초록
CNN은 computer vision뿐만 아니라 natural language process, 그리고 다양한 산업과 학계에서 많은 관심을 받고 엄청난 성취를 거두었다. 이 논문에서는 CNN 의 많은 기발한 idea와 prospect를 review한다.
가장 처음 CNN의 역사, 두번째로는 CNN의 overview, 3번째는 고전적, 그리고 발전된 CNN 모델들을 소개한다. 4번째로 실험적인 분석을 통한 결론과 rules of thumb를 소개하고, 5번재로 다양한 차원에서의 CNN의 적용을 보이고, 마지막으로 CNN의 현재 이슈와 미래의 연구를 위한 방향성과 가이드라인을 소개함.
Brief Overview of CNN
CNN의 특징
다른 전통적인 feature extraction method와 달리 CNN은 수동적으로 특징을 추출하지 않는다. CNN은 인간의 시각적 퍼셉트론 (visual perceptron)에서 영감을 받았는데, 생물학적인 뉴런은 인공적인 뉴런과 대응되고, CNN의 커널은 다양한 특징을 수용하는 수용체를 표현하며, 활성화 함수는 어떤 일정한 threshold를 넘어야만 다음 뉴런으로 전달되는 뉴런의 전기적 신호의 특징을 표현한다.
CNN의 장점
CNN은 일반적인 ANN(Artificial Neural Network)에 비해 많은 이점이 존재한다. 첫번째로 각각의 뉴런은 더 이상 모든 뉴런과 연결되지 않고 국소적인 몇몇의 뉴런과 연결되어 parameter의 수를 덜어주고, 수렴 속도를 높여준다. 두번째로, 같은 weight (=kernel)을 사용하기 때문에 parameter의 수를 줄일 수 있다. 세번째로, pooling과 같은 방법을 사용한 downsampling을 통해 유용한 정보는 그대로 있지만 데이터의 양을 줄여주어 parameter 수를 줄일 수 있다.
CNN procedure
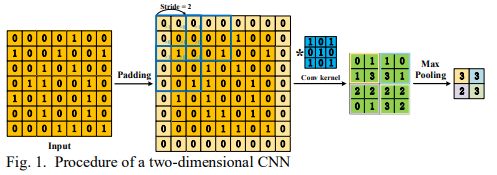
vanilla cNN
CNN의 과정은 아래 사진과 같다.
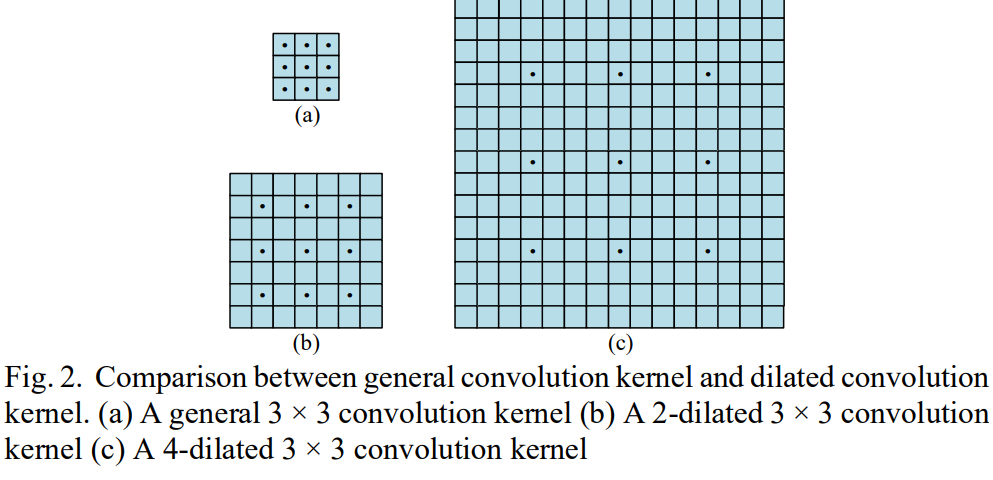
dilated CNN
kernel이 더 많은 영역을 인지할 수 있도록 dilated convolution이 제안되었다. 아래 사진에서 . 으로 표시된 부분이 값이 채워지는 부분이고, 나머지 부분은 0으로 채워진다. 즉, (b)는 실제론 3*3 kernel이지만 7*7 사이즈의 영역을 인지할 수 있고, (c)도 실제로는 3*3 kernel이지만 15*15 사이즈의 영역을 인지할 수 있다.
