본 페이지에서는 U-Net: Convolutional Networks for Biomedical Image Segmentation 논문에 대해서 말하고자 합니다.
1. UNET 특징
이전의 모델들은 모델의 크기에 비해 학습 데이터가 적어서 성능 향상은 이루어지지만 어느정도 제한이 있었다.
또한 기존의 Segmenation 방식은 두가지 취약점이 있는데
첫번째로 patch를 분리해서 실행되고 patch가 겹치면서 중복이 너무 많아 모델이 너무 느리다는 것이고
두번째로 패치가 오직 적은 부분의 context 정보 만을 보기 때문에 context 정보의 사용과 위치정보의 정확성 사이의 trade off가 있다는 것이다.
UNET 은 다음과 같은 두 구조로 나뉘는데
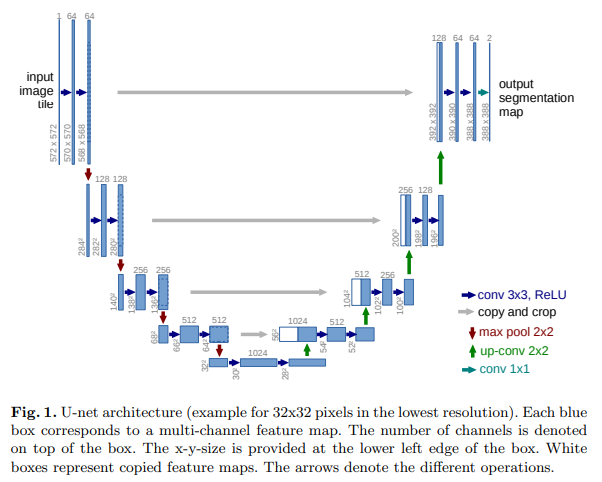
위 이미지에서 절반을 기준으로 왼쪽을 Contracting path(수축) 오른쪽을 Expanding path(팽창)라고 한다.
Contracting path는 위치정보와 context정보를 추출하고
Expaning path는 정확한 위치를 파악하게 할 수 있다.
본 모델은 FCN을 기반으로 구현이 됐는데 이 구조는 적은 수의 의미지로도 정확한 segmentation을 가능하게 했다.
팽창 경로의 구현은 수축 경로와 비슷하지만 pooling 연산을 upsample 연산으로 바꾸는 방법을 사용했다.
upsample을 하면 해상도가 커지게 되는데 이때 위치 정보를 얻어내기위해 수축 경로의 feature와 upsample된 출력을 결합한다.
이러한 구조 때문에 context 정보의 손실을 보완할 수 있게 되는 것이다.
이후 이어지는 Convolution layer는 이를 바탕으로 더 정확한 출력을 낼 수 있도록 학습된다.
이를 반복해 다양한 레이어의 출력을 이용하는 것은 위치정보와 context 정보 사용을 동시에 가능하게 했다.
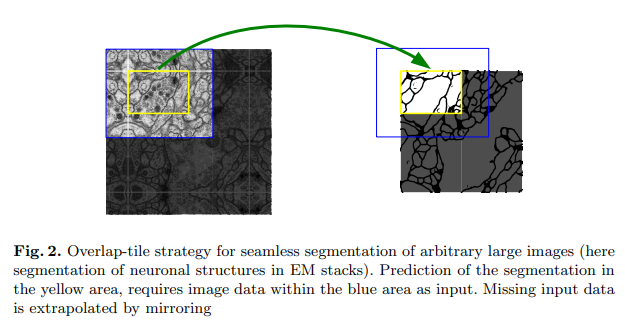
그러나 이러한 구조 때문에 아래의 그림처럼 원본 이미지보다는 적은 경계에 대해서 segmentation이 된다.
또한 이런 구조 덕분에 적은 수의 데이터 셋으로도 학습이 쉽게 가능해지는 것이였고 이러한 특성 때문에 데이터 셋이 부족하고 높은 정확도를 요구하는 의료 이미지에 대해 적합한 모델이라고 알려져있다.
2. 구조
수축 경로는 일반적인 conv network와 비슷한 구조를 따르곤다. (3x3conv->ReLU->3x3conv->ReLU->MaxPool)
팽창 경로는 다음과 같이 구성된다. Upsample-> 2x2Conv(채널수 줄이기) ->3x3 Conv -> ReLU->3x3 Conv -> ReLU
이때 upsample된 feature는 수축경로의 같은 높이에 있는 feature map과 concatenate 연산을 한다.
최종적으로 1x1 conv를 사용해 클래스에 맞는 채널의 수로 전환해준다.
