본 페이지에서는 DACS: Domain Adaptation via Cross-domain Mixed Sampling 논문에 대해서 말하고자 합니다.
1. Intro
본 논문은 Semantic Segmentation 분야의 Unsupervised Domain Adaptation 방법론 논문입니다.
기존 Segmentation 모델들은 학습 데이터와 비슷한 상황에서는 매우 잘 작동합니다. (분포가 비슷한 경우를 말함)
그러나 학습 데이터와 다른 분포를 가진 데이터를 사용하게 되면 성능이 급격히 감소하게 됩니다.
가장 좋은 예시는 다음과 같습니다.

첫 사진은 GTA5 데이터셋이며 두번째 사진은 CityScape 데이터셋입니다.
사람이 보기에는 두 데이터셋의 차이가 그렇게 없지만 둘 중 하나의 데이터셋으로 학습한 모델은 다른 데이터셋에서는 성능이 급감하는 모습을 보입니다.
그 이유는 두 데이터의 분포 차이 때문입니다.
Domain Adaptation은 이런 도메인 사이의 차이를 줄이고자 하는 방법론입니다.
목표로 하는 도메인(Target Domain)의 라벨이 항상 존재하면 좋지만 실제로는 그렇지 않습니다.
특히 Segmentation 분야의 경우 새로운 라벨을 만드는데 시간과 비용이 크게 발생하기 때문에 더더욱 라벨이 존재하기 어렵습니다.
이러한 문제를 해결하기 위해서 Unsupervised Domain Adaptation(UDA)이 등장하게 되었습니다.
본 논문은 UDA를 조금 더 효율적으로 수행하도록 새로운 Mixing 기법을 소개합니다.
2. Unsupervised Domain Adaptation(UDA)
UDA는 Source Domain의 Label은 존재하지만 Target Domain에는 Label이 존재하지 않은 경우에 Domain Adaptation을 진행하는 것입니다.
UDA 기법은 주로 Pseudo Label을 사용하는 Semi-Supervised Learning 혹은 Self-Training 기법을 통해 진행됩니다.
본 논문 또한 Pseudo Label을 통해 UDA를 진행합니다.
2.1 Pseudo Label
Pseudo Label은 잘 학습된 모델의 출력을 라벨로 사용하는 것입니다.
기존의 사람이 라벨링하는 과정은 다음과 같습니다.
사람이 해당 이미지를 보고 손수 튤립이라고 판단하여 튤립에 대한 클래스의 정보를 저장합니다.
Pseudo Label은 다음과 같습니다.
※ Segmentation은 픽셀단위 Classification이기 때문에 참고만 하시면 됩니다.
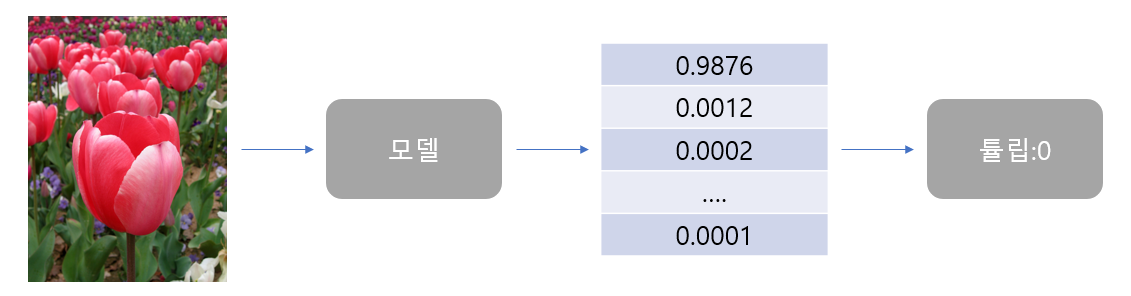
Pseudo Label은 모델이 예측한 클래스 확률과 그 확률에 Argmax를 적용한 클래스 정보를 말합니다.
이를 식으로 표현하면 다음과 같습니다.
본 논문에서는 이 Cls를 사용하여 Loss를 구하고 Confidence를 활용하여 Loss의 크기를 조절하여 학습합니다.
2.2 Semi-Supervised Learnging(SSL)
본 논문에서는 SSL을 기반으로 UDA를 진행하게 됩니다.
Pseudo Label을 만드는 과정에서 생긴 클래스 벡터(확률 벡터) 와 최종 클래스 를 사용합니다.
Pseudo Label에 대한 Loss 함수를 다음과 같이 정의합니다.
※는 Student Model이 예측한 결과 입니다. Student Model은 이후에 설명하겠습니다.
이때 는 전체 이미지 중 Threshold를 넘는 픽셀의 수이며 다음과 같이 정의 됩니다.
하나의 배치에 대해서 Loss를 계산하는 경우에는 다음과 같이 계산해야 합니다.
위의 Loss를 통해 SSL의 성능이 크게 향상된 것은 맞으나 아직 문제점이 존재합니다.
-
Loss의 특성상 예측하기 쉬운 이미지에 대해 편향되기 쉬움
Confidence가 일정 수준 이상인 이미지에 대해서만 Loss가 전파되기 때문에 일부 이미지에 편향될 가능성이 높습니다.
