본 페이지에서는 UNet++: A Nested U-Net Architecture for Medical Image Segmentation논문에 대해서 말하고자 합니다.
1. UNET++의 특징
UNet++는 각 네트워크가 Dense하게 연결되어 있는 skip connection을 가지고 있다.
이러한 구조가 encoder와 decoder 사이의 의미론적 차이를 줄일 수 있게 하였다.
본 논문에서는 encoder와 decoder 사이에 의미론적 차이가 적을 수록 학습이 더 잘된다고 주장한다.
그리고 Deep supervision을 사용하여 좋은 성능을 냈음을 mIoU를 사용해 증명했다.
기존의 네트워크들의 공통점은 encoder와 decoder 사이에 의미론적 차이가 줄어들게 하는 skip connection을 사용한 것이다.
또한 기존의 네트워크들은 성능을 만족할만큼 올렸지만 의료 이미지에 사용하기는 애매한 성능이다.
의료 이미지에서 부정확한 segmentation은 치명적이기 때문에 UNET++를 제안한다.
2. UNET++의 구조
UNET의 기본 구조를 가지면서 skip connection 방법을 수정했는데 아래의 그림을 참고하자.
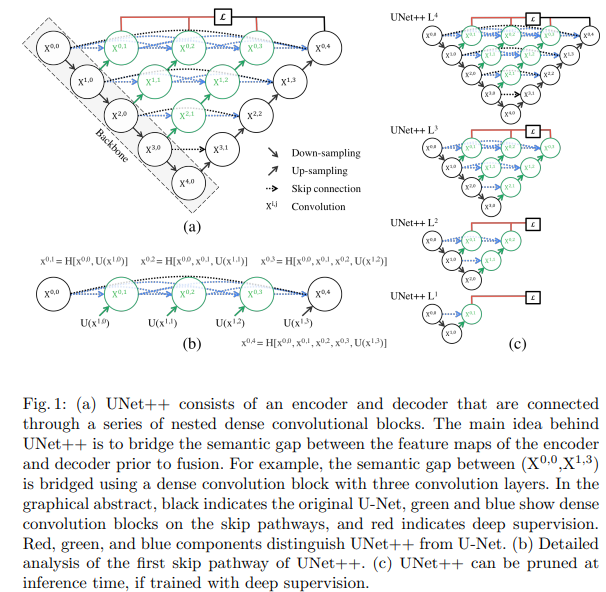
같은 층에 있는 layer들은 Dense Convolution layer를 따른다.
이렇게 얻어진 layer들을 concatenate한 후 아래의 dense block과 함께 또 concatenate연산을 하고 Conv 연산을 진행한다.
이를 식으로 표현하면 아래와 같은데 i는 레벨을 나타내고 j은 같은 층의 블럭 index를 말한다.
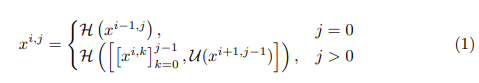
이때 H는 Convolution -> ReLU를 의미한다.
[]는 concatenate 연산을 의미하고
u는 upsample을 의미한다.
3. Deep supervision
Deep supervision은 두가지 모드를 가능하게 하는데 기능은 아래와 같다
accurate mode: 모든 출력을 평균을 내어 사용하는 것
fast mode:마지막 출력만을 사용하는 것
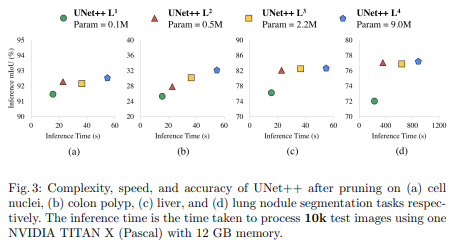
Pruning
Pruning은 Fig1에서 C부분을 보면 확인할 수 있고 다양한 Pruning에서의 성능 수치는 다음과 같다.
4. Dice-Cross Entropy
UNet++에서는 Binary Cross Entrophy loss와 dice coeifficient를 결합해 Loss 함수로 사용하였고 그 식은 아래와 같다.
