A Survey on Model Compression and Acceleration for Pretrained Language Models, 2022
A Survey on Model Compression and Acceleration for Pretrained...
Low rank Factorization
- Decomposing Linear Layers
- 대표적으로 SVD
- 2021년 이후 논문
- Compressing Pre- trained Language Models by Matrix Decomposition, 2020
- DRONE, 2021
- Kronecker decomposition, 2021
- Decomposing Embedding
- embedding layer, which has redundant parameters due to its high input and output dimensions
- the parameters in the token embedding layer are not efficient ➡️ reduce them by factorizing the embedding matrix
- Sub- former: Exploring Weight Sharing for Parameter Efficiency in Generative Transformers, 2021
- self-attentive factorized embeddings (SAFE) by adding a small self-attention layer on the basis of linear projection to achieve better performance
그 외 다른 방법 : Weight Sharing, Pruning, Quantization, Knowledge Distillation, Early Exit, Token Skipping
LoSparse: Structured Compression of Large Language Models based on Low-Rank and Sparse Approximation, 2023
- low-rank approximations, pruning 동시에 적용해서 서로를 보완
- approximates a weight matrix by the sum of a low-rank matrix and a sparse matrix
- low-rank approximation aims to compress expressive bases of the coherent subspace shared by neurons
- while the sparse approximation focuses on removing non-expressive information in incoherent parts of neurons
- DSEE와 비교
- 두 논문 모두 combines both low-rank and sparse approximation
- 차이점
- DSEE - apply it to the incremental matrix that is attached to a dense backbone during parameter-efficient fine-tuning
LoSparse - aims to compress the full model instead of the incremental matrix so that it is capable of saving huge memory. - LoSparse - is motivated by the observation that large singular values exists in large pre-trained models
DSEE - the low-rank design in DSEE is inspired by the hypothesis that the change in weights during model adaptation has a low intrinsic rank(LORA)
- DSEE - apply it to the incremental matrix that is attached to a dense backbone during parameter-efficient fine-tuning
결론
- 본 논문은 전체 pretrained-weight를 Low rank approximation과 prunning을 이용해 Compression 시도
DSEE: Dually Sparsity-embedded Efficient Tuning of Pre-trained Language Models, 2021
Objective
- parameter efficient fine-tuning - by enforcing sparsity-aware low-rank updates on top
of the pre-trained weights - resource-efficient inference - by encouraging a sparse weight structure towards the final fine-tuned model.
- leverage sparsity in these two directions by exploiting both unstructured and structured sparse patterns in pre-trained language models via a unified approach
- draw on the prior of sparsity for both weight updates and the final weights, and establish a dually sparsity-embedding efficient tuning (DSEE) framework
LANGUAGE MODEL COMPRESSION WITH WEIGHTED LOW-RANK FACTORIZATION ( Fisher-Weighted SVD (FWSVD) ), 2022
Language model compression with weighted low-rank factorization

- 기존에 Compression을 위해 사용하는 SVD의 단점을 보완하고자 Fisher Information을 활용한 Fisher-Weighted SVD (FWSVD)를 도입
- 기존 SVD: the optimization objective of SVD does not consider each parameter’s impact on the task performance
- Compression 이전 모델 성능과 유사, 높은 Compression rate & Performance
What is Fisher Information