-
일부 이미지에 대해서만 학습을 하게될 수 있음
1번과 비슷한 이유로 만약 편향되어 학습을 하게 되는 경우 일부 이미지에 과적합이 발생하고 이로 인해 다른 이미지에서 임계값을 넘은 픽셀이 없을 수 있어 Loss가 0이 될 가능성이 높아 오히려 성능이 감소될 수 있습니다.
이를 더 잘 해결하기 위해서 본 논문에서는 Domain Adaptation via Cross domain mixed Sampling(DACS) 기법을 제안합니다.
3 Method
DACS 기법은 간단하게 Source Image와 Target Image를 섞고 Source Label과 Pseudo Label을 섞는 방식을 사용하여 성능이 향상됨을 보여줍니다.
3.1 Naive Mixing
기존의 Mixing 기법은 Target Domain 에서 뽑힌 두 이미지에 대해서 Mix를 하였었습니다.
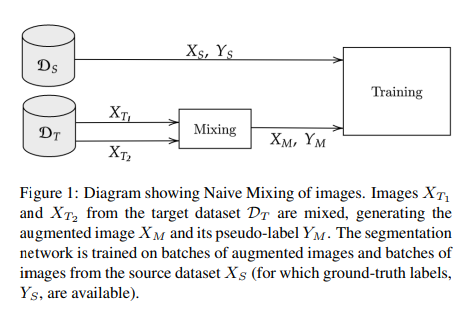
성능은 향상되긴 하였지만 근본적으로 2절에서 말한 문제점은 해결하지 못합니다.
특히 두 이미지에 대해서 섞어서 만나게 되는 경계면이 크게 애매해지게 되어 자주 안나오는 SideWalk 클래스를 비슷한 Road로 예측하는 문제점도 발생하게 됩니다.
이를 Class Conflaction 이라고 합니다.
이런 점은 DACS 기법을 통해 해결이 가능하게 되었습니다.
3.2 DACS
DACS 는 기존의 Naive Mixing 방법과는 다르게 Source Domain과 Target Domain을 섞는 방식입니다.
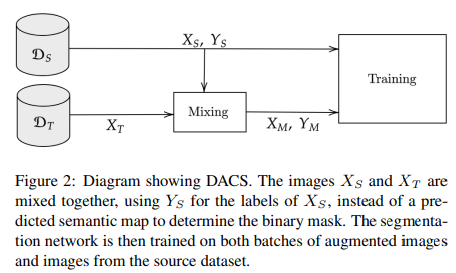
DACS는 ClassMix 방식을 기반으로 하며 과정은 다음과 같습니다.
-
Source Image에 존재하는 모든 클래스 중 절반의 클래스를 선택한다.
-
해당 클래스가 존재하는 위치의 픽셀들을 잘라내어 Target Image에 대응되는 픽셀에 붙여넣는다.
-
Psuedo Label에 동일하게 Source Label을 붙여넣는다.
이 예시는 다음과 같습니다.

이 방법을 통해 성능이 크게 향상 됐다고 합니다.
이때 Pseudo Label에서 ClassMix를 적용한 부분은 Source Label에서 가져온 Label이므로 Confidence는 항상 1이 되어 Threshold를 넘게 됩니다.
이 때문에 예측하기 어려운 Target Image에 대해서도 가 0인 경우가 없으므로 적어도 조금씩은 학습에 반영되기 때문에 기존보다 편향될 확률이 적어지게 됩니다.
Result(Naive, DACS)

Naive 방법에 비해 DACS 기법은 확실히 도로와 보도블럭을 잘 구분하는 모습을 보여줍니다.
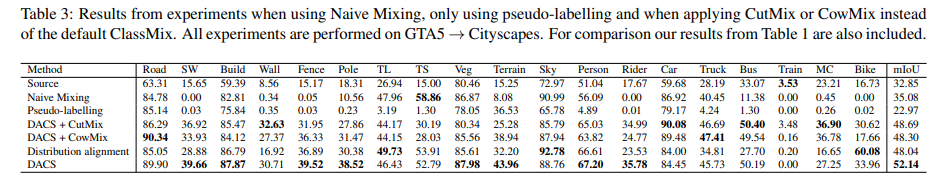
수치적으로도 DACS 기법을 사용함으로써 성능이 크게 향상됨을 확인할 수 있습니다.
3.3 Loss
최소화해야할 Loss는 다음과 같습니다.
는 Source Image Source Label Mixed Image Mixed Label 입니다.
본 논문에서는 이미지들이 모두 모델 에 입력으로 들어가지만 공식 코드에서 Target Image는 Teacher Model 에 들어가게 됩니다.
자세한 구조는 4절에서 다루겠습니다.
4. Overall Algorithm
우선 알고리즘을 설명하기 전 Teacher Model과 Student Model에 대해서 설명하고 가겠습니다.
-
Teacher Model : UDA에서 Pseudo Label을 생성하는 Model로 이 모델의 가중치는 지수 이동 평균과 같은 알고리즘으로 Student Model을 기반으로 업데이트 됩니다.
