본 페이지에서는 MobileNet V2의 등장배경과 특징에 대해서 말하고자 합니다.
1. MobileNet V2
기존에 있던 CNN들은 이미 인간을 넘어설만큼의 성능을 가진 모델들이 많이 있다.
이런 모델들의 성능은 주로 computational cost로부터 오는데 이러한 모델들은 mobile 장치와 같이 성능이 낮고 저장공간이 적은 상황에서 쓰기에 적절하지 않다.
따라서 본 논문은 MobileNet V1과 비슷하게 연산의 수를 줄이면서 메모리 사용량을 줄이는 방법을 목적으로 한다.
MobileNet V2의 특징은 간단하게 다음과 같다.
-
MobileNet V1과 동일하게 Depthwise separable convolution을 사용하였다.
-
특히 ReLU함수와 같은 비선형변환 함수를 사용함에 따라 정보의 손실이 발생하는 경우가 있는데 이 점을 활용해 일부분에 비선형 변환을 적용하지 않으며 성능을 향상 시켰다.
-
위의 특징들을 활용해 기존의 Residual structure와는 다른 Inverted Residual structure를 제안하였다.
2. Detail of MobileNet V2
이 부분은 MobileNet V2의 주요 특징에 대해서 자세히 다루려고 합니다.
2.1 Depthwise Separable Convolution
Depthwise Separable Convolution에 대한 내용은 이전에 MobileNet V1에 대한 내용에 있습니다.
2.2 Linear Bottleneck
2.2.1 Dimensional Space
우선 본 논문의 Linear Bottleneck 부분에 대해서 이해하기 위해서는 고차원의 정보와 저차원의 정보에 대해서 이해를 해야한다.(low-dimensional space,high-dimensional space)
고차원의 정보라고 하면 우리가 어떤 고양이 사진을 보면 사진에 있는 고양이 자체는 고차원의 정보이고 고양이의 어떤 특정 정보들을 저차원의 특징이라고 한다.
즉, CNN에서 고차원의 정보라고하면 input feature 라고 하고 이러한 feature에서 추출한 정보를 저차원의 정보라고 한다.
CNN에서 Conv 연산을 통해 채널의 수를 늘리는 과정은 기존에 얻어낸 특징들로부터 더 많은 특징들을 추출하는 과정(low dimension subspace로 embedding 하는 것)이고
반대로 채널의 수를 줄이는 과정은 기존에 얻어낸 특징들을 활용해 특정 정보를 합성하는 과정(high dimension space로 embedding 하는 것)이다.
실제로는 더 복잡하게 작동하지만 간단하게 육각형을 추출하는 과정을 예로 들면 아래의 사진을 보면 알 수 있다.
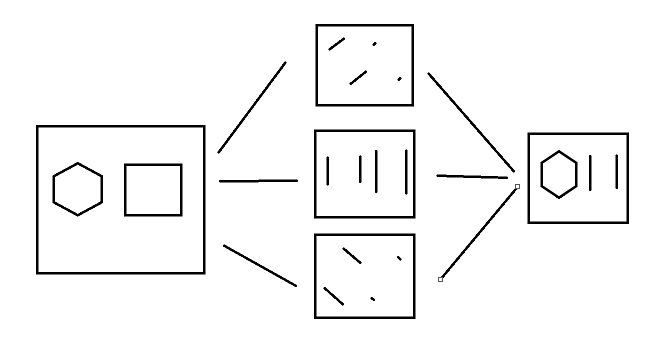
2.2.2 DNN
DNN이 n개의 레이어 Li로 구성되어져 있고 각각의 레이어는 (hi x wi x di)의 차원을 가지고 있는 activation tensor(feature map의 개념이라고 이해했다.)로 이루어져 있다고 하면
이러한 레이어 activation의 집합(즉, 레이어들을 지나온 feature map)은 "manifold of interest"를 형성한다고 한다.
즉 모든 레이어들을 지난 결과라고 보면 된다.
