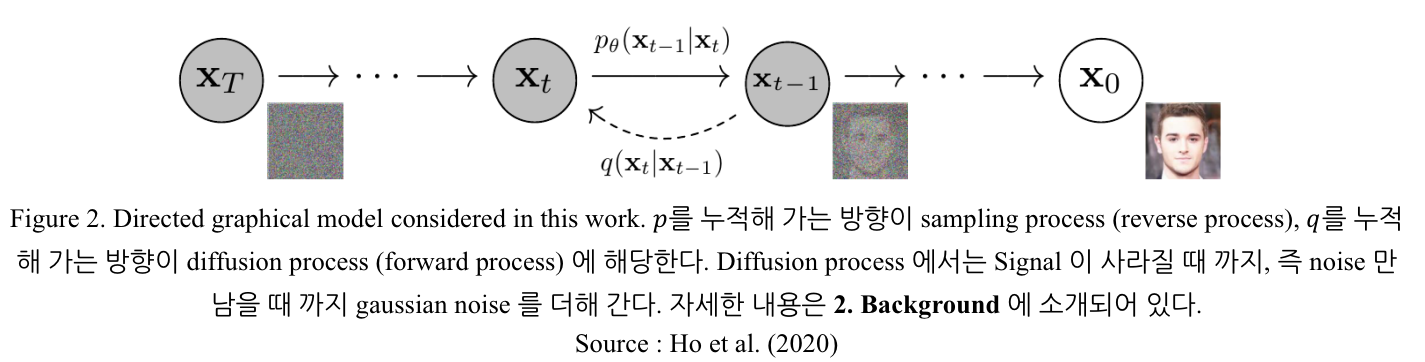
최근에 많은 연구가 이루어지고 있는 Diffusion Model 이 가장 먼저 제안된 논문 (Ho et al., 2020)을 리뷰해 보았다. Diffusion model 은 2020년에 처음 제안되었으며, 앞으로의 모든 포스팅에서 이 논문에서 제안된 Diffusion model 을 DDPM (Denoising Diffusion Probabilistic Model) 으로 표기할 예정이다.
1. Introduction
GAN, VAE, Flow model 과 같은 Deep generative model 들은 다양한 data 에 대해 높은 quality 의 sample 들을 생성하였다. 이미지 및 오디오를 합성하기까지 했으며, energy-based modeling 과 score matching 방법을 이용해서 GAN 의 성능을 넘어선 발전을 이루기도 하였다.
이 논문에서는 Diffusion probabilistic model (이하 “diffusion model”) 에 대해 소개한다. Diffusion model 은 매개화된 마르코프 체인으로, 일정한 시간 간격 이후의 data에 대응(match) 되는 sample 을 생성하는 variational inference 를 이용해 학습되었다. Chain 간의 transition 은 diffusion process 를 역행하도록 학습된다. 이 때 Diffusion process 란, signal 이 사라지지 않을 때 까지 data 에 noise 를 추가하는 마르코프 체인 과정을 의미하며, noise 는 sampling 과정의 역순으로 추가된다. 만약 diffusion 과정에서 작은 gaussian noise 가 지속적으로 더해진다면, sampling 이 일어나는 chain transition 을 conditional gaussian noise 가 추가되는 과정으로 볼 수 있으며 인공 신경망 매개화를 부분적으로 적용할 수 있다.
Diffusion model 은 straightforward 하게 정의되며 효율적으로 학습시킬 수 있지만, (논문이 쓰여진 시점 기준) 현재로서는 해당 모델이 높은 quality 의 sample 을 생성한다고 보장할 수는 없다. 따라서 이 논문에서는 diffusion model 이 충분히 높은 quality 의 sample 을 생성할 수 있으며, 때로는 4. 절에 제시되어 있는 기존 생성 모델보다 더 나은 결과를 산출한다는 것을 보일 것이다. 더 나아가, diffusion model 에 특정한 매개화를 적용하는 경우는 다음 두 가지 case 와 동치 (equivalent) 임을 보인다.
1) Diffusion model 의 학습 (Training) 과정이, multiple noise 에 대한 denoising score matching 와 동치
2) Diffusion model 의 sampling 과정이, annealed Langevin dynamics 와 동치
논문의 저자들은 4.2 절에 소개된 매개화 기법을 이용해 가장 좋은 sampling quality 를 얻었으며, 위에 나타난 동치성을 이 논문의 주요 성과로 소개하고 있다.
