Abstract
본 논문에서는 적대적 과정을 통해 모델을 추정하기 위한 프레임워크를 제안한다.
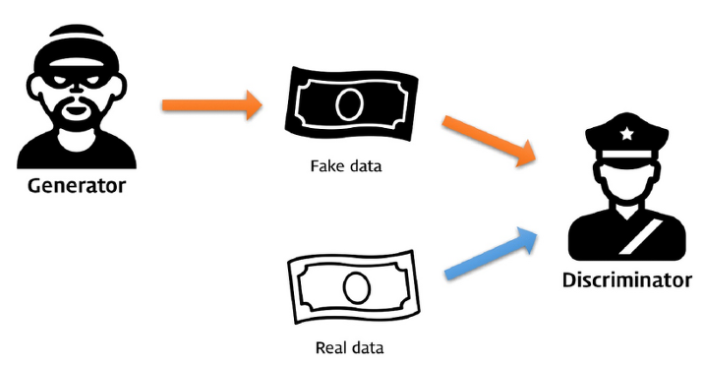
GAN에서 자주 볼 수 있는 그림인데, 데이터를 생성하는 Generator, 판별하는 Discriminator가 있다. 이 프레임워크는 두 명의 플레이어가 minmax game을 하는 것과 같은데, G는 D를 속이기 위해 성능이 오르고, D는 G가 만든 위조지폐를 잡기위해 성능이 오르는 상호 적대적인 관계를 보고 생성적 적대 신경망(GAN) 이라는 이름을 갖게되었다.
1. Introduction
제안된 adversarial nets 프레임워크에서 생성자가 적대적으로 맞서 싸운다. 판별자는 샘플이 모델의 분포에서 온 것인지, 데이터의 분포에서 온 것인지 결정하는 것을 학습한다. 생성자는 위조 지폐를 만들고 이것을 발견되지 않고 사용하려고하는 위조 지폐범 팀과 유사하다고 생각할 수 있고, 판별자는 위조 지폐를 찾으려고 하는 경찰과 유사하다고 생각할 수 있다. 이 게임에서 경쟁은 위조 지폐가 진짜 지폐로부터 구분이 안 될 때 까지 두 개의 팀 둘 다 그들의 방법을 증진시키는 것이다.
이 프레임워크는 많은 종류의 모델과 최적화 알고리즘에 대한 특별한 학습 알고리즘을 생성할 수 있다. 본 논문에서, 우리는 생성 모델이 다층레이어 퍼셉트론을 통해 랜덤 노이즈를 통과하는 것에 의해서 샘플을 생성하는 특별한 경우를 탐험한다. 우리는 이러한 특별한 케이스를 adversarial nets라고 부른다. 이 경우에, 우리는 오직 매우 성공적인 역전파와 드롭아웃 알고리즘을 통해서 두 개의 모델을 학습시킬 수 있고, 오직 순전파를 통해서 생성모델로 부터 샘플할 수 있다. 대략적인 추정이라 마코브 체인은 불필요하다.
딥러닝이 작동하는 방식은 인공지능 영역에서 마주하는 데이터의 종류에 대해서 모집단에 근사하는 확률 분포를 나타내는 계층모델을 발견하는 것 지금까지는, 고차원의 방대한 센싱 데이터를 클래스 레이블에 mapping해서 구분하는 모델 사용 -> well-behaved gradient를 갖는 선형 활성화 함수들을 사용한 backpropagation, dropout 알고리즘 기반
Deep generative model들은 maximum likelihood estimation과 관련된 전략들에서 발생하는 많은 확률 연산들을 근사하는 데 발생하는 어려움과 generative context에서는, 앞서 모델 사용의 큰 성공을 이끌었던 선형 활성화 함수들의 이점들을 가져오는 것의 어려움이 있기 때문에 크게 임팩트 있지 않았음.
