
1. 일변량 질적자료 분석
1) 표
(1) 빈도 (Frequency)
data.variable.value_counts(ascending = False)
(2) 백분율 (Percent)
data.variable.value_counts(normalize = True, ascending = False)*100
round(소수점이 있는 데이터, ndigits = 1) # 소수점 첫째자리 반올림
2) 그래프
import matplotlib.pyplot as plt
(1) 막대 그래프
plt.bar(x = height.index, height = 빈도 or 백분율, color = )
plt.title('')
plt.xlabel('')
plt.ylabel('')
plt.show() 
(2) 원 그래프
plt.pie(x = 빈도 or 백분율,
lables = x.index,
radius = 반지름,
counterclock = True or False,
startangle = 0 ~ 360)
plt.title('')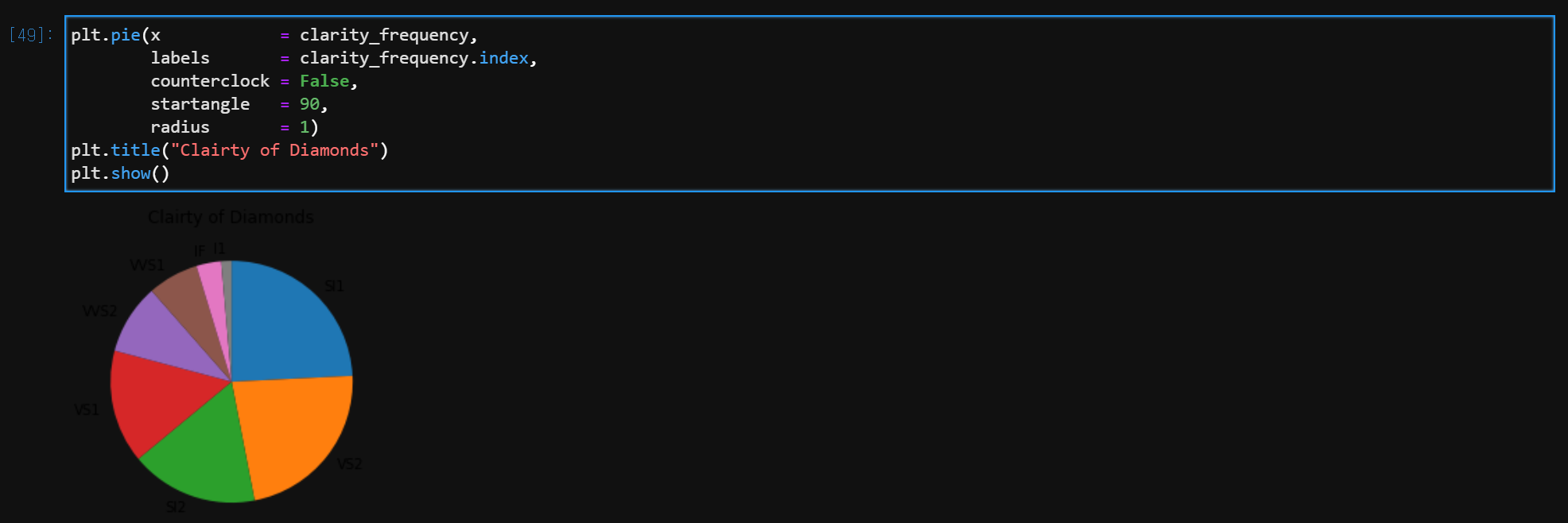
2. 일변량 양적자료 분석
1) 그래프
(1) 히스토그램 (Histogram)
plt.hist(x = 양적 자료, bins = 구간의 정보 : 구간, 구간의 개수)
plt.show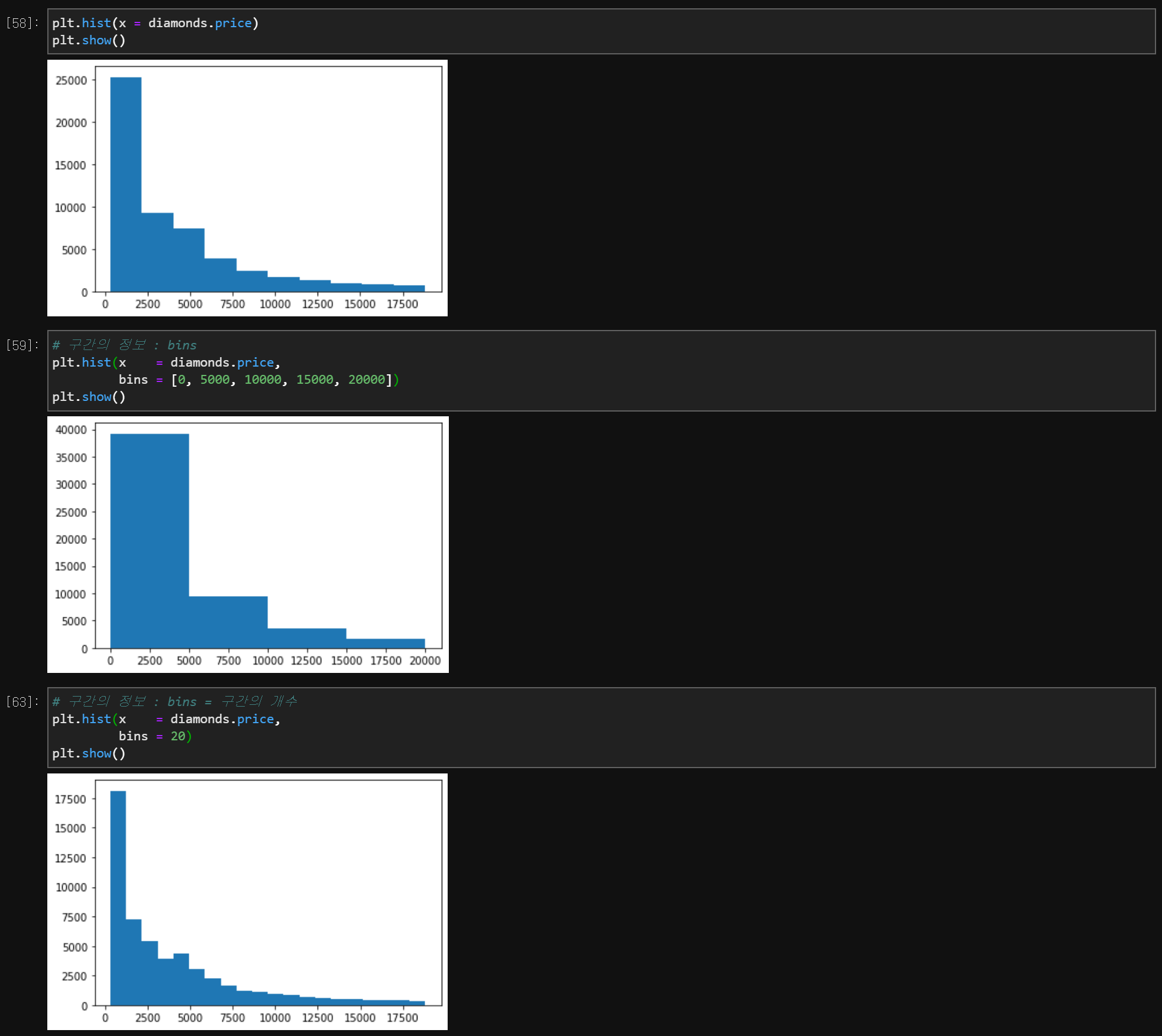
가로를 고려하지 않고 세로의 높이로만 나타내는 막대그래프와는 다르게
히스토그램은 가로와 세로를 함께 고려해야 한다.
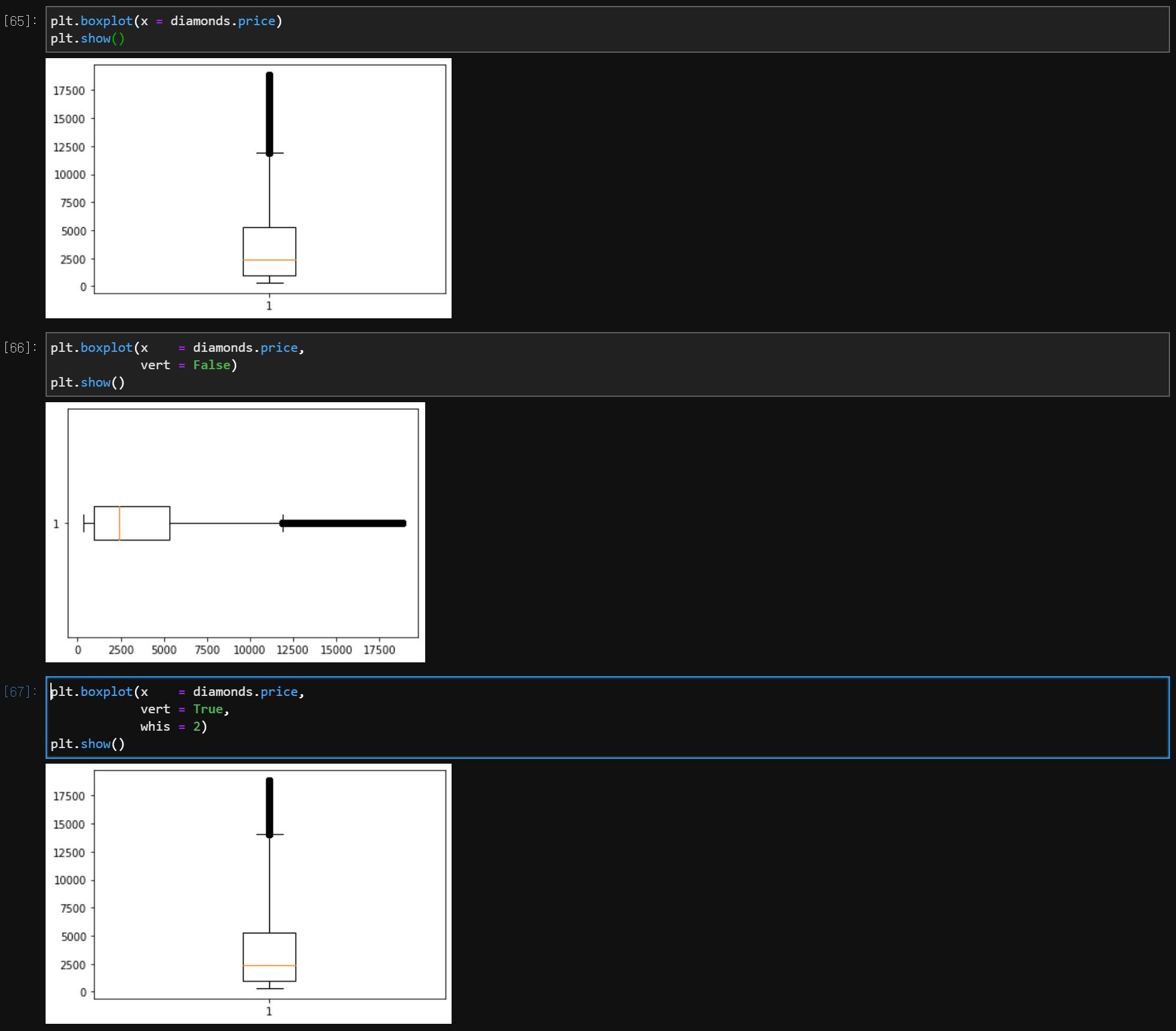
(1) 상자그림 (Boxplot)
plt.boxplot(x = 양적 자료, vert = True or False, whis = 1.5)