논문대로 구현을 한다면(conv연산을 할때 zero padding을 사용하지 않음) Fig 2 처럼 작은 이미지가 나오지만 구현을 할 때는 zero padding을 사용함
3. 코드구현
Keras
import keras
def conv(input,features,kernel_size=3,strides = 1,padding='same',is_relu=True,is_bn=True):
x = keras.layers.Conv2D(features,kernel_size,strides,padding)(input)#,kernel_initializer='he_normal'
if is_bn:
x = keras.layers.BatchNormalization()(x)
if is_relu:
x = keras.activations.relu(x)
return x
def unet(n_levels, initial_features=64, n_blocks=2, kernel_size=3, pooling_size=2, in_channels=1, out_channels=1):
inputs = keras.layers.Input(shape=(400, 400, in_channels))
x = inputs
#인코더부분
skips = []
for level in range(n_levels):
if level != 0 :
x = keras.layers.MaxPool2D(pooling_size)(x)
for _ in range(n_blocks):
x = conv(x,initial_features * 2 ** level,3,1,'same')
skips.append(x)
# 디코더 부분
for level in reversed(range(n_levels-1)):
x = keras.layers.UpSampling2D(pooling_size,interpolation='bilinear')(x)
x = conv(x,initial_features * 2 ** level,3,1,'same')
x = keras.layers.Concatenate()([x, skips[level]])
for i in range(n_blocks):
x = conv(x,initial_features * 2 ** level,3,1,'same')
# 결과
x = keras.layers.Conv2D(out_channels, kernel_size=1, padding='same')(x)
if out_channels == 1:
x = keras.activations.sigmoid(x)
else:
x = keras.activations.softmax(x)
return keras.Model(inputs=[inputs], outputs=x, name=f'UNET-L{n_levels}-F{initial_features}')
model = unet(5)
model.summary()
PyTorch
import torch
import torch.nn as nn
from torchsummary import summary
class UNet(nn.Module):
def __init__(self):
super(UNet,self).__init__()
def cbr(in_channels, out_channels, kernel_size = 3, stride = 1):
layers = nn.Sequential(
nn.Conv2d(in_channels,out_channels,kernel_size,stride,1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
return layers
self.enc1_1 = cbr(1,64)
self.enc1_2 = cbr(64,64)
self.pool1 = nn.MaxPool2d(2,2)
self.enc2_1 = cbr(64,128)
self.enc2_2 = cbr(128,128)
self.pool2 = nn.MaxPool2d(2,2)
self.enc3_1 = cbr(128,256)
self.enc3_2 = cbr(256,256)
self.pool3 = nn.MaxPool2d(2,2)
self.enc4_1 = cbr(256,512)
self.enc4_2 = cbr(512,512)
self.pool4 = nn.MaxPool2d(2,2)
self.enc5_1 = cbr(512,1024)
self.enc5_2 = cbr(1024,1024)
self.unpool4 = nn.ConvTranspose2d(1024,512,2,2)
self.dec4_2 = cbr(1024,512)
self.dec4_1 = cbr(512,512)
self.unpool3 = nn.ConvTranspose2d(512,256,2,2)
self.dec3_2 = cbr(512,256)
self.dec3_1 = cbr(256,256)
self.unpool2 = nn.ConvTranspose2d(256,128,2,2)
self.dec2_2 = cbr(256,128)
self.dec2_1 = cbr(128,128)
self.unpool1 = nn.ConvTranspose2d(128,64,2,2)
self.dec1_2 = cbr(128,64)
self.dec1_1 = cbr(64,64)
self.result = nn.Sequential(
nn.Conv2d(64,1,3,1,1),
nn.Sigmoid()
)
def forward(self,x):
enc1_1 = self.enc1_1(x)
enc1_2 = self.enc1_2(enc1_1)
pool1 = self.pool1(enc1_2)
enc2_1 = self.enc2_1(pool1)
enc2_2 = self.enc2_2(enc2_1)
pool2 = self.pool2(enc2_2)
enc3_1 = self.enc3_1(pool2)
enc3_2 = self.enc3_2(enc3_1)
pool3 = self.pool3(enc3_2)
enc4_1 = self.enc4_1(pool3)
enc4_2 = self.enc4_2(enc4_1)
pool4 = self.pool4(enc4_2)
enc5_1 = self.enc5_1(pool4)
enc5_2 = self.enc5_2(enc5_1)
unpool4 = self.unpool4(enc5_2)
dec4_2 = self.dec4_2(torch.cat((unpool4,enc4_2),1))
dec4_1 = self.dec4_1(dec4_2)
unpool3 = self.unpool3(dec4_1)
dec3_2 = self.dec3_2(torch.cat((unpool3,enc3_2),1))
dec3_1 = self.dec3_1(dec3_2)
unpool2 = self.unpool2(dec3_1)
dec2_2 = self.dec2_2(torch.cat((unpool2,enc2_2),1))
dec2_1 = self.dec2_1(dec2_2)
unpool1 = self.unpool1(dec2_1)
dec1_2 = self.dec1_2(torch.cat((unpool1,enc1_2),1))
dec1_1 = self.dec1_1(dec1_2)
out = self.result(dec1_1)
return out
summary(UNet(),(1,400,400))