[Paper Review] ReMixMatch & FixMatch : Consistency-based Semi-supervised Learning Methods
Paper Review
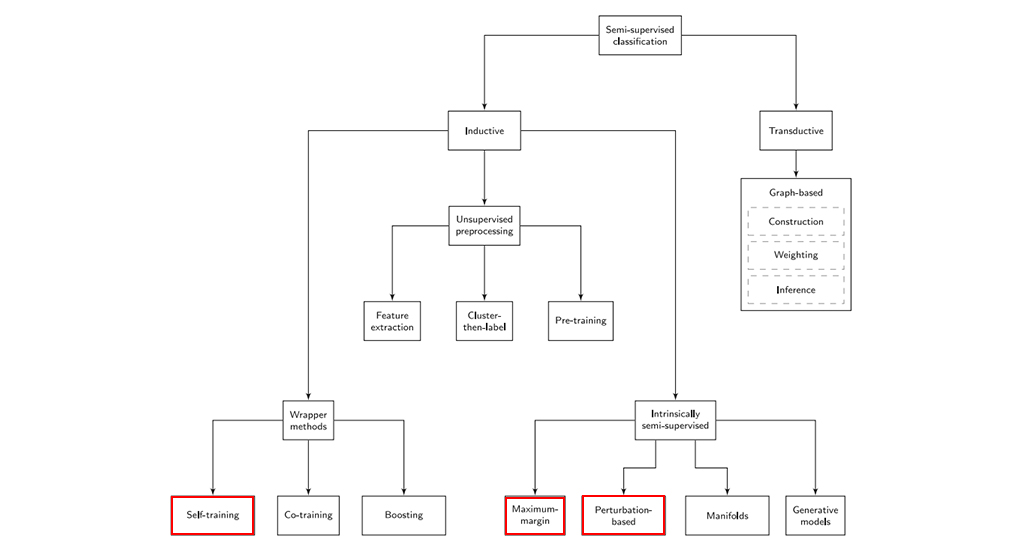
1. Semi-Supervised Learning
준지도학습의 이름에는 절반을 뜻하는 ‘semi-’가 붙지만, 실제로 이 학습방식에는 위에서 언급한 레이블링된 데이터와 레이블링되지 않는 데이터가 모두 사용된다.
준지도학습에서는 한 쪽의 데이터에 있는 추가 정보를 활용해 다른 데이터 학습에서의 성능을 높이는 것을 목표로 하기 때문에 기존 지도학습 데이터에 레이블링되지 않은 데이터 정보를 추가로 사용해 성능을 향상시키고, 클러스터링 분야에서는 새로운 데이터를 어느 클러스터에 넣을지 결정함에 있어 도움을 받을 수 있.
Semi-supervised learning의 필요성
준지도학습은 정답 데이터를 수집하는 ‘데이터 레이블링’ 작업에 소요되는 많은 자원과 비용 때문에 등장하게 되었다. 지금까지 많은 문제에서 좋은 성능을 보인 딥러닝 알고리즘은 이를 해결하기 위한 데이터 레이블링 작업이 필수적이었다. 초기에는 데이터가 비교적 단순한 문제를 다뤘기 때문에 쉽게 작업을 할 수 있었지만 최근 딥러닝은 다루는 문제가 복잡해지고 응용 분야가 다양해지면서 데이터 수집이 문제가 되고 있다!
데이터 수집에 드는 시간과 비용이 증가하게 되면서 단순히 작업량을 늘려 데이터 문제를 해결하기엔 무리가 있기 때문에 바로 '준지도 학습'이 등장하게 된 것
특히 위에서 레이블이 없는 데이터는 비교적 구하기 쉬운 경우가 많기 때문에, 준지도학습은 레이블된 데이터가 적을 때 레이블이 없는 데이터를 사용해 분류기의 성능을 향상시키는 것을 목표로 많이 활용되고 있다.
Semi-supervised learning 방법론들
: 대용량 unlabeled data를 어떻게 학습에 사용할 것이냐의 관점에서 다양한 semi-supervised learning의 방법론들이 등장하였다.