우리가 한 레이어 내의 하나의 채널의 픽셀들을 통해 얻어진 정보들은 또 다른 manifold에 놓이게 되고 이는 또 활용되어 새로운 low dimensional subspace에 embedding 될 수 있다.(manifold 자체는 하나의 레이어에서의 결과라고 볼 수 있다.) 즉 하나의 레이어를 지날 때마다 dimensionality를 줄여가며 필요한 특징을 추출해 나아간다.
MobileNetV1는 효율적으로 computation과 정확도에서 trade off를 width multiplier 파라미터를 통해 해왔었다. 특히 이런 width muliplier는 dimentionality를 줄이기 때문에 효과가 있었다.
하지만 이런 생각은 비선형 변환이 있을 때는 조금 다르게 작용하는 경우가 있다.(안좋은 쪽으로 작동함)
2.2.3 Non Linear Transform(ReLU)
여러가지 비선형 변환이 있는데 ReLU함수를 예를 들면 다음과 같다.
ReLU 함수의 식은 다음과 같다.
ReLU함수는 두가지 문제점이 있는데 하나는 다음과 같다.
Linear Transform
이때 x가 0보다 큰 경우에는 x를 그대로 출력하게 되어 선형 변환이라고 할 수 있다.
만약 하나의 레이어에서의 결과에 ReLU함수를 적용한 결과인 volume S에 대해서 0값이 없는 경우에는 입력에 대해서 선형 변환을 했다고 볼 수 있다.
이러한 이유로 출력의 모든 dimension에 대응하는 입력 space는 선형변환으로 제한된다.
(여기서 입력 space라 함은 입력 레이어의 모든 부분을 의미하는 듯 하고 출력의 모든 dimension이라 함은 입력 space들을 통해 얻어낸 출력들을 말하는 것 같다.)
즉 출력들이 선형 변환이 될 수 있다는 것을 말한다.
Information Loss
만약 ReLU함수가 채널을 붕괴시키면 이는 필연적으로 해당 채널에 있는 정보의 손실을 발생시킨다.
그러나 많은 채널을 가지고 있고 activation manifold에 structure가 있다면 정보가 다른 채널에서 보존될수 있다.
이는 다음 Fig1을 통해 설명 하면 다음과 같다.

Fig1은 ReLU함수를 통해 dimensional 을 전환하는 모습을 보여준다.
각 그림에 대해서 Input에 대해서 n차원으로 embedding 하고 ReLU함수를 적용한 뒤 이를 2D 공간에 project 시킨 모습이다.
Input을 비교적 작은 차원(n=2 ,3)으로 전환 하고 ReLU를 적용한 후 2D공간에 Project 시킨 모습을 보면 나선 모양에 대한 정보가 많이 사라지고 차원이 클 수록 정보의 손실이 적어짐을 확인 할 수 있다.
즉 기존 차원보다 낮은 차원으로 변환 후 ReLU를 적용시키는 경우에 정보의 손실이 발생하는 것을 알 수 있다.
이러한 특징들은 Inverted Residual block을 구현할 때 비선형 변환을 사용 여부에 영향을 주었다.
2.3 Inverted residual block
Bottleneck block이 기존의 residual block과 비슷하다.
기존의 residual block은 입력의 shortcut이 expansion 레이어의 결과와 연결 된다.
본 논문에서 제안한 Bottleneck block은 shortcut이 expansion 레이어의 결과가 아닌 bottleneck 레이어의 결과와 연결된다.
이러한 생각은 residual block에서 bottleneck 레이어가 중요한 정보를 가지고 있다고 생각하고 expansion 레이어는 비선형 변환과 함께 구현에 필요한 연산을 하는 것이라는 생각을 기반으로 Inverted residual block을 구현하였다.
2.3.1 Residual block vs Inverted Residual block
아래의 그림은 두 구조의 다른 점을 보여준다.