Diffusion model 은 양질의 sample 을 생성함에도 불구하고, likelihood 를 기반으로 하는 다른 모델들과 경쟁할 만한 log-likelihood 를 가지지 않는다. 또한, Diffusion model 은 이미지의 미세한 부분까지 묘사할 수 있음을 발견하였다. 논문에서는 현상을 ‘손실 압축 (lossy compression)' 이라는 개념을 이용해 더 정교하게 분석하며, diffusion model 의 sampling 과정은 progressive decoding1 의 한 종류임을 보인다. 이는 순차적으로 일어나는 autoregressive decoding2 과 유사하며 autoregressive model 에서 일반적으로 나타날 수 있는 현상을 일반화하는 형태이다.
2. Background
Diffusion model 은 latent variable 을 가지는 model 이며, 그 형태는 다음과 같다.
pθ(x0):=∫pθ(x0:T)dx1:T
위 식에서 x1,x2,⋯,xT 는 data x0∼q(x0) 와 같은 차원을 가지는 latent variables 이다. pθ(x0:T) 는 joint distribution 으로 reverse process 라고 지칭하며, Gaussian transition 들로 학습된 마르코프 체인으로 정의된다. 이 때 Gaussian transition 은 다음과 같이 정의된다.
pθ(x0:T):=p(xT)t=1∏Tpθ(xt−1∣xt)
p(xT)=N(xT:0,I)
pθ(xt−1∣xt):=N(xt−1;μθ(xt,t),Σθ(xt,t))
Diffusion model 과 다른 latent variable model 과의 차이점은 approximate posterior q(x1:T∣x0) 에 있으며, 이를 forward pass 또는 diffusion process 라고 한다. 이는 Gaussian noise 를 지속적으로 더하는 마르코프 체인 과정을 따르며, gaussian noise 의 variance 는 β1,β2,⋯,βT 에 의해 결정된다. 구체적인 수식은 다음과 같다.
q(x1:T∣x0):=t=1∏Tq(xt∣xt−1)
q(xt∣xt−1):=N(xt:1−βtxt−1,βtI)
x0∼q(x0)
즉, 우리가 이미지를 얻기 위해서는 q(xt−1∣xt) 의 값이 필요하지만, 이 값은 intractable 하다. 따라서 이를 parameterized neural network pθ 를 이용해 표현하는 것이다. 뒤에서 다루겠지만, 현 시점에서 정성적으로 논해 보자면 pθ(xt−1∣xt) 와 q(xt−1∣xt) 의 ‘거리’ 를 가깝게 하는 것이 최종적인 학습의 목표이며, 이를 위해 다양한 trick 을 사용해 computational advantage 를 부여한다. 3. 절 및 4.3. 절에서 이와 관련된 추가적인 논의를 진행한다.
모델 학습은 negative log-likelihood 로 정의된 일반적인 variational bound 를 최소화시키는 방향으로 진행된다. 수식으로 나타내면 아래와 같다.
이 부분은 VAE 의 lower bound 를 증명하는 부분과 유사하다. Diffusion model 이 auto-regressive model 인 점과 Figure 2. 로부터, VAE의 latent variable Z 가 여기서는 x1:T 에 해당되고 VAE data point Xi 가 x0 에 대응된다고 생각하면 그 과정은 동일하다.
Forward process 의 분산 βt 는 재매개화 (reparameterization) 을 통해 학습되거나 모델의 hyperparameter 로써 상수로 유지될 수도 있다. 또한 reverse process pθ(x0:T) 의 expressiveness (표현력, 여기서는 performance 와 유사한 개념으로 해석) 는 pθ(xt−1∣xt) 가 나타내는 conditional gaussian distribution 에 의존한다. βt 가 작을 때, forward / reverse process 모두 같은 함수 형태를 나타내기 때문이다. Forward process 의 중요한 특징은, 임의의 timestep t 에서 xt 를 sampling 한 결과를 closed form 으로 나타낼 수 있다는 점이다. αt:=1−βt, αtˉ∶=∏s=1tαs 로 치환하면
결과적으로 KL-Divergence 를 이용한 식에서, forward process 의 posterior q(xt−1∣xt) (measure 할 수 없는 값) 와 pθ(xt−1∣xt) 를 직접적으로 비교할 수 있다. Posterior 는 q(xt−1∣xt) 자체로는 계산할 수 없지만, x0 에 대한 condition 이 주어졌을 때 베이즈 정리를 이용해 계산 가능하며 그 값은 아래와 같다.