- 어떤 확률변수의 관측값으로부터, 확률변수의 분포의 매개변수에 대해 유추할 수 있는 정보의 양
SVD와 FWSVD의 차이
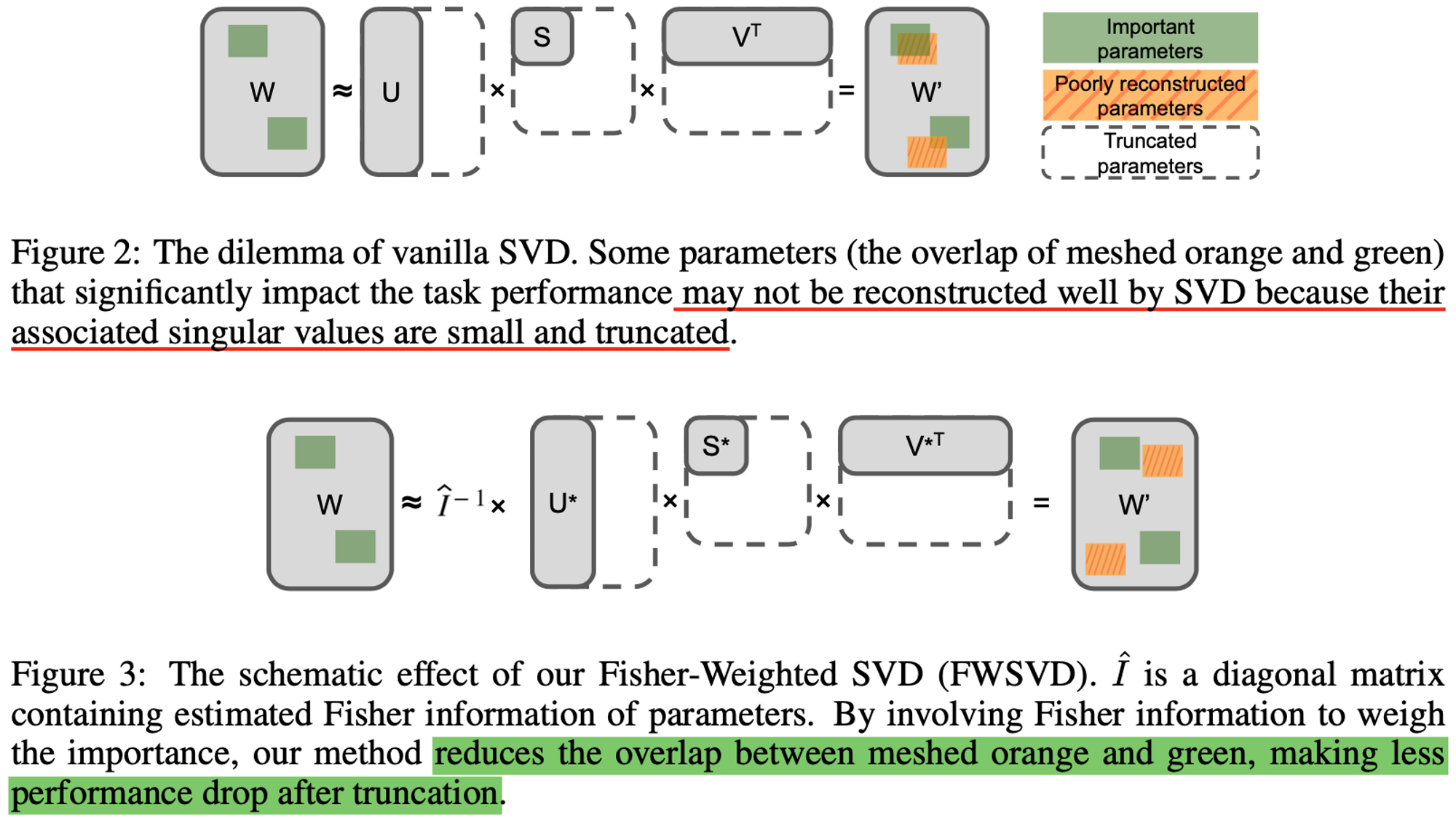
- the optimization objective of SVD does not consider each parameter’s impact on the task performance

※ 용어 정리
Reconstruction error
- it refers to the difference between the original model weights and the compressed model weights obtained through low-rank approximation
- A smaller reconstruction error indicates a better approximation of the original matrix and a higher likelihood of maintaining the performance of the original model
Truncation
- truncation refers to the process of reducing the rank of a matrix by keeping only the top k singular values in its Singular Value Decomposition (SVD)
DRONE: Data-aware Low-rank Compression for Large NLP Models, 2021
DRONE: Data-aware Low-rank Compression for Large NLP Models
-
BERT의 both feed-forward layers and attention layers모두 low-rank가 아니기 때문에 SVD를 사용하면 Reconstruction Error가 매우 크고, 그래서 Compression이 성공적이지 않다
- 본 논문은 weight matrices가 low-rank가 아니더라도 효과적으로 compress 하는 방법을 제시한다
-
NLP application에서 latent features는 often lie in a subspace with a low intrinsic dimension ➡ matrix-vector products는 weight matrices가 low-rank가 아니더라도 input vectors lie in a low dimensional subspace
-
Data Distribution Term을 포함하고 optimal rank-k decomposition을 위한 Closed-form Solution을 제공한다.
-
SVD를 Outperform하고 일반 BERT 뿐만 아니라 Distilled BERT에도 적용가능하다.
- MRPC에서 정확도 1.5% 하락 but 1.92배 빠르다
-
본 논문에서 주장하기론, Attention Module을 accelerating하는 것이 전체 Inference Time을 줄이는 데 크게 기여하지 못한다고 한다.
Attention complexity reduction only works when a long sequence is used but in current practice this is unusual. Thus, in many tasks accelerating the attention module itself does not contribute to a significant reduction of overall inference time.
- 그 이유는 Attention Module 뒤에 붙어있는 2개의 Feed-Forward이 훨씬 더 많은 Computational Time을 소모하기 떄문에 이를 조정해야 한다고 주장한다.


