#AI 논문 리뷰 생활스터디
오늘의 논문은 Going deeper with convolutions !
왜 GoogLeNet인가 했더니 저자들이 구글팀이라서..?
1. Abstract
논문에서는 Inception이라는 모듈을 제안하며 네트워크상에서 파라미터 계산에 사용되는 자원의 양을 개선한 방법을 연구하였다.
성능 최적화를 위해 Hebbian principle과 multi-scale processing을 적용
-> GoogLeNet codename = Inception
2. Introduction
Layer를 깊게 쌓을수록 성능은 좋아지는가?
아니다. 그만큼 filter 수가 많아지고 계산해야할 파라미터 값이 증가하므로 그에 소비되는 자원도 따라서 증가.
본 논문은 AlexNet보다 파라미터가 12배나 더 적지만 정확도는 증가
-> From the synergy of deep architectures and classical computer vision, like the R-CNN algorithm.
Inception이라는 이름은 "We need to go deeper"에서 착안,
What does "deeper" mean ?
1. "Inception module"의 형태로 새로운 차원의 구조 도입
2. 네트워크 깊이 증가
3. Related Work
CNN은 일반적인 표준 구조로 - Convoulutional layer가 쌓이고 그 뒤에 1개 또는 그 이상의 fully-connected layers가 따라오는 구조이다.
대용량 데이터에서의 요즘 트렌드는 layer의 수와 사이즈를 늘리고 오버피팅을 해결하기 위해 dropout을 적용하는 것이다.
overfitting
: 모델이 실제 분포보다 학습 샘플들 분포에 더 근접하게 학습되는 현상을 오버피팅(overfitting) 이라고 하며, 오버피팅(overfitting)을 피하는 방법을 정규화(regularization)라고 한다.
Network in Network(NIN)
The method could be viewed as additional 1 x 1 convolutional layers followed typically by the rectified linear activation.
ReLu (Rectified Linear Unit)
Neural Network에서 activation function으로 sigmoid function을 많이 사용하는데, sigmoid function은 연속이어서 미분 가능한 점과 0과 1사이의 값을 가진다는 점과 0에서 1로 변하는 점이 가파르기 때문에 사용해왔다.
그러나 ReLu가 이를 대체하게 된 이유 중 가장 큰 것은 Gradient Vanising 문제이다.
Sigmoid function은 0에서 1사이의 값을 가지는데 gradient descent를 사용해 Backpropagation 수행시 layer를 지나면서 gradient를 계속해서 곱하게 되므로 gradient는 0으로 수렴하게 된다. 따라서 layer가 많아지면 잘 작동하지 않는다.
따라서 이러한 문제를 해결하기 위해 ReLu를 새로운 activation function으로 사용.
ReLu는 입력값이 0보다 작으면 0, 0보다 크면 입력값 그대로를 내보낸다.
구현도 쉬워서 쓰기 좋음 !
1 x 1 Convolutional layer 사용 목적
- 병목현상을 제거하기 위한 차원 축소
- 네트워크 크기 제한
CCCP 기법은 1 x 1 Convolutional Layer과 그 연산 방식, 효과가 매우 유사
따라서 GoogLeNet에서 1 x 1 Convolutional layer를 Inception 모듈에 적용한 것 !
CCCP (Cascaded Cross Channel Pooling)
CCCP기법은 하나의 feature map에 대하여 수행하는 일반적인 pooling 기법과는 달리 channel을 직렬로 묶어 픽셀별로 pooling을 수행하는 것인데, 이러한 CCCP 연산의 특징은 feature map의 크기는 그대로이고, channel의 수만 줄어들게 하여 차원 축소 효과를 가져온다.
4. Motivation and High Level Considerations
심층 신경만의 성능을 개선시킬 수 있는 방법은 신경망의 크기를 늘리는 것이다.
이 때, 크기를 늘린다는 것은 다음 의미를 뜻한다.
1. depth의 증가 (the number of levels)
2. width의 증가 (the number of units at each level)
여기서 문제점이 발생한다.
첫 번째로, 크기가 커진다는 것은 파라미터 수가 늘어난다는 것, 이는 학습 데이터 수가 적은 경우에 오버피팅 발생 가능성 증가
두 번째로, 네트워크가 커질수록 자원 사용량이 증가
Since in practice the computational budget is always finite, an efficient distribution of computing resources is preferred to an indiscriminate increase of size, even when the main objective is to increase the quality of results.