Diffusion model 은 마치 latent variable model 중 제한된 일부만을 나타내는 것처럼 보이지만, 그 구현에 있어서는 자유도가 매우 높다. 구현을 위해서는 다음과 같은 값들을 결정해야 한다.
1) 분산 βt
2) 모델 구조
3) Reverse process 에서 나타나는 Gaussian distribution 의 매개화 (μθ(xt,t),Σθ(xt,t) 부분)
논문의 경우, diffusion model 과 denoising score matching 간의 직접적인 연결을 도입하였으며, 이를 통해 simplified, weighted variational bound L=LT+∑t=1T−1Lt+L0 를 유도하였다. 이러한 design 이 적합함을 단순함 (simplicity)과 경험적인 결과 측면에서 보였다.
3.1. Forward process and LT
우선, 3.1. 에서는 βt 를 모두 학습 불가능한 상수로 가정한다. 따라서 이 경우 approximate posterior q(x1:T∣x0) 에는 학습 가능한 파라미터가 존재하지 않으므로 (q(x0) 의 경우 Data 의 분포이므로 역시 학습가능한 파라미터에서는 제외된다), 그 값은 상수이며 LT 역시 학습이 진행되는 전 과정에서 상수이다. 따라서 optimization 관점에서는 LT 가 무시될 수 있다.
3.2. Reverse process and L1:T−1
3.2.1. Training
이제 1<t≤T 에 대해, pθ(xt−1∣xt):=N(xt−1:μθ(xt,t),Σθ(xt,t)) 를 결정하는 과정을 살펴보자. 첫 번째로,
Σθ(xt,t)=σt2I
와 같이 timestep 에만 의존하고 학습되지 않는 상수로 두자. σt2 값의 경우, 두 가지 값 (βt 와 1−αˉt1−αˉt−1βt)을 모두 시도해 본 결과 유의미한 차이는 나타나지 않았다.
두 번째로,
μθ(xt,t)
을 고려해 보자. 위 항의 경우, 특정한 매개화를 통해 나타낼 수 있으며 (θ에 대해 parameterized 된 neural networks 를 이용) 매개화 된 모델은 위에서 계산한 forward process posterior mean μtˉ(xt,x0) 를 예측한다. KL-Divergence 의 정의를 생각해 보았을 때 t=2,3,⋯,T 에 대해 두 분포 q(xt−1∣xt,x0) 와 pθ(xt−1∣xt) 의 ‘거리’ 가 가까워야 하므로 pθ의 평균값이 q(xt−1∣xt,x0) 의 평균값 μtˉ(xt,x0) 와 ‘가까워져야’ 하는 것이다.
결과적으로 pθ(xt−1∣xt):=N(xt−1:μθ(xt,t),σt2I), q(xt−1∣xt,x0)=N(xt−1:μtˉ(xt,x0),βtˉI) 에 대해 Lt−1 을
위 식에 pθ(xt−1∣xt), q(xt−1∣xt,x0) 의 정규분포 식을 대입하면 Lt−1 에 대한 식을 얻을 수 있다.
C는 parameter θ에 의존하지 않는 항들을 모두 expectation 밖으로 정리한 상수이다. 이 때 위 식을 더욱 계산하기 적합한 형태로 정리할 수 있다. q(xt∣x0)=N(xt:αtˉx0,(1−αtˉ)I) 에 reparameterization trick 을 적용해 보자. ϵ∼N(0,I) 에 대해 xt(x0,ϵ)=αtˉx0+1−αtˉϵ 로 치환하면
Distribution q에 대한 expectation 이 x0,ϵ 에 대한 expectation 으로 치환된다. 첫 번째 등호는 단순히 변수 치환을 이용해 식을 전개한 것이고, 두 번째 등호의 경우 위에서 계산한 forward process posterior mean μtˉ(xt,x0) 에 대한 식을 대입해 계산한 결과이므로 성립한다.
Computational 관점에서 더욱 계산하기 간결한 형태로 정리할 수 있다. 위 식으로부터 매개화된 μθ 의 예측 결과값이
αˉt1(xt−1−αtˉβtϵ)
가 되어야 한다는 점을 알 수 있다. 아래 식과 같은 매개화를 생각하자. μθ는 xt에 의존하므로, xt 로부터 우리가 가정한 분포 ϵ을 예측하는 functional approximator ϵθ network 를 생각하자. 즉 ϵθ 내부의 파라미터 값을 학습시켜, μθ 의 예측값이 목표한 값이 되도록 매개화 한 것이다.