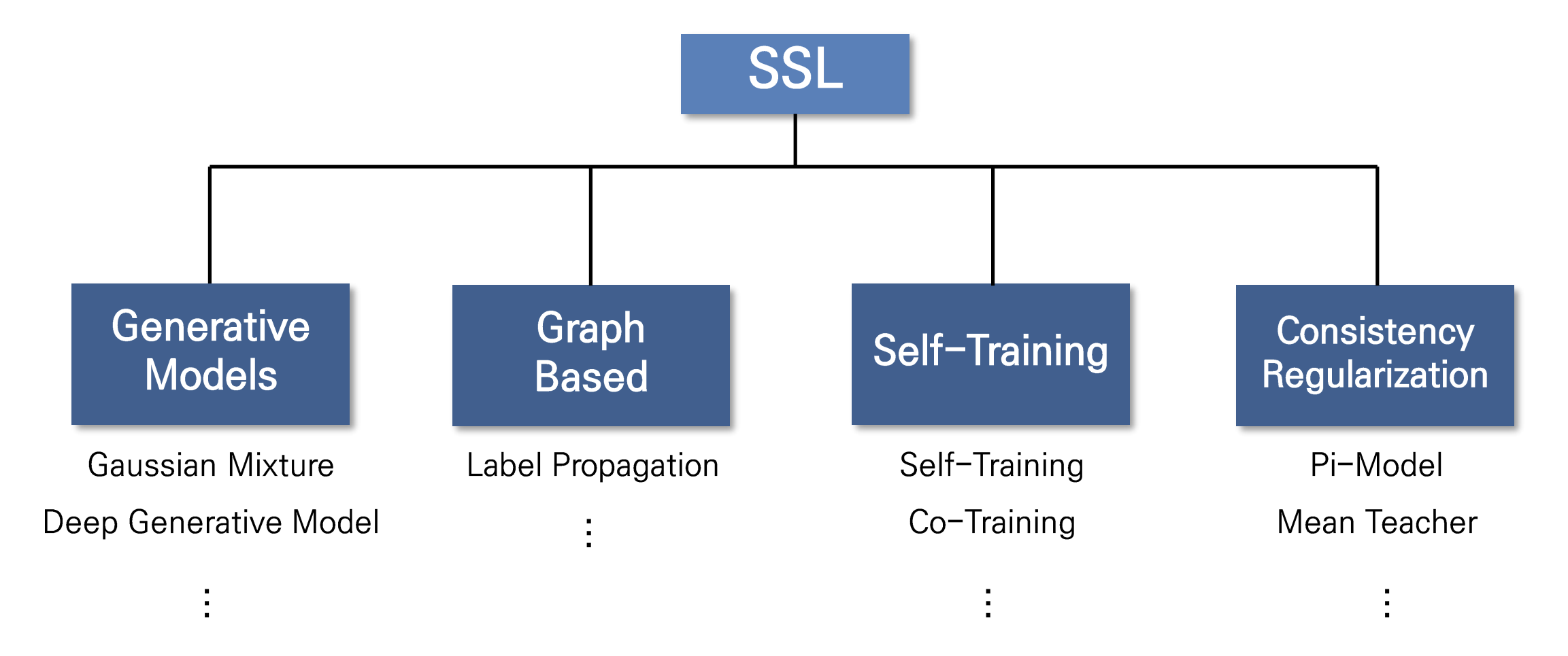
1.1 Entropy minimization
Entropy minimization는 'decision boundary는 데이터의 저밀도 지역에서 형성될 것'이라는 가정에 기초해서 unlabeled data output의 entropy를 minimization하는 기법이다.
예를 들어 개와 고양이를 분류하려고 할 때, 개 0.6, 고양이 0.4가 나오는 것보다 개 0.9 고양이 0.1 이 나오는 것이 entropy가 더 낮고 이런 방향으로 학습이 되어야한다는 것이다.(=decision boundary 근처에 있는 애매한 애들을 확실하게 구별할 수 있도록)
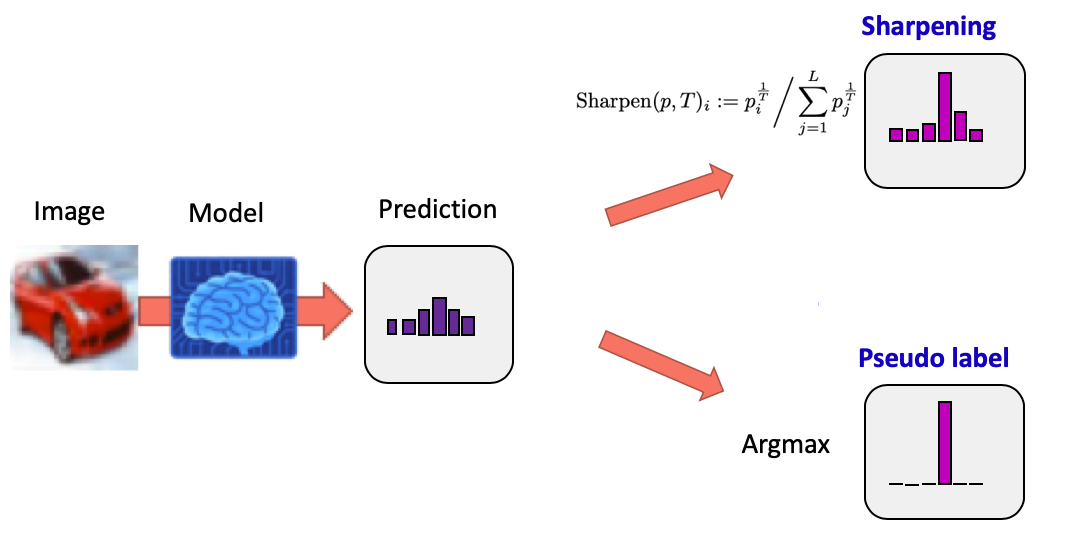
MixMatch, UDA, ReMixMatch 는 temperature sharpening을 통해 entropy minimization을 간접적으로 사용하고 FixMatch의 경우 pseudo-label을 이용하기 때문에 이또한 간접적 entropy minimization이다. pseudo-label은 왜 entropy minimization이냐 라고 할 수 있는데 pseudo-label을 달 때, argmax()를 통해 one-hot vector로 mapping 시키는 과정이 들어가기 때문이다.
