
XAI Part 1
최근 DL 모델들의 성능은 크게 향상하고 있음.
- But, 모델의 구조가 점점 복잡해지면서 이해하기가 점점 어려워짐
- 실무에선 AI가 내리는 결정을 그대로 따르기엔 무리가 있음
- Ex) AI의 편향성 : 특정 인종에 잘못된 판단을 내리는 것
- 왜 AI가 그런 판단을 내렸는지 이유를 설명할 수 있어야 함
이미지의 어느 부분을 보고 말이라고 판단 하였는지 보여주는 기법을 사용
- 말을 분류해내는 모델에 적용했더니 말 사진이 아니라 사진에 있는 텍스트 워터마크를 보고 판단하는 것을 발견해냄
- 이런 식으로 모델이나 데이터셋의 오류를 탐지해낼 수 있다!
설명 가능하다는 것은 뭘까?
: 구체적인 정의는 내려지지 않음. 다만 사람들이 이해 가능하도록 해주는 것 정도로만!
XAI의 분류
Local : 주어진 특정 데이터에 대한 예측 결과를 ‘개별적으로’ 설명
Global : 전체 데이터셋에서 모델의 행동 결과를 설명
White-Box : 모델의 내부 구조를 알고 있는 상태에서 설명
Black-Box : 입력과 출력만 알고 있는 상태에서 설명 시도
Intrinsic : 모델의 복잡도를 애초에 설명하기 좋은 상태로 제한한 다음에 학습시키고 설명
Post-hoc : 그냥 훈련을 끝낸 모델을 보고 설명하는 것
Model-Specific : 특정 모델에만 적용 가능
Model-Agnostic : 어느 모델에나 적용 가능
Linear Model이나 Decision Tree같은 경우
- Global, White-Box, Intrinsic, Model-Specific
딥러닝에 많이 쓰이는 Grad-CAM방식
- Local, White-Box, Post-hoc, Model-Agnostic
Saliency map-based
이미지가 모델에 들어가면 이미지에서 중요하게 작용한 부분을 히트맵으로 보여주는 거 !!
- Gradient로 설명을 제공

- 이렇게 각 픽셀의 Gradient로 중요도를 판단함!!
- 역전파로 쉽게 구할 수 있기 때문에 효율적이라고도 할 수 있음!!
- 같은 이미지이지만 약간 다른 이미지에 대해선 취약함 -> Noise에 취약함
- 그걸 극복하기 위해서 SmoothGrad라는 기법이 등장함

- 애초에 가우시안 분포로 되어있는 노이즈를 인풋에 섞어주고 Gradient를 여러번(보통 50번)계산하고 그것의 평균을 구함
- 중요한 픽셀들을 더 잘 잡아냄! // 물론 계산 복잡도가 엄청 높음
XAI Part 2
Saliency map-based 방식
CAM
Global Average Pooling을 이용하여 설명 제공
Global Average Pooling : FatureMap 자체의 평균을 구해내는 방법
- 각 Feature Map에 대해 선형 결합을 통해 최종 결합한 Feature Map을 구할 수 있고, 이를 Input Image와 합성시키면 어느 부분이 중요했는지 확인할 수 있음
근데 GAP을 하면 w과 h가 작아지니까 이를 Upsampling을 통해 극복

잘 설명하고 있음을 확인할 수 있음 -> Detection과 Segmentation에도 활용 가능 (Weakly Supervised Learning)
장점 : 해석이 용이하다
단점 : Model-Specific하다 -> GAP가 있는 모델에만 사용 가능
=> Grad CAM 등장
Grad CAM
CAM을 Gradient와 엮어서 설명! -> GAP가 없어도 됨
피쳐맵의 Gradient를 구하고 그 Gradient의 평균값들을 선형 결합하여 CAM을 구해냄
장점 : Model Agnostic 하다 (Gradient를 사용하는 어느 모델에나 적용 가능)
단점 : 평균 Gradient값이 꼭 중요도를 반영하지는 않음
Perturbation-Based 방식
입출력에 대한 정보만 가지고 있는 경우 사용하는 방식
- 입력 데이터를 조금씩 바꿔가면서 출력이 변하는 것을 보면서 설명하는 방식
LIME 방식 (Local Interpretable Model-agnostic Explanations)
분류기가 비선형적 특징을 가지고 있더라도 Data Point에 대해선 선형적으로 설명 가능하다

