
본 글은 <밑바닥부터 시작하는 딥러닝 2>와 <딥 러닝을 이용한 자연어 처리 입문>을 참고하였습니다.
seq2seq의 문제점
seq2seq 은 크게 두 가지의 문제를 가지고 있습니다.
1) context vector 의 길이가 고정돼 있음
2) 기울기 소실 / 폭발 문제가 발생함
기울기 폭발에는 기울기 클리핑, 기울기 소실에는 LSTM이나 GRU등의 해결책이 있습니다.
맥락 벡터의 길이가 고정돼 있으면, 시퀀스가 길어질수록 정보가 소실되는 문제가 발생합니다. 컴퓨터로 비유하자면 메모리 크기가 작아서 memory over error가 발생하는 것입니다.
물론 컴퓨터는 에러를 출력하고 작동을 멈추지만 seq2seq 네트워크는 넘친 데이터를 버리고 계속 작동한다는 차이점이 있습니다.
어텐션 메커니즘
아래에서 살펴보는 내용은 엄밀히 말해 <어텐션을 적용한
seq2seq>에 해당합니다.
맥락 벡터의 크기 문제를 해결하기 위해 제시된 것이 어텐션 메커니즘입니다.
어텐션의 기본 아이디어는 디코더에서 출력 단어를 예측하는 매 시점()마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고하는 것입니다. 이를 통해 매 시점마다 각 원소의 중요도를 알 수 있습니다.
문장을 참고한다는 것은 무슨 의미일까요? 차근차근 살펴보겠습니다.
Encoder 개선
seq2seq에서 사용하는 인코더의 기본구조는 단어마다 LSTM 계층을 거쳐 나온 은닉 상태를 하나의 벡터 에 담아 디코더로 넘겨주도록 설계돼 있습니다.
