Intro
딥러닝/인공지능과 관련된 강의를 듣게 되어 기초부터 처음부터 차근차근 천천히 정리하며 학습을 진행해보려 한다. 누구 한 명은 봐주겠지.
Training Logic
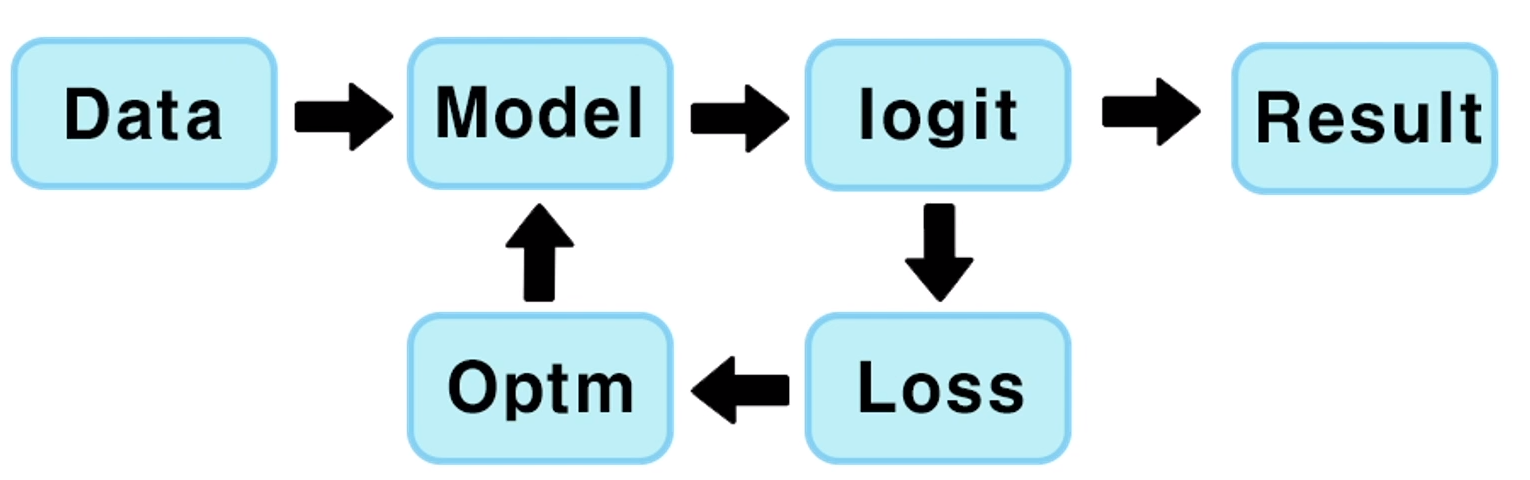
학습용 Data가 주어지게 되면 컴퓨터는 이를 기반으로 Model을 생성하게 된다. 이 Model을 기반으로 컴퓨터는 예측을 하고, 컴퓨터가 예측한 데이터와 Data에 Label된 데이터를 기반으로 Loss를 산출하게 되고, 이 Loss를 기반으로 Optimization을 하는 과정을 반복하여 Result를 출력한다.
Data
Model을 만들기 위한 데이터- 모델에 들어가기 전 데이터 전처리 필요
Model에 데이터를 넣을 시 Batch로 만들어서Model에 입력
Model
LeNet,AlexNet,VGG,ResNet등 성격에 맞게 분류해주는 다양하게 설계된 모델 존재Convolution Layer,Pooling등 다양한 Layer 구성Model에 Training Param 존재- 학습하려는 데이터의 종류에 따라 가장 효율적인
Model을 선택하는 것이 관건
Prediction / Logic
- 컴퓨터가
Model을 기반으로 각 Class별로 예측한 값

- 예를 들면, 컴퓨터에 각 과일에 대한 데이터를 기반으로
Model을 생성했다고 하면, 컴퓨터는 어떠한 특정 값이 입력되었을 때 이Model을 기반으로 해당 입력 값에 대한 예측을 진행한다. - 이 때 각 Class별로 어느 정도 값이 일치하는 지에 대해 수치 상으로 출력하게 되며, 이를
Prediction이라고 한다. - 위 이미지를 예로 들자면 컴퓨터가 사과일 확률 0.65, 수박일 확률 0.15, 딸기 0.1, 포도 0.05, 바나나 0.05 라고 예측했으며, 이 중 가장 높은 값이 모델이 예상하는
Class또는 정답이다. - 위 값이 정답이라고 할 때 얼마나 맞았는지, 틀렸는지 확인이 가능
Loss / Cost
- 예측한 값이 입력 시 Label된 정답과 비교해서 정답률을 확인
Cross Entropy와 같은 다양한Loss Function존재Loss는 오답률을 말하며, 이 값을 최소화 시키는 것이 학습의 과정
Optimization
- Loss 값을 최소화 하기 위한 과정
- 내부 Weight 변경을 통해
Model최적화를 진행하는 과정
Result
- 위 과정을 우리가 원하는 만큼 반복한 뒤에 나오는 최종 결과물
- 평가할 때 또는 예측된 결과를 확인할 때는 예측된 값에서
argmax를 통해 가장 높은 값을 예측한class

@github https://github.com/jhpark-jarvis