deformable CNN
또한 세상의 많은 물체의 형태가 대개 불규칙하다는 문제점을 해결하기 위해 deformable convolution이 제안되었다. deformable convolution은 feature map을 더 대표성을 띠게 함으로써 그들이 관심있는 것에 더 집중할 수 있게 한다.

Classic CNN Models
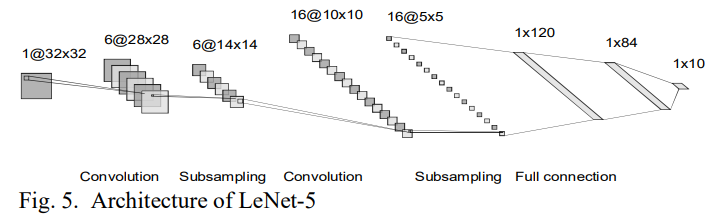
LeNet-5 (1998)
손글씨 인식을 위해 CNN과 Back Propagation을 사용한 모델이다. 7개의 trainable한 layer가 있고, 그 안에 2개의 convolution layer, 2개의 pooling layer, 3개의 fc layer가 있다. LeNet-5는 SVM과 Boosting 알고리즘보다 좋은 성능을 내진 못했고, 그 당시 주목 받지 못했지만 국소적인 receptive field, 공유되는 weight, subsampling 등을 조합한 CNN의 개척자 격의 모델이다.
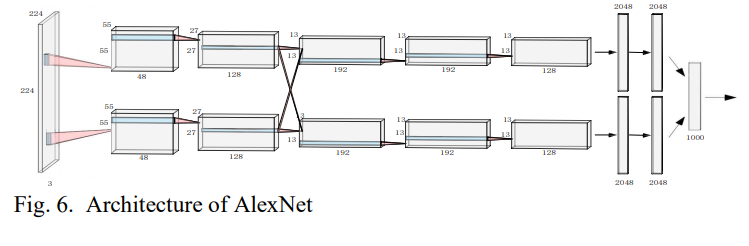
AlexNet (2012)
ImageNet 대회에서 1등을 차지한 모델이다. 8개의 layer가 있고, 그 안에는 5개의 convolutional layer와 3개의 fc layer가 있다. AlexNet은 LeNet의 아이디어와 CNN의 기본적인 원리를 deep and wide network에 적용한 모델이다. 다음은 AlexNet의 주요한 기술이다.
1. ReLU Activation Function
ReLU를 CNN layer의 활성화 함수로 사용하며 네트워크가 깊어질 때 발생하는 gradient vanishing problem을 완화시켰다.
2. Dropout
몇몇 개의 뉴런을 무시하며 학습을 시킴으로써 over-fitting을 방지했다. 이 방법은 마지막 단의 fc layer에 주요하게 적용되었다.
3. MaxPooling
이전의 CNN 모델에서는 Average Pooling이 많이 쓰였는데 이는 흐린(blurred) 결과를 발생시켰다. AlexNet에서는 MaxPooling을 사용함으로 그 결과를 피했고, feature에 더 많은 정보를 담게 했다.
4. Local Response Normalization
이는 자극을 전달받는 뉴런은 말초 신경의 활동을 억제할 수 있다는 생태학적인 신경계의 메카니즘을 시뮬레이션 하기 위해 고안되었다. 이와 비슷하게 LRN은 작은 값을 가진 뉴런을 억제하고, 큰 값을 가진 뉴런을 상대적으로 활동적으로 할 수 있게 한다. 이는 정규화와 매우 유사하다. 이러한 방법으로 LRN은 모델의 일반화 성능을 높여주었다. (아마 batch normalization과 비슷한 개념인 듯)
5. Multi GPU
AlexNet은 2대의 gpu를 사용하여 학습을 진행할 수 있는 구조를 개발했고, 결과적으로 2개의 feature map이 나오는데 이를 조합하여 최종 결과물을 만들었다.