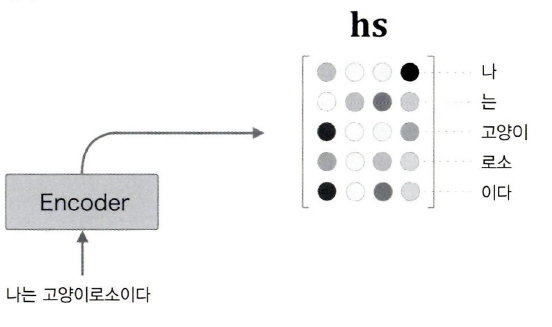
어텐션에서는 각 단어의 은닉 상태를 맥락 벡터 에 담지 않고 하나의 벡터행렬 로 모아 사용합니다.
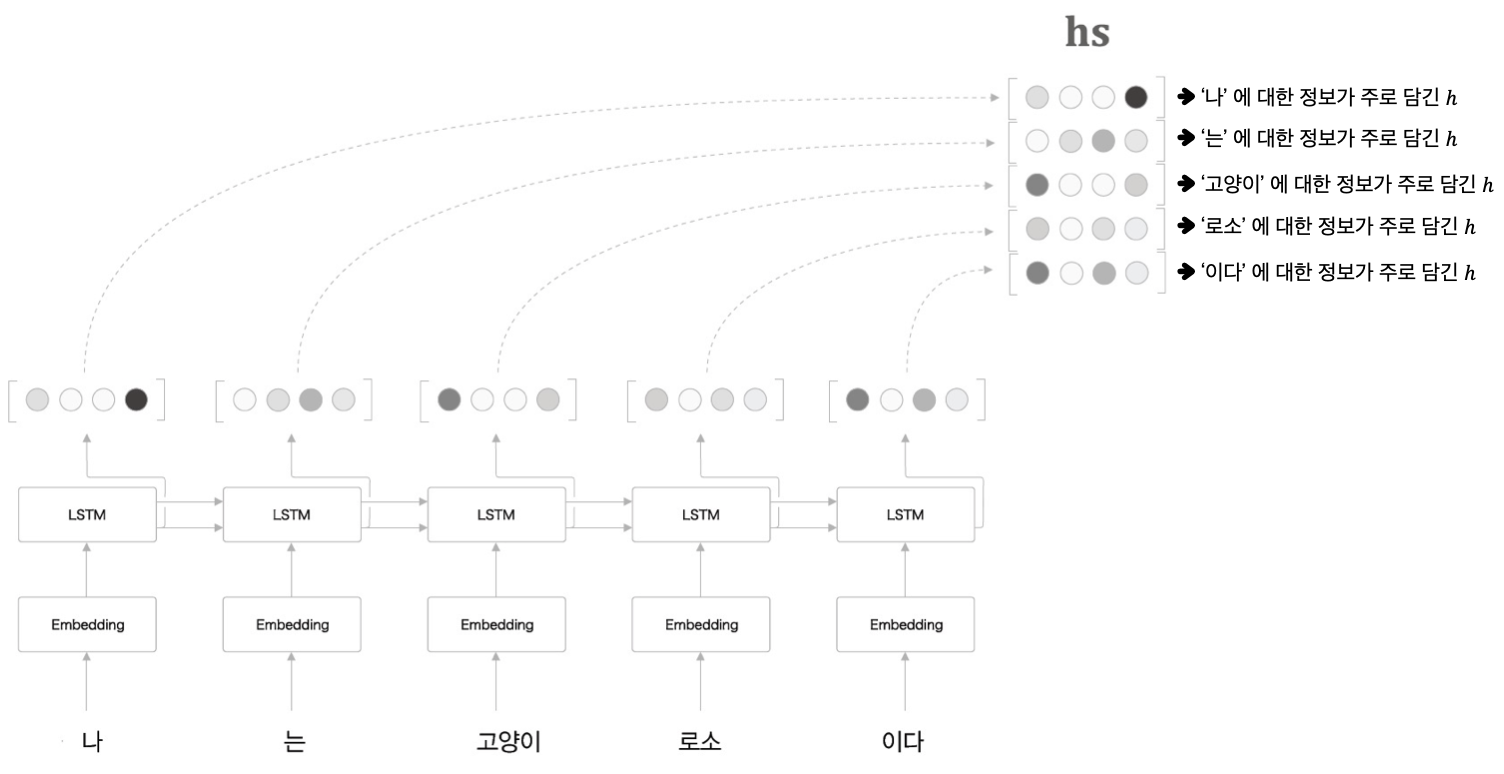
구체적으로는 위 그림과 같은 형태가 됩니다.
추출되는 은닉 상태의 수는 input 시퀀스의 단어 수와 같습니다. 해당 예시에서는 나, 는, 고양이, 로소, 이다 5개로 이뤄진 시퀀스이므로 추출되는 은닉 상태의 개수 또한 5개임을 확인할 수 있습니다.
는 각 시점의 단어들의 중요도를 가진 벡터행렬입니다. 가 가지고 있는 각 단어별 은닉 상태 값 는 각 단어마다 개별 LSTM을 거쳐 나온 값이기 때문에, 각 단어의 영향을 가장 크게 받습니다.
예컨대 위 그림에서 (고양이)는 나, 는에서 전달받은 값도 반영하고 있지만, 고양이 단어의 영향을 가장 크게 받은 값이라는 의미입니다.
결과적으로 는 입력 시퀀스 내 모든 시점(time step)에서 각 원소들의 중요도 정보를 갖게 됩니다.
이로써 추출되는 맥락 벡터의 크기를 능동적으로 바꾸는 데 성공했습니다.
Caution
인코더는 순차적으로 입력을 받아 처리합니다.
즉, 위 그림에서 (고양이)는로소나이다의 영향을 고려하지 못한다는 문제가 있습니다.
이런 경우에는 양방향 RNN 또는 양방향 LSTM을 사용합니다.
Decoder 개선 1
어텐션의 디코더도 seq2seq과 기본 구조는 동일합니다.