와 같이 나타난다 (단, t=2,3,⋯,T). 위 식은 Langevin-like reverse process 의 variational bound 와 같다. 3.4. 절에서 더 간결한 형태의 training object 를 유도하고, 구체적인 학습 알고리즘에 대해 설명을 이어 나간다.
3.2.2. Sampling
이제 Sampling process 를 살펴보자. xt 로부터 xt−1 을 sampling 하면 되므로 이에 관련된 분포를 다시 한번 살펴보자.
pθ(xt−1∣xt):=N(xt−1:μθ(xt,t),σt2I)
μθ(xt,t)=αt1(xt−1−αtˉβtϵθ(xt,t))
여기서도 reparameterization trick 을 사용하면 분포
z∼N(0,I)
에 대해
xt−1=αt1(xt−1−αtˉβtϵθ(xt,t))+σtz
을 계산하는 과정이 바로 sampling 이다. ϵθ의 경우 train된 network 이므로 ϵθ(xt,t) 의 값은 direct 하게 구할 수 있다. t=T,T−1,⋯,1 에 대해 위 과정을 반복하며, 이를 pseudo-code 로 나타내면 아래와 같다.
3.2.3. Summary
Reverse process (noise 로부터 image 를 sampling 하는 과정) 은 두 가지 방법 중 하나를 이용해 학습시킬 수 있다.
1) θ-parameterized reverse process mean function approximator μθ 가 q(xt−1∣xt,x0) 의 평균값 μtˉ(xt,x0) 에 가까워지게 끔
2) 재매개화를 통해 functional approximator ϵθ network 를 학습시킨다 :
μtˉ(xt,x0)=αt1(xt−1−αˉtβtϵθ(xt,t))
위 두 가지 방법 모두 pθ(xt−1∣xt) 의 매개화를 이용하는 방법이다. 4. 절에서 2) 의 방법이 1)의 방법보다 더 효과적임을 보인다. 분포 ϵ 를 예측하도록 하는 것은 training 과정의 object ( = variational bound) 를 denoising score matching 의 object 와 동일하게 만들고, sampling 과정이 Langevin dynamics 가 되게 해 준다. 이 내용에 대해서는 Score-Based Generative Modeling through Stochastic Differential Equations 논문을 참고하자.
3.3. Data scaling, reverse process decoder, and L0
모든 이미지의 픽셀 값은 [-1, 1] 로 scaling 되었다고 가정한다. 이는 p(xT) 로부터 시작되는, 모든 reverse process 가 항상 scaling 된 input 에 대해 일어난다는 것을 보장한다. 또한 이산적인 log-likelihood 를 얻기 위해, reverse process 의 가장 마지막 과정 (x1 으로부터 x0 를 sampling 하는 과정) 은 정규분포 N(x0;μθ(x1,1),σ12I)를 사용하는, 이전과 독립적인 discrete decoder 를 이용한다.
D 는 데이터의 차원을 의미한다. 비록 conditional autoregressive model 처럼 매우 powerful 한 decoder 를 사용할 수도 있지만 이 논문에서는 해당 아이디어를 사용하지는 않았다. VAE 의 decoder 와 같이, 논문에서 정의한 decoder 는 Diffusion model 의 variational bound 가 data 에 별도로 noise 를 더하거나 log-likelihood 에 scaling 연산에 대한 야코비 행렬을 대입하지 않아도 이산적인 데이터의 lossless codelength 가 됨을 보장해 준다. Sampling 의 마지막 단계에서는 μθ(x1,1) 에 별도의 noise 를 추가하지 않고 이를 그대로 출력한다. 위 내용으로부터
L0=−logpθ(x0∣x1)
를 얻을 수 있다.
3.4. Simplified training object
3.1. 절 부터 3.3. 절 까지의 과정을 통해 얻은 variational bound (Lt,L0) 는 모두 θ 에 대해 미분 가능하고 학습 과정에서 사용된다. 그러나, 아래 식과 같은 variational bound 의 ‘변형’ 을 이용해 학습한다면 더욱 간단한 구현 과정을 통해 동일한 performance 를 얻을 수 있음이 확인되었다.
모든 실험 과정에서 T=1000 으로 설정하였다. Forward process 의 분산 βt 들은 모두 상수로 두었다. β1=10−4, βT=0.02 로 두고 다른 값들은 linear scale 로 계산하였다. 위 값들은 xT의 SNP 가 충분히 작은 값이 되게끔 설정한 값들이다.