6. Augmentation Methods
AlexNet은 training 과정에서 두가지 data augmentation 방법을 사용했다. 첫번째는 원래의 256*256 이미지에서 랜덤하게 224*224 패치를 추출하고 그것을 수평으로 대칭시켜 더 다양한 학습 데이터를 만들었다. 또한 학습 데이터셋의 RGB 값을 바꾸기 위해 PCA를 사용했다. 또한 예측할 때에도 데이터셋을 더 크게 만들어 그것들의 평균을 사용하여 최종 결과를 예측했다. 이를 통해 over-fitting 문제를 완화시키고, 일반화 성능을 향상시켰다.
VGGNets (2014)
ImageNet에서 1등을 차지한 모델이다. VGGNets의 저자는 신경망의 깊이가 늘어나면 어느 정도 최종 결과물의 성능이 향상된다는 것을 증명했다. AlexNet과 비교하여 VGGNets는 다음과 같은 발전점이 있었다.
1. LRN layers are removed
저자는 LRN layer가 깊은 CNN 모델에서 좋은 성능을 내지 못한다고 했고, LRN layer를 제거했다.
2. 3*3 kernel
저자는 5*5 kernel을 사용하기보다 3*3 kernel을 사용했다. 작은 사이즈의 커널을 여러 개 사용하는 것이 큰 사이즈의 커털 한 개를 사용하는 것 보다 같은 receptive field를 보더라도 더 많은 비선형 연산이 진행되기 때문이다. 예를 들어 5*5 커널은 3*3 커널 2개와 receptive field가 같다. 이때 parameter의 개수는 5*5 커널은 25개, 3*3 커널 2개는 18개로 적어진다.
GoogLeNet (2014)
ILSVRC 이미지 분류 대회에서 1등을 차지한 모델이다. 이 모델은 Inception 모듈을 쌓아 형성하여 만든 첫번재 large-scale CNN 모델이다.
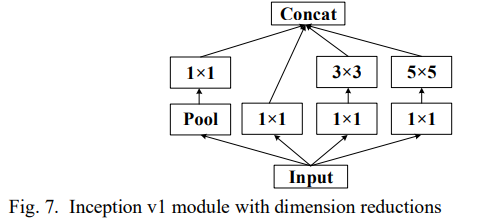
Inception v1
이미지 안의 객체들은 카메라와 거리가 서로 다르기 때문에 이미지의 비율이 큰 객체는 큰 사이즈의 커널이나 여러 개의 작은 커널을 선호하고, 비율이 작은 객체는 그 반대를 선호한다. 동시에, 큰 사이즈의 커널은 학습할 parameter의 수가 너무 많고, 깊은 네트워크를 쌓는다면 학습이 어렵다.
이를 해결하기 위해 Inception v1은 1*1, 3*3, 5*5 사이즈의 커널을 통해 넓은 네트워크를 구성한다. 다양한 사이즈의 커널을 이용하여 여러 feature maps를 추출하는 것이다. 이 feature maps는 더 잘 대표하는 것을 얻기 위해 쌓인다. 게다가 1*1 convolution은 channel을 줄이는데 유용하며 적은 parameter를 사용한다.
Inception v2
Inception v2는 batch normalization을 사용한다. 모든 layer의 결과는 정규분포로 정규화되어 모델의 robustness를 올리고, 상대적으로 큰 learning rate를 이용해 학습할 수 있게 한다. 또한 5*5 커널을 2개의 3*3 커널로 교체한다. 그리고 n*n 커널을 하나의 1*n 커널과 하나의 n*1 커널로 대체한다. 하지만 이런 factorization은 초기의 layer에서는 효과적이지 않고 medium size의 feature map에 더 효과적이다. 그러므로 마지막의 3*3 사이즈의 커널 또한 factorized 된다.