인코더가 단어의 중요도를 의미하는 은닉 상태 벡터행렬 를 추출하면, 디코더는 이를 입력받아 유사 단어를 찾아냅니다.
기본적인 seq2seq에서는 인코더에서 추출한 은닉 상태 벡터 를 디코더의 첫 은닉 상태 값으로 사용했습니다. shape가 동일하기 때문에 그렇게 할 수 있었습니다.
인코더를 개선해 여러 은닉 상태를 모은 행렬 를 입력받으려면 디코더 구조도 바뀌어야 합니다.
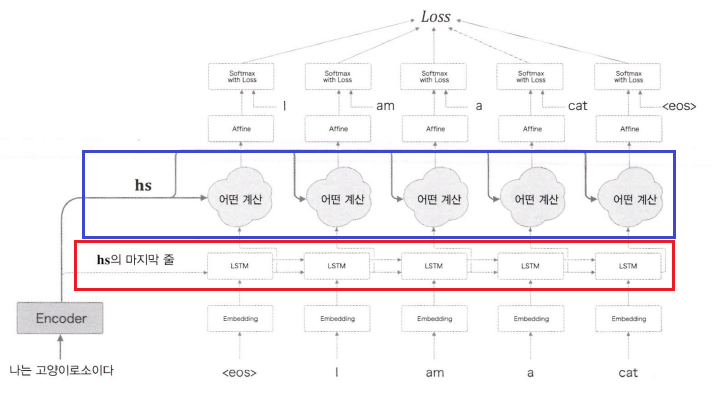
위 그림에서 붉은색 네모가 가장 단순한 seq2seq에서 사용되는 구조이고, 파란색 네모 부분이 를 사용하기 위해 추가되는 어떤 계산 과정까지 포함한 구조입니다.
그렇다면 이 어떤 계산이란 도대체 무엇일까요?
얼라인먼트 alignment
얼라인먼트는
단어끼리의 대응 관계를 나타내는 정보입니다. 예를 들면 <고양이 = Cat> 같은 것이죠.
얼라인먼트 작업에 필수적인 두 가지 정보는출발어 정보(고양이)와도착어 정보(Cat)입니다.
기존의 seq2seq는 맥락 벡터 의 길이가 한정돼 있었습니다.
이는 전체 시퀀스 중에서 상대적으로 중요한 부분만 추출해 요약하는 효과가 있었습니다.
그 대신 디테일하게 볼 수가 없었습니다. 그래서 정보 소실 문제가 발생했죠.
위 그림의 어텐션 구조에서는 입력 시퀀스 전체의 원소 데이터를 행렬 에 전부 담아 넘겨줍니다.
결과적으로 모든 원소의 중요도에 대한 정보가 담겨 있어 문장을 디테일하게 추출할 수 있는 대신, 디코더가 직접 중요한 부분을 골라내야 하는 문제가 발생합니다.
즉, 위 그림에서 어떤 계산 부분에는 'cat'을 출력하기 위해 행렬에서 어떤 것이 '고양이'인지 선택하는 과정이 들어가야 합니다.
조금 더 쉬운 설명
seq2seq은 순서와 부품이 지정돼 있는 문장 조립 설명서를 넘겨주는 대신 남는 부품이 생기고,어텐션은 각 순서마다 각 부품이 무슨 역할을 하는지 적혀 있는 설명서를 넘겨주는 대신 각 순서에서 어떤 부품을 쓸 지 직접 선택해야 한다는 의미입니다.
'선택'은 미분할 수 없다
그런데 N개의 벡터 중에서 어떤 것이 '고양이'인지 선택하는 것은 미분할 수 없다는 문제가 있습니다. 미분할 수 없으면 오차역전파법을 통해 학습할 수도 없죠.
그래서 하나를 선택하는 대신 모든 것을 선택하는 방식을 사용합니다.