-
Student Model : UDA에서 학습을 하는 모델로 Source 이미지와 Label과 Target 이미지와 Pseudo Label을 통해 학습을 진행합니다.
간단하게 말해서 Teacher Model은 Target 이미지에 대한 라벨을 생성해서 Student Model 에게 Target 이미지에 대한 정보를 알려주는 것이기 때문에 Teacher Model이라고 하는 것입니다.
4.1 DACS
DACS의 전반적인 알고리즘은 다음과 같습니다.

※ 실제 코드와 조금 다른 점이 있어 코드 기반으로 설명하겠습니다.
-
모델 초기화
-
학습 에폭 수
-
Source Data로부터 이미지와 라벨을 추출
-
Target Data로부터 이미지를 추출
-
Target 이미지를 Teacher Model에 입력으로 넣어 Pseudo Label을 생성
-
Class Mix를 적용하여 Mixed 이미지와 라벨을 생성
-
Source 이미지와 Mixed 이미지를 Student Model에 입력으로 하여 예측값을 생성
-
예측값과 라벨을 통해 Loss를 계산
-
BackPropagation 진행
-
SGD를 기반으로 Student Model 가중치 Update 후 Teacher Model의 가중치는 Student Model의 가중치를 기반으로 EMA를 통해 Update 진행
4.2 Architecture Flow
이를 간단히 흐름도를 통해 보이면 다음과 같습니다.
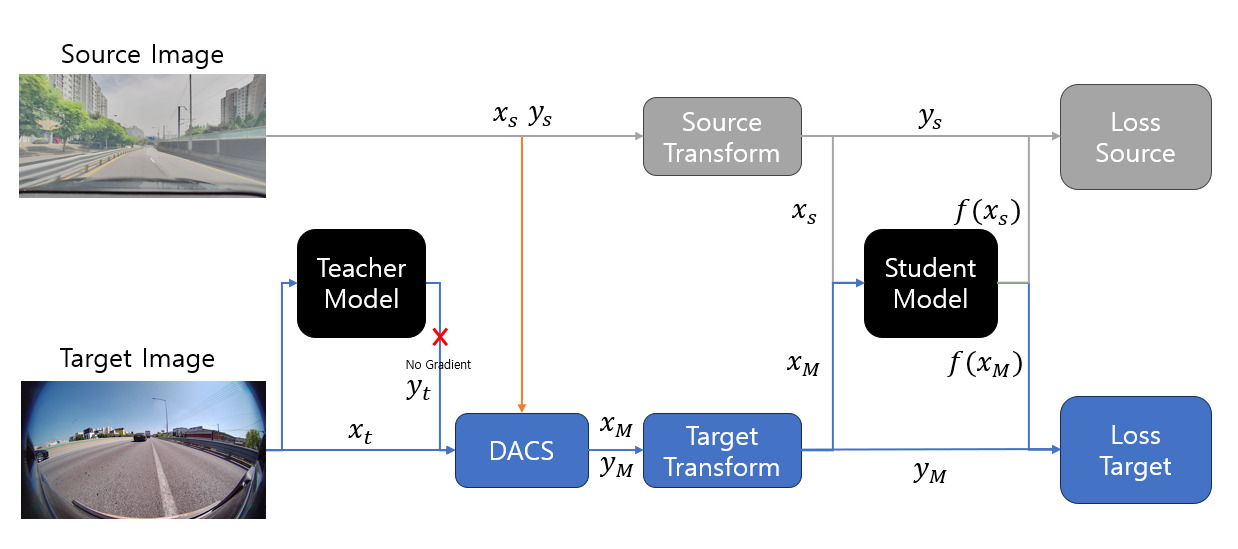
여기서 Teacher Model은 Student Model과 동일한 모델이지만 파라미터(가중치)를 지수이동평균(EMA)을 통해 업데이트합니다.
Student Model의 학습될 파라미터들을 Teacher Model의 파라미터들을 라고 한다면 각 에폭당 Teacher Model의 파라미터는 다음과 같습니다.
이렇게 학습을 진행하며 일관적으로 학습을 하게 된다고 합니다.
여기서 중요한 점은 Teacher Model은 Pseudo Label을 생성하기 위한 용도이므로 Dropout 등을 사용하지 않는 Eval 모드(Pytorch에서)로 진입해두어야 합니다.
4.3 Similarity Between Source and Target
본 논문의 저자들은 GTA 5 -> CityScapes 로의 UDA 성능이 SYNTHIA -> CityScapes로의 UDA 성능보다 좋다는 것을 보여줍니다.
이를 설명하기 위해 저자들은 Source와 Target에서의 Cityscapes와 GTA5의 유사도가 SYNTHIA와의 유사도보다 높았기에라고 설명합니다.
즉, DACS 기법의 특성상 적절한 위치에 있는 Class가 섞이는 경우에 더 합리적이기 때문이라고 합니다.
5. 마무리
본 논문에서 사용한 방법론은 이후에 다룰 UDA 관련 논문인 DAFormer, MIC에서도 사용되기 때문에 알고가면 좋습니다.