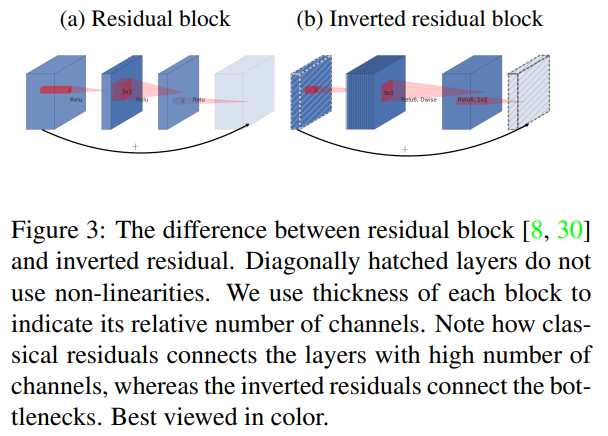
기존의 Residual Block의 특징은 다음과 같다.
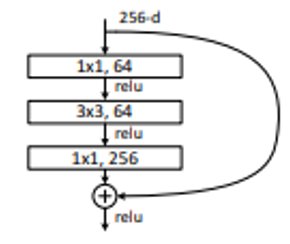
기존의 큰 채널에서 채널을 좁히는 bottleneck 레이어 이후에 추가적인 연산을 하고 다시 expansion 레이어를 통해 채널을 늘린다. 이후 expansion 레이어의 결과에 입력을 연결하여 shortcut을 구현한다.
즉, 좁힘->연산->늘림 방식의 연산이다.
반면에 Inverted residual block의 특징은 다음과 같다.

기존의 작은 채널에서 채널을 늘리는 expansion 레이어 이후에 Depthwies conv 이후 Pointwise conv 연산을 진행한 후 bottleneck 레이어를 통해 채널을 줄인다 이후 bottleneck 레이어의 결과에 입력을 연결하여 shortcut을 구현한다.
즉, 늘림->연산->좁힘 방식의 연산이고 기존의 Residual block과는 반대되는 특징을 가져 Inverted residual block이라 하는 것이다.
2.3.2 Linear bottleneck
Residual block과 Inverted Residual block의 또 다른 차이점은 비선형 변환을 사용하는 레이어도 있고 사용하지 않는 레이어도 있다는 것이다.
Information Loss 에서 보면 비교적 작은 차원으로 전환한 후에 ReLU함수를 적용하는 경우에 정보의 손실이 발생한다고 하였다.
이는 Inverted Residual block에서 발생할 수 있는데 Bottleneck 레이어의 경우 원래의 채널보다 적은 수의 채널로 전환을 하기 때문에 여기에 비선형 변환을 적용하게 될 경우 정보의 손실이 발생할 수 있다는 것이다.
즉, 이러한 문제를 해결하기 위해서 Bottleneck 레이어의 결과에 비선형 변환을 하지 않았고 이를 Linear Bottleneck이라고 한다.
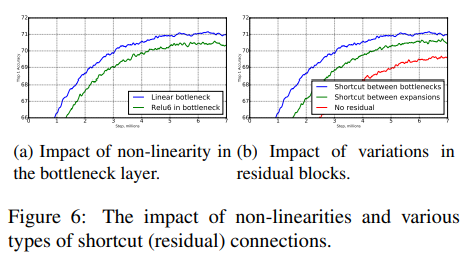
Linear Bottleneck을 사용 여부에 따라 성능 비교는 아래와 같다.
2.3.3 Computational Cost
기존의 Depthwise Separable Conv 연산의 computational cost는 아래와 같다.
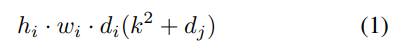
이때 hi wi di 는 Li의 높이 너비 차원이고 k는 kernel size를 의미한다.
Inverted Residual block 전체의 computational cost는 아래와 같다.
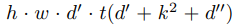
이때 t는 expansion factor이고 d'은 입력 채널 d''은 출력 채널 h,w는 입력의 높이와 너비이다.
이때 식 1과 비교했을 때 computational cost는 추가적인 1x1 conv 연산 때문에 더 많지만 MobileNet V2 모델의 특직때문에 더 작은 input output channel 때문에 모델의 전체적인 연산에 대한 computational cost는 낮다.
이는 아래의 Table 3을 보면 알 수 있다.
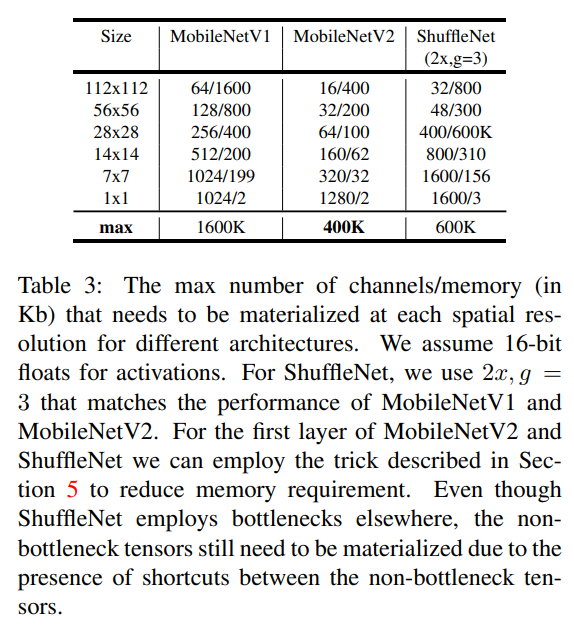
2.4 Information flow interpretation
위 에서 말한 구조적 특성때문에 자연스럽게 Bottleneck 레이어들의 입출력 domain과 레이어 변환(Non-linear function)을 분리 할 수 있게 되었다.
전자는 각각의 레이어에서의 네트워크 성능이라고 볼 수 있고 반면에 후자는 표현력이라고 볼 수 있다.
표현력과 성능이 분리할 수 없는 것과 function of the output layer depth(?)라는 것에서 기존의 conv block과의 차이점이다.
특히 Inner 레이어 깊이가 0이 된다면 기존의 연산은 shortcut connection 덕분에 항등 함수가 된다.
이 얘기는 기존에 식이 F(x)=ReLU(f(x)+x)라고 했다면 본 논문은 G(x)= g(x)+x이므로 (g(x)내에만 relu함수가 있기 때문에 만약 g(x)의 깊이가 0(아무 함수도 없다면) G(x)=x가 된다라고 이해 했다.
이러한 분리에 대한 이해는 네트워크의 특성을 더 쉽게 이해할 수 있게 해준다.
3. Model Architecture
MobileNet 구조적 detail은 다음과 같다.
-
초기의 Fully Convolution layer는 32개의 filter를 사용하고 이후에 19개의 Residual Bottleneck 레이어를 사용한다.
-
기존의 ReLU함수 대신 ReLU6 함수를 사용했는데 이는 low-precison computation에서 사용될 때를 위해서 사용하였다 식은 다음과 같다.
-
현대의 network들과 동일하게 3x3 kernel size의 conv 연산을 사용하고 dropout과 BatchNorm을 사용하였다.
-
첫 레이어르 제외한 나머지 레이어는 expansion rate 상수를 사용하였다. 본 실험에서는 5~10 정도의 expansion rate에서 성능이 좋았다.(작은 넥트워크에서는 약간 작은게 더 낫고 큰 네트워크에서는 큰게 더 나았다.)
-
본 논문에서 사용한 expansion rate는 6으로 고정하였다 예를들면 64개의 채널을 입력으로 하고 출력 채널은 128로 한다면 채널 수의 변화 과정은 64 -> 384(64*6) -> 128이 된다.
자세한 구현은 다음과 같다.

t는 expansion rate c는 채널 수 n은 반복횟수 s는 첫 번째 반복에서의 stride 수다.