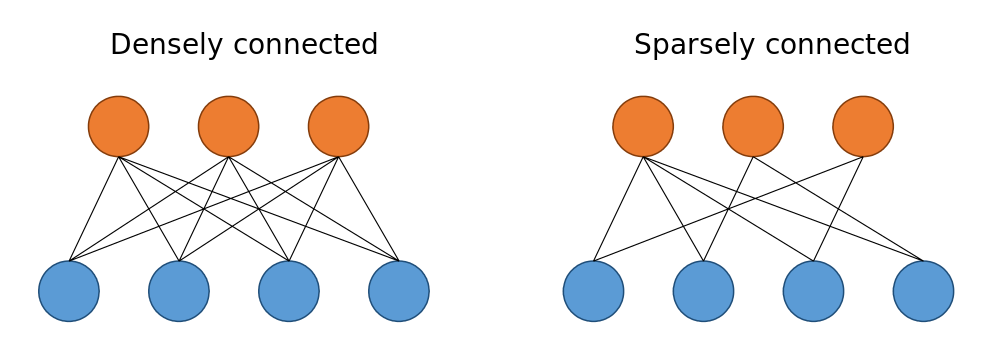
위 문제를 해결하는 방법은 fully connected -> Sparsely connected 구조로 바꾸는 것
하지만 요즘 컴퓨팅 환경은 sparse data structures를 다룰 때 매우 비효율적 !
(dense data만 꾸준히 개선되었음)
The vast literature on sparse matrix computations suggests that clustering sparse matrices into relatively dense submatrices tends to give state of the art practical performance for sparse matrix multiplication.
Sparse 매트릭스를 클러스터링해서 상대적으로 Dense한 서브매트릭스 만드는 것을 제안 !
Inception 모듈은 이러한 구조를 시험하기 위해서 시작되었고,
learning rate, hyperparameter, 훈련 방법등을 개선한 결과 localiztion, object detection 분야에 좋은 성능을 보임.
Localization
Localization이란 모델이 주어진 이미지안의 Object 가 이미지 안의 어느 위치에 있는지 위치 정보를 출력해주는 것으로, 주로 Bounding box 를 많이 사용하며 bounding box 의 네 꼭지점 pixel 좌표가 출력되는 것이 아닌 left top, 혹은 right bottom 좌표를 출력한다.
5. Architectural Details
Inception 구조의 주요 아이디어는 CNN에서 각 요소를 최적의 local sparce structure로 근사화하고, 이를 dense component로 바꾸는 방법을 찾는 것 !
All we need is to finde the optimal local constructiona nd to repeat it spatially.
이 때, 입력 데이터와 가까운 낮은 레이어에서는 특정 부분에 correlated unit들이 집중될 수 있기 때문에 1 x 1 Convolution으로 처리하지만 어느 우치에서는 좀 더 넓은 영역의 convoultional filter가 있어야 하기 때문에 correlated unit의 비율을 높일 수 있는 상황 발생
->feature map을 효과적으로 추출할 수 있도록 1 x 1, 3 x 3, 5 x 5 연산을 병렬적으로 수행
공간적 집중도가 감소한다는 것 -> 3x3, 5x5 Convolutional filter 수도 늘어나야함
여기서 문제점은 이러한 필터 수가 많아지면 연산량이 증가하게 된다는 것 !
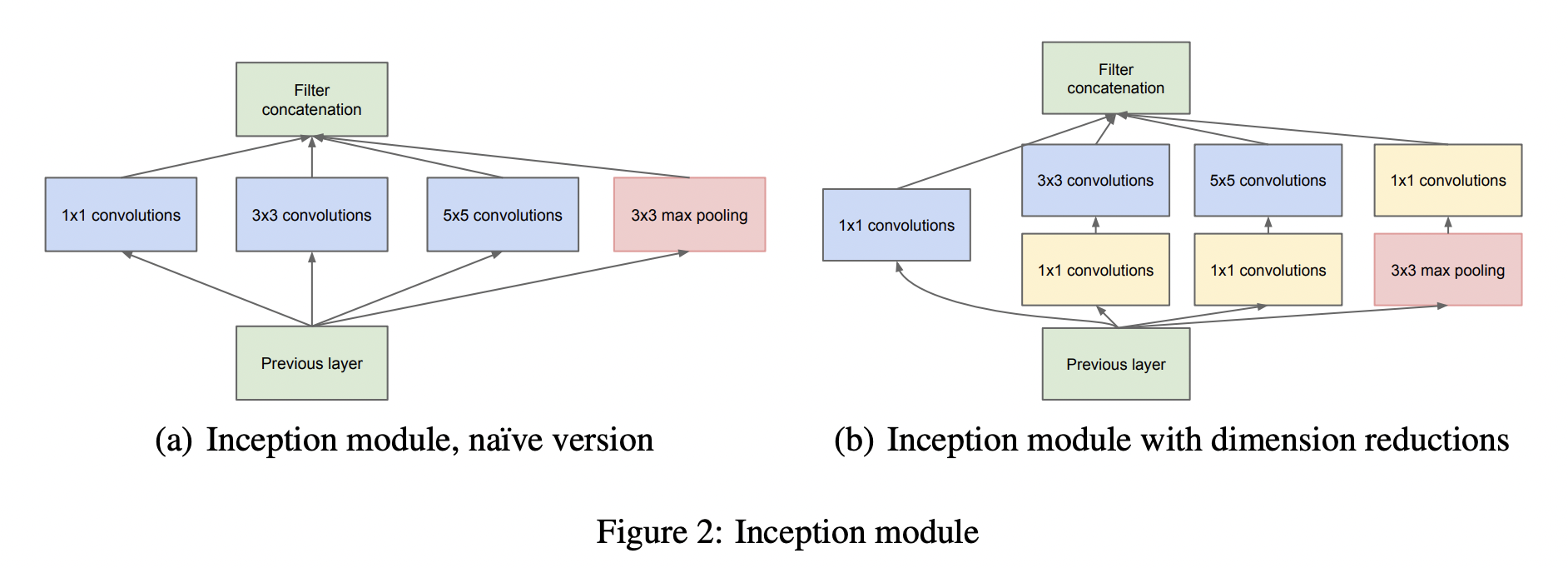
따라서 이 문제를 해결하기 위해 1x1 Convolutional filter를 이용해서 차원을 축소하였다.