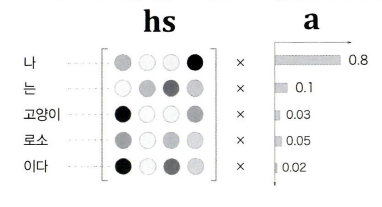
위 그림에서 는 행렬 내 벡터들의 가중치를 계산한 것입니다.
는 확률분포처럼 0.0~1.0 사이의 스칼라 값을 가지며, 모든 원소의 총합은 1이 됩니다.
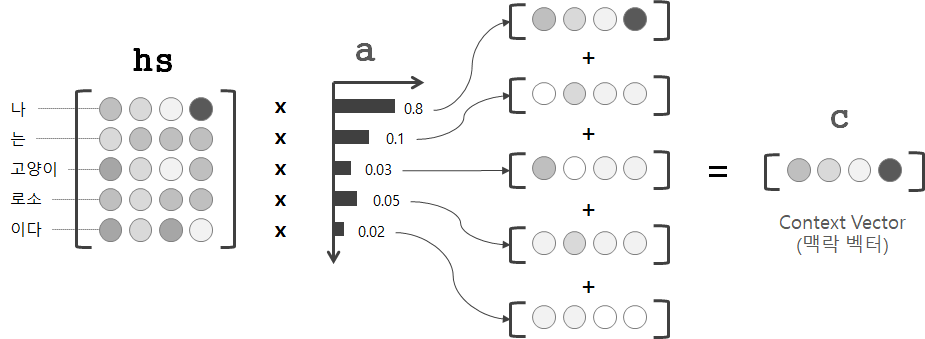
hs와 a를 통해 가중합을 구하면 '선택'에 필요한 맥락 벡터 c를 얻을 수 있습니다.
위 그림에서 나에 해당하는 가중치는 0.8입니다. 이는 맥락벡터 c에 나 벡터의 정보가 많이 포함돼 있다는 것을 의미합니다. 만약 디코더가 시점 에서 추출한 맥락벡터 에 나 벡터의 값이 많이 포함돼 있다면, 이것은 시점에 사용할 벡터로 나를 선택한 것으로 해석할 수 있습니다.
Decoder 개선 2
가중치 벡터 를 구하려면 디코더의 LSTM 계층의 은닉 상태 벡터 가 필요합니다.
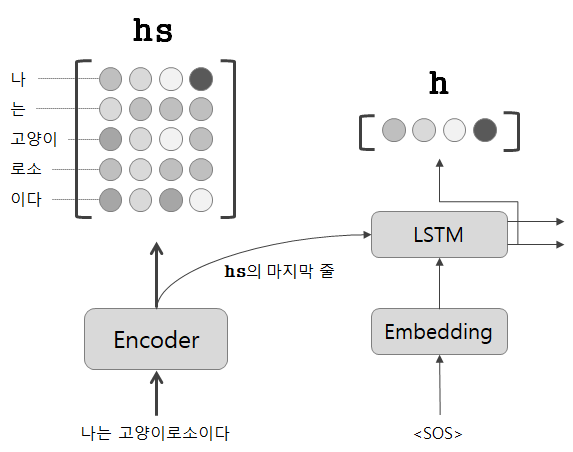
위 그림을 보면 의 마지막 벡터를 입력받습니다. 이는 전체 시퀀스 관점에서 각 원소별 중요도가 반영된 벡터를 받는 것과 같습니다.
따라서 디코더의 첫 LSTM 계층의 은닉 상태 벡터 와 인코더에서 추출한 행렬 의 유사도를 수치로 나타내면 가중치 벡터 를 구할 수 있습니다.
벡터간의 유사도를 측정하는 방법으로는 벡터의 내적을 사용합니다.
벡터의 내적을 직관적으로 생각하면 두 벡터가 얼마나 같은 방향을 향하고 있는가를 나타내는 것입니다.
Note
은닉벡터 와 의 유사도를 비교하는 것은 전체 입력 시퀀스 내 벡터별 중요도의 변화를 살펴보는 것과 같습니다.