의문점
- BERT에만 적용한 이유? 과연 다른 모델(GPT2,3, RoBERTA)에 적용할 때도 동일한 결과일까?
Kronecker Decomposition for GPT Compression, 2021
- 크로네커 곱
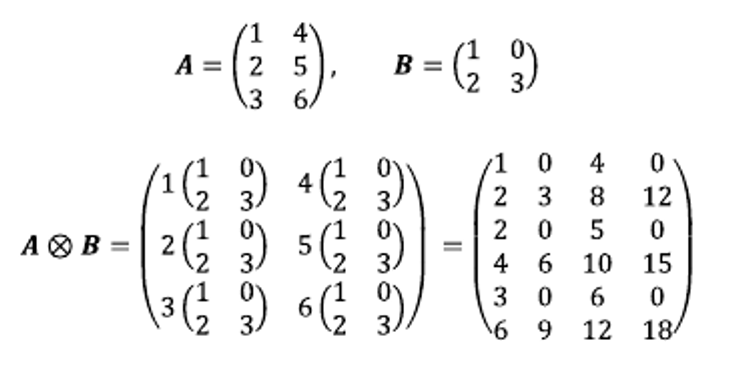
-
W ∈ IRm×n, by two smaller matrices, A ∈ IRm1×n1 and B∈IRm2×n2
- W=A⊗B and m=m1m2,n=n1n2
-
parameters : mn → m1n1+m2n2
- EX) W : 10241024 → A: 512512, B: 2*2
-
중요하게 언급되는 논문 : KroneckerBERT: Learning Kronecker Decomposition for Pre-trained Language Models via Knowledge Distillation
SUMMARY
Low-Rank를 사용해서 Weight Matrices를 Compression할 때
➡️ Low rank Factorization (Approximation이랑 거의 동일한 의미로 사용하는 듯)
크게 2가지 방법이 있는데 1. Decomposing Linear Layers 2. Decomposing Embedding
전자의 연구가 좀 더 활발한 듯.
대표적으로 SVD가 있다
But SVD 사용해 Compression하면 성능 매우 나빠 → 보완해서 적용해야 한다
- 성능 안 좋은 이유 (반복적으로 언급됨) : SVD는 Reconstruction Error를 Optimize하는 데, 이것이 모델의 성능을 올리는 것과 관련이 적다.
- Compressing Pre- trained Language Models by Matrix Decomposition, 2020
- 2 stage approach : SVD → Distill
- DRONE (Data-aware Low-rank Compression for Large NLP Models, 2021)
- Data Distribution 활용
- Kronecker decomposition (Kronecker Decomposition for GPT Compression, 2022)
- W=A⊗B, Kronecker product 사용
- Fisher-Weighted SVD (LANGUAGE MODEL COMPRESSION WITH WEIGHTED LOW-RANK FACTORIZATION, 2022)
- Fisher Information 도입해서 보완

4개의 댓글

survey biglots Just by completing the customer survey (available at https://biglotscomsurveywin.info), you may be entered to win a $1,000 Big Lots gift card.

Welcome to the survey on https://homdpotcomsurveys.org! Do you shop at Home Depot frequently? If so, Home Depot is interested in knowing your thoughts and suggestions.

It was opened in San Antonio, Texas, in 1952, near to the Alamo. That was the first Church's Chicken eatery.
https://churchschickenfeedback.live
The feedback from the Loyal Lowes customer experience survey is used to make improvements to the products, services, and Lowes stores. The survey is an essential tool for Lowes to ensure that it is meeting customer needs.
The Lowes Guest satisfaction survey can be finished at the online survey page https://lowes-survey.co/ and The survey takes only a few minutes to complete.
If you have recently shopped at a Lowes store, please spend a few minutes completing the Lowes customer survey. Your opinions will help to make Lowes a better store.
Here are some of the benefits of completing the Lowes Sweepstakes survey: