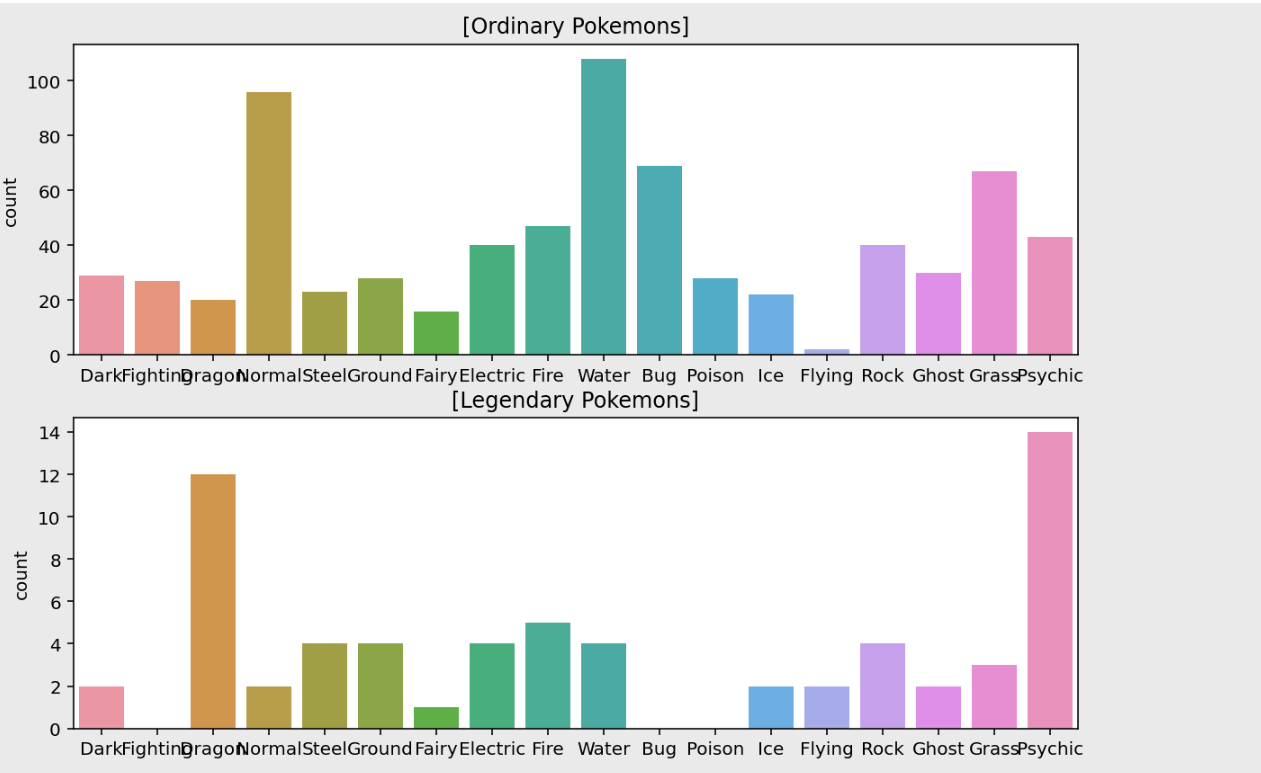
전설 포켓몬 중에는 Bug, Poison, Fighting 속성이 없고, Dragon 속성과 Psychic 속성이 많다. 반대로 일반 포켓몬은 Water 속성과 Normal 속성에 많이 분포해 있다.
그렇다면 Dragon 속성에 전설 포켓몬이 많을까?
확인해보기 전까지는 알 수 없다.
각 속성별로 전설 포켓몬 비율을 나타내면 다음과 같다.
# Type1별로 Legendary 의 비율을 보여주는 피벗 테이블
pd.pivot_table(pokemon, index="Type 1", values="Legendary").sort_values(by=["Legendary"], ascending=False)
>>> Legendary
Type 1
Flying 0.500000
Dragon 0.375000
Psychic 0.245614
Steel 0.148148
Ground 0.125000
Fire 0.096154
Electric 0.090909
Rock 0.090909
Ice 0.083333
Dark 0.064516
Ghost 0.062500
Fairy 0.058824
Grass 0.042857
Water 0.035714
Normal 0.020408
Poison 0.000000
Fighting 0.000000
Bug 0.000000Dragon 이 아니라 Flying 속성에 전설 포켓몬이 가장 많이 분포하는 것을 볼 수 있다.
마찬가지 방법으로 Type2 컬럼을 확인해보자.
plt.figure(figsize=(12, 10))
# countplot은 결측치를 알아서 배제함
plt.subplot(211)
sns.countplot(data=ordinary, x="Type 2", order=types).set_xlabel('')
plt.title("[Ordinary Pokemons]")
plt.subplot(212)
sns.countplot(data=legendary, x="Type 2", order=types).set_xlabel('')
plt.title("[Legendary Pokemons]")
plt.show()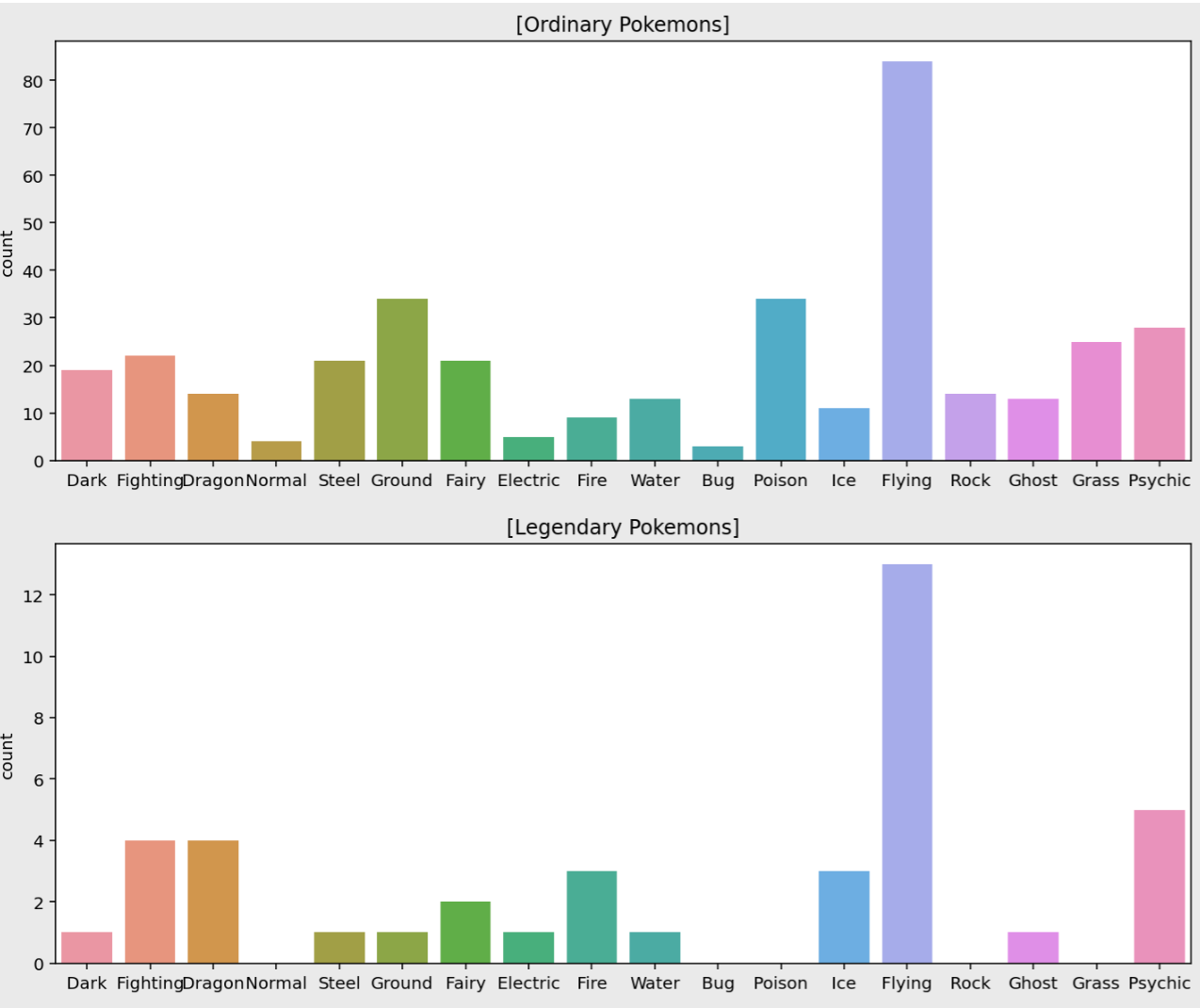
Type2 컬럼은 듀얼 타입 포켓몬 데이터만 사용한다. 따라서 듀얼 타입 포켓몬 대부분은 Flying 속성을 갖는다는 것을 알 수 있다.
그렇다면 Type2 에서도 Flying 속성에 전설 포켓몬이 많이 분포할까?
# Type2별로 Legendary 의 비율을 보여주는 피벗 테이블
pd.pivot_table(pokemon, index="Type 2", values="Legendary").sort_values(by=["Legendary"], ascending=False)
>>> Legendary
Type 2
Fire 0.250000
Dragon 0.222222
Ice 0.214286
Electric 0.166667
Fighting 0.153846
Psychic 0.151515
Flying 0.134021
Fairy 0.086957
Water 0.071429
Ghost 0.071429
Dark 0.050000
Steel 0.045455
Ground 0.028571
Rock 0.000000
Bug 0.000000
Poison 0.000000
Normal 0.000000
Grass 0.000000듀얼 타입 포켓몬 중에는 Fire 속성에 전설 포켓몬이 가장 많이 분포함을 알 수 있다.
(5) Total과 Stats
데이터셋 설명을 보면 각 포켓몬들은 6가지의 스탯을 가지고 있다.
Total 컬럼을 보면 해당 포켓몬이 가진 스탯의 총합을 알 수 있다.
# stats 리스트 생성
stats = ["HP", "Attack", "Defense", "Sp. Atk", "Sp. Def", "Speed"]
# 데이터 검증
sum(pokemon['Total'].values == pokemon[stats].values.sum(axis=1))
>>> 800
# 분포 시각화
fig, ax = plt.subplots()
fig.set_size_inches(12, 6)
sns.scatterplot(data=pokemon, x="Type 1", y="Total", hue="Legendary")
plt.show()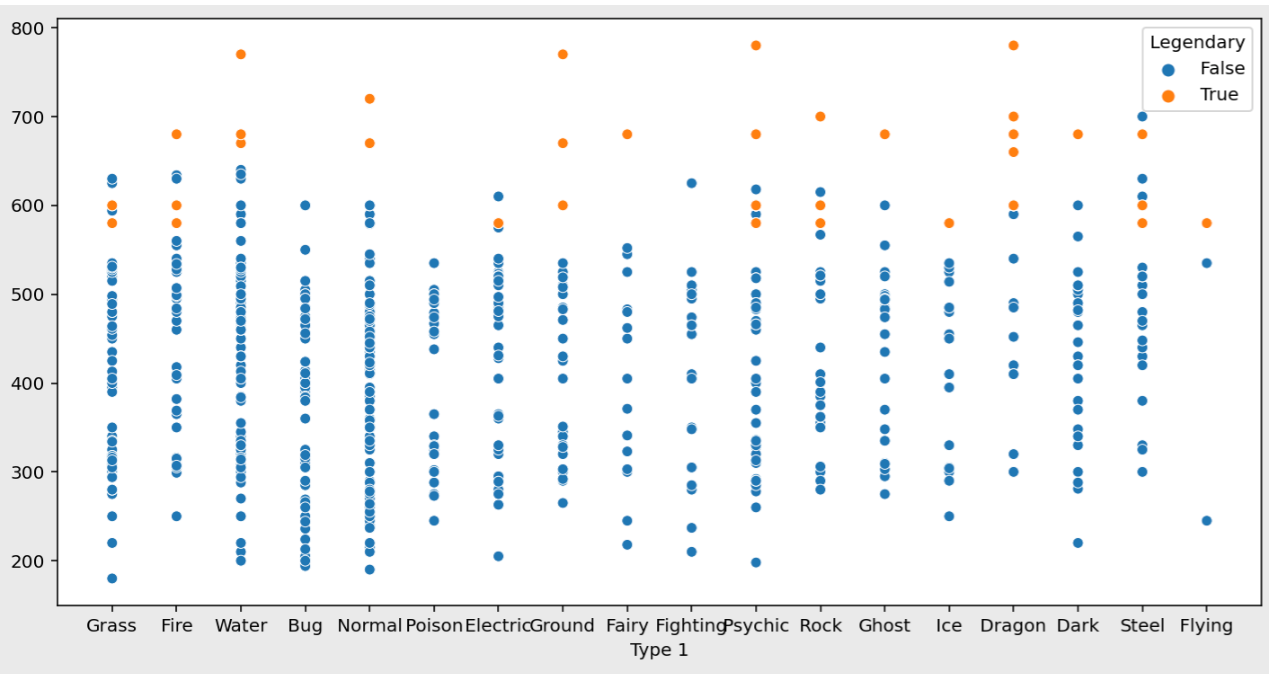
전설 포켓몬들은 (당연하게도) Total 값이 높다.
600점 근방부터는 전설 포켓몬과 일반 포켓몬의 차이가 두드러지는 것을 확인할 수 있다.
그렇다면 개별 스탯도 전설 포켓몬들이 높을까?
아니면 특정 스탯이 특출나게 높을까?
figure, ((ax1, ax2), (ax3, ax4), (ax5, ax6)) = plt.subplots(nrows=3, ncols=2)
figure.set_size_inches(12, 18)
sns.scatterplot(data=pokemon, y="Total", x="HP", hue="Legendary", ax=ax1)
sns.scatterplot(data=pokemon, y="Total", x="Attack", hue="Legendary", ax=ax2)
sns.scatterplot(data=pokemon, y="Total", x="Defense", hue="Legendary", ax=ax3)
sns.scatterplot(data=pokemon, y="Total", x="Sp. Atk", hue="Legendary", ax=ax4)
sns.scatterplot(data=pokemon, y="Total", x="Sp. Def", hue="Legendary", ax=ax5)
sns.scatterplot(data=pokemon, y="Total", x="Speed", hue="Legendary", ax=ax6)
plt.show()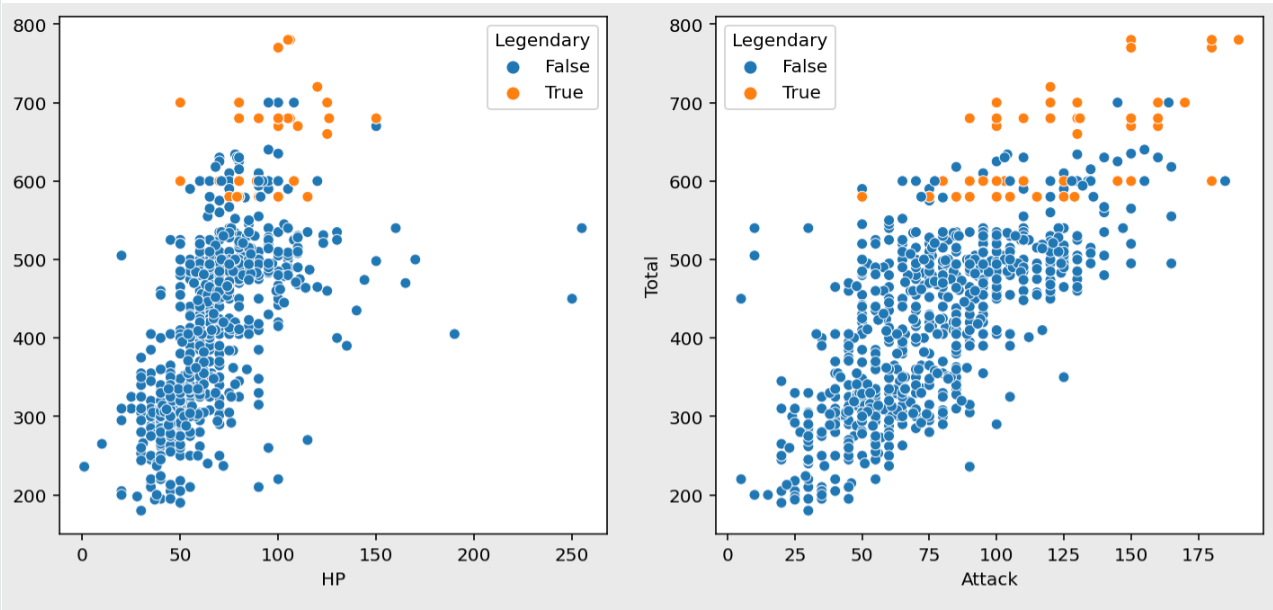
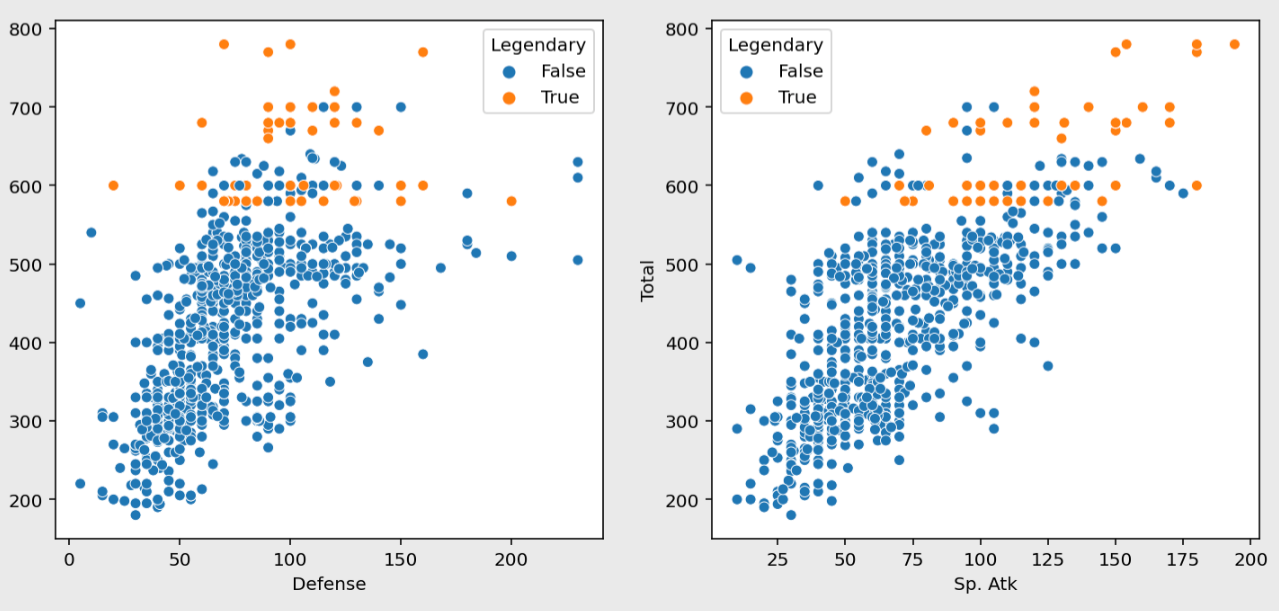
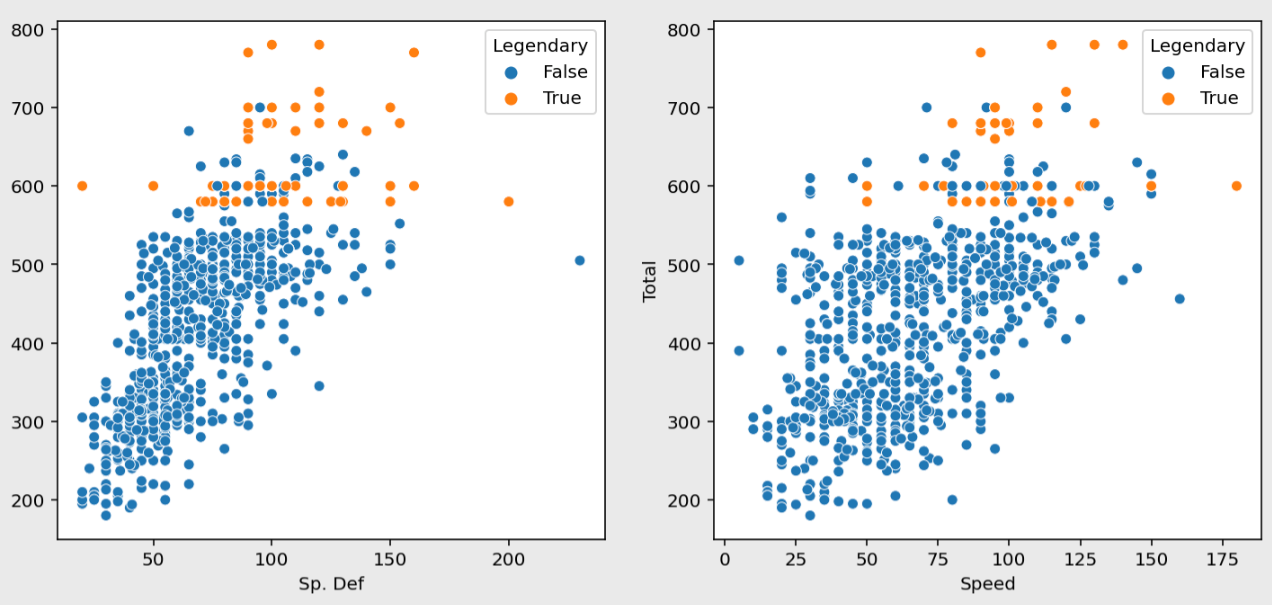
각 스탯별 분포를 보면 대부분 전설 포켓몬이 높은 수치를 갖고 있다는 것을 알 수 있다.
하지만 전설 포켓몬의 스탯보다 높은 수치를 가진 일반 포켓몬들도 존재한다.
전반적으로 Total 과 비례하지만 일반 포켓몬이 최대값을 갖고 있는 컬럼도 있다.
(6) Generation
Generation 컬럼은 포켓몬의 세대를 나타낸다.
어느 세대에 전설 포켓몬이 많이 분포하는지 살펴보자.
plt.figure(figsize=(12, 10))
plt.subplot(211)
sns.countplot(data=ordinary, x="Generation").set_xlabel('')
plt.title("[All Pkemons]")
plt.subplot(212)
sns.countplot(data=legendary, x="Generation").set_xlabel('')
plt.title("[Legendary Pkemons]")
plt.show()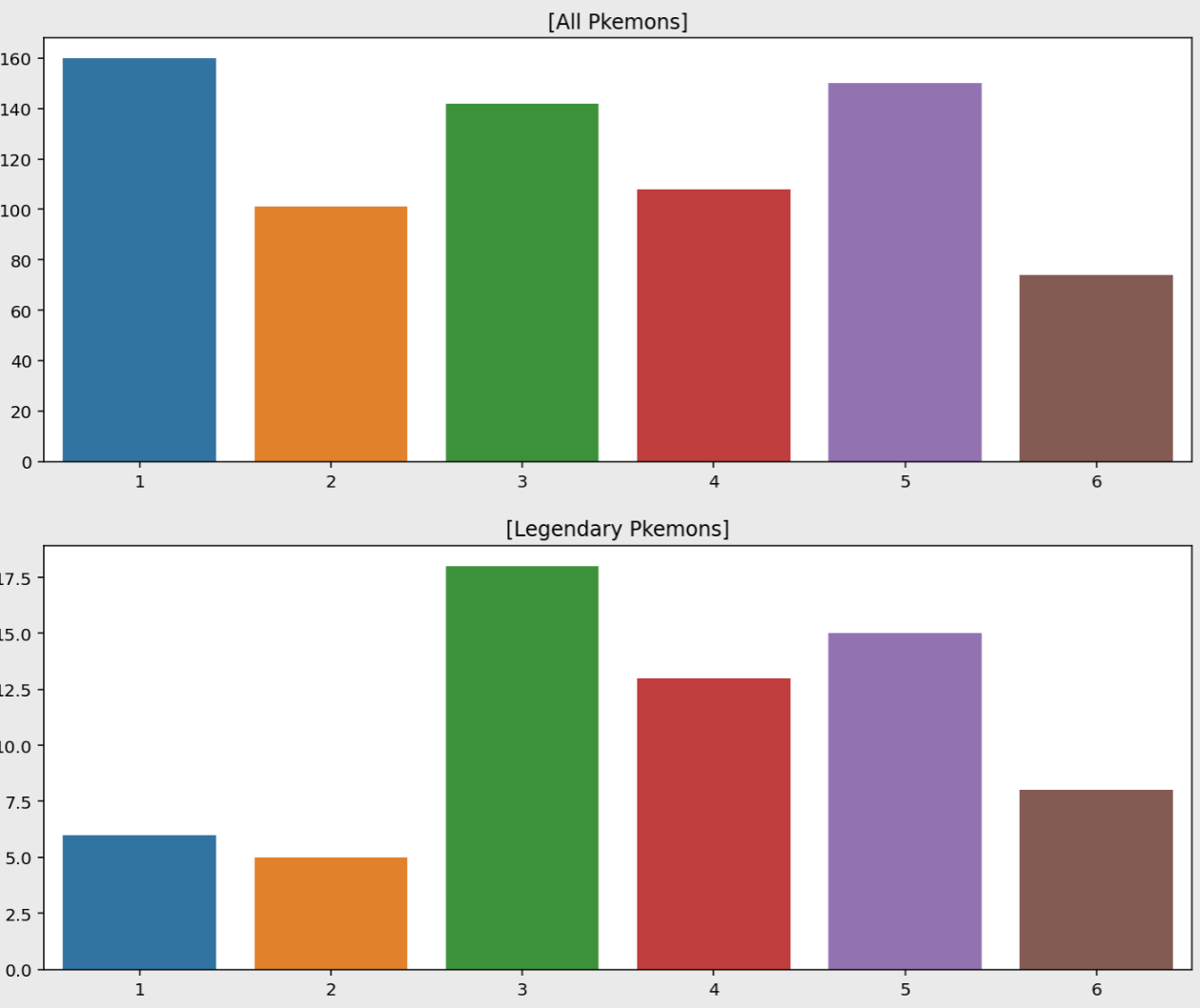
전설 포켓몬은 3세대에 가장 많고, 일반 포켓몬은 1세대에 가장 많이 분포한다.
전설 포켓몬 VS 일반 포켓몬
전설 포켓몬과 일반 포켓몬의 차이를 알면 둘을 구분할 수 있다.
지금까지 분석한 내용을 기반으로 차이점을 살펴보자.
Total
앞서 전설 포켓몬의 Total 값이 상대적으로 높은 편임을 확인했다.
그럼 특정 Total 값의 여부로 전설 포켓몬을 구분할 수 있을까?
# 전설 포켓몬 total 분포
print(sorted(list(set(legendary["Total"]))))