=> 이 논문에서 소개될 새로운 generative model은 이러한 어려움들을 회피한다
이 논문에서 소개되는 adversarial nets 프레임워크의 컨셉은 ‘경쟁’으로, discriminative model은 sample data가 G model이 생성해낸 sample data인지, 실제 training data distribution인지 판별하는 것을 학습함
GAN의 경쟁하는 과정을 경찰(분류 모델, 판별자)과 위조지폐범(생성 모델, 생성자) 사이의 경쟁으로 비유하면, 위조지폐범은 최대한 진짜 같은 화폐를 만들어 경찰을 속이기 위해 노력하고, 경찰은 진짜 화폐와 가짜 화폐를 완벽히 판별하여 위조지폐범을 검거하는 것을 목표로 한다. 이러한 경쟁하는 과정의 반복은 어느 순간 위조지폐범이 진짜와 다를 바 없는 위조지폐를 만들 수 있고 경찰이 위조지폐를 구별할 수 있는 확률 역시 50%로 수렴하게 됨으로써 경찰이 위조지폐와 실제 화폐를 구분할 수 없는 상태에 이르도록 한다.
=> 결국 GAN의 핵심 컨셉은 각각의 역할을 가진 두 모델을 통해 적대적 학습을 하면서 ‘진짜같은 가짜’를 생성해내는 능력을 키워주는 것
3. Adversarial nets
adversarial modeling 프레임워크는 가장 간단하므로, multi-layer perceptrons 모델 적용
학습 초반에는 G가 생성해내는 이미지는 D가 G가 생성해낸 가짜 샘플인지 실제 데이터의 샘플인지 바로 구별할 수 있을 만큼 형편없기 때문에 D(G(z))의 결과가 0에 가까움. 즉, z로 부터 G가 생성해낸 이미지가 D가 판별하였을 때 바로 가짜라고 판별할 수 있다고 하는 것을 수식으로 표현한 것이다. 그리고 학습이 진행될수록, G는 실제 데이터의 분포를 모사하면서 D(G(z))의 값이 1이 되도록 발전한다. 이는 G가 생성해낸 이미지가 D가 판별하였을 때 진짜라고 판별해버리는 것을 표현한 것이다.
-> D는 training data의 sample과 G의 sampl에 진짜인지 가짜인지 올바른 라벨을 지정할 확률을 최대화하기 위해 학습하고, G는 log(1-D(G(z))를 최소화(D(G(z))를 최대화)하기 위해 학습되는 것!
D입장에서는 V(D,G)를 최대화시키려고, G입장에서는 V(D,G)를 최소화시키려고 하고, 논문에서는 D와 G를 V(G,D)를 갖는 two-player minmax game으로 표현한 것이다.
4. Theoretical Results
앞서 제시되었던 GAN의 minmax problem이 제대로 동작한다면, minmax problem이 global minimum에서 unique solution을 가지고 어떠한 조건에 만족하면 그 solution으로 수렴한다는 사실이 증명되어야 한다.
수식은 영상 참조
6. Advantages and disadvantages
1) 단점
- pg(x)가 명시적으로 존재하지 않는다.
- D와 G과 균형을 잘 맞춰서 성능이 향상되어야 한다. 또한, D가 먼저 너무 발전해버린다면 G가 데이터를 많이 붕괴시켜버리게된다.
2) 장점
- Markov chains이 전혀 필요 없고 gradients를 얻기 위해 back-propagation만이 사용된다.
- 학습 중 어떠한 inference가 필요 없게 된다.
- 다양한 함수의 모델이 적용될 수 있다.
7. Conclusions and future work
conditional generative model로 발전시킬 수 있다. (CGAN)
Learned approximate inference는 주어진 x를 예측하여 수행될 수 있다.
parameters를 공유하는 conditionals model를 학습함으로써 다른 conditionals models을 근사적으로 모델링할 수 있다. 특히 MP-DBM의 stochastic extension의 구현에 대부분의 네트워크를 사용할 수 있음
Semi-supervised learning: 제한된 레이블이 있는 데이터 사용할 수 있을 때, classifiers의 성능 향상
효율성 개선: G,D를 조정하는 더 나은 방법이나 학습하는 동안 sample z에 대한 더 나은 분포를 결정함으로써 학습의 속도 높일 수 있다.
: 수식 다시 한 번 정리하기