# vert = True : 세로형, False : 가로형
# whis = 1.5 : default, IQR에 어떤 값을 곱할지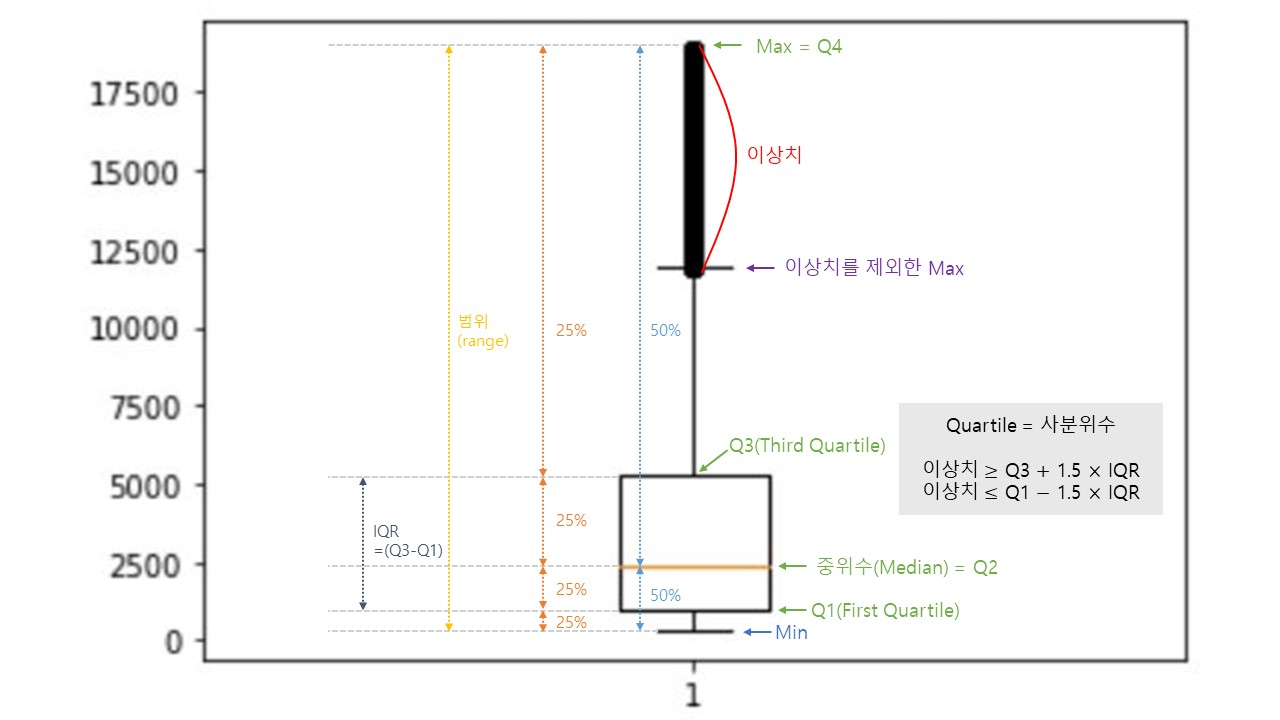
3. 기술통계량 (numpy 사용하기)
import numpy as np1) 평균 (mean, average)
data.variable.mean() #양적 자료2) 중위수 (median)
data.variable.median() #양적 자료3) 최빈수 (mode)
data.variable.mode()
Counter(data.variable).most_common() #가장 많은 숫자와 개수4) 절사평균 (Trimmed mean)
stats.trim_mean(data.variable, proportiontocut = 0.05)
#scipy 사용
#0.05 = 5%5) 범위 (range)
data.variable.max() - data.variable.min()6) 사분위 범위(IQR) : Q3 - Q1