>>> [580, 600, 660, 670, 680, 700, 720, 770, 780]
# 일반 포켓몬 total 개수
len(sorted(list(set(ordinary["Total"]))))
>>> 195
# 일반 포켓몬 최댓값
print(max(set(ordinary["Total"])))
>>> 700전설 포켓몬은 최소 580, 최대 780까지 총 9개의 Total 값을 가진다.
반면 일반 포켓몬은 총 195개의 값을 가지며, 최댓값은 700이다.
즉, Total 값이 700보다 높으면 전설 포켓몬일 가능성이 매우 높아진다.
Name
앞서 Name 컬럼은 unique해서 인덱스로 사용할 수 있다는 것을 확인했다.
혹시 이름으로 전설 포켓몬을 구분할 수 있을까?
# 비슷한 이름을 가진 포켓몬들
n1, n2, n3, n4, n5 = legendary[3:6], legendary[14:24], legendary[25:29], legendary[46:50], legendary[52:57]
names = pd.concat([n1, n2, n3, n4, n5]).reset_index(drop=True)
print(names)
# 이름에 formes 가 들어가는 포켓몬
formes = names[13:23]
print(formes)위 코드를 실행해보면 각 이름들이 비슷한 경향을 띤다는 것을 확인할 수 있다.
전설의 포켓몬은 수식어가 붙는 경우도 많아서 상대적으로 이름이 길다는 특징도 있다.
# 전설 포켓몬 이름 길이
legendary["name_count"] = legendary["Name"].apply(lambda i: len(i))
# 일반 포켓몬 이름 길이
ordinary["name_count"] = ordinary["Name"].apply(lambda i: len(i))
# 시각화
plt.figure(figsize=(12, 10))
plt.subplot(211)
sns.countplot(data=legendary, x="name_count").set_xlabel('')
plt.title("Legendary")
plt.subplot(212)
sns.countplot(data=ordinary, x="name_count").set_xlabel('')
plt.title("Ordinary")
plt.show()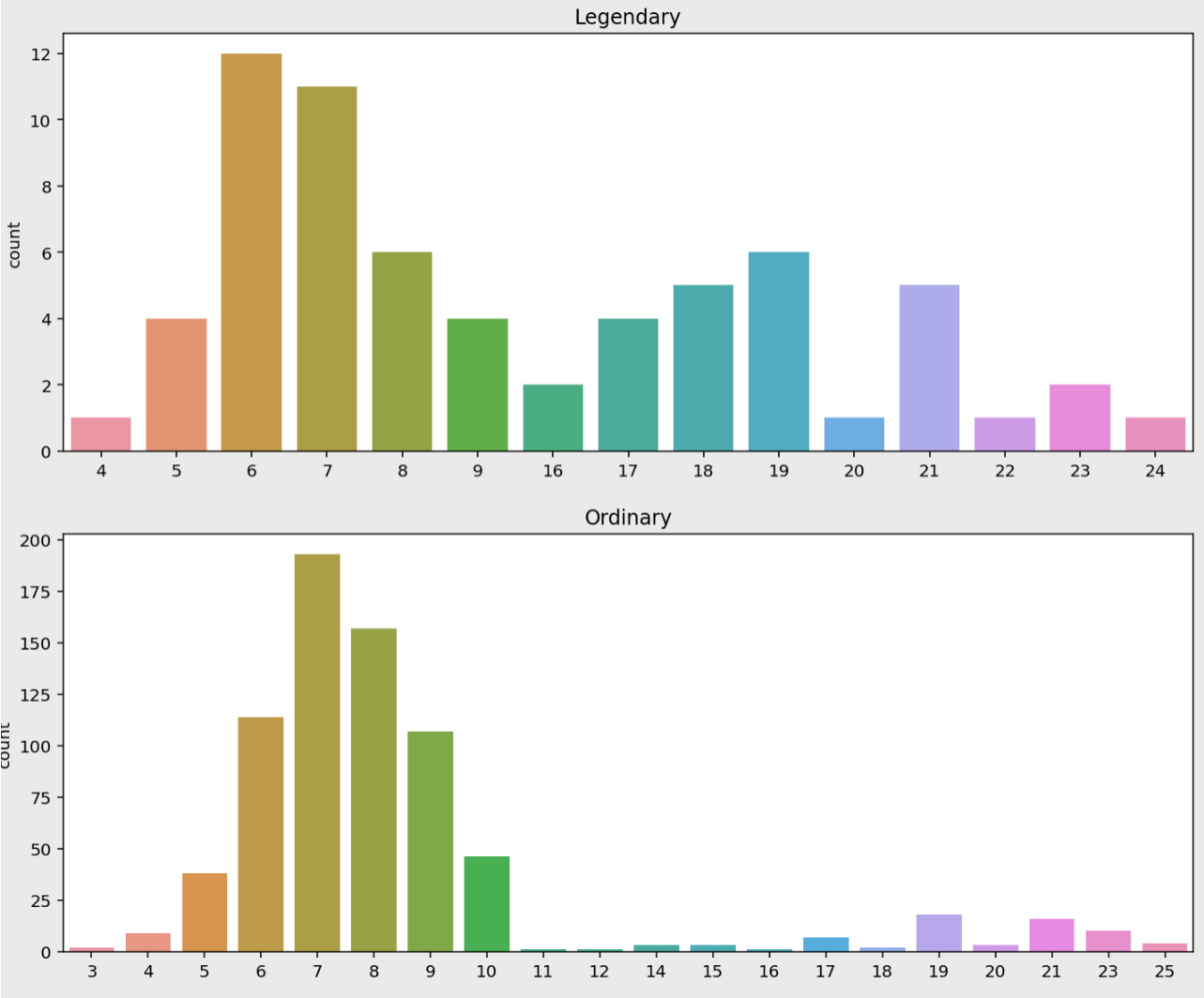
전설 포켓몬은 16글자 이상의 이름을 갖는 경우도 꽤 있지만, 일반 포켓몬은 거의 존재하지 않는다.
# 전설 포켓몬 중 이름이 10글자 이상일 확률
print(round(len(legendary[legendary["name_count"] > 9]) / len(legendary) * 100, 2), "%")
>>> 41.54%
# 일반 포켓몬 중 이름이 10글자 이상일 확률
print(round(len(ordinary[ordinary["name_count"] > 9]) / len(ordinary) * 100, 2), "%")
>>> 15.65%