LT=DKL(q(xt∣x0)∣∣N(0,I))≃10−5
Reverse process 에 사용된 NN 의 경우, U-Net 을 기반으로 한 PixelCNN++ 의 구조를 기반으로 구현하였다.
weight normalization 대신 group normalization 사용
Self-attention block 도입
Time step t의 경우 Transformer 에서 도입된 positional encoding 을 기반으로 사용
CIFAR10, LSUN, CelebA-HQ Dataset 에 대해 학습 진행
4.1. Sample quality
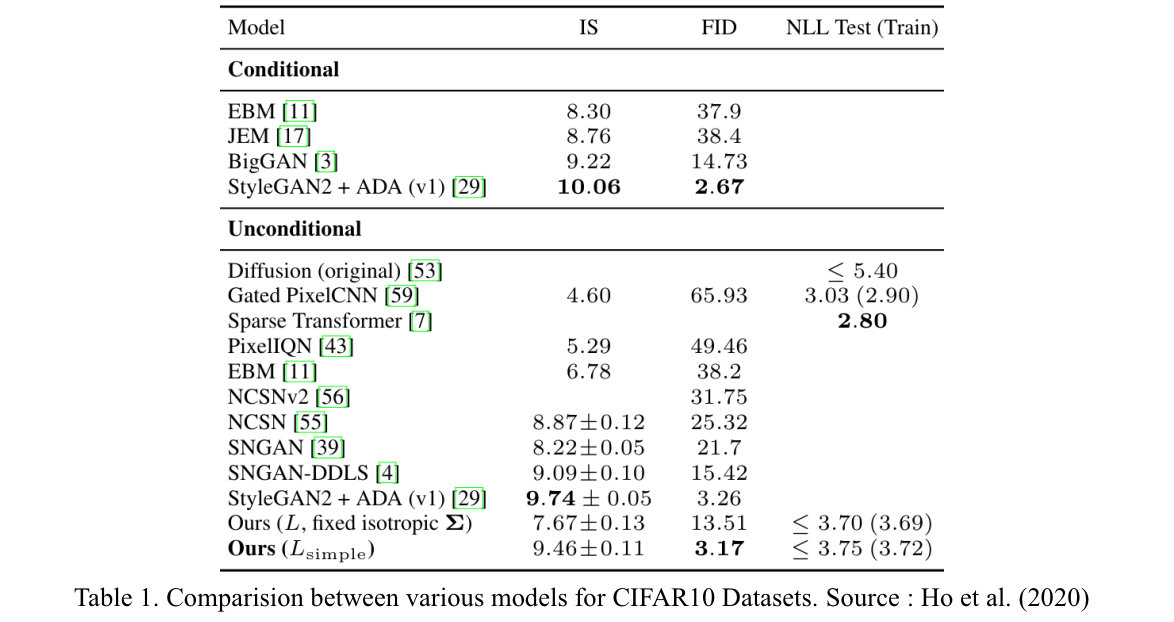
Diffusion model 의 FID score 는 다른 논문에서 제시된 모델들과 비교했을 때 높은 값을 나타냈다.
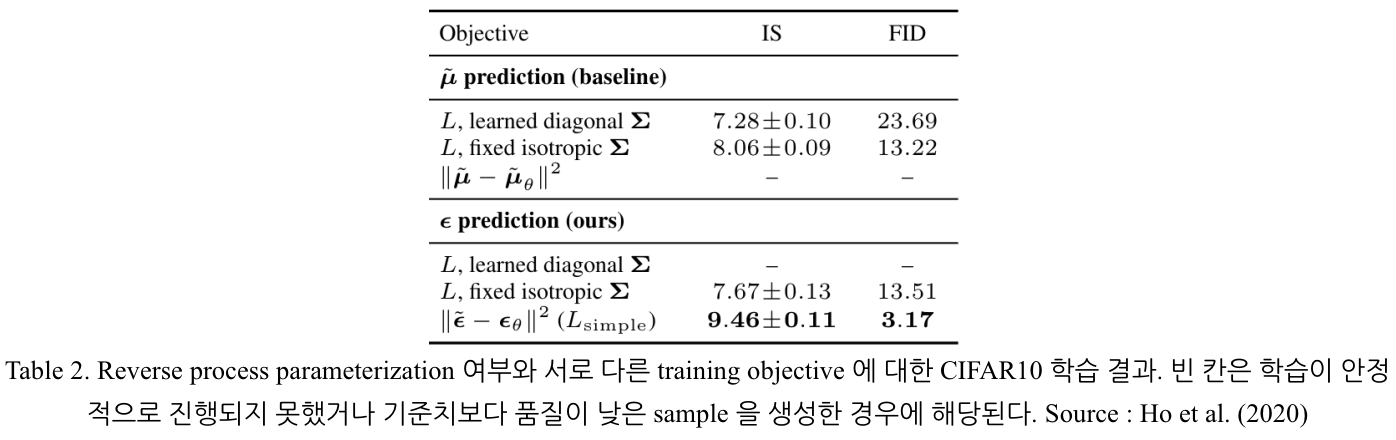
4.2. Reverse process parameterization and training object ablation
직접 μˉ 값을 예측 시키는 경우, Simplified learning object 처럼 RMSE 를 이용하는 경우 (∣∣μ−μθˉ∣∣2) 학습이 진행되지 않았으며 simplify 되기 전의 true variational bound 를 이용하는 경우에만 학습이 진행됨이 확인되었다.