np.percentile(data.variable, q = 75) - np.percentile(data.variable, q = 25)7) 표준편차 (SD)
data.variable.std()8) 중위수 절대편차 (MAD)
import statsmodels import robust
robust.mad(data.variable)9) 통계량
data.variable.describe()
data.describe()
data.describe(include = 'all')
#include : 'all', [object], ['category'], [np.number]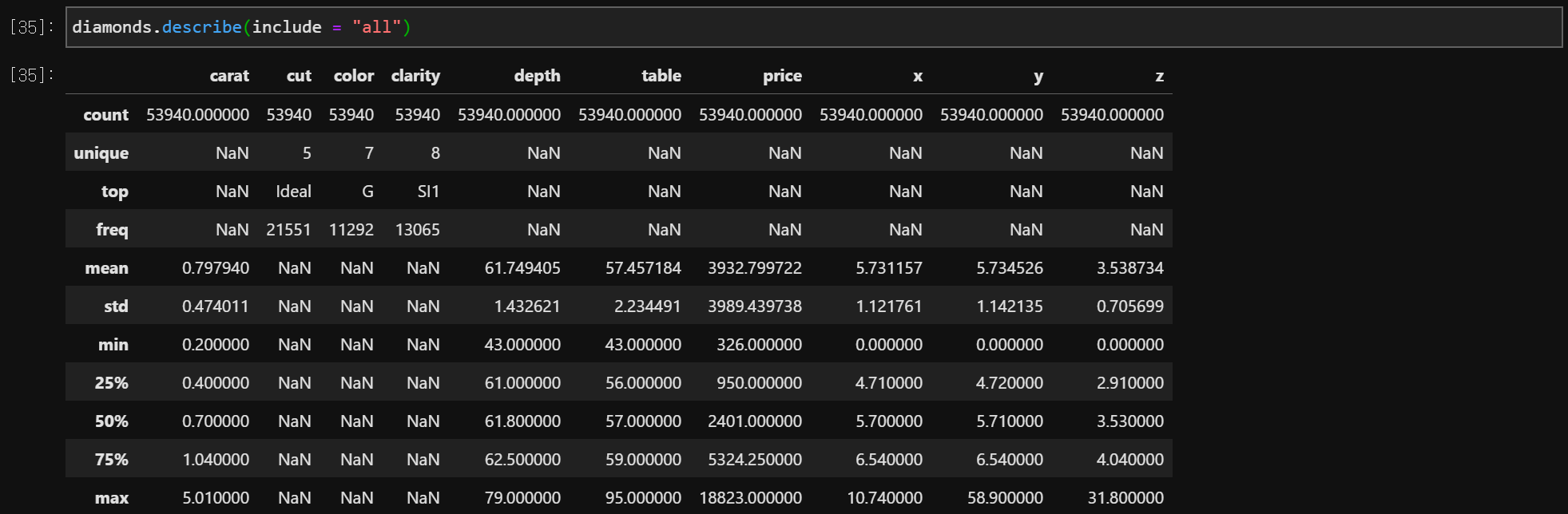
10) 왜도
data.variable.skew()11) 첨도
data.variable.kurt()
Back-end, Python, Data