3x3, 5x5 앞에 1x1을 두어 차원을 줄여 여러 Scale을 확보하면서도 연산량을 낮출 수 있다.
이전 CNN 모델들은 한 층에서 동일한 사이즈의 필터커널을 이용해 convolution 했던 것과 차이점이 있다.
따라서 좀 더 다양한 종류의 특성이 도출된다.
추가적으로 convolution 연산 이후에 추가되는 ReLu를 통해 비선형적 특징을 더 추가할 수 있다.
Inception Module 사용의 이점
1. 복잡한 연산없이 각 단계의 유닛 수를 증가시킬 수 있다.
2. visual 정보가 다양한 스케일로 처리되고, 다음 stage에서 서로 다른 stage의 특징을 동시에 추출할 수 있다.
6. GoogLeNet
효율적인 메모리 사용을 위해 낮은 레이어에서는 기본적인 CNN 모델을 적용, 높은 레이어에서는 Inception 모듈 사용
다양한 특징 추출을 위해 병렬적으로 연산 수행 및 연산량을 줄이기 위해 1x1 Convolutional layer 적용
Auxiliary Classifier(보조 분류기)
네트워크의 깊이가 깊어지면 깊어질수록 vanishing gradient 문제가 발생한다. 이 문제를 극복하기 위해서 네트워크 중간에 보조 분류기를 달아주고 이는 훈련시에만 활용되고 사용할 때는 제거해준다.
모델의 깊이가 매우 깊을 경우 기울이가 0으로 수렴하는 gradient vanishing 문제 발생
이때, 상대적으로 얕은 신경망의 강한 성능을 통해 신경망 중간 layer에서 생성된 특징이 매우 차별적이라는 것을 알 수 있다.
따라서 중간 layer에 Auxiliary Classifier를 추가하여 중간중간에 결과를 출력해 gradient가 전달될 수 있게끔 하여 정규화 효과가 나타나도록 하였다.
지나치게 영향 주는 것을 막기 위해 loss값 변동 및 실제 테스트 시에는 auxiliary classifier제거 후 제일 끝단의 softmax만을 사용한다.
본 논문에서는 global average pooling 방식을 사용하여 가중치의 개수를 많이 없앨 수 있었다.
Global average pooling
전 층에서 산출된 특성맵들을 각각 평균낸 것을 이어서 1차원 벡터로 만들어주는 것이다.
-> 1차원 벡터로 만들어줘야 최종적으로 이미지 분류를 위한 softmax 층을 연결해줄 수 있기 때문에
7. Training Methodology
Our training used asynchronous stochastic gradient descent with 0.9 momentum [17], fixed learning rate schedule (decreasing the learning rate by 4% every 8 epochs).
one prescription that was verified to work very well after the competition includes sampling of various sized patches of the image whose size is distributed evenly between 8% and 100% of the image area and whose aspect ratio is chosen randomly between 3/4 and 4/3. Also, we found that the photometric distortions by Andrew Howard [8] were useful to combat overfitting to some extent.
아직 모델 훈련을 어떻게 설정해야 좋은 결과가 나오는지까지는 생각해보기 어렵다..
8. Conclusions
Inception module은 Sparse 구조를 Dense 구조로 근사화하여 성능 개선을 하였다.
개선된 성능에 비해 연산량 증가는 매우 적다는 장점이 있다.
전반적인 개념공부를 하면서 확장시킬 수 있어서 공부하기 매우 좋았던 논문이었다.