Variational bound 에 Σθ(xt) 에 대한 항을 직접적으로 포함시키고 대각행렬 Σθ 자체를 학습시키는 것은 높은 성능을 가져다 주지 못함이 확인되었으며, 학습 역시 불안정하게 진행되었다. 따라서 3.2.1. 절에 나타난 바와 같이, 분산 σt2 을 고정된 상수 βt 또는 1−αˉt1−αˉt−1βt 로 두고 학습을 진행하였다.
가장 좋은 FID Score 는 Lsimple 을 training object 로 이용한 경우에 얻어졌다.
4.3. Progressive coding
Table 1. 에는 CIFAR-10 데이터셋에 대한 모델의 성능과 실행 속도에 대한 지표 (codelength, Table 1. 상에서 NLL)가 bits/dim 단위로 나타나 있다. Train 과 test 의 차이는 최대 0.03 bits/dim 으로, 이때까지 발표된 likelihood 기반의 모델들과 비교할 만한 값을 나타내며 과적합이 일어나지 않았다는 것을 알 수 있다. 그러나, codelength 가 다른 likelihood 기반의 생성 모델 (Sparse transformer 등)에 비해서는 뒤쳐진다. 이에 대한 자세한 내용은 부록 D 에 서술되어 있다.
그럼에도 불구하고 논문에서 제시한 DDPM 은 높은 품질의 샘플을 생성하므로, diffusion model 이 좋은 lossy compressor 로 써 작용하게 하는 inductive bias4 가 존재한다고 결론지을 수 있다. L0 를 distortion 으로 취급하고, L1+L2+⋯+LT 를 rate 로 본다면 CIFAR-10 데이터셋에 대한 모델의 rate 는 (전체 NLL 3.75 중) 1.78 bits/dim, distortion 은 1.97 bits/dim5 이다. 즉 codelength 의 절반 이상 (1.97/3.75>0.5)이 imperceptible distortions 을 표현한다.
4.3.1. Progressive lossy compression
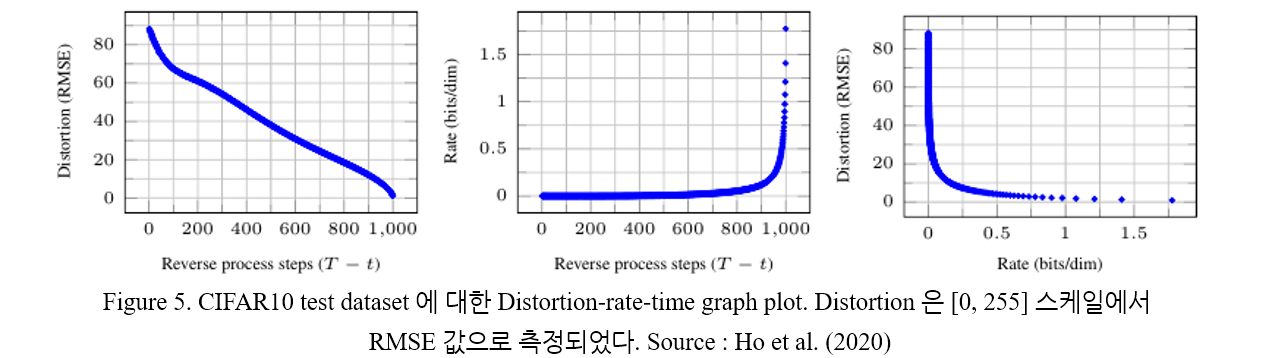
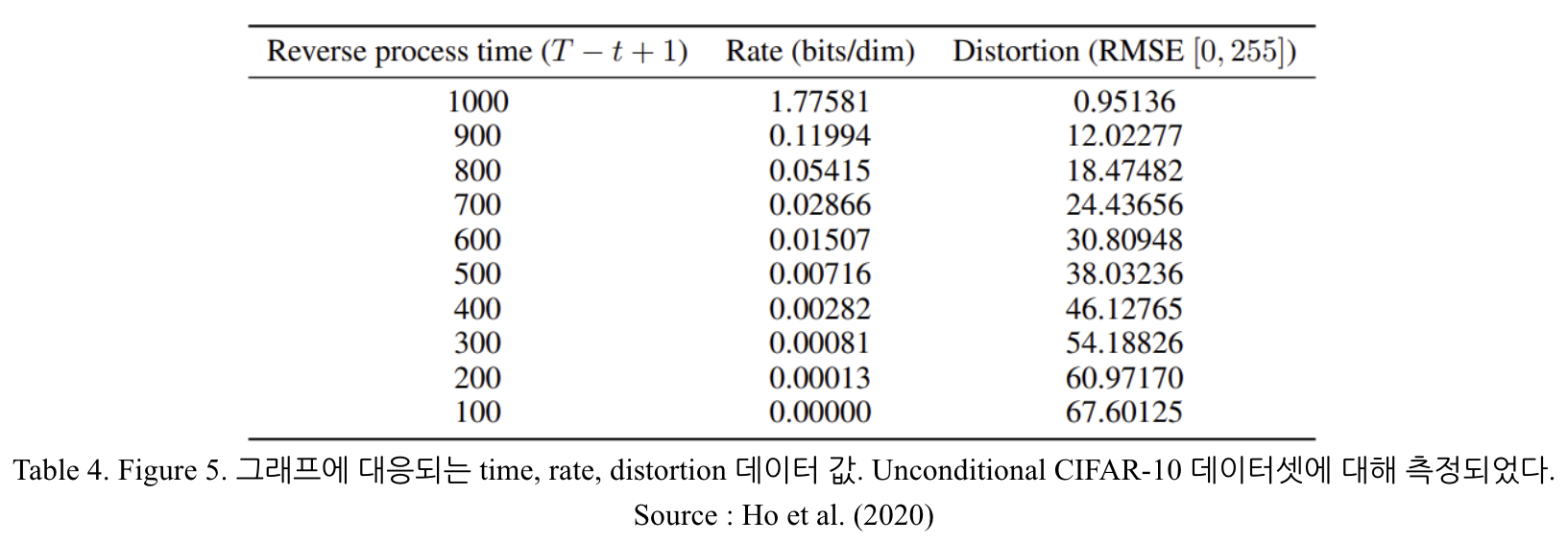