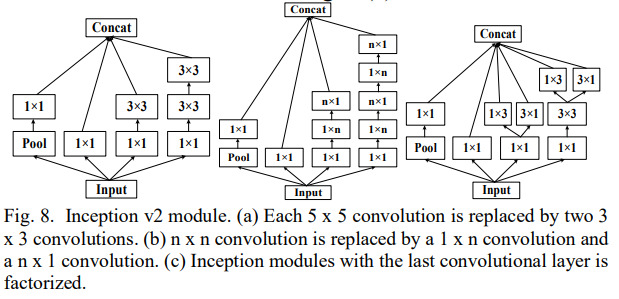
Inception v3
Inception v3는 Inception v2의 주요한 기술들을 통합시켰다. 그리고 5*5, 3*3 사이즈의 커널을 두 개의 커널로 쪼갰다. 이것은 학습을 가속화시키고, 네트워크의 깊이를 늘렸고, 네트워크의 비선형성 또한 늘어났다. 또한 input size가 224*224 에서 299*299로 늘어났고, optimizer로 RMSProp이 사용되었다.
Inception v4
Inception v4는 Inception v3를 기반으로 하고 더 간결하고 더 많은 Inception 모듈을 사용하는 모델이다.
추가적으로 ResNet은 Inception 네트워크의 깊이를 확장하기 위해 사용되어, Inception-ResNet-v1, Inception-ResNet-v2가 만들어지기도 했다. 이는 더 빠른 학습 속도와 성능을 보여준다.
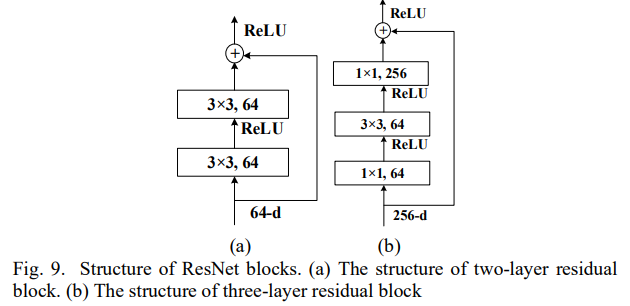
ResNet
딥러닝은 모델의 깊이가 얕은 것보다 이미지의 더 복잡하고 충분한 특징을 추출할 수 있지만, 층의 개수가 많아질수록 딥러닝은 gradinet vanishing problem과 gradient exploiding problem에 노출되기 쉬워졌다. 이 때 ResNet-34은 short connection을 통한 two-layer residual block을 사용하여 ILSVRC 대회에서 1등을 차지했다.
ResNet-50, ResNet-101, ResNet-152는 two-layer residual block이 아닌 bottleneck 모듈이라 불리는 three-layer residual block을 사용한다. bottleneck이라 불리는 이유는 block의 양 끝이 중간보다 얇기 때문인데 이는 1*1 커널을 사용했기 때문이다. 이는 parameter의 수를 줄여줄 뿐만 아니라 네트워크의 비선형성에도 크게 기여한다.
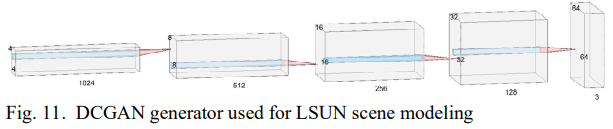
DCGAN
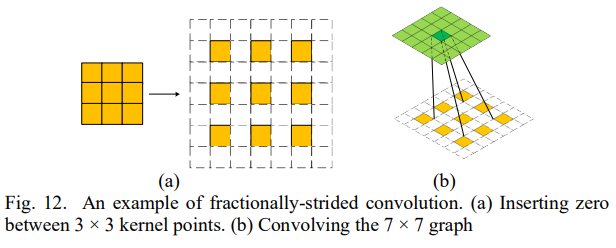
DCGAN의 generator는 Large-scale Scene Understanding(LSUN) 데이터셋이 쓰였다. DCGAN의 generator는 'fractionally-strided convolution'을 통해 upsampling을 한다. 3*3 커널 사이사이에 0을 넣어 커널을 크게하여 convolution 곱을 하는 것이다. (= dilated CNN?)
