[논문리뷰] MDETR - Modulated Detection for End-to-End Multi-Modal Understanding
Multimodal Deep Learning
Paper: MDETR -- Modulated Detection for End-to-End Multi-Modal Understanding

0. Abstract
Multi-modal 추론 시스템은 이미지로부터 관심 있는 region을 추출하기 위해 pre-trained object detector에 의존한다. 하지만, 이 핵심적인 모듈은 보통 downstrame task(?)와 독립적으로 훈련되며, object와 attributes의 '고정된 단어'를 기반으로 학습되는 black-box로서 쓰인다. 이런 문제는 시스템이 자유 형식 텍스트로 표현된 visual concept의 긴 꼬리를 포착하는 것을 어렵게 만든다.
본 논문에서는 MDETR 모델을 제안하는데, 이는 raw text query(caption, question)를 기반으로 조건화된 이미지 내 object를 detect하는 end-to-end modulated detector이다. 우리는 text와 image를 공동으로 추론하기 위해 트랜스포머 기반 구조를 사용하며, 모델의 초기 단계에서 두 modalities(양식)를 혼합함으로써 실현하였다.
우리는 text 내 phrase와 이미지 내 objects 사이의 명시적인 할당이 이루어진, 기존에 존재한 multi-model dataset을 이용해 130만개의 text-image pairs에 네트워크를 pre-train 하였다. 그 후, phrase grounding, reffering expression comprehension, segmentation 등에 해당하는 여러가지 downstream task에 fine-tuning하였다. 또한, few-shot setting에 fine-tuned 됐을 때 주어진 label set에 대해 object detector로서 우리 모델의 유용성을 탐구하였다. 그 결과, pre-training 접근법은 매우 조금 라벨링된 instance를 갖는 object category의 long tail(?)을 다루는 데 효과적인 방법을 제공하였다. 우리의 접근법은 쉽게 VQA 태스크로도 확장될 수 있으며, 역시 좋은 성능을 보였다.
Code: github.com
1. Introduction
(아마 vision-language 관련 task에서)Object detection은 대부분의 state-of-the-art multi-modal understanding system의 통합으로 이루어져 있는데, 전형적으로 black-box로 쓰이곤 한다. detection system을 사용하는 이 유명한 접근법(어떤 구조를 얘기하는 지 알아볼 필요 있음들은 downstream multi-modal(여기서, 멀티모달이란 image와 text의 결합을 말한다) understanding task를 설명하지 못하고, 종종 성능에 있어서 bottleneck에 걸리곤 한다. 추가로, 이런 시스템은 모델의 인지 능력을 정교화하기 힘들고, 전체 이미지가 아닌 오직 detected object로의 접근만 하게끔 제한하는 frozen이라 할 수 있다(아마 pre-training 관련해 말하는 듯). 아무튼, 비전-언어 관련 모델에서는 이러한 문제점들이 자유 형식의 text로 표현되는 concept의 조합들을 이해하기 힘들게 만든다.
최근 연구들은 text-conditioned object detection이라는 문제를 고려한다. 이 방법들은 주로 one-state, 또는 two-stage detection 구조를 확장한다. 하지만 여전히 그런 detector는 VQA같은, detected object 너머의 추론이 필요한 downstream task들에서 성능을 향상시키진 못한다. 이는 이 detector들이 end-to-end 관점에서 미분가능하지 않고, 그렇기에 downstream task들과 시너지를 내며 학습될 수 없기 때문이라고 믿는다.
우리의 방법인 MDETR은 end-to-end로 모듈화된 detector이며, DETR detection framework를 기반으로 한다. 또한, 자연어 이해와 함께 object detection을 하기 때문에 진정한 end-to-end 멀티모달 추론을 할 수 있게 된다.
※ 이 연구는 visual-language task이기 때문에 image 그 자체보다는 visual reasoning에 필수적인 요소인 text에 더 중점을 두는 것 같다.
내 경우 text, image로 이루어진 멀티모달을 구현하는 것이 아닌, reasoning이 가미된 object detection을 구현하기 위한 아이디어를 얻는 것이기 때문에, 이를 중심으로 중간중간 중요해보이는 문장만 발췌하도록 하겠다.
2. Architecture
※ 논문의 단락과는 다릅니다.
해당 모델의 구조는 아래와 같다.