Diffusion Model 의 training object 에 대응되는 lossy compression 을 통해, rate-distortion 양상을 조사해 볼 수 있다. 우선 다음과 같은 Algorithm 3, 4 를 생각해 보자.
Algorithm 3, 4 는 임의의 두 분포 p,q 에 대해 receiver 에 주어진 분포가 p 뿐일 때 (즉, 분포 q가 주어지지 않았을 때) DKL(q(x)∣p(x)) 의 bit 로 x∼q(x) 를 sampling 하는 과정을 나타낸다. x0∼q(x0) 가 주어졌을 때, Sender 에서는 xT,xT−1,⋯,x0 를 순차적으로 Receiver 에게 보낸다. 각각은 pθ(xt∣xt+1) 을 이용해서 sampling 된다. Receiver 에서는 순차적으로 receive 되는 각각의 xT,xT−1,⋯ 에 대해 순차적으로 x0 를 estimate 한다. 앞서 xt=αˉtx0+1−αˉtϵ 와 같이 치환했으므로,
x0≃x0=(xt−1−αtˉϵθ(xt))/αtˉ
와 같이 estimate value 를 산출할 수 있다. 물론
x0∼pθ(x0∣xt)
를 이용한 stochastic reconstruction 을 진행할 수도 있지만, computation 이 복잡하기에 논문에서는 다루지 않는다. 이 때 매 timestep t 에서 distortion 의 경우 RMSE 값으로 정의되어
distortion=RMSE=D∣∣x0−x0∣∣2
와 같이 계산되고, rate 는 "Timestep t 까지 receive 된 bit 수의 누적 합" 으로 계산된다. Timestep 이 경과함에 따라 distortion 이 감소하고, rate 가 증가하는 과정이 Figure 5. 에 나타나 있다. Rate-distortion 그래프의 경우, rate 값이 낮은 영역에서 distortion 값이 급격하게 감소하는 양상이 나타난다. 이는 대부분의 bit 가 imperceptible distortion 에 할당되어 있음을 나타낸다. 이 부분에 대한 자세한 내용은 LDM 을 소개한 Rombach et al. 2022 에도 나타나 있다.
