[paper-review] Contextual Augmentation: Data Augmentation by Words with Paradigmatic Relations
Paper Review
Kobayashi, Sosuke. "Contextual augmentation: Data augmentation by words with paradigmatic relations." arXiv preprint arXiv:1805.06201 (2018).
Abstract
- 텍스트 Classification의 성능 향상을 위한 Data Augmentation의 방법론을 제안
- Contextual augmentation
- 문장을 구성하는 단어들을 문맥 상 비슷한 다른 단어로 대체하여 데이터를 증강하는 방법
- Bi-LSTM과 같은 언어 모델로 각 단어별 문맥 상 비슷한 확률을 계산해 높은 확률을 가진 단어로 그 단어를 대체
- Label-conditional architecture
- Contextual augmentation에 사용되는 언어 모델은 증강된 데이터의 class label도 변환해서는 안됨
- 따라서 이러한 언어 모델에 증강에 사용되는 데이터의 class label 정보를 전달하여 언어 모델이 class label의 정보를 바꾸지 않도록 방지함.
1. Introduction
텍스트 데이터 증강에서의 한계
많은 신경망 기반의 자연어 처리 모델은 여러 분야에서 좋은 결과를 만들어냄.
그러나, 이러한 모델들은 꽤 많이 일반화(Generalization)를 이루지 못하고 과 적합됨.
일반화의 성능은 학습 데이터의 크기와 품질, 학습 제약(regularization)에 영향을 받지만, 이러한 큰 규모의 데이터셋을 준비하는 것은 매우 시간이 소모되는 일임.
때문에 컴퓨터 비전 등의 분야에서 유용한 기법인 데이터 증강이 사용될 수 있음.
하지만 기존 자연어 처리(Natural Language Processing; NLP) 분야에서의 데이터 증강의 사용은 제한적이었음.
- 다양한 도메인에 적용하기 쉬운 일반적인 변환 규칙 정의의 어려움
- 사람이 임의로 만들어낸 기준으로 선택된 동의어로의 단어 대체는 그 범위가 매우 한정적
위와 같은 이유로 일반화를 온전히 이루지 못한 채로 특정 도메인에 특화된 방법론만이 발전됨.
새로운 방법론에 대한 소개
Contextual augmentation
- 언어 모델을 통한 문장 내 단어들의 위치에 대해 문맥상 올바른 단어일 확률을 계산
- 계산에 사용되는 모든 단어의 확률 계산, 높은 확률을 가진 단어로 대체
- 증강된 데이터의 class label 변환을 Label-conditional architecture를 통해 억제
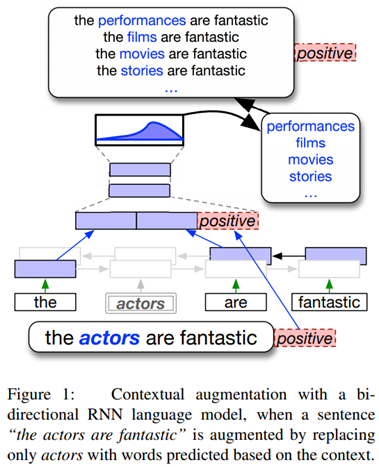
2 Proposed Method
2.1 Motivation
예문 "the actors are fantastic"이라는 문장은 Positive label이 부여되어 있음. "actor"라는 단어에 대해 데이터 증강을 하면 어떤 방식이 사용될까?
- 기존 동의어를 기반으로한 단어 대체: histrion, player, thespian, role-player와 동의어
- 긍정적인 감정 상태와 문맥의 자연스러움을 유지한 대체: characters, movies, stories, songs와 같은 "actors"와 의미가 다른 명사
후자의 경우가 모델의 학습에 더 도움을 줄 것이라 판단할 수 있음.
2.2 Word Prediction based on Context
모든 단어들의 문맥상 가치 판단을 위한 언어 모델은 문장 의 번째 단어 의 문맥상 가치를 확률로써 다음과 같이 나타냄.
여기에 temperature parameter 를 도입하여 augmentation되는 단어의 다양성을 조절함.
- 일 때, 모든 단어들이 동일한 확률로 샘플링됨
- 일 때, 가장 높은 확률을 가지는 하나의 단어만 지속적으로 샘플링됨
2.3 Conditional Constraint
단어의 문맥상 가치 판단만을 고려하여 데이터 증강을 하면, 원래 데이터의 class label과 증강된 데이터의 class label이 서로 다른 경우가 발생할 수 있음.
- Label-compatibility issue
- "the actors are fantastic"에서 "fantastic"은 다양한 단어로 대체될 수 있음
- "good", "entertaining": 긍정적인 변화, class label이 기존 데이터와 동일함.