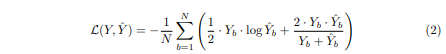
5. 코드구현
Keras
import keras
def conv(input,features,kernel_size=3,strides = 1,padding='same',is_relu=True,is_bn=False):
x= keras.layers.Conv2D(features,kernel_size,strides,padding)(input)
if is_bn:
x = keras.layers.BatchNormalization()(x)
if is_relu:
x = keras.activations.relu(x)
return x
def unet2(n_levels,DSV=True, initial_features=64, n_blocks=2, kernel_size=3, pooling_size=2, in_channels=1, out_channels=1):
inputs = keras.layers.Input(shape=(400, 400, in_channels))
x = inputs
#인코더부분
skips = []
for _ in range(n_levels):
skips.append(list())
for level in range(n_levels):
if level != 0 :
x = keras.layers.MaxPool2D(pooling_size)(x)
for _ in range(n_blocks):
x = conv(x,initial_features * 2 ** level,3,1,'same')
skips[level].append(x)
#스킵 생성 부분
for i in range(1,n_levels):
for level in range(n_levels-i):
list_concat = []
for row in range(i):
list_concat.append(skips[level][row])
x = skips[level+1][i-1]
x = keras.layers.UpSampling2D(pooling_size, interpolation='bilinear')(x)
list_concat.append(x)
x = keras.layers.Concatenate()(list_concat)
x = conv(x,initial_features * 2 ** level,3,1,'same')
skips[level].append(x)
# 출력부분
result = []
if DSV:
for i in range(1,n_levels):
result.append(keras.layers.Conv2D(out_channels, kernel_size=1, padding='same')(skips[0][i]))
else:
result.append(keras.layers.Conv2D(out_channels, kernel_size=1, padding='same')(skips[0][-1]))
for i in range(len(result)):
if out_channels == 1:
result[i] = keras.activations.sigmoid(result[i])
else:
result[i] = keras.activations.softmax(result[i])
#모델 이름 설정
output_name=f'UNET2-L{n_levels}-F{initial_features}'
if DSV:
output_name+='-DSV'
return keras.Model(inputs=[inputs], outputs=result, name=output_name)
model = unet2(5,True)
model.summary()PyTorch
import torch
import torch.nn as nn
from torchsummary import summary
class UNet2(nn.Module):
def __init__(self,DSV=True):
super(UNet2,self).__init__()
self.DSV = DSV
def cbr(in_channels, out_channels, kernel_size = 3, stride = 1):
layers = nn.Sequential(
nn.Conv2d(in_channels,out_channels,kernel_size,stride,1),
#nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(out_channels,out_channels,kernel_size,stride,1),
#nn.BatchNorm2d(out_channels),
nn.ReLU()
)
return layers
def h(y,x,kernel_size = 3, stride = 1):
in_channels = (64*2**y)*x+(64*2**(y+1))
out_channels = 64*2**y
layers = nn.Sequential(
nn.Conv2d(in_channels,out_channels,kernel_size,stride,1),
nn.ReLU()
)
return layers
self.enc0_0 = cbr(1,64)
self.enc1_0 = cbr(64,128)
self.enc2_0 = cbr(128,256)
self.enc3_0 = cbr(256,512)
self.enc4_0 = cbr(512,1024)
self.pool = nn.MaxPool2d(2,2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear')
self.block0_1 = h(0,1,3,1)
self.block1_1 = h(1,1,3,1)
self.block2_1 = h(2,1,3,1)
self.block3_1 = h(3,1,3,1)
self.block0_2 = h(0,2,3,1)
self.block1_2 = h(1,2,3,1)
self.block2_2 = h(2,2,3,1)
self.block0_3 = h(0,3,3,1)
self.block1_3 = h(1,3,3,1)
self.block0_4 = h(0,4,3,1)
self.result = nn.Sequential(
nn.Conv2d(64,1,1,1,1),
nn.Sigmoid()
)
def forward(self,x):
enc0_0 = self.enc0_0(x)
pool1 = self.pool(enc0_0)
enc1_0 = self.enc1_0(pool1)
pool2 = self.pool(enc1_0)
enc2_0 = self.enc2_0(pool2)
pool3 = self.pool(enc2_0)
enc3_0 = self.enc3_0(pool3)
pool4 = self.pool(enc3_0)
enc4_0 = self.enc4_0(pool4)
block0_1 = self.block0_1(torch.cat([enc0_0,self.up(enc1_0)],1))
block1_1 = self.block1_1(torch.cat([enc1_0,self.up(enc2_0)],1))
block2_1 = self.block2_1(torch.cat([enc2_0,self.up(enc3_0)],1))
block3_1 = self.block3_1(torch.cat([enc3_0,self.up(enc4_0)],1))
block0_2 = self.block0_2(torch.cat([enc0_0,block0_1,self.up(block1_1)],1))
block1_2 = self.block1_2(torch.cat([enc1_0,block1_1,self.up(block2_1)],1))
block2_2 = self.block2_2(torch.cat([enc2_0,block2_1,self.up(block3_1)],1))
block0_3 = self.block0_3(torch.cat([enc0_0,block0_1,block0_2,self.up(block1_2)],1))
block1_3 = self.block1_3(torch.cat([enc1_0,block1_1,block1_2,self.up(block2_2)],1))
block0_4 = self.block0_4(torch.cat([enc0_0,block0_1,block0_2,block0_3,self.up(block1_3)],1))
out = []
if self.DSV:
out.append(self.result(block0_1))
out.append(self.result(block0_2))
out.append(self.result(block0_3))
out.append(self.result(block0_4))
else:
out.append(self.result(block0_4))
return out
summary(UNet2(),(1,400,400))