
전통 기계학습과 딥러닝에서의 비지도학습
전통적 비지도학습
K-means : 데이터를 몇 개의 클러스터로 나눠서 비슷한 특징을 가지는 군집을 형성하는 것
+ 이 외에도 계층적 군집화, Density Estimation, PCA
작은 차원의 데이터를 다룬다 / 단순하다 / 의미가 있나? (군집화 결과를 항상 검증해야함)
어쨌든 연구는 많이 진행되었지만 실전에서 적용되기엔 많은 검증이 필요하다
딥러닝에서의 비지도학습
힐튼 : Feature Engineering을 잘 하면 NN이 잘 작동할 수 있다.
실전에서 발생하던 일 : Input X에 대해 영향을 주는 수많은 요소가 있었지만 우리가 보는 건 X밖에 없음
- 이런 요소들을 잘 정리해주기 위해 Feature Engineer를 해줘야 함
- 딥러닝은 Feature Engineer 단계를 패스하게 해줌
- 인간이 결정을 안 해줘서 DL이 알아서!
- Representation Learning!!!! 정보 자체보단 모델에 대한 고민을 하게 됨
- 실전엔 Feature Engineer와 Representation Learning을 같이 함
Representation Learning
각도를 표현하는 방법 : 우리가 생각하는 각도의 개념과 알고리즘이 생각하는 각도는 다름
Ex) 우리 : 0이랑 2파이는 같지!!! / 알고리즘 : 이게 왜 같아,,,?
현실의 문제들을 “컴퓨터에게 어떻게 전달할까?” 가 핵심이 됨
- 근데 이 Rule을 사람이 정해서 전달해줘야 함
즉, Representation은 정보를 어떻게 표현할 것인가? X라는 개념을 수학적인 Rule로 표현하는 것.
인간이 알고리즘을 도와줘야 좋은 성능이 나올 수 있다.
DNN에서 발생하는 과정을 요약하면
인간이 Input을 좀 Process를 해서 주면 -> DL이 해결해주길 “기대” 하는 중
지금까지 학습 프로세스들은 결국 인간이 짠 Rule을 따라간다.
Representation과 딥러닝
어떤 Regularization을 사용하냐에 따라서 Activation의 Representation이 너무 크게 바뀜
- Representation이 Underconstrain 돼있음
- 정해진 게 없고, Representation 조건이 정해진 게 없다.
- 굿 뉴스 : SGD만 써도 좋은 성능을 낼 수 있음 / Representation에 특성을 입힐 수 있음 (자유롭게 학습을 시킬 수 있다)
- 배드뉴스 : 해석이 어려움. -> 성능이 잘 나와도 수학적으로 말하기 어려움
Task
잘 정의된 Task : 목표가 뚜렷하게 주어짐
Information Bottleneck
Input에서 내가 필요한 정보만 뽑아올 수 있을 수 있다!
근데 비지도 학습은 그 자체로 굉장히 애매모호함.
- Downstream Task를 정함
- 특정한 보상 규칙을 정해두고 거기에 맞게 Task를 풀어내도록 해내는 방식
- 이걸 과연 비지도학습이라고 할 수 있을까? : 아니라고 생각함…
- 그래도 일단 성능 지표를 하나 만들었다는 것에 큰 의의가 있음
- 가장 좋은 예시 : Word2Vec
- Transformer : Task를 정하는데, 문장의 단어 하나를 지우고 그걸 맞추라고 함
- 정답이 없었지만 원래 있던 걸 가렸기 때문에 지도학습처럼 됨
- 성능이 이렇게 하면 잘 나오더라!!
View Point
1. Representation은 해석 가능해야 하고 설명할 수 있어야 한다.
: 힐튼의 논문 – 문장만을 주고 학습을 시켰더니 모델이 그 내부에서 스스로 규칙을 만들더라!
=>인간이 그러하듯 신경망이 학습이 잘 되면 그 내부의 규칙을 만들어내는 것도 가능할 것이다!
Visualization : CNN 내부의 Filter들을 보니까 모델의 Representation을 볼 수 있더라!
- 그럼 학습한 걸 부숴버린다면 잘 안 되겠네? [개념을 잡는다고 하는데, 맨 위부터 Layer를 망가뜨리면 개념을 못 잡겠네?]
- 근데 Representation은 계속 잘 해내고 있었음
- 즉, 개념을 학습하고 있던 게 아니라 Edge Detector 역할만 했던 것이다… ㅠㅠ
그래도 XAI에선 최소한 예측에 대한 근거는 제시할 수 있게 해줌(Grad CAM)
OPEN AI는 그래도 믿음을 가지고 학습을 진행함
- 특정 input에 뉴런들이 반응을 특히 잘하는 현상을 발견하긴 함
2. Representation 솔직히 필요 없다.
: 왜 Intelligence가 항상 설명되어야 하느냐?
사람이 정보를 계속 정리해준 다음에 AI 성능을 보는 건 인간의 일을 보는 거다.
- 이건 AI가 아니야
인간의 결론 도달 과정이 진짜 “그 이유에서” 나왔을까? 하는 의문 - 이유를 물어보면 그제서야 이유를 만들어서 대답하는 거 아닐까?
- 인간조차 그럴 거 같은데,,, AI한테 왜 그걸 요구하지?
Unsupervised Representation Learning
k-means 아님!! ㅋㅋ 가장 중요한 단어는 Representation Learning
Pretext Learning
잘 정리된 Representation, 유용한 정보를 만들기 위한 학습 Task
Self-Supervised Learning
비지도는 아닌데, 학습 과정에서 스크립트 하나만으로 Reference를 만들어 학습
- 지도학습을 하기엔 레이블이 부족할 때 성능이 좋더라!
Contrastive Learning
각 Sequence를 정리해서 RNN에 넣어주면 미래의 것을 예측할 수 있다!
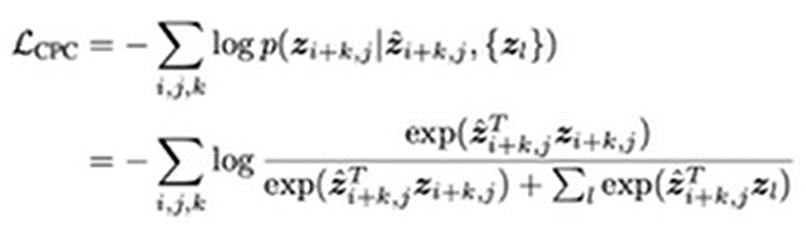
이 수식이 Unsupervised Representation Learning을 하는 데에 가장 기본이 되는 식이 되고 있음 [CPC]
- A와 B가 유사하다면 A에 대한 Representation Vector와 B에 대한 Representation Vector가 비슷하게 나와야 한다라는 의미를 지닌 식
Multiview Coding
같은 컨셉이라면 어느 방향에서 찍은 사진이어도 결국 같은 정보를 담고 있다
[자동차 왼쪽이나 정면이나 같은 개념]
- Representation한 Activation Vector는 비슷하게 생겨야 한다!!
- Augmentation을 통해 학습
SimCLR
: 개념을 학습시키기 위한 방법. 즉, 강아지의 여러 일부 사진을 보여주고 얘네를 Representation한 것들을 비슷하게 나와야 한다고 학습을 시킴
- Network Size에 상관 없이 기존의 모델 성능 압도
- Network가 크면 지도학습 수준의 성능을 발휘함
- 비지도학습은 제한된 조건 안에서 만든 문제에서는 엄청나게 좋은 성능을 내고 있다