이런 식으로 여러 부분을 자르고 나서

이런 식으로 변형을 줌 => 변형을 준 input값만으로 예측을 어떻게 하냐에 따라 뭘 더 중요시 하는지 확인할 수 있음
- 장점 : Black-Box를 설명할 수 있는 장점이 있음
- 단점 : 여러 번 예측해야 하는 단점이 있음(계산 너무 많아!)
Randomized Input Sampling for Explanation (RISE)
랜덤한 MASK를 만들어서 이걸 input image에 씌워버림 -> 이 입력이 모델을 통과했을 때 예측 확률이 얼마나 떨어지는지를 확인
- 이 mask에 가중치를 적용해서 확인해보면 이미지에서 중요한 부분을 확인할 수 있다.
- 장점 : saliency-map 방식보다 더 확실하게 잡아낸다
- 단점 : 계산량이 너무 많다. Noisy한 경향이 있다.
Influence function-based 방식
지금까진 주어진 테스트 이미지가 있으면 분류를 하고 하이라이팅 하는 방식 -> 그러나 모델은 함수로 표현할 수 있으므로, Test 데이터를 추론할 때 가장 영향을 준 Training Data를 찾게하면 된다!!
여러 Training Image들 중에서 test image를 추론할 때 가장 큰 영향을 준 Training image를 뽑아줌
해당 Training image가 없을 때 해당 test image를 추론할 때 얼마나 큰 영향을 주는지를 계산함
XAI Part 3
Metrics
1. 사람들이 직접 보고 평가하는 것
AMT Test (Amazon Mechanical Turk)
사람이 모델의 해석본을 보고 모델의 예측을 맞춰보는 것
혹은 어느 쪽 설명이 더 나은지를 직접 고르게 하는 것
- 단점 : 비싸고 오래걸림
2. 이미 만들어 놓은 Annotation 을 이용하는 것
- Pointing Game : Bounding Box 활용
: 바운딩 박스 안에 해당 설명력이 높은 픽셀이 들어가 있는가? - Weakly Supervised Semantic Segmentation :
: 하이라이팅을 했을 때 Segmenation Pixel과 얼마나 겹치는지 IoU로 확인
단점 : annotation을 만들기가 애초에 어렵다 / bbox와 seg가 진짜 정답이라고 할 수 있을까?
3. Motivation
중요하다고 하는 부분을 지웠을 때, 얼마나 예측값이 떨어지는지 확인하는 것
- AOPC(Area Over the MoRF Perturbation Curve)
중요한 픽셀 순서대로 input을 교란(랜덤하게 바꿈)할 때 얼마나 바뀌는지 확인하는 기법
Insertion : 이제는 픽셀을 중요한 순서대로 하나씩 추가해가면서 성능을 보는 것
Deletion : AOPC와 비슷한 아이디어.
장점 : 사람이 개입 안 됨
단점 : 픽셀을 지우고 넣은 값은 training이미지와 분포가 달라짐 -> ML의 중요 가정 위반 - ROAR(RemOve And Retrain) : 지우고 나서 재학습 시키는 방식
: 좀 더 객관적이고 정확한 평가가 가능하지만 계산 복잡도가 엄청 높아짐
XAI의 신뢰성
Sanity Check
: 온전성 확인 -> 객체를 잘 찾는다고 해서 그게 설명을 잘 하는 건가?
Model Randomization Test : 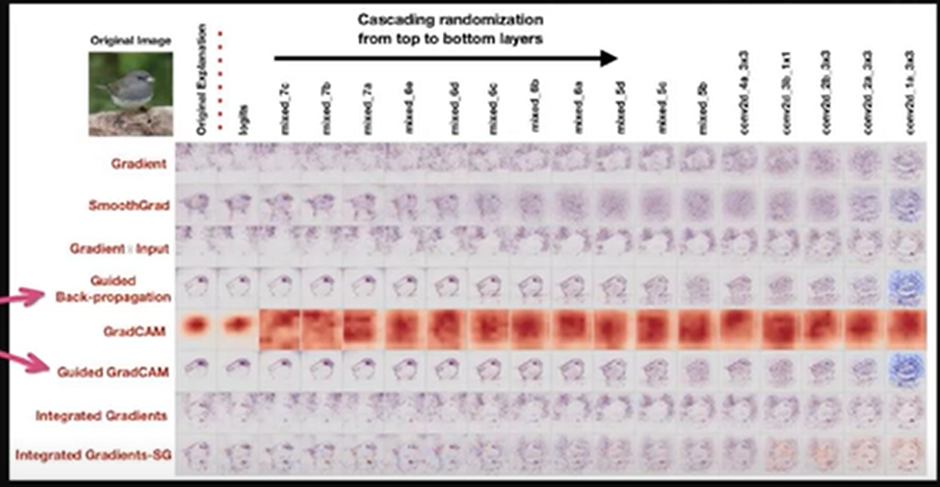
오른쪽으로 갈수록 계수들을 Random하게 바꾸고 함 -> 정상적이라면 오른쪽으로 갈 수록 예측 결과가 의미없게 나와야함
그런데 몇몇 애들은 그거랑 상관없이 나옴 -> 얘는 설명하는 게 아니라 Edge Detector로 기능하고 이었던 것이다!!
Adversarial Attack
입력 이미지의 약간의 변형을 가해 설명 방법을 완전히 다르게 바꿔버리는 것
많은 방식들이 Gradient와 연관되어 있는데 Decision Boundary가 삐쭉하게 되어있기 때문에 조금만 바뀌어도 크게 바뀌는 것
- Softplus function 이라는 활성화 함수를 사용하면 그나마 강건하게 만들 수 있다!
입력만 건드는 것이 아니라 Model 자체를 건드는 방법도 있음
파라미터만 조금 바꿈으로써 결과는 그대로 유지하되 덜 편향적이게 만들 수 있다는 얘기 - 중요하게 보는 요소를 바꿀 수 있다.