3.1 Hyper parameters ( Width Multiplier )
MobileNet V1과 동일하게 Width multiplier를 사용하였다.
MobileNet V2는 주로 Width multiplier는 1 해상도는 224x224를 사용하였디.
이러한 width multiplier와 해상도를 각각 0.35 ~ 1.4 , 96 ~ 224로 하여 성능을 trade off 했다.
MobileNet V1과의 구현의 차이는 Width Multiplier를 1보다 작게 설정하였고 마지막 Conv layer를 제외한 모든 레이어에 적용하였다.
이는 작은 모델에서 성능 향상을 이뤄냈다.
4. Memory Efficient Inference
이 부분에서는 computation을 최소화하는 식과 이를 어떻게 간소화 하는지를 나타내지만 이부분은 자세히 보지 않고 Bottleneck Residual Block부분을 볼 것입니다.
Inverted Residual Bottleneck 레이어는 mobile 장치에서 많이 중요한 memory efficient 구현이다.
Inverted Residual Bottleneck 은 다음과 같은 식으로 구성될 수 있다.
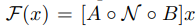
이때 A, N과 B는 다음과 같다.
A는 선형 변환으로 SxSxk 를 SxSxn으로 변환하고
N은 비선형 채널별 변환(Depthwise conv연산이기 때문에)으로 SxSxn 을 S'xS'xn으로 변환한다.
B는 출력 domain으로의 선형 변환으로 S'xS'xn을 S'xS'xk'으로 변환한다.
이때 MobileNet V2에서 N은 다음과 같다.
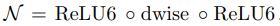
F(x) 연산에서 필요한 최소 메모리는 다음과 같이 표현될 수 있다.
이때 내부 tensor L이 n/t사이즈의 t개의 tensor의 concatenation이라고 볼 때 F(x)는 다음과 같이 표현될 수 있다.
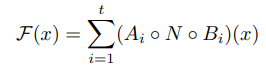
이런 경우 중간 블록 N에서 block의 크기는 n/t만큼만 메모리에 저장되면 된다.
n==t인 경우에는 오직 하나의 중간 채널만 메모리에 저장되면 된다.
아래의 두 경우 때문에 위의 방법이 가능하게 되었다.
-
내부 변환(비선형 변환과 depthwise conv을 포함하여)이 채널별(per-channel) 연산인점
-
이어지는 non per channel 연산은 상당한 입출력 크기 비율을 가진다.
이런 방식은 성능 향상을 이뤄내지 못했다.
F(x)를 t개로 나누어 연산하는 것의 연산의 수는 t에대해 독립적이다.(영향을 주지 않는다.)
그러나 더 작게 나누어 matrix multiplication을 하는 것은 cache miss의 증가로 인해 실행시간에 악영향을 준다.
이러한 접근법은 t가 2~5사이의 작은 수일 때 도움이 된다.
이는 memory 필요량을 줄이게 된다.