예를 들어 시점의 벡터 와 최종적으로 출력한 은닉 벡터 의 유사도가 1이라면 해당 시점에서도, 전체 시퀀스 관점에서도 벡터의 중요도는 변하지 않았을 뿐 아니라 가장 중요한 벡터라는 뜻이 됩니다.
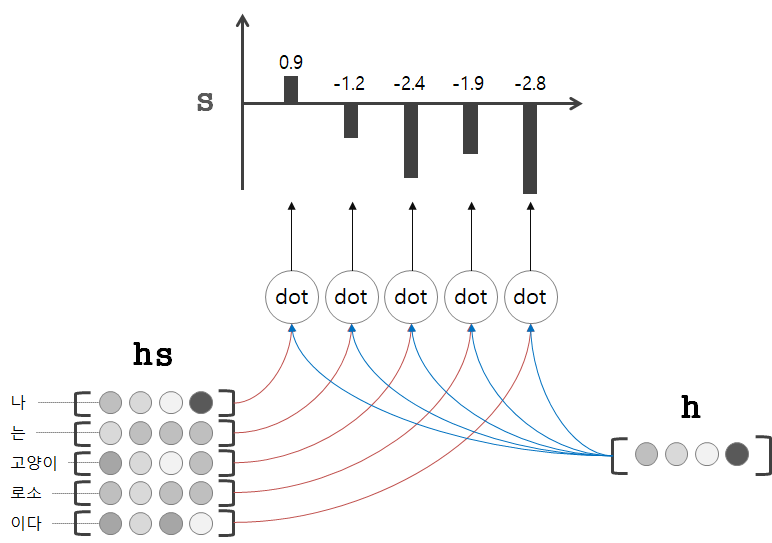
은닉 상태 벡터 와 의 내적을 통해 구한 유사도 값을 라고 합니다.
는 어텐션 점수score라고도 부르며, softmax 함수를 적용하여 0~1 사이의 값으로 정규화합니다.
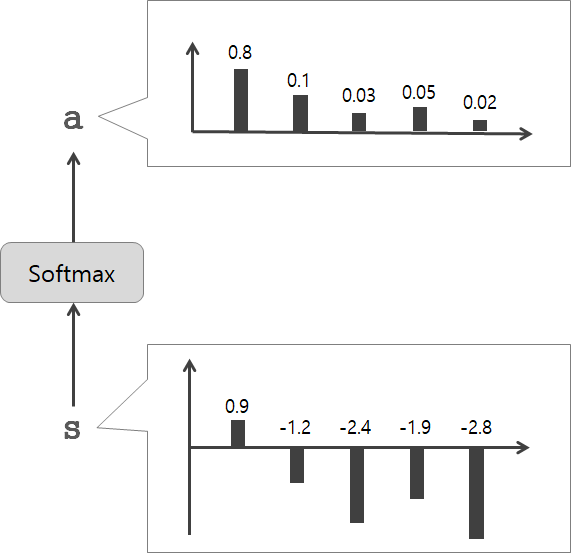
정규화한 값들을 모으면 바로 위에서 살펴본 가중치 벡터 가 됩니다.
Decoder 개선 3
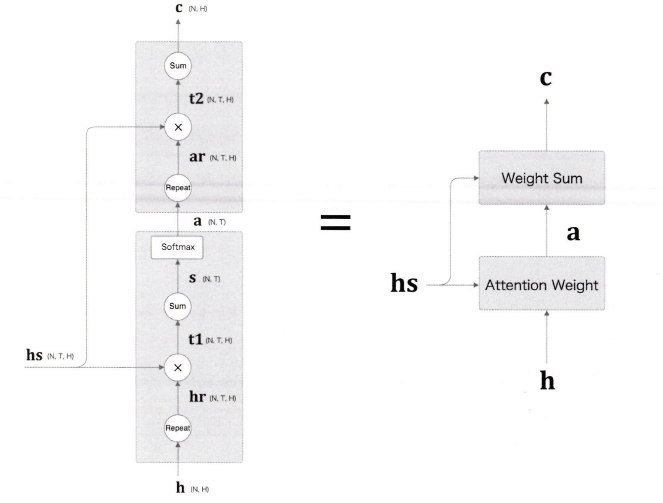
지금까지의 과정을 정리하면 위와 같습니다.
: 디코더의 첫 LSTM 계층의 은닉 상태 벡터
: 인코더가 출력한 각 원소들의 은닉 상태 벡터
: 와 를 내적한 값 (두 벡터간의 유사도)
: softmax 함수로 를 정규화한 벡터
: 와 의 가중합으로 구한 맥락 벡터
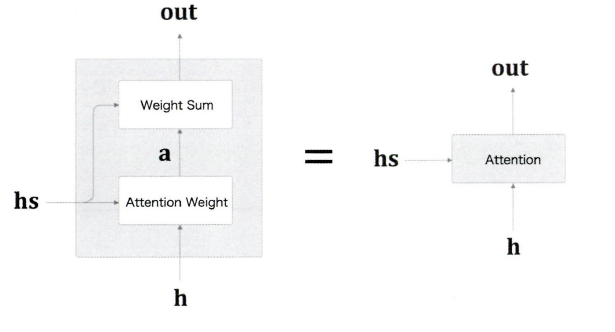
여기까지가 어텐션 기술의 핵심 아이디어입니다.
어텐션 메커니즘
- 인코더가 각 단어별로 은닉 상태를 출력하여 행렬로 모아 디코더에게 전달
- 디코더는 매 LSTM 계층마다 전달받은 에서 중요한 원소의 맥락 벡터를 추출
- 추출된 맥락 벡터를 Affine 계층으로 전달
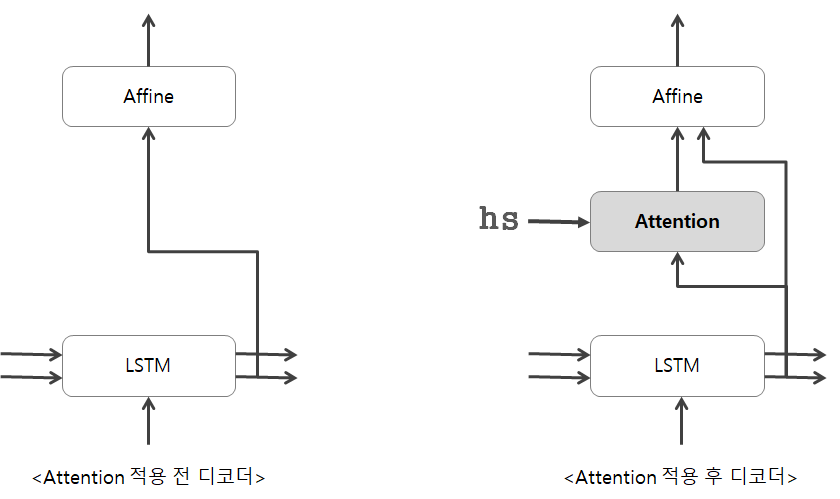
어텐션 메커니즘을 적용하기 전과 후를 보면 조금 더 직관적으로 이해할 수 있습니다.
