자료구조
1.[자료구조] Data Design and Implementation
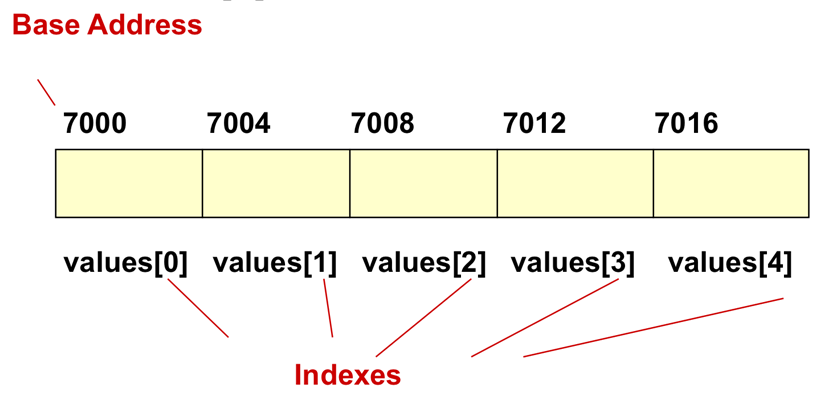
자료구조: 데이터의 집합데이터의 추상화 (Data Abstraction)=> Data EncapsulationApplication의 Data와 Logical 단계에서의 Data를 구분하자풀이하면, 추상 데이터 형식자료구조의 동작 방법을 표현하는 데이터 형식 즉, 자료구
2.[자료구조] Unsorted List & Sorted List

Unsorted List: 특정 순서 없이 데이터가 배치됨, 그저 predecessor / successor 관계만 존재Sorted List: Key를 통해 값이 정렬되어 있음.Key: 리스트의 논리적 순서를 결정하는 데 쓰이는 애트리뷰트Insert1) 넣고자 하는 아