MobileNets
MobileNets는 핸드폰 같은 embeded 기계를 위해 제안된 경량화된 모델의 시리즈이다. 깊이 별로 분리 가능한 convolution을 사용하고, 조금 더 얇은 deep neural network를 만들기 위해 몇가지 진보된 기술을 사용한다.
MobileNet v1
MobileNet v1은 기존의 convolution을 깊이 별 convolution과 pointwise convolution으로 분리하는 Xception에 제안된 깊이 별로 분리 가능한 convolution을 사용한다. 즉, 원래 convolution은 input의 모든 channel에 convolution 곱을 취했지만, 깊이 별 convolution은 input의 한 채널에만 각각의 convolution 곱을 취한다. 그리고 1*1 convolution을 사용하여 결과물을 합친다. 이러한 방법은 parameter 수를 줄이는 효과가 있다. 또한 MobileNet v1은 각각의 layer의 channel 수를 줄이기 위한 width multiplier와 input 이미지의 좋지 않은 화질을 위한 resolution multiplier를 소개했다.
MobileNet v2
MobileNet v1을 기반으로 하여 v2는 2개의 improvements를 소개한다. 첫번재는 inverted residual block이고 두번재는 linear bottleneck이다.
MobileNet v2의 inverted residual block은 ResNet에서 소개한 residual block의 기능과 반대이다. inverted residual block의 입력은 처음 1*1 사이즈의 커널을 통해 channel 수를 늘리고, 3*3 커널을 이용하여 깊이 별 convolution 연산을 한다. 그리고 마지막에 다시 1*1 커널을 통해 원래의 channel 숫자로 돌아온다. 깊이 별 convolution 연산은 channel 수를 변화시킬 수 없으므로 양 끝 단에 1*1 커널을 통해 channel을 늘리고 줄이는 것이다. 하지만 channel 수를 줄이는 것에서 문제가 발생할 수 있다. ReLU 함수를 저차원 공간에서 활용할 때 정보를 없앨 수 있기 때문이다. 그렇기 때문에 두번째 (채널 수를 압축하는) 1*1 커널에서는 ReLU 함수를 사용하지 않고 선형 변환만을 사용한다.
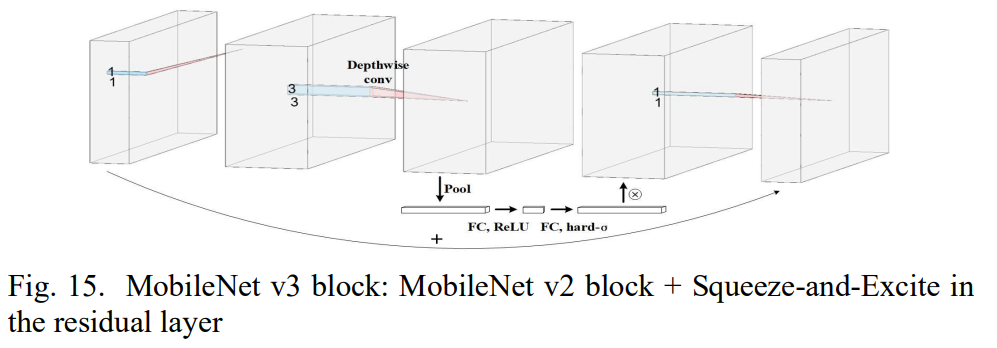
MobileNet v3
MobileNet v3는 3개의 imporvements를 소개한다. platform-aware NAS(Neural Architecture Search), NetAdapt 알고리즘, 수축과 자극(squeeze and excitation)을 기반으로 한 경량화된 어텐션 모델, 그리고 h-swish 활성화 함수이다.
