Abstract
Regional dropout strategy는 CNN 성능을 높이기 위해 많이 제안되었다. 이미 객체의 차별성이 없는 부분 (사람의 다리)을 모델에게 보여주며 generalization 성능을 높이는 것은 증명이 되었다. 기존의 regional dropout strategy는 픽셀을 검정색으로 만들거나 random noise로 만드는 것인데 이는 정보 손실과 학습 과정 중 비효율로 이어진다. 그래서 CutMix를 제안한다. 이미지 패치들이 잘라지고 붙여지며, 이와 동시에 label도 그 비율에 맞추어 합쳐진다.
1. Introduction
CNN이 너무 작은 중간의 활성화된 부분이나 input image의 너무 작은 부분에 집중하는 것을 방지하기 위해 random feature regularization 이 제안되었다. 이 regional dropout strategy는 분류 성능을 어느 정도까지 향상시켰지만 삭제된 부분은 0으로 채워지거나 random noise로 채워졌기 때문에 이미지에서 매우 많은 정보들이 없어진다는 문제점이 있었다. 그리하여 CutMix를 제안한다. 단순히 픽셀을 지우는 것 대신에 다른 사진의 패치를 사용하여 삭제된 부분을 채운다. ground truth label도 마찬가지로 섞는다. 그럼으로써 학습과정에서 정보가 없는 부분이 없는 특징을 갖게 된다. CutMix는 Mixup과 이미지와 레이블을 합친다는 부분에서 유사하다. 하지만 분류 성능을 높이는데에 있어서 mixup sample들은 너무 부자연스럽다. cutmix는 이러한 문제점을 해결한다.
2. Related Works
Regional Dropout
CNN의 일반화 성능을 올리기 위해 이미지의 랜덤한 부분을 삭제하는 기법이다.
Synthesizing training data
몇몇 논문들은 더 나은 일반화 성능을 위해 학습 데이터를 합성한다. Stylizing ImageNet이라는 새로운 학습 샘플들을 만들기도 하며 모양보다는 texture에 더 집중하게 한다.
Mixup
두 샘플을 섞는다는 점에서 cutmix와 유사하다. 하지만 국소적으로 모호하고 부자연스럽다는 문제점이 있다. 최근에는 mixup의 변형들이 많이 생겨났다. feature-level interpolation 이나 다른 종류의 transformation을 사용하기도 한다.
Tricks for training deep networks
Weight decay, dropout, Batch Normalization은 효과적으로 deep network를 학습시키는데 많이 사용된다. 최근 CNN의 internal feature에 노이즈를 추가하는 방법이나 모델 아키텍쳐에 추가적인 경로를 더하는 방법이 분류 성능을 올린다고 제안되었다.
3. CutMix
3.1. Algorithm
, 를 각각 학습 이미지와 label이라고 하자.
CutMix의 목표는 2개의 학습 샘플 , 을 합쳐서 새로운 학습 샘플 를 만들어내는 것이다.
이 때 combining operation은 아래와 같다.
는 두 이미지로부터 어느 부분을 삭제하고 채울 것인지 선택하는 binary mask 행렬이다. 은 모든 원소가 1인 행렬이다. 은 행렬의 element-wise multiplication을 뜻한다.
MixUp과 마찬가지로 combination ratio 가 베타 분포 에서 추출된다. 논문에서는 실험을 해보았을 때 , 즉, uniform distribution에서 추출했다고 한다. CutMix와 MixUp의 주요한 차이점은 CutMix가 이미지 영역을 다른 교육 이미지의 패치로 대체했고, 더 로컬하게 자연스러운 이미지를 생성했다는 것이다.
을 추출하기 위해 우리는 먼저 와 를 자르는 곳을 가리킬 bounding box 좌표 를 추출해야 한다.
에 해당하는 부분은 제거되고 위의 bounding box에 해당하는 부분으로 채워진다.
box 좌표는 아래와 같이 정해진다.
,
,
위와 같이 bounding box를 정하게 되면 잘리는 부분의 비율은 가 된다. 이렇게 정해진 bounding box에 맞게 binary mask 가 0과 1로 채워지게 된다.
각각의 학습 iteration마다 새로운 샘플 이 mini-batch내의 임의로 선택된 2개의 학습 샘플들을 CutMix하여 생성된다.
q. 배치 사이즈를 64로 하면 32로 알아서 컷믹스한 결과를 내어주나?
q. 사진 예시에서는 고양이 얼굴에 개 몸 이런 식으로 예쁜 결과가 나왔는데 실제로는 고양이 발에 개 발 이런식으로 합성될 수도 있지 않을까?