4.3.2. Progressive generation
Figure 6. 은 Algorithm 2 를 이용한 sampling (reverse process) 의 각 시점에서 x0를 추출해보자. 큰 scale 의 feature (전체적인 이미지의 형태) 가 먼저 생성되고, 세부적인 부분이 나중에 나타나는 것을 확인할 수 있다.
Figure 7. 은 여러 가지 값의 t에 대해 x0∼pθ(x0∣xt) 를 추출한 결과를 보여준다.
작은 값의 t에 대해서는 세부적인 detail 이 모두 유지된 반면, 큰 값의 t에 대해서는 전체적인 이미지 형태만 보존된다. 이를 통해 conceptual compression 에 대한 아이디어를 얻을 수 있다.
이 때, T=D 로 두는 상황을 생각해 보자. Forward process 의 q(xt∣xt−1) 이 t-th pixel 을 mask out 하도록 해당 과정을 정의하면, p(xT) 는 noise 만이 존재하는 black image 가 되고 Reverse process 의 경우 매 step 마다 하나의 pixel 을 sampling 하게 된다. 따라서,
DKL(q(xT)∣∣p(xT))=0
이 성립하고,
minimizeDKL(q(xt−1∣xt)∣∣pθ(xt−1∣xt))
와 같은 과정을 통해, pθ 가 t+1,t+2,⋯,T step 의 pixel 을 copy 하고 t+1,t+2,⋯,T step 의 pixel 값을 이용해 t step 의 pixel 을 예측하는 방향으로 학습된다. 결과적으로, T=D 와 같은 설정이 적용된 Diffusion model 에서 pθ 가 학습되는 과정은 autoregressive model 을 학습시키는 과정이다. 결과적으로 Gaussian Diffusion model 을 autoregressive model 의 한 종류로 해석할 수 있다.
4.4. Interpolation
Source image x0 와 x0′∼q(x0)(=distributionofdatapoints) 를 latent space 에서 보간할 수 있다 (단 q는 stochastic encoder). 각각의 latent space representation 을 xt,xt′∼q(xt∣x0) 라고 하면, linearly interpolated latent xˉt 를
xˉt=λx0′+(1−λ)x0
와 같이 정의하고 이에 대해 reverse process 를 적용해
xˉ0∼p(x0∣xˉt)
를 얻을 수 있다. 이 과정이 Figure 8. (Left) 에 나타나 있다. Figure 8. (Right) 에 256×256 size 의 CelebA-HQ 이미지에 대한 보간 결과가 나타나 있다. 서로 다른 λ 값을 이용해 보간을 진행하였으며, 이 때 모든 과정에서 xt 와 xt′ 을 같게 해 주기 위해 noise 는 고정시켰다.
더 큰 값의 T 를 사용해 다양한 보간 결과를 얻을 수 있다. Appendix D. 에 결과가 제시되어 있다.
6. Conclusion
이 논문에서는 높은 품질의 이미지를 생성하는 Diffusion model (DDPM) 을 소개하였다. DDPM 과 마르코프 체인과의 관련성을 논하였으며, 학습 과정이 denoising score matching 을 따르고, inference 과정이 annealed Langevin dynamics 와 동치라는 점 역시 논하였다. 더 나아가, diffusion model 이 lossy compression 및 autoregressive decoding 의 관점으로 해석될 수 있다는 점 역시 보였다. Diffusion model 이 이미지에 대해 좋은 inductive biases 를 가지는 것으로 보이며, 새로운 종류의 생성 모델로서 다른 데이터와 결합되어 사용되거나 후속 연구가 진행되기를 기대한다.
Reference
[1] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. arXiv Preprint arXiv:2006.11239 (2020).
4: Inductive bias is the set of assumptions that the model uses to predict outputs of given inputs that it has not encountered. (Wikipedia, Inductive bias, https://en.wikipedia.org/wiki/Inductive_bias). In case of CNN, translation invariance is corresponding inductive bias.