3.[자료구조] Stack and Queue
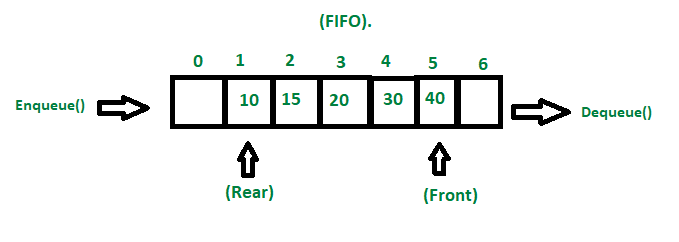
Stack homogeneous items를 보관하며, 한쪽으로만 넣고 뺄 수 있음 LIFO: Last In First Out ADT Operations Push(ItemType newItem) Pop() Top() 대표적으로 쓰이는 건 이 세 개고, 외에도 Mak
4.[C++ / 자료구조] 배열(Array), 리스트(List), 벡터(Vector)의 차이점
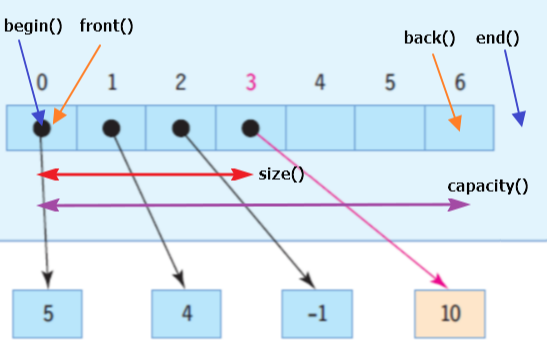
array 기반의 구조지만, 크기가 유동적임장점데이터 추가/삭제가 매우 빠르다. => O(1) 메모리가 연속적이기 때문에 iterator 연산자를 이용한 접근이 가능하다.동적으로 확장/축소가 가능한 동적 배열(dynamic array)로 구현되어 있다.단점컨테이너 중
5.[C++ / 자료구조] Map과 Unordered Map
Balanced tree(균형 트리)로 구현되면, 그중 red-black tree로 구현되어 있다.중복을 허용하지 않고, key를 기준으로 자동으로 오름차순 정렬된다.보통 3번 방식을 많이 쓴다고 한다.또한 2와 3을 쓰려면 iostream을 include해야 한다고
6.[자료구조] 해시 테이블 (Hash Tables)
개발자라면 꼭 알아야 할 Hash Table의 모든 것! (YouTube 노마드 코더)Hash Tables는 Key : Value System을 이용하여 자료를 정리한다. (ex. 사전)배열(array)은 데이터를 찾을 때 Linear Search(선형 검색)을 하기
7.[자료구조] Linked Allocation - Stack
이전 내용에서의 Stack과 Queue는, 배열을 이용하여 구현하였음 => 저장할 수 있는 데이터의 양에 한계 존재 * Push할 때마다 메모리 할당을 받을 순 없을까?* * => Dynamic Array를 이용한 구현* 이런 식으로, 현재의 값과 다음 노드로 향하는
8.[자료구조] Linked Allocation - Queue
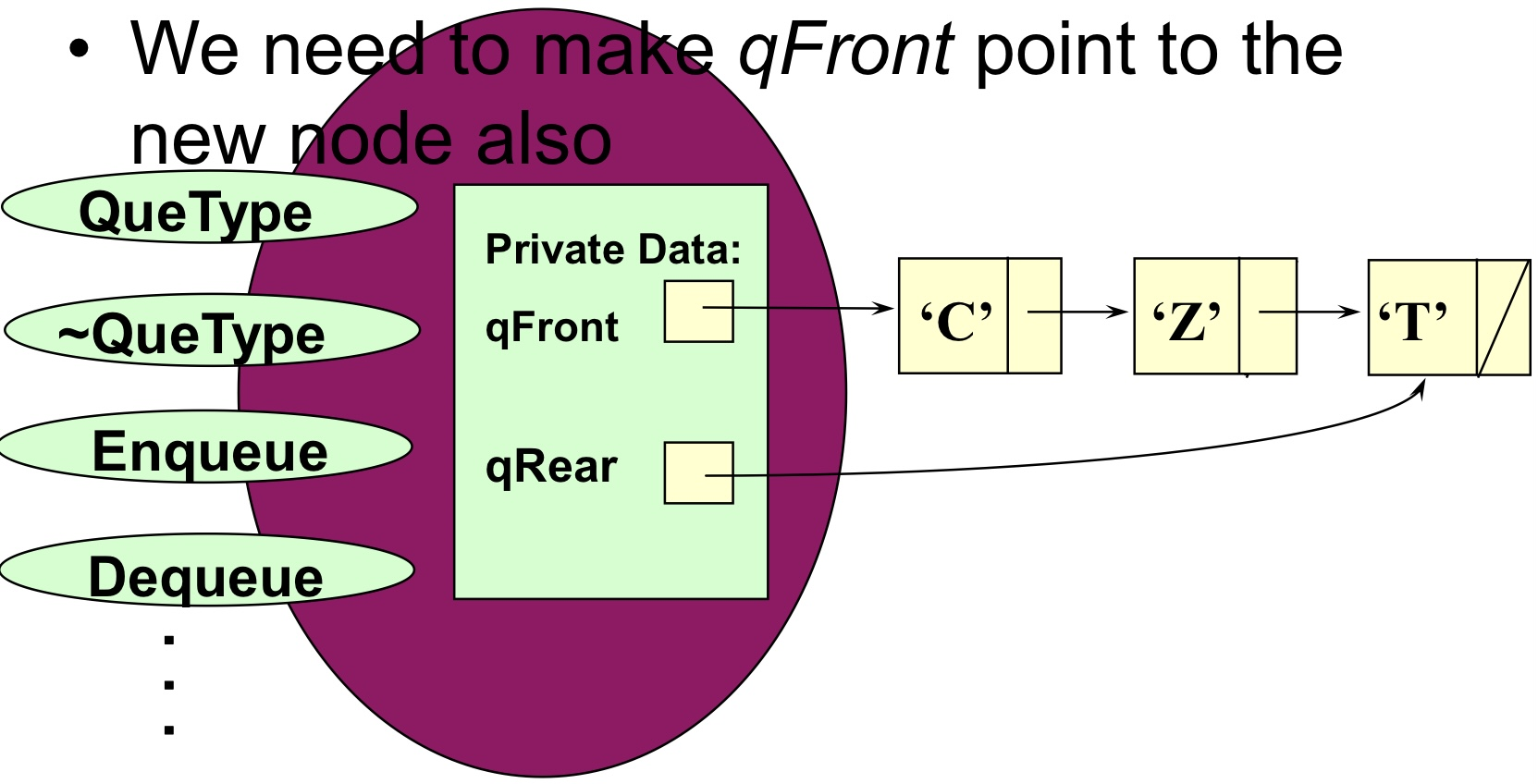
Queue
9.[자료구조] Linked Allocation - Linked List
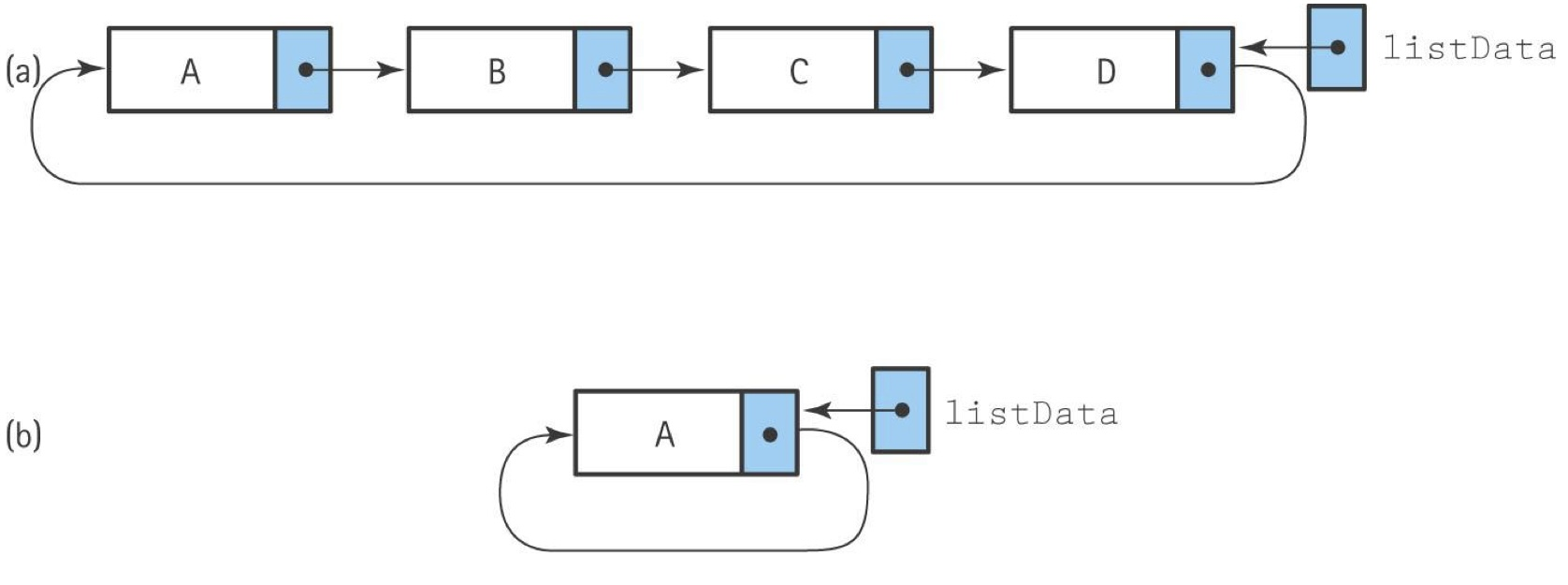
배열(Array)는 생성 시 길이가 고정되어 있다. (정적 메모리 할당)이를 보완하기 위해, 연결 리스트는 아이템을 삽입해야 하는 상황이 오면, 그만큼의 공간을 동적으로 할당받는다.각 노드는 해당 노드의 정보인 info와, 다음 노드를 가리키는 next 변수를 가짐.S
10.[자료구조] Binary Search
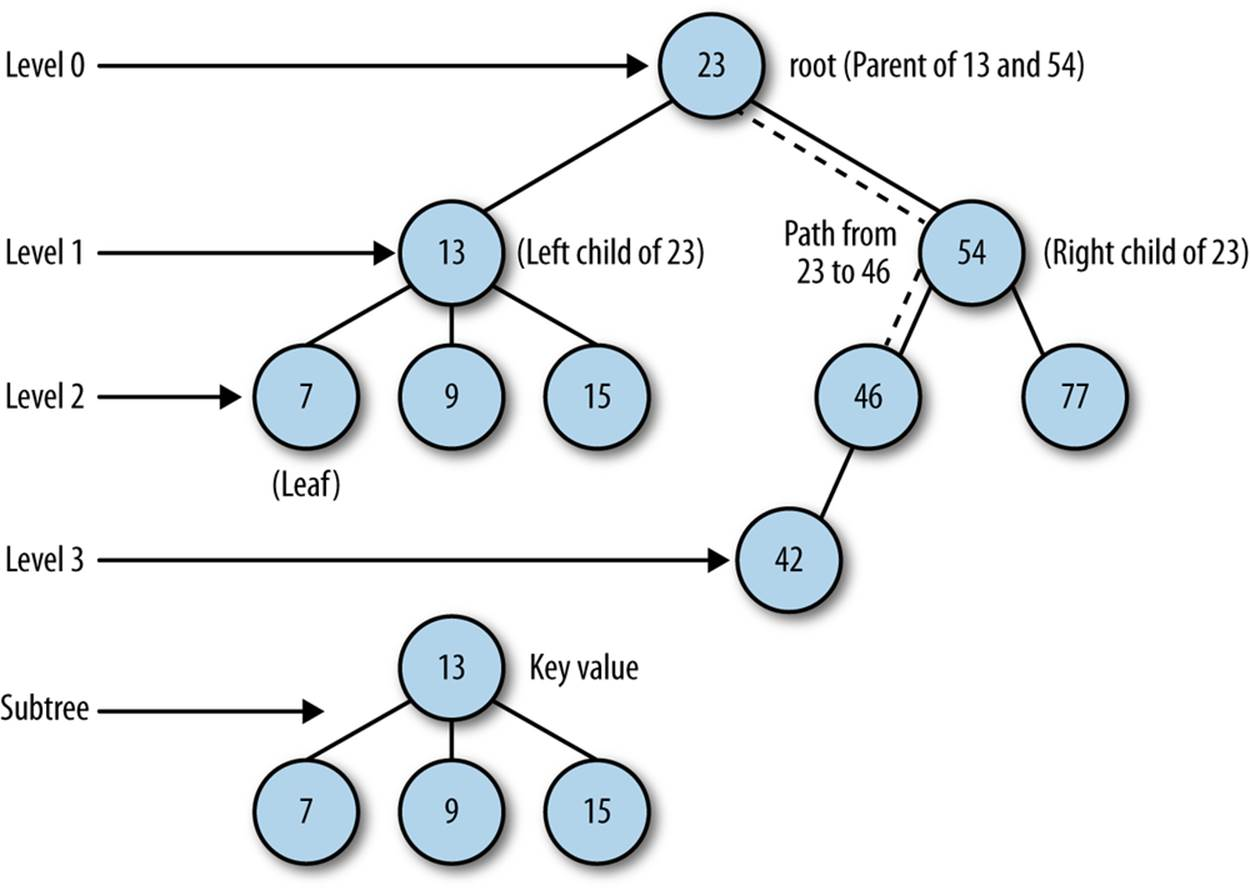
이진 트리(Binary Tree)의 성질각 부모노드는, 최대 두 개까지의 자식 노드를 가짐.Root에서부터 다른 노드로 가는 path는 unique함.높이가 h인 Binary Tree의 최대 레벨은 l=h-1 (높이-1까지의 레벨을 가짐!)또한, 높이가 h인 Binar
11.[자료구조] Heap과 Priority Queue
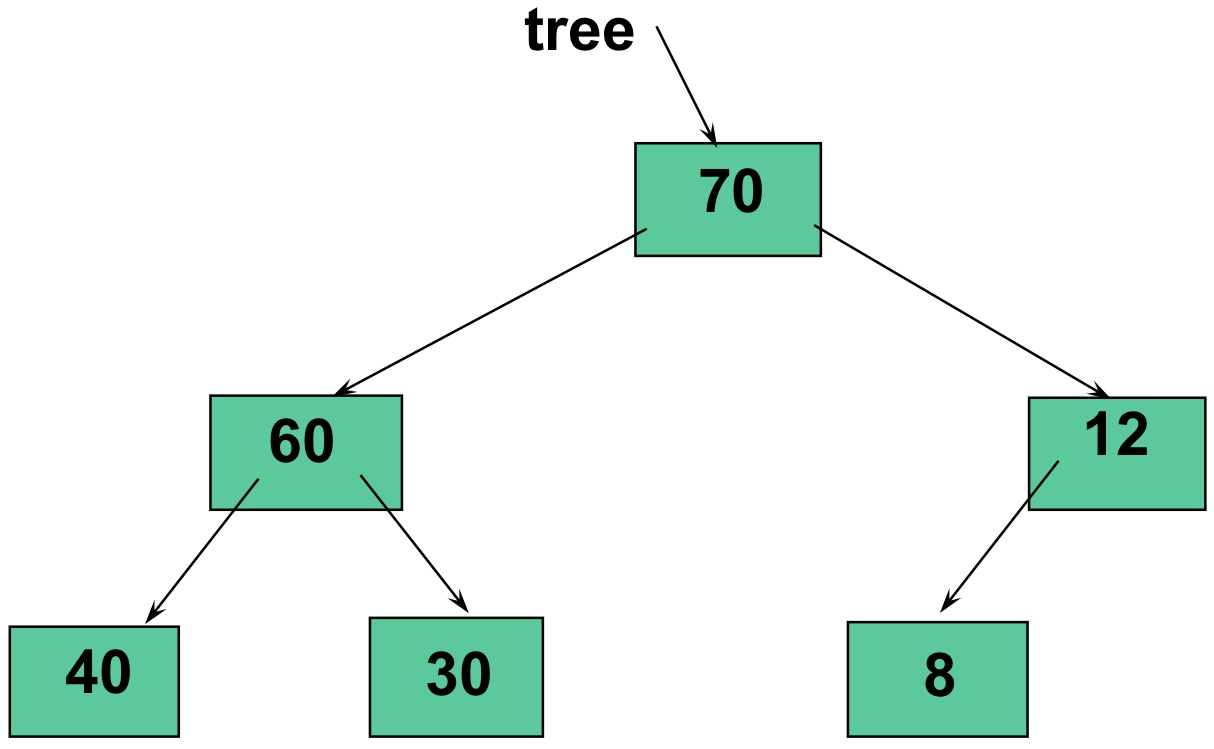
SHAPE과 ORDER의 특성을 모두 만족하는 특별한 이진트리\*\*\\Complete binary tree를 만족하며\*\*\\모든 부모가 자식노드보다 큰(또는 작은) 값을 가짐Binary Tree가 그러하듯, Heap 또한 root -> left subtree ->