3.2. Discussion
What does model learn with CutMix?
전체 객체의 범위가 분류의 단서로 여겨지도록 CutMix를 설계함과 동시에 한 이미지의 부분적인 시각으로 두 객체를 인지하도록 하며 학습 효율성을 높였다. CutMix가 이런 부분적인 시선으로 두 객체를 인지하는 것이 실제로 어떻게 학습되는지 확인하기 위해 Activation Map을 살펴보자. 아래의 사진에 MixUp, CutOut, CutMix 세 방법론의 Class Activation Mapping이 나와있다. 이 사진을 보면 CutOut이 모델이 물체의 덜 차별적인 부분에 성공적으로 집중하게 했지만 사용되지 않는 픽셀로 인해 효율적이지 않음을 볼 수 있다. 또한 MixUp은 모든 픽셀을 사용하지만 부자연스럽고, 모델이 분류에대한 단서를 고르는 것에 혼동스러워 하는 것을 볼 수 있다. 우리는 이런 혼란이 분류와 localization에 최적의 성능으로 이끌 수 없다고 생각했다.
CutMix는 두 객체를 정확하게 localize할 수 있어 Cutout보다 더 효율적으로 성능을 향상시킨다.

Analysis on validation error
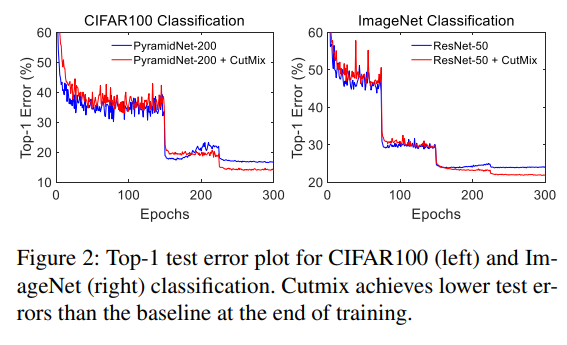
ResNet-50 모델과 ImageNet, PyramidNet-200과 CIFAR 100 분류에서 top-1 validation error를 측정한 결과 아래와 같은 결과를 보였다.
CutMix는 더 낮은 validation error를 보였고, 150 epoch에서 learning rate를 줄였을 때 base model은 overfitting으로 인해 validation error가 늘었지만 CutMix는 ovefitting을 피해 꾸준한 감소를 보였다.
4. Experiments
4.1 ImageNet Classification
4.1.1 ImageNet Classification
Augmentation methods : standard augmentation setting (resizing, cropping, flipping)
Hyperparameters : 300 epochs, 0.1 learning rate decayed by factor 0.1 at epochs 75, 150, 225. Batch size 256.
Comparison against baseline augmentations
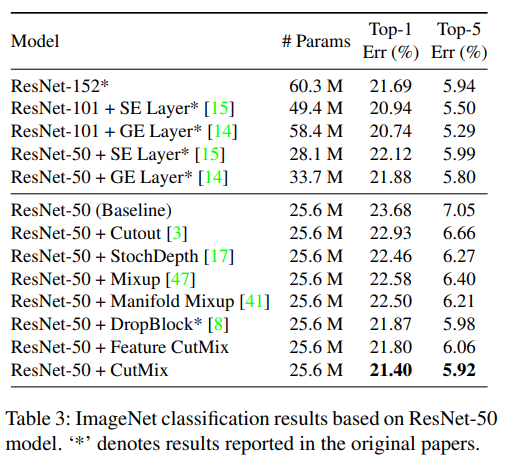
Comparison against architectural imporvements
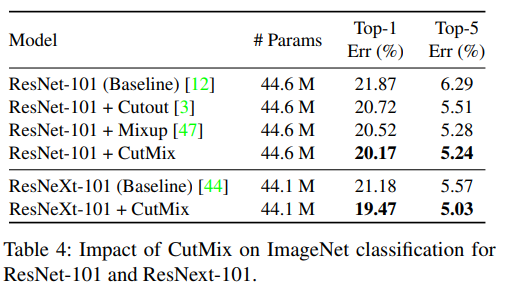
4.1.2 CIFAR Classification
batch size 64, training epochs 300. Learning rate 0.25 and decayed by the factor of 0.1 at 150 and 225 epoch.