MobileNet v3는 block-wise search를 위해 platform-aware NAS를 사용한다. 이것은 RNN을 기반으로 한 컨트롤러와 전역적인 네트워크의 구조를 찾기 위한 계층적인 검생 공간을 활용한다. 그리고 platform-aware NAS의 보충물인 NetAdapt 알고리즘은 layer-wise search를 위해 사용된다. 이것은 각각의 layer 안의 filter의 적절한 숫자를 찾는데 사용할 수 있다. 요약하자면 그냥 모델의 구조를 파악해서 적절한 숫자의 filter를 구하고, 적절한 모델의 구조를 완성한다는 의미인 것 같다.
또한 MobileNet v3는 경량화된 어텐션 모델을 위해 각각의 레이어의 채널의 가중치를 다시 조정하기 위해 squeeze and excitation (SE)를 사용한다. inverted residual block 뒤에 SE 모듈을 붙여 global pooling을 하고, 첫번째 fc layer를 통해 채널의 수를 1/4로 줄이고, 두번째 fc layer는 원래의 채널 수로 되돌린 후 각각의 layer의 가중치를 얻게 되어, 재 조정된 가중치를 만들기 위해 depth-wise convolution의 결과와 곱하게 된다. 이것은 추가적인 시간 소요 없이도 정확도를 올릴 수 있다고 증명되었다.
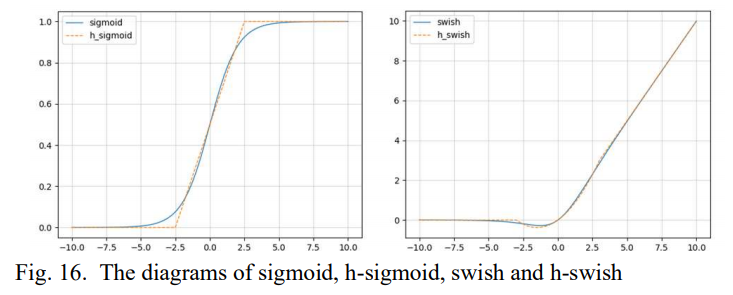
저자는 MobileNet v3를 통해 ReLU 함수 보다 swish 함수가 더 좋은 성능을 보였다고 한다. swish 함수가 더 많은 연산량을 요구하기 때문에 정확도에 변화 없이 연산량을 줄이기 위해 h-swish를 사용했다. 하지만 h-swish 모델이 깊은 층에서만 효과적인 모습을 보였기 때문에 모델의 후반의 layer에만 사용되었다. 또한 sigmoid 함수가 h-sigmoid 함수로 대체할 수 있음을 밝혔다.
ShuffleNets
이는 모바일 기기의 불충분한 컴퓨팅 파워를 해결하기 위해 제안된 CNN 기반 모델의 시리즈이다. 이 모델들은 pointwise group convolution, channel shuffle, 그리고 다른 기술들을 조합하여 최소한의 성능 저하로 연산량을 줄인 모델이다.
ShuffleNet v1
ShuffleNet v1은 자원이 제한된 기기를 위한 고효율의 CNN 구조를 제안한다. pointwise group convolution, channel shuffle을 통해 이를 구현했다.