1.2 Proxy-label method
Proxy-label기법은 labeled set으로 학습된 모델을 이용해 unlabeled data point들에 label을 달아주는 기법이다. 간단한 기법으로 classification, regression에 모두 사용할 수 있다는 장점이 있다. 유명한 모델로는 self-training (pseudo-label, meta pseudo-label, noisy student), multi-view training (Co-training) 등이 있다.
Self-Training 방법의 장단점
장점
: The simplest semi-supervised learning method.
A wrapper method, applied to existing (complex) classifiers.
Often used in real tasks like natural language processing.
단점
: Early mistakes could reinforce themselves.
Cannot say too much in terms of convergence.
1.3 Generative models
Generative model은 label이 없이도 원본 데이터를 생성(복원)할 수 있는 feature를 뽑아내는 reconstruction task를 수행한다. reconstruction task 역시 label이 없이 입력만 있다면 수행할 수 있기 때문에 semi-supervised learning에서 unlabeled data에 주는 unsupervised task로 적합하다.
1.4 Consistency regularization (Consistency training)
이 방법은 unlabeled data point에 작은 perturbation을 주어도 예측의 결과에는 일관성이 있을 것이다라는 가정에서 출발한다. unlabeled data는 예측결과를 알 수 없기 때문에 data augmentation을 통해 class가 바뀌지 않을 정도의 변화를 줬을 때, 원 데이터와의 예측결과가 같아지도록 unsupervised loss를 주어 학습하게 된다. 이를 통해 약간 헷갈리는 샘플들에 대해 class를 유연하게 예측할 수 있도록 해준다.
1. 모델을 이용해 unlabeled Data의 분포 예측
2. Unlabeled Data에 Noise 추가(Data Augmentation)
3. 예측한 분포를 Augmented Data의 정답 label로 사용해 모델 학습
1.5 Graph-based methods
Graph-based semi-supervised learning은 unlabeled data의 label을 알고싶다는 것에서 출발한다. 이는 앞선 방법들이 unlabeled data로 labeled data의 예측성능을 올리고 싶다는 것과는 다른 목표를 가진다. 대표적인 방법으로는 graph의 노드로 {labeled, unlabeled} 데이터를 표현하고 노드들 사이의 유사도를 기준으로 유사도 가중치가 높은 이웃으로 건너 건너 label을 추정하는 label propagation이 있다.
2. ReMixMatch
SSL 접근법들은 Consistency Regularization과 Entropy minimization의 방법론으로 통합되어 연구되어 왔다. 대표적으로 MixMatch가 이 두개의 cost function을 잘 조합하여 좋은 성능을 달성한 예시 !
ReMixMatch에서는 기존 MixMatch 에서 제시한 방법론 외적으로 2가지 추가적인 성능을 제안한다.
-> Distribution Alignment, Augmentation Anchoring
2.1 Recap
: Consistency Training과 Mixup을 이용한 SSL 방법론
Label Guessing
-> Unlabeled data에 augmentation을 여러번 한 뒤 예측 분포들 평균값 계산
2.2 Distribution Alignment
SSL의 목표는 Labeled data와 Unlabeled data가 모델의 성능 향상을 위해 같이 협업하는 알고리즘을 찾는 것! 접근 방식은 Input-Output pair의 mutual information값을 최대화시키는 것이다. 이전 SSL의 경우에는 Entropy Minimization관점에서 Pseudo labeling 방법을 통해 모델을 훈련시키고 앞 쪽 Term H는 무시되어왔다.
H는 fairness(훈련데이터가 각 클래스별로 Uniform distribution을 따른다는 것)을 가정하고 클래스 불균형문제가 없다고 보는데 실제로는 아님 !!
클래스 불균형과 Outlier들이 훈련을 방해하고 있기 때문에 Remixmatch에서는 예측 평균을 클래스별로 나눠서 클래스가 적은 셋에 대해서는 normalize된 예측값이 보다 큰 contribution을 주는 효과를 주는 방법론을 제시했다.
2.3 Augmentation Anchoring
Remixmatch에서는 Strong Augmentation의 이점을 살리기 위해 이 방법을 도입
입력 이미지에 대해 Weak Augmentation(W), Strong Augmentation(S)를 모두 적용하여 나온 Output, W(x), S(x)에 대해, W(x)를 이용해 추론한 Pseudo label을 사용하여 S(x)에 대한 Entropy Minimization을 수행하여 성능을 향상 시켰다.
-> 이 두 가지 기법을 활용하여 MixMatch와 비교해 더 나은 성능 달성
3. FixMatch