5. 코드구현
Keras
import keras
def inverted_residual_block(input,t,c,n,s):
x = input
for i in range(n):
if i == 0 :
stride = s
else :
stride = 1
shortcut = x
x = keras.layers.Conv2D(x.shape[-1]*t,1,1,'same')(x)
x = keras.layers.BatchNormalization()(x)
x = keras.activations.relu6(x)
x = keras.layers.DepthwiseConv2D(3,stride,'same')(x)
x = keras.layers.BatchNormalization()(x)
x = keras.activations.relu6(x)
x = keras.layers.Conv2D(c,1,1,'same')(x)
x = keras.layers.BatchNormalization()(x)
if (stride == 1) and (i != 0):
x = keras.layers.Add()([shortcut,x])
return x
def mobilenetv2(w=1.0):
input = keras.layers.Input((224,224,3))
x = keras.layers.Conv2D(int(32*w),3,2,'same')(input)
x = keras.layers.BatchNormalization()(x)
x = keras.activations.relu6(x)
x = inverted_residual_block(x,1,int(16*w),1,1)
x = inverted_residual_block(x,6,int(24*w),2,2)
x = inverted_residual_block(x,6,int(32*w),3,2)
x = inverted_residual_block(x,6,int(64*w),4,2)
x = inverted_residual_block(x,6,int(96*w),3,1)
x = inverted_residual_block(x,6,int(160*w),3,2)
x = inverted_residual_block(x,6,int(320*w),1,1)
x = keras.layers.Conv2D(int(1280*w),1,1,'same')(x)
x = keras.layers.BatchNormalization()(x)
x = keras.activations.relu6(x)
x = keras.layers.GlobalAvgPool2D()(x)
x = keras.layers.Dense(1000)(x)
x = keras.activations.softmax(x)
return keras.Model(inputs=input,outputs=x,name='MobileNetV2')
model = mobilenetv2()
model.summary()PyTorch
import torch.nn as nn
from torchsummary import summary
class inverted_residual_block(nn.Module):
def __init__(self,i,t,c,s,shortcut=False):
super(inverted_residual_block,self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(i,i*t,1,1),
nn.BatchNorm2d(i*t),
nn.ReLU6()
)
self.dconv = nn.Sequential(
nn.Conv2d(i*t,i*t,3,s,1,groups=i*t),
nn.BatchNorm2d(i*t),
nn.ReLU6()
)
self.linearconv = nn.Sequential(
nn.Conv2d(i*t,c,1,1),
nn.BatchNorm2d(c)
)
self.shortcut = shortcut
def forward(self,x):
out = self.conv(x)
out = self.dconv(out)
out = self.linearconv(out)
if self.shortcut :
out += x
return out
class mobilenetv2(nn.Module):
def __init__(self,w=1.0):
super(mobilenetv2,self).__init__()
def make_layers(i,t,c,n,s):
layers = []
layers.append(inverted_residual_block(i,t,c,s))
for i in range(1,n):
layers.append(inverted_residual_block(c,t,c,1,True))
return nn.Sequential(*layers)
self.conv1 = nn.Sequential(
nn.Conv2d(3,int(32*w),3,2,1),
nn.BatchNorm2d(int(32*w)),
nn.ReLU6()
)
self.irb1 = make_layers(int(32*w),1,int(16*w),1,1)
self.irb2 = make_layers(int(16*w),6,int(24*w),2,2)
self.irb3 = make_layers(int(24*w),6,int(32*w),3,2)
self.irb4 = make_layers(int(32*w),6,int(64*w),4,2)
self.irb5 = make_layers(int(64*w),6,int(96*w),3,1)
self.irb6 = make_layers(int(96*w),6,int(160*w),3,2)
self.irb7 = make_layers(int(160*w),6,int(320*w),1,1)
self.conv2 = nn.Sequential(
nn.Conv2d(int(320*w),int(1280*w),1,1),
nn.BatchNorm2d(int(1280*w)),
nn.ReLU6(),
nn.AdaptiveAvgPool2d(1)
)
self.conv3 = nn.Linear(int(1280*w),1000)
def forward(self,x):
out = self.conv1(x)
out = self.irb1(out)
out = self.irb2(out)
out = self.irb3(out)
out = self.irb4(out)
out = self.irb5(out)
out = self.irb6(out)
out = self.irb7(out)
out = self.conv2(out)
out = out.view(out.size(0),-1)
out = self.conv3(out)
return out
summary(mobilenetv2(),(3,224,224))
혹시
mobilenet에서 expansion이 왜 필요한지에 대한 목적과
왜 이런 구조로 만들었는지
v1 -> v2갈때의 bottlneck이 왜 들어갔는지 또 들어간 이후 성능이 향상된 이유
v2->v3로 갈때 senet이 어떻게 선능이 좋아지는 원리에 대해 설명이나 참고 사이트 알려주실수있나여?