저자는 1*1 커널이 많은 연산량을 요구하기 때문에 작은 네트워크에서는 Xception과 ResNeXt이 덜 효율적이라고 생각했다. 그래서 1*1 convolution의 연산량을 줄이기 위해 pointwise group convolution이 제안되었다. 이것은 각각의 convolution 연산이 대응되는 input channel group에만 수행하여 연산량을 줄인다. (아래 왼쪽 사진) 하지만 이것은 feature map이 다른 그룹들과 연결되는 것을 막는 문제점이 있다. 이것은 대표성을 띠는 feature map을 만드는데 치명적이다. 그러므로 channel shuffle을 통해 다른 그룹들의 정보를 랜덤하게 흐를 수 있도록 했다. (아래 오른쪽 사진)
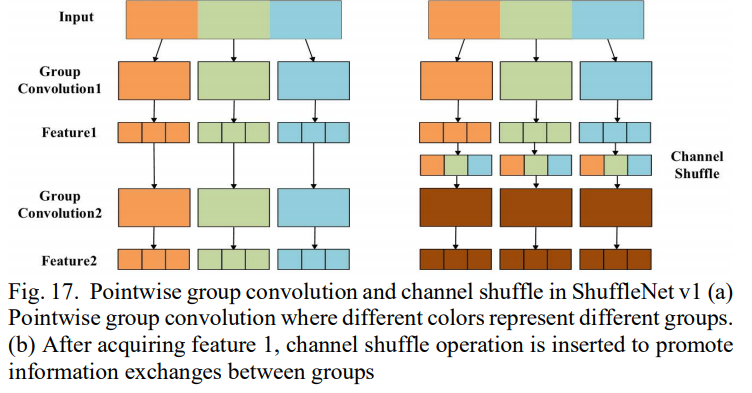
또한 ShuffleNet 유닛은 channel shuffle 연산을 기반으로 제안된다. (c)가 최종 ShuffleNet 유닛의 아키텍처이다.
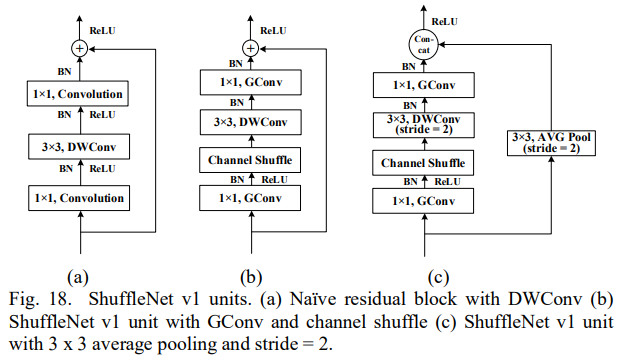
ShuffleNet v2
저자는 많은 네트워크들이 FLOPs인 연산량 metric에 지배되어 왔다고 제안한다. 그럼에도 불구하고, 메모리 액세스 비용(MAC)이 또 다른 중요한 요소이기 때문에 FLOPs를 네트워크 속도를 평가하는 유일한 표준으로 간주해서는 안 된다. 저자는 실험을 통해 네트워크를 디자인하기 위한 몇가지의 가이드라인을 제공했고, 그것을 이용해서 ShuffleNet v2를 만들었다. 4가지 요소가 제안되었는데 그것은 다음과 같다.
- GPU, ARM 기반의 플랫폼에서 1*1 convolution 연산의 메모리 액세스 비용은 input과 output이 동일한 채널을 가질 때 가장 최소화된다.
- convolution 그룹의 숫자가 변하는 것은 학습 속도에 큰 영향을 미친다. 그룹의 숫자가 많아질수록 메모리 액세스 비용은 늘고, 학습 속도는 느려진다.
- 분리된 네트워크의 구조와 기본 구조에서 convolution layer의 수를 조정함으로써, 네트워크를 분리하는 것이 병렬화의 정도를 감소시킨다는 것을 발견했다. 여러 개로 분리된 구조가 정확도를 올릴 수 있지만 GPU같은 병렬된 연산량에서 효율을 줄일 수 있다.
- ReLU, tensor addition, offset addition, separation convolution 등과 같은 elementwise operation은 무시할 수 없다. 다시 말해, 너무 많은 시간을 소모한다. 그렇기 때문에 네트워크를 설계할 때 이런 elementwise 연산을 가능한 한 많이 줄여야 한다.