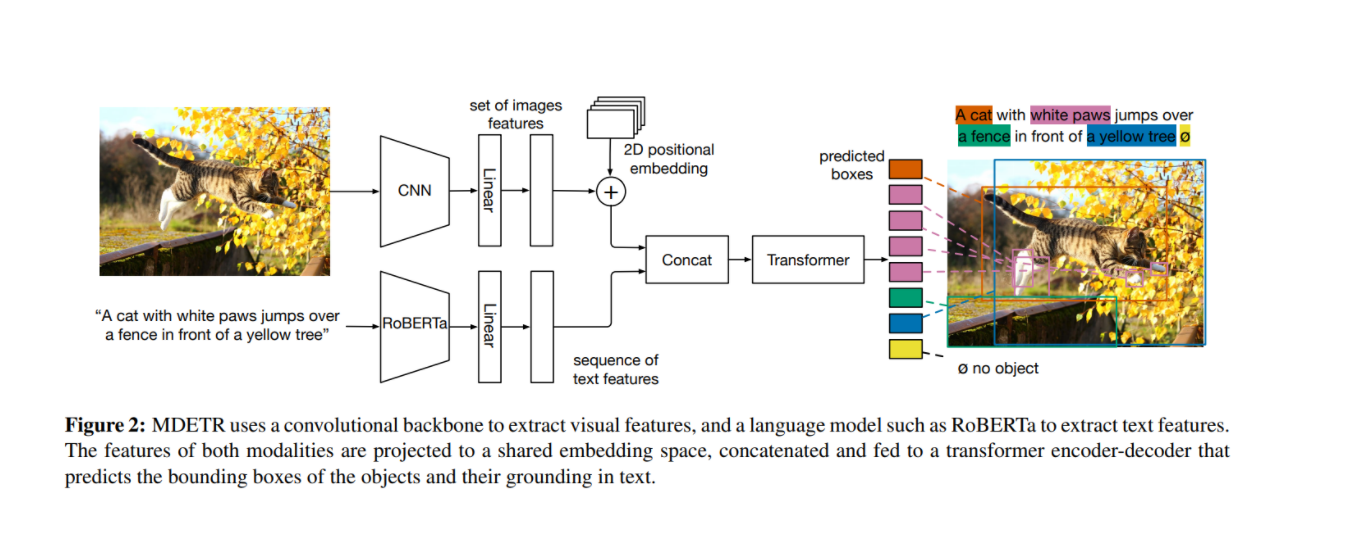
우선, 이미지는 convolutional backbone을 통해 인코딩되고, 그 후 flattened된다. 또한, 공간 정보를 보존하기 위해 2-D positional embedding이 이 flattened된 vector에 더해진다.
(text도 마찬가지로 트랜스포머 모델을 이용해 인코딩된다)
그 후, modality에 의존하는 linear projection이 image 및 text에 적용된 다음, 이 두개가 같은 embedding space를 갖게끔 프로젝션된다.
이 feature vector들은 single sequence가 되게끔 concat된다. 그 후, cross encdoer라 불리는 joint transformer encdoer에 투입된다. DETR 이후에, 우리는 cross encdoer의 final hidden state를 cross-attending하는 동시에 object queries에 transformer decoder를 적용한다. decoder의 output은 actual boxes를 예측하는 데 쓰인다.
3. Training process
MDETR에서는 두 가지의 loss function을 추가적으로 제안하는데, 이는 image와 text 사이의 할당(alignment)를 encourage하기 위해 쓰인다. 두 loss 다 'bounding box'에 할당된 'free from text'라는 같은 annotations을 사용한다.
-
soft token prediction loss : non parametric alignment loss
-
text-query constrastive alignment loss : parametetric loss function으로, token과 aligned object queries 사이의 유사성을 강화한다.
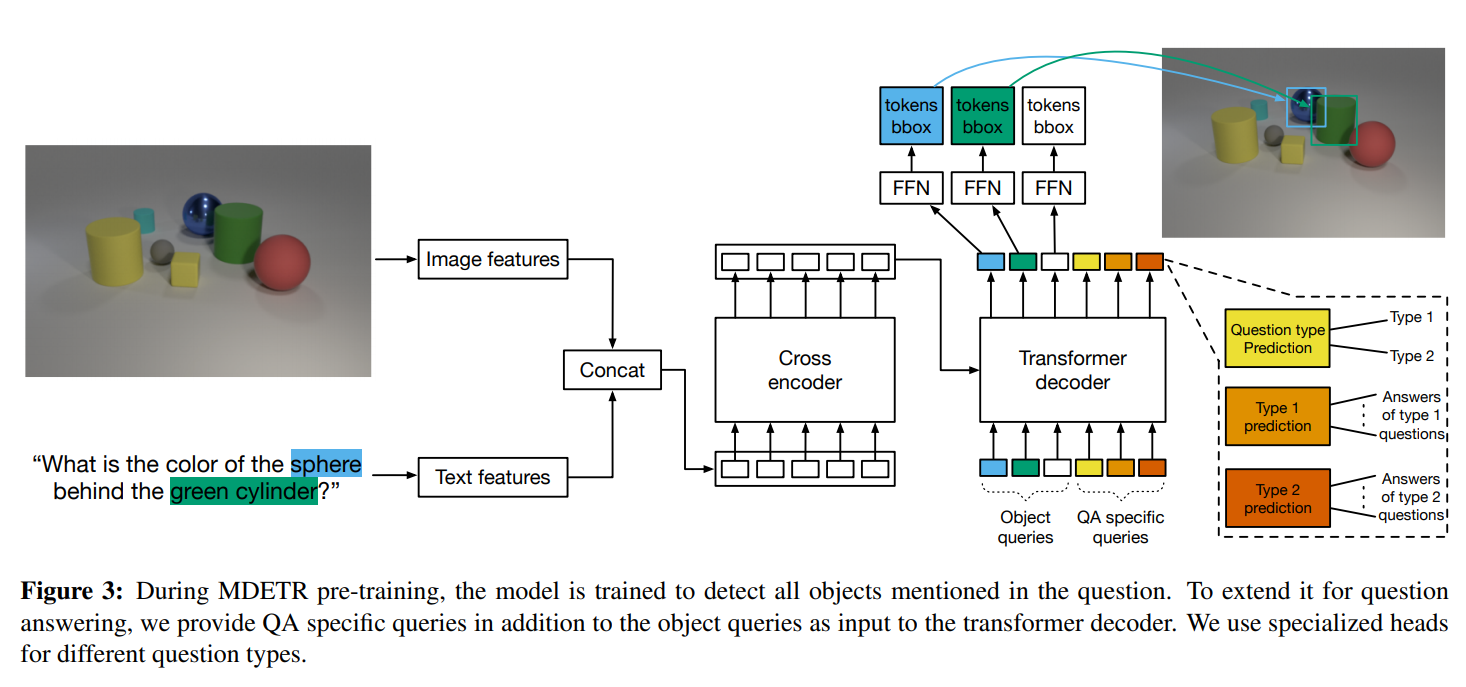
단, 이 학습과정 역시 text에 너무나도 의존하기 때문에, 학습 과정을 그림으로 첨부한 뒤 학습 과정에 대한 리딩은 마치도록 하겠다.
4. Backbone object detector
본 논문은, transformer 모델을 활용한 end-to-end detection model을 기반으로 한다. 기반이 되는 DETR 모델은 논문에서 볼 수 있다.
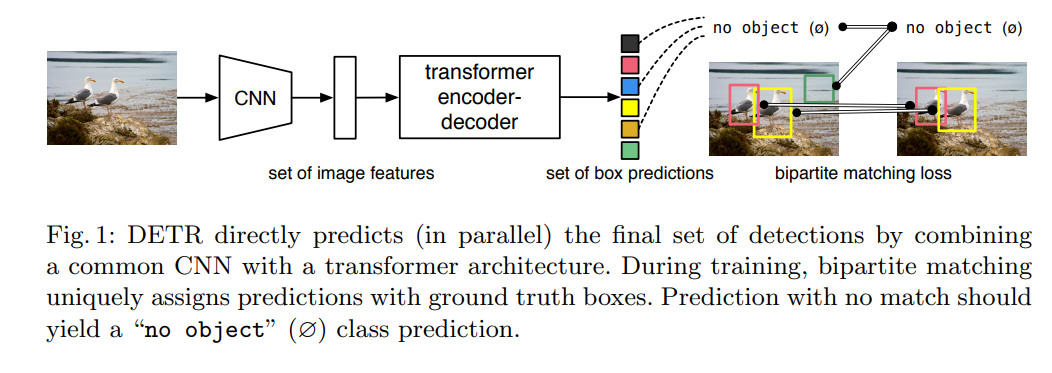
이는 CNN을 Transformer encoder-decoder와 결합해 bounding box를 예측한다.
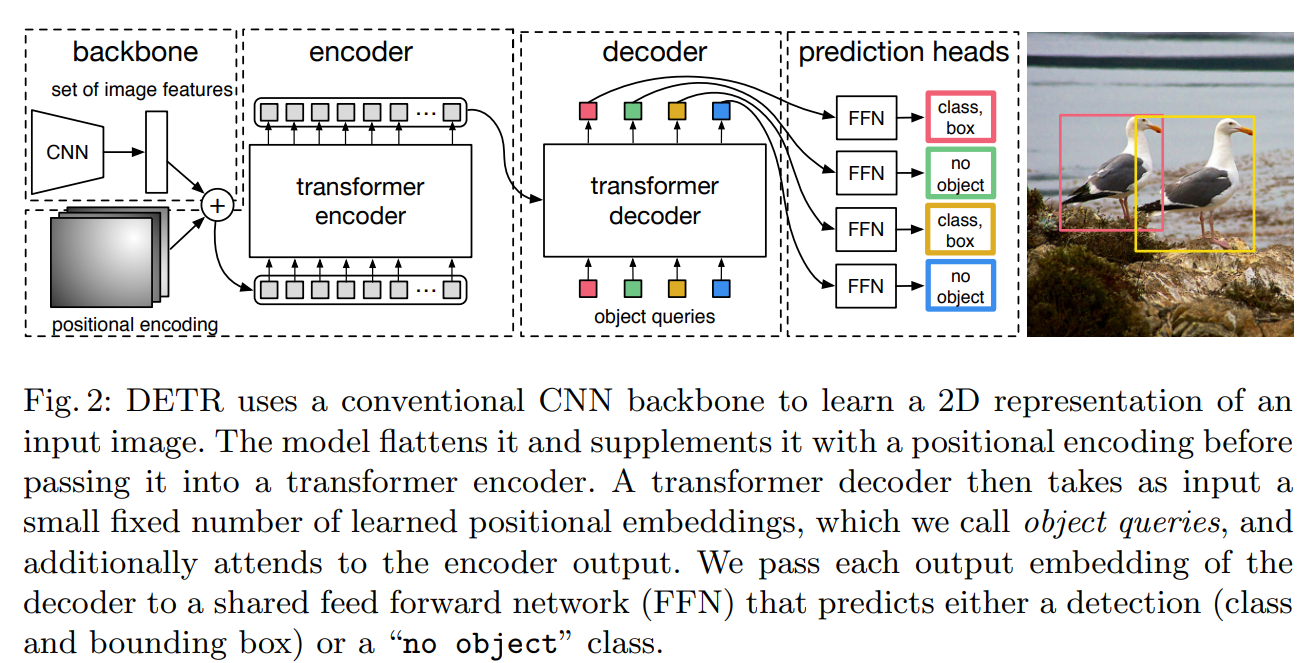
더욱 자세히 보면 아래와 같다.
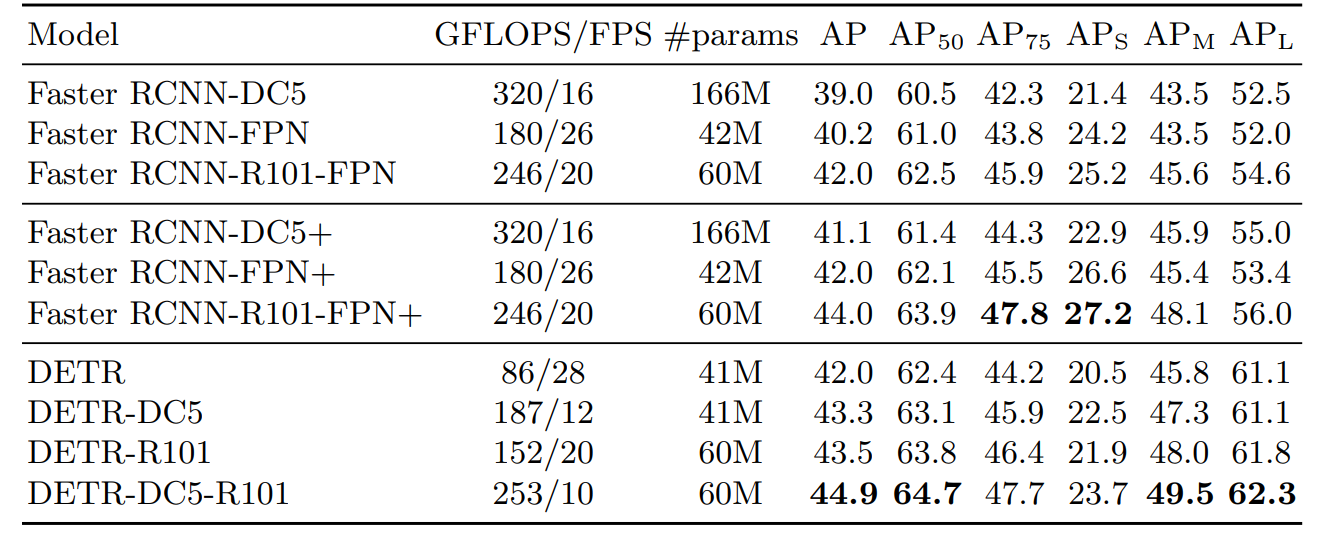
성능은 아래와 같다.
또한, Transformer 모델의 특성 상 self-attention을 확인할 수 있다.

Conclusion
DETR에 관해 리뷰한 글은 [논문리뷰]End-to-End Object Detection with Transformers에서 볼 수 있습니다.