- "bad", "terrible": 잘못된 변화, 문맥상 가치는 매우 높지만 class label이 기존 데이터와 전혀 달라짐.
이러한 Issue의 해결을 위해 기존 데이터의 class label 를 모델에 포함함
논문에서는 이러한 작업을 'Label-conditional architecture'라고 부름.
3. Experiment
3.1 Settings
사용된 데이터셋 목록은 다음과 같음.
- SST5: 영화 리뷰에 대한 감정 분류를 위한 데이터셋 다섯 가지의 레이블이 부여되어 있음.
- SST2: 1과 동일, 두 가지의 레이블이 부여되어 있음.
- Subjectivity dataset (Subj): 문장의 주격, 목적격의 분류 문제 데이터셋.
- MPQA: 짧은 어구에 대한 의견 분류 데이터셋.
- RT: 영화 리뷰 감정 분류 데이터셋.
- TREC: 질문 타입 분류 데이터셋, 여섯 가지 레이블.
방법론의 검증을 위해 LSTM-RNN, CNN 등의 분류기로 아래 세 가지 데이터 증강 방법론을 비교함.
- synonym-based augmentation
- contextual augmentation without a label-conditional architecture
- contextual augmentation with a label-conditional architecture
2와 3의 방법을 위해서는 아래의 작업이 필요함.
- contextual augmentation without a label-conditional architecture
- bi-LSTM without a label-conditional architecture를 WikiText-103 말뭉치 데이터에 사전 학습
- contextual augmentation with a label-conditional architecture
- 사전학습 후, 각각의 데이터셋에 맞추어 label-conditional architecture를 붙여 fine-tuning
3.2 Results
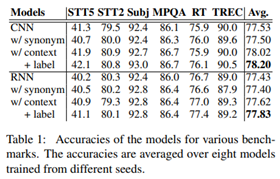
논문에서 제안한 방법이 다양한 데이터셋과 다양한 도메인에 대해 성능이 향상되는 경향을 보임.
두 가지 레이블(Binary classification)보다는 여러 가지의 레이블(Multi class classification) 데이터셋에 대해 더 효과적이었음.
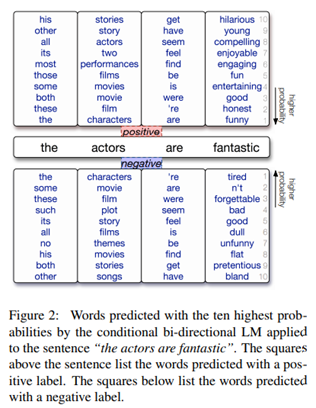
Figure 2.에서는 SST 데이터셋에 대한 데이터 증강 결과임. 상위 10개의 증강된 데이터 목록을 보면 동의어라고 볼 수 없는 단어들이 많이 분포하고 있음.
Label-conditional architecture의 효과로 다음의 현상을 관찰할 수 있음.
- 긍정적인 증강 데이터에는 "funny", "honest", "good", "entertaining"과 같은 긍정적인 단어들이, 부정적인 증강 데이터에는 "tired", "forgettable", "bad", "dull"과 같이 모두 부정적인 표현들이 나타남.
- "the" 단어 위치에서는 "no"라고 바뀌면서 전체 문장이 "no actors are fantastic"이 되며 부정적인 의미가 되었음.
- class label에 크게 영향을 미치지 않는 단어인 "actors"에 대해서는 긍정 데이터와 부정 데이터의 단어 차이가 크게 보이지 않음.
4. Related Work
- 동의어 리스트, 문법 적용, 각 태스크에 특화된 규칙 적용, 오토인코더와 같이 다양한 방식의 텍스트 데이터 증강을 시도한 연구가 있었음.
- 본 연구와 가장 비슷한 연구는 Kolomiyets 등의 연구와 Fadaee 등의 연구를 들 수 있음.
- 위 두 가지 연구들은 "언어 모델의 사용"이라는 아이디어를 공유하고 있음.
5 Conclusion
- 언어 모델이 예측해내는 다양한 단어들을 사용하는 새로운 데이터 증강 방식을 제안.
- 언어 모델에 label-conditional architecture를 도입.
- 원래의 텍스트 class label을 해치지 않는 다양한 단어를 통해 데이터를 증강.
- 기존의 동의어 기반 데이터 증강 방법보다 신경망의 성능 향상을 도움.
- 특정 태스크나 규칙에 매몰되지 않고 독립적이며 일반적이고 쉽게 다양한 도메인의 분류 태스크에 사용될 수 있음.
- 성능 향상은 미미한 수준일 때가 있었으며 향후 연구에서 데이터셋을 심도 있게 활용하는 다른 방법론과의 비교 및 조합을 연구할 수 있음.
