MIC 논문 리뷰
본 페이지에서는 MIC: Masked Image Consistency for Context-Enhanced Domain Adaptation 논문에 대해서 말하고자 합니다.
DACS, DAFormer와 직접적인 연관성이 있고 해당 페이지에만 있는 내용도 있으니 아래의 링크를 통해 같이 보시는 걸 추천드립니다.
-
DACS: Domain Adaptation via Cross-domain Mixed Sampling 논문 리뷰
-
HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation 논문 리뷰
1. Intro
기존의 UDA 방법론들은 시각적인 유사성에 기반에 UDA를 진행하였습니다.
즉, 이미지 내의 Context 정보를 완전히 활용하지 않았다는 것입니다.
아래의 사진으로 예를 들어보겠습니다.

Target Image만 보았을 때 실제로 어디가 보도블럭이고 어디가 도로인지 겉으로 보기에는 구분이 잘 안갑니다.
하지만 주변의 건물, 나무 등과 같이 이미지 내의 Context를 보면 보도블럭과 도로를 쉽게 구분할 수 있습니다.
이처럼 외적인 부분에 대해서만 학습한 모델(a)은 보도블럭과 도로를 잘 구분하지 못합니다.
반대로 주변 Context 정보에 대해서 학습한 모델(b)은 둘을 잘 구분하는 모습을 보입니다.
본 논문의 저자들은 Context 정보에 대해서도 학습시키기 위해서 Masked Image Consistency(MIC) 모듈을 소개합니다.
-
Random Masking 방법을 통한 Spatial Context 정보 학습을 더 원활하게 하여 강건한 특징 활용
-
Classification, Semantic Segmentation, Object Detection 등과 같은 여러 Vision Task에서도 쉬운 적용과 성능 향상
2. Term
본 논문을 이해하시기 전에 용어들이 어떤 것을 의미하는지 확인하시면 편하실 겁니다.
-
: Source 데이터들의 개수 입니다.
-
: Target 데이터들의 개수 입니다.
-
: Source 이미지들을 의미하며 는 번째 Source 이미지 입니다.
-
: Source 라벨들을 의미하며 는 번째 Source 라벨 입니다.
-
: Target 이미지들을 의미하며 는 번째 Target 이미지 입니다.
-
: Student Model의 가중치를 의미합니다.
-
: Teacher Model의 가중치를 의미합니다.
-
: Student Model을 의미합니다.
-
: Teacher Model을 의미합니다.
3. Method
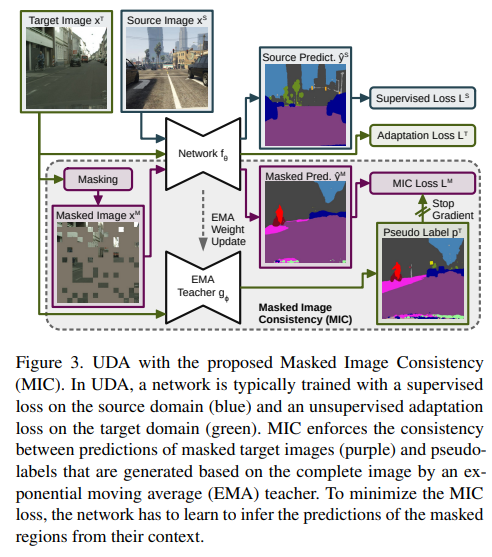
3.1. Unsupervised Domain Adaptation (UDA)
Student Model ()
일반적으로 Classification이나 Segmentation에서 Source Domain에서 를 학습시키기 위해서는 Categorical Cross Entropy를 사용합니다.
그 식은 다음과 같습니다.
이때 Classification는 인 경우입니다.
UDA를 위해서는 를 위한 Loss함수를 사용해야하는데 이를 라고 합니다.
최종적인 Loss함수는 다음과 같습니다.
DACS나 DAFormer의 경우
는 Mix된 이미지에 대한 Loss입니다.
Teacher Model ()
DACS나 DAFormer와 동일하게 Teacher Model()의 가중치 를 지수이동평균(Exponetial Moving Average)을 이용해 업데이트합니다.
그 식은 다음과 같습니다.
시점의 는 다음과 같이 정해집니다.
EMA를 사용함으로써 이전 시점의 Student Model()을 Ensemble하는 것과 같은 효과를 낼 수 있습니다.
이로 인해서 강건함을 증진시키고 Pseudo Label의 Temporal 안정성을 증대시킵니다.
특히 Student Model()을 통해 가중치를 업데이트 하기 때문에 Context 정보에 대한 가중치도 가지고 있게 됩니다.