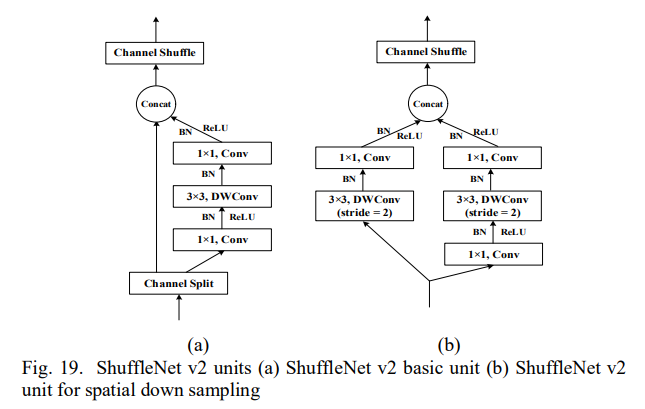
저자는 이 4가지 가이드라인 외에 channel split을 제안한다. 각각의 ShuffleNet v2 유닛에는 가장 처음 채널을 A와 B로 나눈다. 디테일은 아래 사진과 같다.
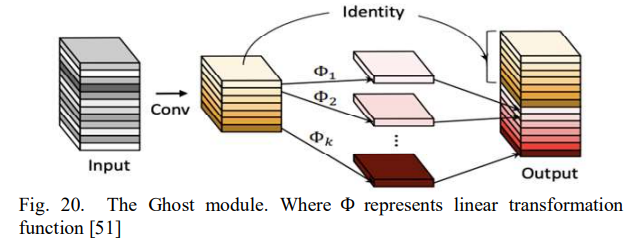
GhostNet
이미지 인식을 위한 기존의 CNN들에 의해 많은 양의 중복 기능이 추출되기 때문에 효율적으로 연산량을 줄이기 위해 GhostNet을 제안했단. 그들은 전통적인 convolution layer에 많은 비슷한 feature map이 있다는 것을 발견했다. 이러한 feature map을 ghost라고 한다. 그러므로 그들은 SOTA 성능을 위해 비용 효율적인 GhostNet을 제안한다. 두가지 주요한 기능이 있는데, 첫번째는 전통적인 convolution layer를 두 파트로 나눈다. 첫번째 파트에서는 기존의 convolution과 같이 특징 추출을 위해 적은 양의 convolution 커널을 사용한다. 그리고 이러한 특징들은 multiple feature map을 얻기 위해 선형 변환을 통해 가공된다.
Discussion and Experimental Analysis
여러 조건들에 대한 실험적인 분석이다. 이것은 rules of thumb만 정리한다.
Activation Function
Rules of Thumb
- binary classification을 위해 마지막 layer는 sigmoid를 사용할 수 있고, multi-classification을 위해서는 softmax를 사용할 수 있다.
- Sigmoid와 tanh 함수는 gradient vanishing 문제로 인해 피해야 할 수 있다. 은닉층에서는 ReLU, Leaky ReLU가 좋은 선택이다.
- 활성화 함수를 무엇을 고를지 모르겠다면 ReLU나 Leaky ReLU를 사용해라
- 만약 학습 과정에서 너무 많은 뉴런들이 활성화되지 않거나 죽는다면 Leaky ReLU나 PReLU를 사용해라
- Leaky ReLU의 negative slope는 0.02로 했을 때 학습 속도를 올렸다.
Loss Function
Rules of Thumb
- regression 문제를 다룰 때는 L1 Loss, L2 Loss를 사용할 수 있다.
- 분류 문제를 다룰 때에는 나머지 손실함수를 사용할 수 있다.
- 크로스 엔트로피 로스는 가장 대중적인 선택이다.
- 만약 클래스 사이 또는 다른 클래스 간의 margin이 고려된다면 center-loss나 large-margin softmax loss를 사용할 수 있다.
- 손실 함수의 선택은 어느 곳에 적용할 지에 따라 의존적이다. 만약 얼굴 인식을 위한 손실함수를 고른다면 triplet loss나 contrastive loss가 보편적이다.
Optimizer
Rules of Thumb
- Mini Batch Gradient Descent는 연산량과 매 업데이트 시 정확도 간의 trade-off를 만든다.
- optimizer의 성능은 데이터 분포와 밀접한 연관이 있다. 그러니 다양한 optimizer를 사용해보는 것에 부담을 갖지 말아라.
- 만약 과도한 진동이나 발산이 발생한다면 learning rate를 줄이는 것이 좋은 선택이다.