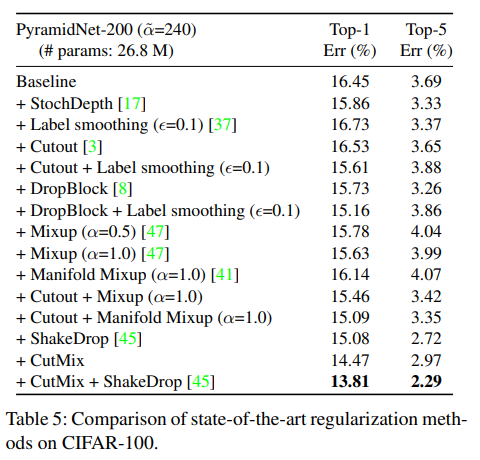
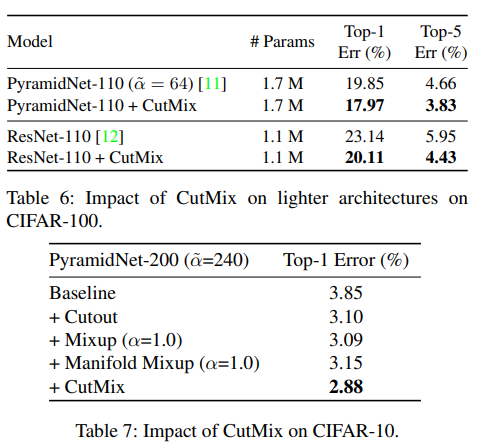
q. 왜 굳이 다른 모델을 사용했을까?
q. Shake Drop?
q. 왜 갑자기 normalization을 추가하고 뭐시고 했을까?
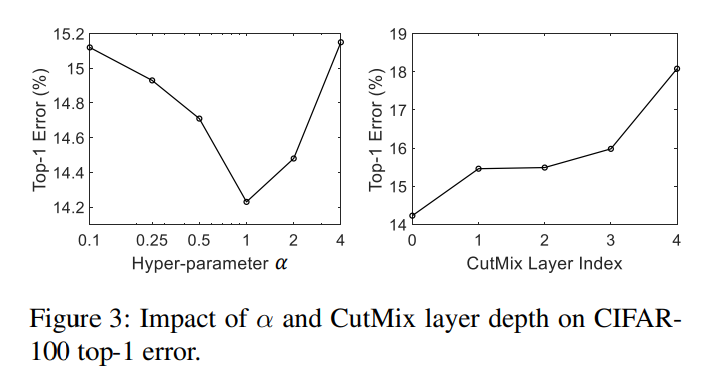
4.1.3 Ablation Studies
, the results are given in Figure 3 left plot. 에 따라 error가 상이하지만 이 모든 결과는 baseline model의 결과 (16.45%)보다 모두 낮음.
performance of feature-level CutMix is given in Figure 3 right plot.
4.2 Weakly Supervised Object Localization
Weakly Supervised Object Localization은 분류기가 클래스 label만을 사용하여 타겟 사진의 지역적인 부분을 잡아내는 것을 의미한다. 이것을 잘하기 위해서는 CNN이 타겟의 작은 차별적인 부분에 집중하는 것이 아닌 전체 객체의 지역을 잘 잡아내야 한다.

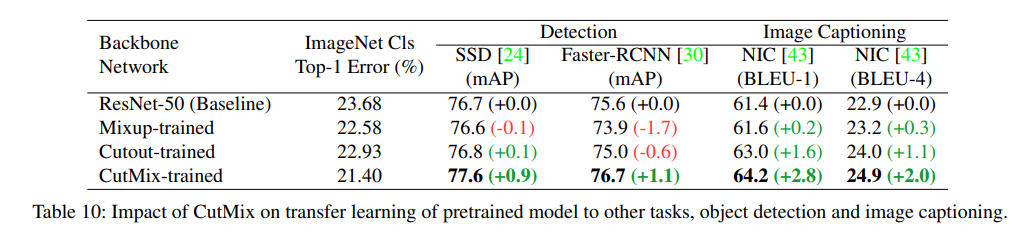
위의 사진을 보면 CutMix를 했을 때 ground truth의 bounding box(red)와 모델이 잡아낸 bounding box가 거의 일치하고 다른 모델들은 그렇지 않은 것을 볼 수 있다. 이 말인 즉슨 CutMix로 학습을 했을 때 이미지의 전역적인 특징을 잘 잡았다고 볼 수 있다.
수치적인 결과는 다음과 같다.