이러한 특성 때문에 Pseudo Label을 생성할 때 Teacher Model()에 원본 Target 이미지()를 입력으로 넣게 되면 시각적인 요소와 Context 요소를 둘 다 사용하기 때문에 고품질의 Psuedo Label을 생성하게 됩니다.
3.2. Masked Image Consistency (MIC)
Masking된 부분에 대해서 정확한 Segmentation을 하는 것은 사람의 벽뒤에 어떤 것이 있을까를 예측하는 것과 동일합니다.
즉, 주변의 상황에 대한 이해를 통해 안보이는 부분에 대해서 예측하는 것입니다.
Loss를 최소로 하기 위해서 결국에는 시각적인 정보 뿐만이 아닌 Context 정보를 활용하도록 모델에게 학습시키는 것입니다.
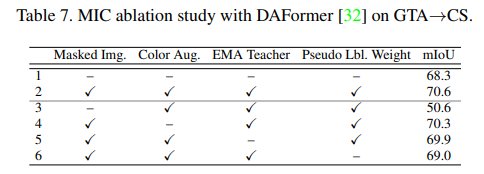
위에 있는 표를 보면 실제로 Masking을 한 것과 하지 않은 것의 차이를 보면 mIoU가 20정도로 큰 차이가 납니다.
이런 MIC의 과정은 Fig 3의 아래 부분과 같습니다.
이 과정을 설명하면 다음과 같습니다.
Masking
-
Masking Map을 만듭니다.
패치들에 대해서 균등 분포를 따르도록 랜덤하게 0~1사이의 수를 입력합니다.
이후에 각 패치의 값이 임계값 을 넘으면 1 아니면 0으로 이진화합니다.
이때 는 패치 크기이며 은 이며 과 은 각각 다음과 같습니다.
-
Target 이미지()와 을 픽셀별로 곱하여 Masking 이미지를 만들어 냅니다.
이 과정을 코드로 보이면 다음과 같습니다.
import torch
import torch.nn.functional as F
def masking(input,mask_ratio = 0.5 , mask_size = 32):
b,c,h,w = input.shape
h_patch = h // mask_size
w_patch = w // mask_size
mask = (torch.rand((b,1,h_patch,w_patch),device=input.device) > mask_ratio).float()
mask = F.interpolate(mask,(h,w),mode='nearest')
output = input.detach().clone() * mask
return outputTraining
-
Masking한 이미지 를 Student Model의 입력으로 넣습니다.
-
Masking 하기 전 이미지 를 Teacher Model의 입력으로 넣어 Pseudo Label($p^T)을 생성합니다.
생성
-
Classification, Segmentation
-
Obeject Detection
임계치 $\delta$와 Non-Maximum Suppression 알고리즘을 통해 출력 결과를 필터링 하여 만들어 줌
-
-
2번과 동일하게 Masking 하기 전 이미지 를 Teacher Model의 입력으로 넣어 Pseudo Label($q^T)을 생성합니다.
생성
-
Classification
-
Segmentation
-
Object Detection
각 Bounding Box에 Classification Brach에 대해서 Classification의 경우와 동일하게 적용
-
-
Masking에 대한 Loss 계산합니다.
최종적으로 MIC의 Loss는 다음과 같이 구성됩니다.
4. Performance
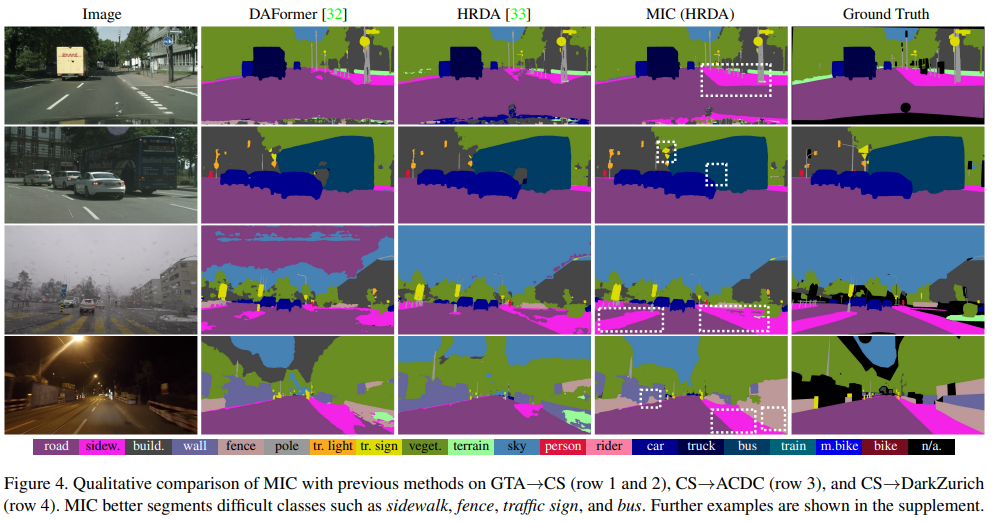
기존의 SOTA와 비교해 추론 이미지를 보면 다음과 같습니다.