어텐션 시각화
(x_train, t_train), (x_test, t_test) = \
sequence.load_data('date.txt')
char_to_id, id_to_char = sequence.get_vocab()
# 입력 문장 반전
x_train, x_test = x_train[:, ::-1], x_test[:, ::-1]
vocab_size = len(char_to_id)
wordvec_size = 16
hidden_size = 256
model = AttentionSeq2seq(vocab_size, wordvec_size, hidden_size)
model.load_params()
_idx = 0
def visualize(attention_map, row_labels, column_labels):
fig, ax = plt.subplots()
ax.pcolor(attention_map, cmap=plt.cm.Greys_r, vmin=0.0, vmax=1.0)
ax.patch.set_facecolor('black')
ax.set_yticks(np.arange(attention_map.shape[0])+0.5, minor=False)
ax.set_xticks(np.arange(attention_map.shape[1])+0.5, minor=False)
ax.invert_yaxis()
ax.set_xticklabels(row_labels, minor=False)
ax.set_yticklabels(column_labels, minor=False)
global _idx
_idx += 1
plt.show()
np.random.seed(1984)
for _ in range(5):
idx = [np.random.randint(0, len(x_test))]
x = x_test[idx]
t = t_test[idx]
model.forward(x, t)
d = model.decoder.attention.attention_weights
d = np.array(d)
attention_map = d.reshape(d.shape[0], d.shape[2])
# 출력하기 위해 반전
attention_map = attention_map[:,::-1]
x = x[:,::-1]
row_labels = [id_to_char[i] for i in x[0]]
column_labels = [id_to_char[i] for i in t[0]]
column_labels = column_labels[1:]
visualize(attention_map, row_labels, column_labels)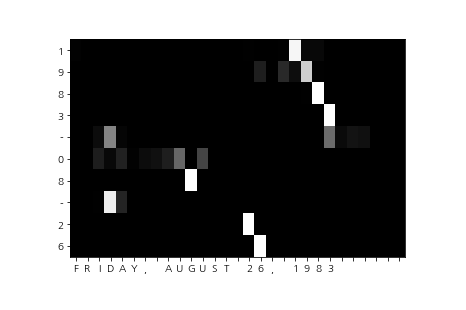
날짜 변환용 데이터셋을 활용한 어텐션 모델의 시각화 결과입니다.
가로는 입력 문장, 세로는 출력 문장이고, 밝을 수록 큰 값을 가진 원소입니다.
가르쳐주지 않았음에도 August를 08로 읽어내고 있는 것을 볼 수 있습니다.
Attention의 설명가능성?
위 시각화 결과를 보면 attention의 또다른 강점을 알 수 있습니다. 바로 그 동안 블랙박스로 가려져 있던 학습 과정을 어느 정도 인간이 이해할 수 있는 형태로 살펴볼 수 있다는 것입니다.
하지만 정말 이 시각화 결과를 신뢰할 수 있을까요?
Attention is not explanation 이라는 논문에 따르면 attention weight ( 시점의 어텐션 가중치 값 )가 output에 대해 설명력을 가지려면 다음의 2가지 가정을 따라야 한다고 주장합니다.
- Attention weight는 feature importance를 측정하는 다양한 방법들과 상관관계가 있다.
- Alternative(adversarial) attention weight는 예측 결과의 변화를 야기할 것이다.
저자는 어텐션을 사용하는 다양한 NLP 태스크에서 위의 가정들을 만족하는 결과가 관찰되지 않았다고 말합니다.

구체적인 예시를 살펴보겠습니다.
위 그림은 텍스트 감정 분류 사례인데, 양쪽 모두 분류 결과는 negative입니다. 왼쪽은 original attention distribution, 오른쪽은 advarsarial(alternative) attention distribution에 해당합니다. 왼쪽에서는 waste 토큰이 결과와 연관성이 높고, 오른쪽에서는 was 토큰이 결과와 연관성이 높습니다. 집중하고 있는 토큰이 전혀 다르지만, 같은 결과를 예측하고 있습니다. 따라서, 이러한 방식은 explanation에 적합하지 않다고 주장합니다.
좀 더 상세한 논문 리뷰는 여기에서 읽을 수 있습니다.
결론적으로 attention weight가 무조건적으로 설명력을 가진다는 가설은 잘못되었을 수 있습니다.
하지만 분명히 어텐션이 설명력을 가지는 경우도 존재합니다.
굳이 따지자면, Attention MIGHT be Explanation 에 더 가깝다고 볼 수 있겠습니다.
