본 페이지에서는 BlazePose: On-device Real-time Body Pose tracking논문에 대해서 말하고자 합니다.
1. Intro
BlazePose는 Mobile Device에서 실시간 추론이 가능하도록 하기 위해서 경량화된 Covolution Neural Network이다.
-
BlazePose는 두가지 방식을 계층적으로 사용한다.
-
Heatmap-Based 방식 : 최소한의 오버헤드로 여러 사람에게 적용이 가능하지만 모델의 크기가 커진다.( 이 부분은 Mobile Device에서 사용이 가능하도록 경량화 하기 위해 뺄 수 있다.)
-
Regression-Based 방식 : Computational Cost가 상대적으로 적지만 좌표를 얻어내는데 실패한다.
-
2. 모델 구조와 파이프라인 디자인
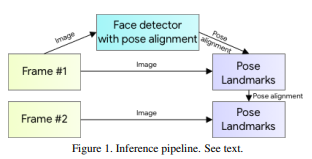
2.1 추론 파이프라인

위 구조의 파이프라인을 사용하는데 다음 두 계층적 구조로 이루어진다.
-
Body Pose Detector
-
Pose Tracker Network
Tracker는 현재 프레임에 있는 사람의 키포인트의 좌표를 예측하고 현재 프레임에 대해 Region of Interest를 Refine한다.
만약 Tracker에서 사람이 없다고 하면 다음 프레임에 대해 진행한다.
2.2 Person Detection
최근 Object Detection(객체 탐지) 분야에서의 후처리 과정은 Non Maximal Suppresion(NMS) 알고리즘에 의존한다.
이 알고리즘은 일부 상황(포옹하는 것과 같은 두 사람이 겹치는 상황)에서는 두 Bounding Box를 하나의 Box로 묶어버리는 경우가 발생한다.
이를 해결하기 위해 본 논문은 다음의 근거로 얼굴을 탐지하는 것을 목표로 합니다.
-
모델의 예측 결과가 얼굴에서 가장 좋은 성능을 보이는 것을 확인했다
-
얼굴은 변형이 적고, 다른 것과 크게 대비된다.
그래서 다음과 같은 가정을 사용합니다.
한사람의 이미지 내에서는 얼굴이 항상 보일 것이다.
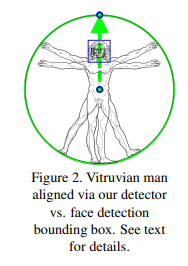
또한 Face Detector가 얼굴만을 찾아내는 것이 다음을 추가적으로 찾아냅니다.(아래의 사진과 함께 보시면 이해가 쉬울 겁니다.)
이때 얼굴을 탐지하기 위해 BlazeFace를 사용한다고 합니다.
-
엉덩이의 중간점
-
사람에 대한 경계 라인
-
각도(엉덩이의 중간 점과 어깨 중간점을 잇는 직선을 통해 구함)
2.3 관절 정보
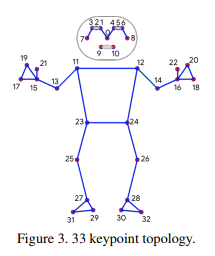
관절 정보는 위와 같이 사용했다
2.4 모델 구조
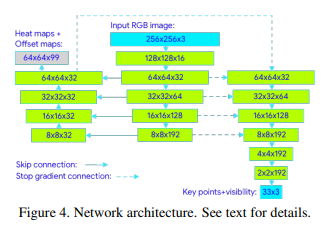
본 구조는 Heatmap과 Offset을 모두 만들어내는 구조이다.
-
왼쪽 : Heatmap Decoder
-
중간 : Main Encoder
-
오른쪽 : Regression Encoder, Decoder
Skip Connection 구조는 Stacked Hourglass Networks for Human Pose Estimation 라는 논문에서 나온 기법을 활용한 것이다.
Stop Gradient
Regression Encoder에 들어오는 모든 피쳐들은 Gradient 흐름이 끊긴다.
즉, Regression Encoder,Deocoder와 Main Encoder, Heatmap Decoder는 서로 독립적으로 학습한다는 얘기다.
이에 대한 얘기는 PyTorch 독립 레이어 만들기를 보면 된다.
이러한 구조를 사용해서 Heatmap 예측 성능 뿐 아니라 좌표 예측 성능 또한 향상시켰다.
2.5 데이터 증강
고의적으로 Angle,Scale,Translation에 대한 데이터 증강의 변화량을 제한했다.
이로 인한 장점은 다음과 같다.
-
모델의 크기를 감소시키면서 빠르고 더 적은 Computational Cost를 소비하게 하였다.(증강과 모델의 크기의 상관관계는 없는 걸로 아는데 이유는 모르겠다.)
-
작은 Device에서도 사용이 가능하게 되었다.
Scale, Shift, Translation, Rotate
-
Detection Stage와 이전 프레임의 Key Point들에 기반해서 엉덩이의 중앙이 이미지의 정 중앙에 오도록 함
-
엉덩이의 중앙과 어깨의 중앙을 잇는 선 을 구하고 이 을 y축과 평행하도록 함
-
Scale : 모든 Body Point들이 BBox 안에 들어올 수 있도록 함
이 과정의 결과는 Fig2와 비슷하다고 보면 됩니다.
프레임 사이의 움직임으로 인한 변형을 다루기 위해서 오직 10%의 Scale과 Shift 증강을 사용하였다.
Invisible Point Predict
또한 안보이는 포인트를 잘 예측하기 위해서 학습 과정에서 다음과 같은 이미지 증강을 처리 했다.
-
이미지 내에 무작위의 사각형을 관절 포인트를 포함하도록 하여 그렸다.
-
해당 관절 포인트가 보이는지에 대한 정보도 제공하였다.
이러한 증강을 통해 아래와 같이 상체만 보이는 경우에도 관절에 대해 잘 예측이 가능하도록 하였다.