실제로 MIC가 다른 방법론에 비해 도로와 보도블럭을 잘 구분하는 모습을 보여줍니다.
※ 하이퍼 파라미터에 대한 자세한 내용은 논문에 나오므로 해당 부분은 논문에서 확인해주시면 됩니다.
4.1 Context Aware
그렇다면 정말로 Context를 이해하는 것인가?
위 질문에 대한 답은 아래의 사진을 보면 됩니다.
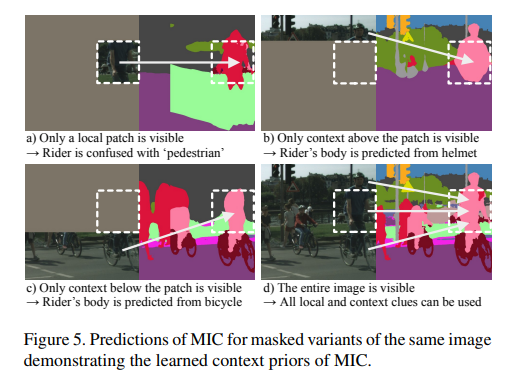
모델에게 대부분을 Masking 한 후 일부분만 보여주며 모델에 입력으로 사용한 결과는 진짜 그럴 듯 하게 분할한 결과를 내놓는다는 것입니다.
4.2 Why Only Target
Source에도 Masking을 하면 성능이 더 좋지 않을까?
논문을 보면서 이렇게 생각을 했는데 저자들이 실제로 실험을 해주었습니다.
데이터셋에 따라서 Source와 Target 둘다 Masking을 하는 것이 좋을 때도 있고 안좋을 때도 있습니다.
이를 보면 모델 구조가 복잡해지지 않게 Target에만 하는 것이 더 편할 거 같습니다.
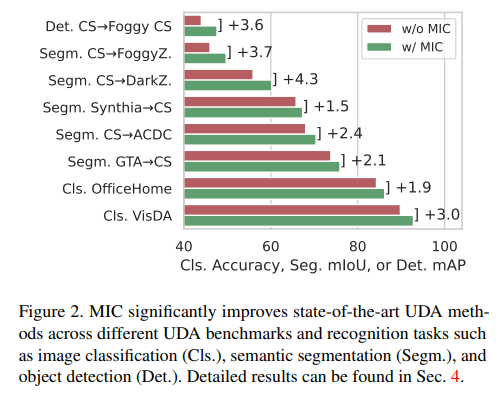
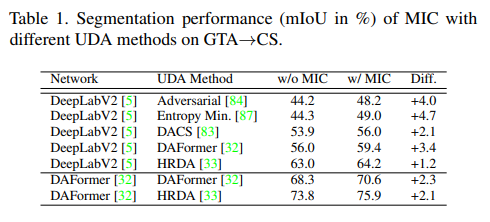
4.3 Performance Increase Ratio
모델과 UDA 방법에 따른 성능 향상 차이를 보면 위의 표와 같습니다.
실제로 모든 패치들과의 유사도를 계산하는 Transformer에서 오히려 성능 개선이 훨씬 더 좋을 줄 알았는데 성능 향상에는 둘 다 큰 차이가 없습니다.
5. 마무리
간단한 Masking 방법을 통해 모델에게 Context 정보를 이해시킨다는 점이 인상 깊었던 거 같습니다.
새로운 도메인에 대해서 알지 못하는 인공지능 모델에게 Masking 부분을 예측하도록 해서 학습을 한다는 점은 오히려 성능이 안좋을 거 같다고 생각했습니다.
그러나 오히려 기존 UDA 방법론에 간단한 MIC 모듈을 추가함으로써 전체적으로 성능이 향상되는 것을 보면 Masking 방법의 힘을 알 수 있는 거 같습니다.
특히 기존의 UDA 방법론들과는 달리 Classification, Detection에서도 사용가능하다는 점이 큰 메리트라고 생각되며 이를 잘 활용하면 KeyPoint Detection에서도 활용이 가능할 거 같습니다.
